目录
io_uring 原理及核心数据结构
io_uring 来自资深内核开发者 Jens Axboe 的想法,他在 Linux I/O stack 领域颇有研究。 从最早的 patch aio: support for IO polling 可以看出,这项工作始于一个很简单的观察:随着设备越来越快, 中断驱动(interrupt-driven)模式效率已经低于轮询模式 (polling for completions) —— 这也是高性能领域最常见的主题之一。
-
在设计上是真正异步的(truly asynchronous)。只要 设置了合适的 flag,它在系统调用上下文中就只是将请求放入队列, 不会做其他任何额外的事情,保证了应用永远不会阻塞。
-
支持任何类型的 I/O:cached files、direct-access files 甚至 blocking sockets。
由于设计上就是异步的(async-by-design nature),因此无需 poll+read/write 来处理 sockets。 只需提交一个阻塞式读(blocking read),请求完成之后,就会出现在 completion ring。
-
灵活、可扩展:基于
io_uring甚至能重写(re-implement)Linux 的每个系统调用。
每个 io_uring 实例都有两个环形队列(ring),在内核和应用程序之间共享:
提交队列:submission queue (SQ)
完成队列:completion queue (CQ)
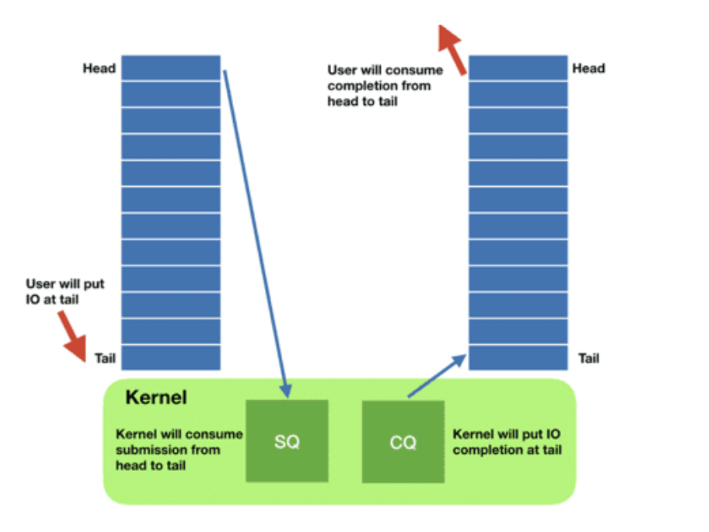
这两个队列:
都是单生产者、单消费者,size 是 2 的幂次;
提供无锁接口(lock-less access interface),内部使用 内存屏障做同步(coordinated with memory barriers)。
使用方式:
-
请求
应用创建 SQ entries (SQE),更新 SQ tail;内核消费 SQE,更新 SQ head。 -
完成
- 内核为完成的一个或多个请求创建 CQ entries (CQE),更新 CQ tail;
- 应用消费 CQE,更新 CQ head。
- 完成事件(completion events)可能以任意顺序到达,到总是与特定的 SQE 相关联的。
- 消费 CQE 过程无需切换到内核态。
io_uring 和 epoll的区别
epoll 和 io_uring 都是 Linux 下用于处理 I/O 事件的机制,它们有以下区别:
设计理念与用途
- epoll:是基于
poll和select改进的 I/O 多路复用机制,专门用于监控多个文件描述符(如 socket、文件等 )上的事件(读、写、异常等 )。它采用事件驱动模式,只在注册的文件描述符发生事件时触发,避免无效扫描。适用于事件驱动的网络编程场景,像监视多个客户端连接的服务器 。比如 Nginx、Redis 等都基于epoll构建。 - io_uring:是更广泛的异步 I/O 框架,不仅用于事件通知,还能直接执行 I/O 操作。旨在提高大规模并发 I/O 操作性能,可处理网络 I/O、文件 I/O、内存映射等多种场景,目标是实现 Linux 下一切基于文件概念的异步编程 。
实现机制
- epoll:使用红黑树管理需要监听的文件描述符,用一个事件队列存放 I/O 就绪事件。调用
epoll_wait时,内核将已就绪的事件从内核空间拷贝到用户空间,用户程序依次处理这些事件。若有大量事件就绪,需多次系统调用处理。 - io_uring:基于两个共享环形缓冲区,即提交队列(SQ )和完成队列(CQ ) 。用户程序将 I/O 请求写入 SQ,内核处理完 I/O 操作后,把结果写入 CQ,用户程序从 CQ 异步获取结果。通过这种方式,减少了用户态到内核态的上下文切换次数,且支持批量提交和处理 I/O 请求 。比如初始化 1000 个 I/O 请求,可一次提交,而
epoll需逐个处理 。
I/O 操作类型支持
- epoll:主要功能是监听和处理文件描述符上的事件,本身不直接执行 I/O 操作。当监听到事件就绪后,仍需通过系统调用(如
