目录
6.3 udp如何才能做到可靠,kcp协议在哪些方面上有优势
2 如何集成到项目中,参考代码的chat_server.cc和chat_client.cc两个代码实现聊天室功能
9.省略过多内容......................
一.我们要如何才能做到可靠性传输
1.ACK机制
ACK 机制即确认机制,是一种在计算机网络通信、消息队列系统等领域广泛应用的机制,用于确认接收方是否已经正确接收了发送方发送的数据,其英文全称为 acknowledgement 。
2.重传机制/重传策略
重传机制:在网络通信中,由于网络拥塞、传输错误、信号干扰或硬件故障等原因,数据包可能会丢失或损坏。重传机制指的是当发送方发送数据包到接收方时,如果接收方没有正确接收到数据包,或者发送方未收到接收方的确认消息,发送方会重新发送该数据包,直到接收方正确接收到为止的整个过程。比如在 TCP 协议中,发送方发送数据后会等待接收方的确认应答(ACK),若未在规定时间收到,就会重传数据 。它有效解决了数据传输的不确定性,是保障网络通信可靠性的关键措施。
重传策略 :为了更高效、合理地实现重传,衍生出了多种重传策略,常见的如下:
①超时重传:发送方发送数据包后启动一个定时器,设定一个重传超时时间(RTO)。如果在 RTO 内没有收到接收方的确认消息,就认为数据包丢失,需要重新发送。比如固定 RTO 超时重传,在发送前设定一个固定的 RTO;动态 RTO 超时重传则会根据网络情况等因素调整 RTO
②快速重传:不是基于时间,而是基于重复确认的重传机制。当发送方连续收到多个(如三个或四个)重复的确认消息时,就认为在之前的传输中可能有数据包丢失,立即重传疑似丢失的数据包,无需等待 RTO 超时,减少重传延迟,提高网络传输效率 。
③选择性确认重传(SACK) :接收端在确认应答中会指定哪些数据包已经收到,哪些还没收到,发送端根据这些信息,有选择地重传丢失的数据,而不是重传所有可能丢失的数据,提升传输效率。
④重复选择性确认重传(D - SACK):接收端通过该策略告知发送方哪些数据包是重复接收的,发送端可据此判断哪些数据包需要重传,能有效处理 ACK 丢失、网络延时等导致的误判重传情况,减少多余的网络传输
3.序号机制
序号机制是一种通过为数据单元(如数据包、消息、文件块等)分配唯一编号,来管理数据传输顺序、确保完整性和可靠性的机制,广泛应用于网络通信、分布式系统等领域。
4.重排机制
重排机制是一种处理数据单元顺序的机制,用于解决数据在传输或处理过程中出现的乱序问题,确保数据按正确逻辑顺序被处理
5.窗口机制 流量控制 带宽有限
