目录
一.原子操作
多线程下确保堆共享变量的操作在执行时不会被干扰,从而避免竞态条件
1.原子操作的概念
①.原子操作定义:
对基本类型或指针进行的不可中断的操作。
②.原子性:
确保操作在多线程环境下不被中断,保证线程安全。
③.内存序:
理解内存序的概念,确保操作的同步性和顺序性。
2.原子变量
①autoinc.cc
②原子变量的操作
③原子性
④原子操作是实现和平台相关
二.原子性
1.中间状态描述
要么都做要么都还没做,不会然其他核心看到执行的一个中间状态
2.单处理器单核
①单核单线程我们只需要保证操作的指令不会被中断即可(调用机制)
②在硬件底层有自旋锁
③屏蔽中断:通过关闭处理器的中断功能,让处理器在执行关键代码段的时候,不接收外部的请求从而保证了关键代码段执行的过程中不会被打断
3.多处理器或多核的情况下
除了不被打断还需要避免其他核心操作相关的内存空间
①以往0x86,lock指令锁总线,避免所有内存的访问
②现在lock指令只需要阻止其他核心堆相关内存空间的访问即可
4.cache(高速缓冲器的作用)
为了解决cpu运算速度与内存访问速度不匹配的问题
5.在cpu cache基础上,cpu如何读写数据???
我们可以通过写回策略来决定
写
①是否命中缓存?
命中直接写并标记为脏 ,没命中则直接往下
②定位缓存块,该数据是否为脏数据?
是脏数据则刷主存,不是脏数据,从内存读取,写入缓存,并标记为脏
读
①是否命中缓存?
命中直接返回,没命中直接往下
②定位缓存块,该数据是否为脏数据?
是脏数据则刷主存,不是脏数据,从内存读取,写入缓存,并标记为非脏
6.为什么会有缓存一致性问题
①cpu是多核的
②基于写回策略将会出现缓存不一致的问题
7.解决策略
①基于总线嗅探机制实现了事务串行化,通过状态机降低总线带宽的压力
②事务的串行化:“锁” 和 “lock指令”
③MESI一致性协议
三.内存序
1.为什么有内存序问题???
①编译器优化重排
②CPU指令优化重排
2.内存序规定了什么
①规定了多个线程访问同一内存地址时的语义
②某个线程对内存地址的更新何时能被其他线程看见
③某个线程对内存地址访问附件可以做什么样的优化
3.六种不同的内存序
① std::memory_order_relaxed不保证顺序性,性能优先。
② std::memory_order_consume读取数据的顺序不被重排(但现代编译器会优化成 acquire)。
③ std::memory_order_acquire保证之前的操作不被重排到后面。
④ std::memory_order_release保证之后的操作不被重排到前面。
⑤ std::memory_order_acq_rel结合了 acquire 和 release 的特性。
⑥ std::memory_order_seq_cst保证全局顺序一致性。
补充::
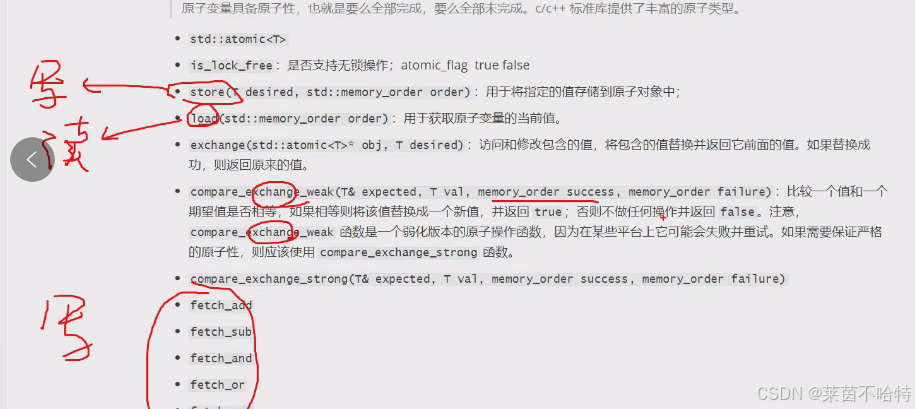
4.代码案例
①
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_relaxed); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_relaxed)); // 3
if(x.load(std::memory_order_relaxed)) // 4
++z;
}这种情况下没有指定内存序的位置会导致y先变成true 然后 x依旧是false while结束死循环 if语句判断失败 从而z不会发生++的操作
由于使用了 std::memory_order_relaxed,x 和 y 的写操作可能会在内存中被重排,因此 read_y_then_x 线程检查到 x 为 false 的情况是可能的。最终,这会导致 z 不一定等于 1,甚至可能为 0,取决于内存重排的情况。
②
#include <atomic>
#include <thread>
#include <assert.h>
#include <iostream>
std::atomic<bool> x,y;
std::atomic<int> z;
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_release); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire)); // 3
if(x.load(std::memory_order_relaxed)) // 4
++z;
}这种情况下z的结果一定为1
因为y读出来是true的时候 x一定也是true
使用了 memory_order_release 和 memory_order_acquire,确保了在 y 设置为 true 之后,x 的修改在 read_y_then_x 线程中变得可见。
z 最终会等于 1,因为通过这些内存序约束,线程间的同步得到了保证。
③
#include <assert.h>
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<bool> x, y;
std::atomic<int> z;
void write_x() {
x.store(true, std::memory_order_seq_cst); // 1
}
void write_y() {
y.store(true, std::memory_order_seq_cst); // 2
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst)) // 3
++z;
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst)) // 4
++z;
}
int main() {
for (int i = 0; i < 20; i++) {
x = false;
y = false;
z = 0;
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
// assert(z.load() != 0); // 5
std::cout << z.load() << std::endl;
}
return 0;
}在 memory_order_seq_cst 下,所有的操作会严格按照全序进行,因此每个线程的原子操作都是同步的。
程序的输出 z 最终将是 0 或 2,这取决于两个 read_* 线程的执行顺序。如果两个线程都能正确读取到 x 和 y,则 z 会增加到 2。
四.总结
只有我们要极致提升性能的时候才有考虑原子操作进行提升性能 ,在绝大部分时候我们只需要使用互斥锁和条件变量即可满足服务器开发的需求