read、write等 )来完成实际的 I/O 读写 。 - io_uring:不仅能处理事件通知,还可直接执行多种 I/O 操作,如读写文件、网络 I/O 操作(
send、recv、accept等 ) 。
阻塞与非阻塞特性
- epoll:
epoll_wait可设置为阻塞或非阻塞模式,通常情况下是阻塞的,直到有事件发生才返回 。 - io_uring:支持完全异步的操作,通过提交和完成队列机制实现非阻塞 I/O 。应用程序提交 I/O 请求后无需等待,可继续执行其他任务,内核处理完后将结果放入完成队列 。
性能表现
- 在高并发场景下,
io_uring性能优势明显。测试显示,连接数 1000 及以上时,io_uring性能开始超越epoll,其极限性能单 core 在 24 万 QPS 左右,而epoll单 core 只能达到 20 万 QPS 左右 。io_uring能极大减少用户态到内核态的切换次数,在连接数超过 300 时,其用户态到内核态的切换次数基本可忽略不计 。不过在某些特殊场景(如meltdown和spectre漏洞未修复时 ),io_uring相对epoll的性能提升不明显甚至略有下降 。
编程复杂度
- epoll:相对简单,开发者只需关注文件描述符的事件注册(
epoll_ctl)和事件处理(epoll_wait返回后的逻辑 ) 。 - io_uring:功能强大但开发复杂度较高。需深入理解提交队列和完成队列工作机制,手动管理 I/O 请求的提交、结果获取,以及处理队列初始化、事件提交与回收等操作
io_uring实现一个TCP服务器
#include <stdio.h>
#include <liburing.h>
#include <netinet/in.h>
#include <string.h>
#include <unistd.h>
#include"func.h"
#define EVENT_ACCEPT 0
#define EVENT_READ 1
#define EVENT_WRITE 2
struct conn_info{
int fd;
int event;
};
int init_server(unsigned short port) {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serveraddr;
memset(&serveraddr, 0, sizeof(struct sockaddr_in));
serveraddr.sin_family = AF_INET;
serveraddr.sin_addr.s_addr = htonl(INADDR_ANY);
serveraddr.sin_port = htons(port);
if (-1 == bind(sockfd, (struct sockaddr*)&serveraddr, sizeof(struct sockaddr))) {
perror("bind");
return -1;
}
listen(sockfd, 10);
return sockfd;
}
#define ENTRIES_LENGTH 1024
#define BUFFER_LENGTH 1024
int set_event_recv(struct io_uring *ring,int sockfd,void*buffer,size_t len,int flags){
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);//从ring中获取一个提交队列
struct conn_info accept_info={
.fd = sockfd,
.event=EVENT_READ,
};
io_uring_prep_recv(sqe,sockfd,buffer,len,flags);
memcpy(&sqe->user_data,&accept_info,sizeof(struct conn_info));
return 0;
}
int set_event_send(struct io_uring *ring,int sockfd,void*buffer,size_t len,int flags){