窗口机制、流量控制与带宽有限性是网络通信中相互关联的关键概念,共同作用于数据传输的效率与稳定性。
窗口机制
定义
发送方在未收到接收方确认(ACK)的情况下,可连续发送的数据量上限,通常以 “窗口大小” 表示。例如,TCP 中的滑动窗口允许发送方在等待 ACK 时持续发送多个数据包。
作用
提升效率:通过 “流水线” 式传输减少等待时间,充分利用带宽。
流量控制基础:窗口大小由接收方的处理能力(接收缓冲区)和网络状况动态调整。
流量控制
定义:接收方通过限制发送方的发送速率,防止自身因处理速度或缓冲区不足导致数据丢失。
与窗口机制的结合:
接收窗口(Advertised Window):接收方在 ACK 中告知发送方当前可用的最大窗口大小。例如,接收方缓冲区剩余 10KB,则窗口大小为 10KB,发送方最多发送 10KB 数据后需等待新 ACK。
动态调整:当接收方处理能力下降时(如缓冲区占用过高),通过缩小窗口大小降低发送速率;反之则扩大窗口。
带宽有限性的挑战
问题:当网络带宽不足以承载发送方的发送速率时,会导致拥塞(数据包丢失、延迟增加)。
窗口机制与流量控制的应对:
避免拥塞:通过窗口大小限制发送速率,使其不超过网络的实际承载能力。例如,若带宽为 10Mbps,RTT 为 100ms,则理论上窗口大小需至少为 (10Mbps × 0.1s) = 1.25MB(带宽延迟积)才能充分利用带宽,过大则可能引发拥塞。