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);//从ring中获取一个提交队列
struct conn_info accept_info={
.fd = sockfd,
.event=EVENT_WRITE,
};
io_uring_prep_send(sqe,sockfd,buffer,len,flags);
memcpy(&sqe->user_data,&accept_info,sizeof(struct conn_info));
return 0;
}
int set_event_accept(struct io_uring*ring,int sockfd,struct sockaddr *addr,socklen_t* len,int flag){
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);//从ring中获取一个提交队列
struct conn_info accept_info={
.fd = sockfd,
.event=EVENT_ACCEPT,
};
io_uring_prep_accept(sqe,sockfd,(struct sockaddr*)addr,len,flag);
memcpy(&sqe->user_data,&accept_info,sizeof(struct conn_info));
return 0;
}
int main(int argc , char*argv[]){
unsigned short port = 9999;
int sockfd = init_server(port);
struct io_uring_params params;
memset(¶ms, 0, sizeof(params));
struct io_uring ring;
io_uring_queue_init_params(ENTRIES_LENGTH,&ring,¶ms);//初始化
//ring这个结构体包含了提交队列和完成队列
struct sockaddr_in clinaddr;
socklen_t clinlen = sizeof(clinaddr);
set_event_accept(&ring,sockfd,(struct sockaddr*)&clinaddr,&clinlen,0);
char buffer[BUFFER_LENGTH]={0};
while(1){
io_uring_submit(&ring);
// io_uring 提交队列中的 I/O 操作请求提交给内核进行处理
struct io_uring_cqe *cqe;
io_uring_wait_cqe(&ring,&cqe);//
//该函数会阻塞当前进程,直到 io_uring 完成队列中有新的 I/O 操作完成事件。
//存储到 cqe 指针中。
struct io_uring_cqe *cqes[128];
int nready = io_uring_peek_batch_cqe(&ring,cqes,sizeof(cqes));
int i;
for(i=0;i<nready;i++){
struct io_uring_cqe *entries=cqes[i];
struct conn_info reslut;
memcpy(&reslut,&entries->user_data,sizeof(struct conn_info));
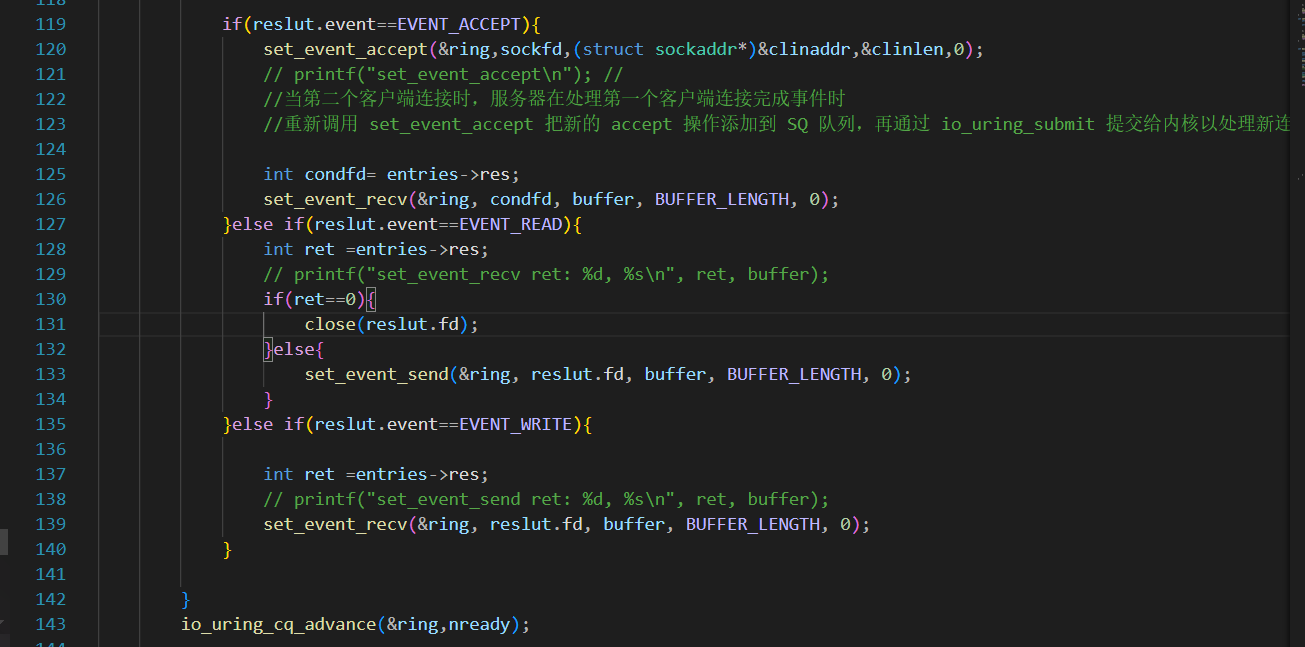
if(reslut.event==EVENT_ACCEPT){
set_event_accept(&ring,sockfd,(struct sockaddr*)&clinaddr,&clinlen,0);
// printf("set_event_accept\n"); //
int condfd= entries->res;
set_event_recv(&ring, condfd, buffer, BUFFER_LENGTH, 0);