自适应调整:TCP 通过拥塞控制算法(如慢启动、拥塞避免)动态调整窗口大小。当检测到丢包时,窗口减半以降低速率;当网络空闲时,逐渐增加窗口以探测可用带宽。
三者的协同关系
目标:在带宽有限的环境下,平衡可靠性与效率。
流程示例:
发送方初始以较小窗口试探网络(慢启动)。
接收方根据自身处理能力通告窗口大小(流量控制)。
网络根据拥塞情况隐式反馈(如延迟或丢包),发送方调整窗口(拥塞控制)。
最终窗口大小稳定在 min (接收窗口,拥塞窗口),确保不超出接收方能力和网络带宽。
二 UDP和TCP之间爱恨情仇以及新兴的KCP协议!
1.udp和tcp我们应该如何选择
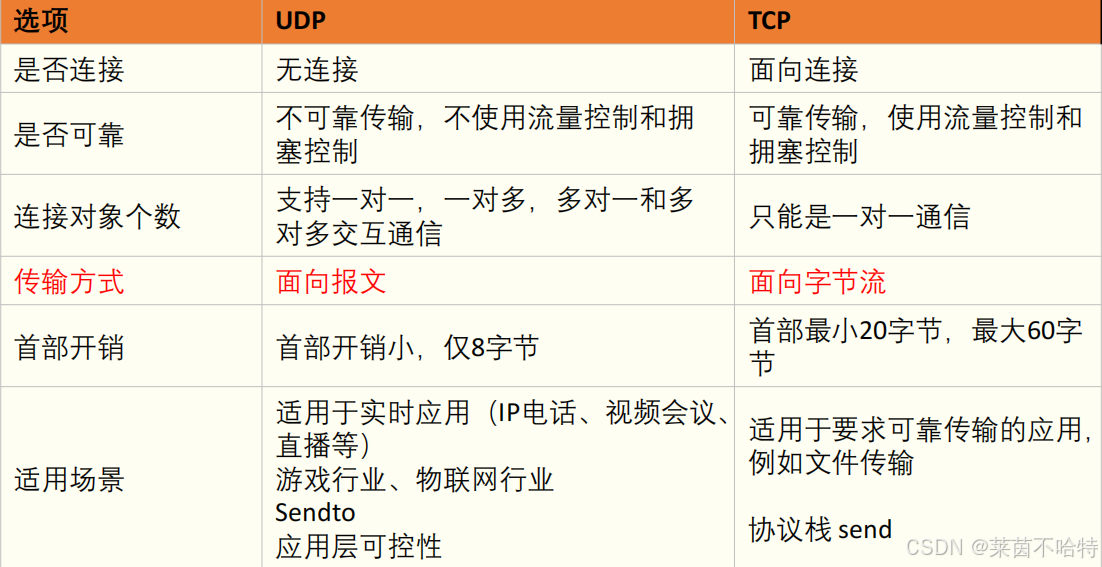
2.udp和tcp的格式对比

3.1 ARQ协议
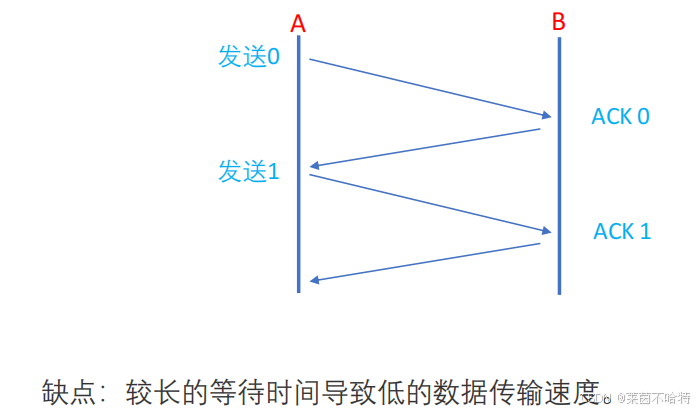
3.2 ARQ协议---停等式
3.3 ARQ协议---回退帧
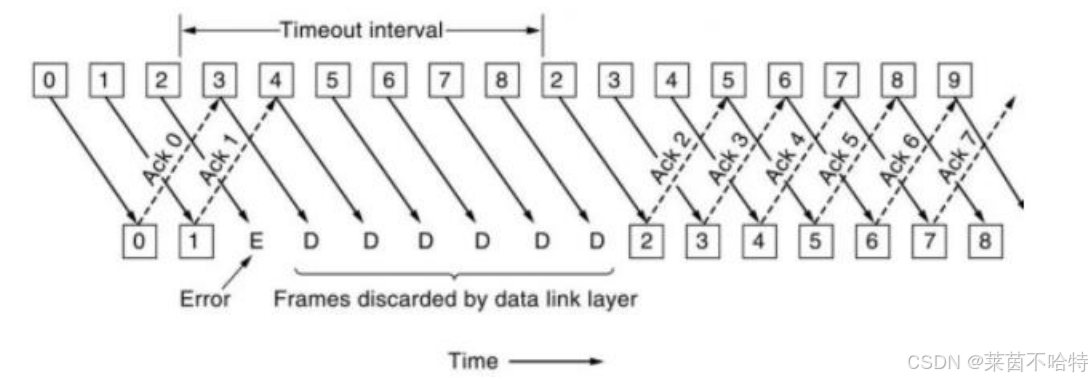
3.4ARQ协议---回退n帧
3.5ARQ协议---选择重传
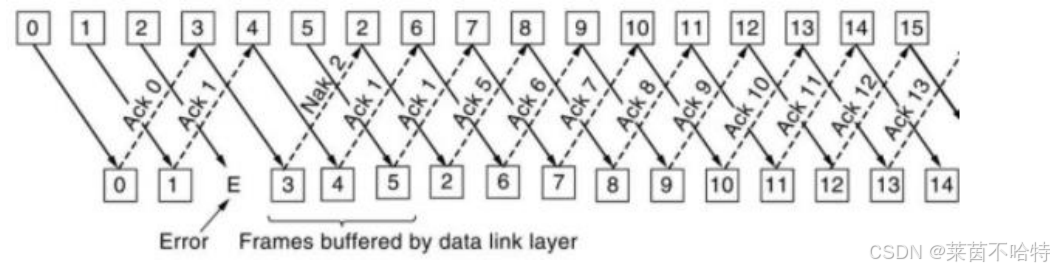
4.1 RTT和RTO

4.2 流量控制
4.3 如何做到流量控制
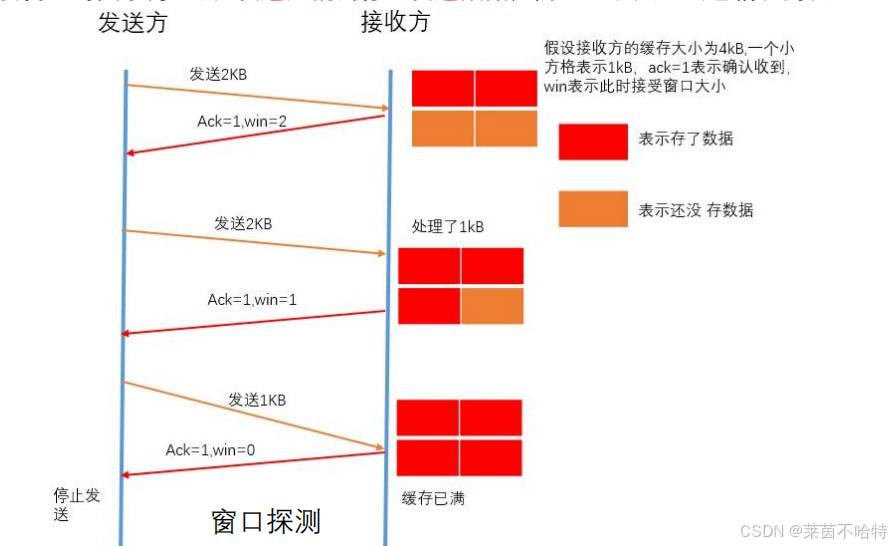
4.4 发送方何时再继续发送数据
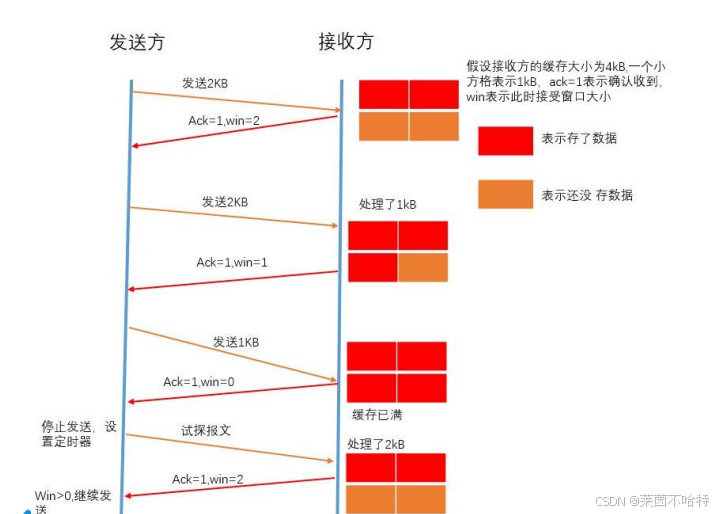
4.5 流量控制小结
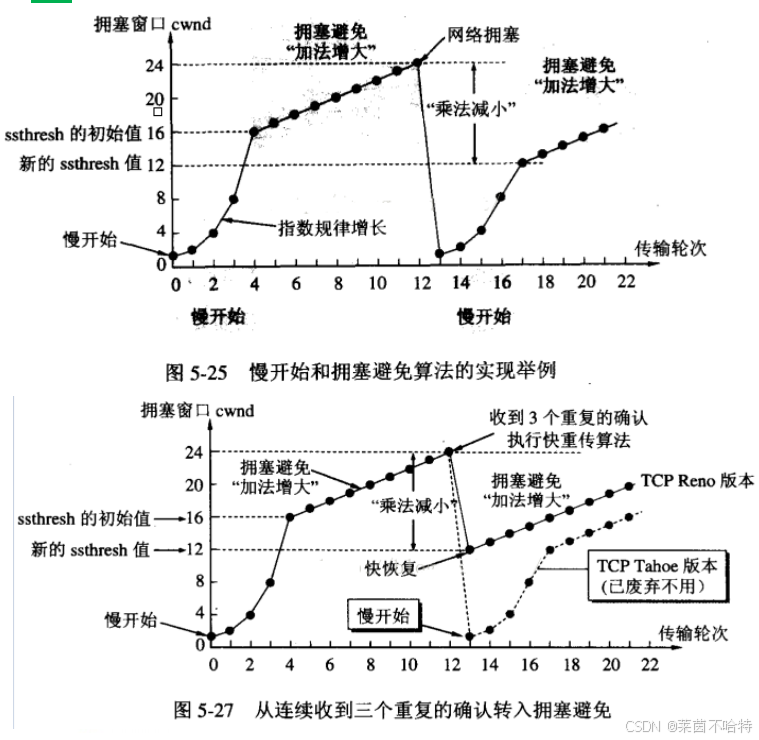
5 拥塞控制
6 .1 udp编程模型
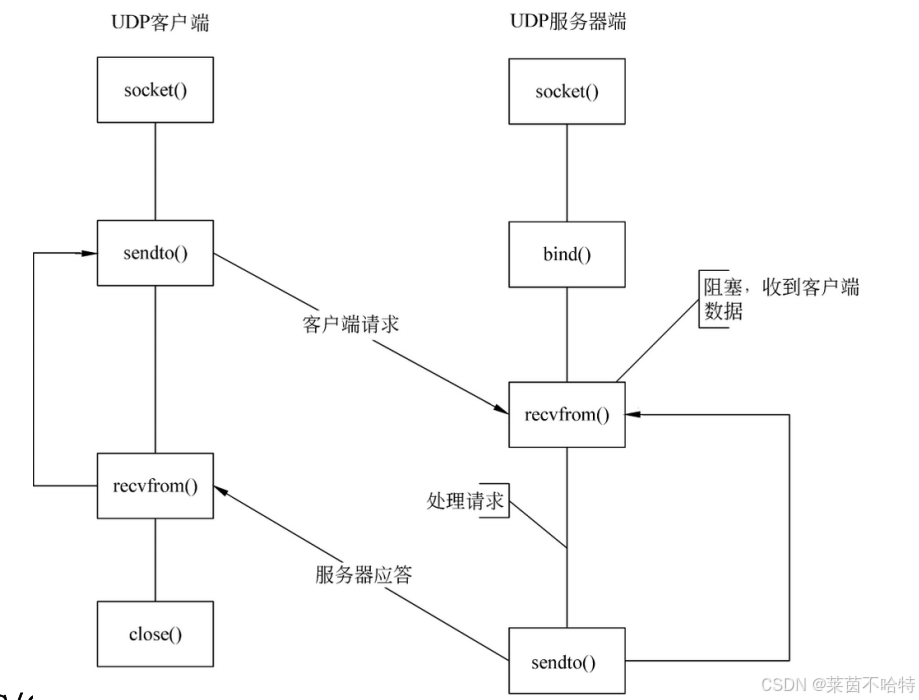
6.2 udp并发编程
自己找源码
6.3 udp如何才能做到可靠,kcp协议在哪些方面上有优势

6.4 UDP如何可靠,KCP协议在哪些方面有优势2
7.1 牛逼的KCP协议
7.2 如何使用KCP协议
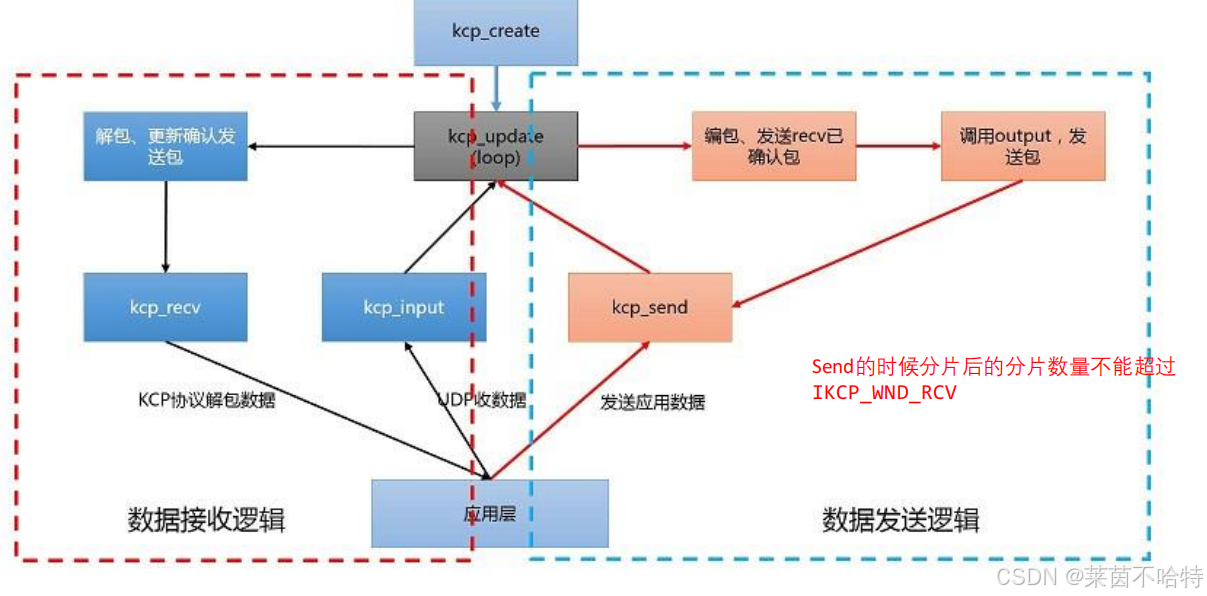
7.3 KCP源码流程图
7.4 KCP的配置方式
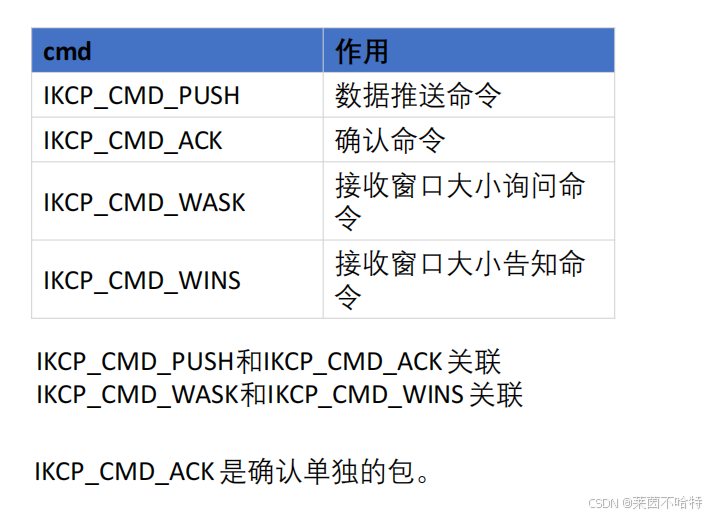
7.5 KCP协议头

7.6 KCP发送数据过程
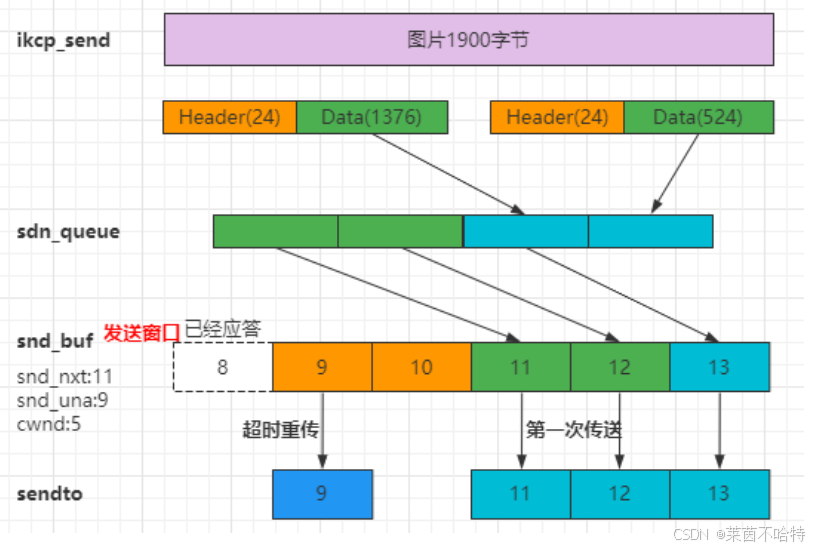