}else if(reslut.event==EVENT_READ){
int ret =entries->res;
// printf("set_event_recv ret: %d, %s\n", ret, buffer);
if(ret==0){
close(reslut.fd);
}else{
set_event_send(&ring, reslut.fd, buffer, BUFFER_LENGTH, 0);
}
}else if(reslut.event==EVENT_WRITE){
int ret =entries->res;
// printf("set_event_send ret: %d, %s\n", ret, buffer);
set_event_recv(&ring, reslut.fd, buffer, BUFFER_LENGTH, 0);
}
}
io_uring_cq_advance(&ring,nready);
}
}①

struct io_uring_params 结构体包含了多个字段,用于配置 io_uring 队列的各种行为和特性,例如提交队列(SQ)和完成队列(CQ)的条目数量、标志位、线程相关参数等。
②

io_uring结构体 它代表了整个 io_uring 实例,包含了提交队列(Submission Queue,SQ)和完成队列(Completion Queue,CQ)。
io_uring_queue_init_params此函数会根据 params 结构体中的参数对 ring 进行初始化,从而设置提交队列和完成队列的大小、特性等。
③

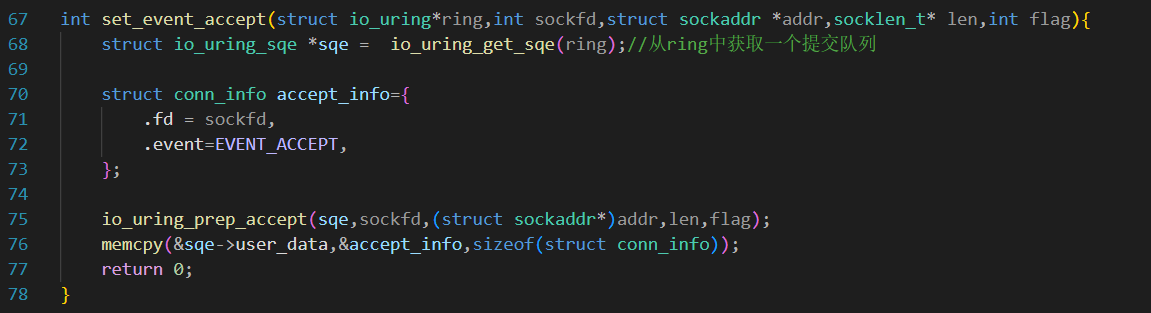 io_uring_prep_accept函数的作用是将一个
io_uring_prep_accept函数的作用是将一个 accept 操作封装到 io_uring 的提交队列条目(Submission Queue Entry, SQE)中。accept 操作通常用于在服务器端接受客户端的连接请求,当有新的客户端连接时,该操作会返回一个新的套接字描述符,用于与客户端进行通信。
④
 // io_uring_submit函数作用是把io_uring 提交队列中的 I/O 操作请求提交给内核进行处理
// io_uring_submit函数作用是把io_uring 提交队列中的 I/O 操作请求提交给内核进行处理
⑤
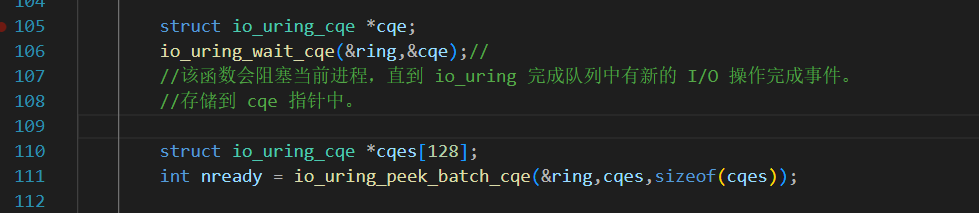
io_uring_wait_cqe 是 io_uring 库提供的一个函数,用于等待完成队列中有新的 I/O 操作完成事件。
int nready = io_uring_peek_batch_cqe(&ring, cqes, sizeof(cqes)); 是 io_uring 库中的一个关键操作,用于批量从完成队列(Completion Queue, CQ)中获取已完成的 I/O 操作条目
与epoll取就绪队列有几分相似
⑥

io_uring_prep_recv(sqe, sockfd, buffer, len, flags); 是 io_uring 库中的一个函数调用,用于准备一个接收数据的 I/O 操作,并将其添加到 io_uring 的提交队列条目(Submission Queue Entry,SQE)中。
io_uring_prep_send(sqe, sockfd, buffer, len, flags); 是 io_uring 库中的一个关键函数调用,其主要作用是准备一个发送数据的 I/O 操作,并将这个操作封装到 io_uring 的提交队列条目(Submission Queue Entry, SQE)中
io_uring_cq_advance 函数位于一个 for 循环之后,这个 for 循环用于遍历从完成队列中获取到的所有完成条目,并根据条目的事件类型(如 EVENT_ACCEPT、EVENT_READ、EVENT_WRITE)进行相应的处理。处理完所有完成条目后,调用 io_uring_cq_advance 函数,告知 io_uring 实例这些条目已经处理完毕。