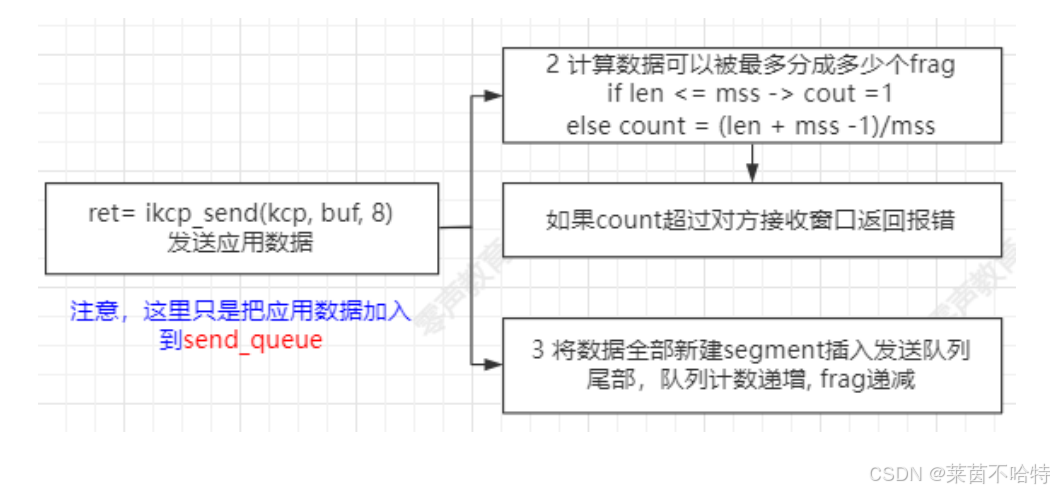
7.7 kcp发送窗口
// calculate window size 取发送窗口和远端窗口最小值得到拥塞窗口小
cwnd = _imin_(kcp->snd_wnd, kcp->rmt_wnd); // 当rmt_wnd为0的时候,
// 如果做了流控制则取配置拥塞窗口、发送窗口和远端窗口三者最小值
if (kcp->nocwnd == 0) cwnd = _imin_(kcp->cwnd, cwnd); // 进一步控制cwnd大小, kcp->cwnd拥塞窗口
// kcp->nocwnd = 1 少了一次_imin_的判断,可以尽量多发送数据
// move data from snd_queue to snd_buf
// 从snd_queue移动到snd_buf的数量不能超出对方的接收能力 此时如果
// 发送那些符合拥塞范围的数据分片
// kcp->snd_una = 10
// cwnd = 3
//
while (_itimediff(kcp->snd_nxt, kcp->snd_una + cwnd) < 0) {
IKCPSEG *newseg;
if (iqueue_is_empty(&kcp->snd_queue)) break;
// 从snd_queue读取segment
newseg = iqueue_entry(kcp->snd_queue.next, IKCPSEG, node);
iqueue_del(&newseg->node);
// 插入到snd buf 发送窗口
iqueue_add_tail(&newseg->node, &kcp->snd_buf); // 从发送队列添加到发送缓存
kcp->nsnd_que--;
kcp->nsnd_buf++;
//设置数据分片的属性
newseg->conv = kcp->conv;
newseg->cmd = IKCP_CMD_PUSH;
newseg->wnd = seg.wnd; // 告知对方当前的接收窗口
newseg->ts = current; // 当前时间
newseg->sn = kcp->snd_nxt++; // 序号
newseg->una = kcp->rcv_nxt; // 告诉对方可以发送的下一个包序号
newseg->resendts = current; // 当前发送的时间
newseg->rto = kcp->rx_rto; // 超时重传的时间, 重传间隔的时间
newseg->fastack = 0; // 是否快速重传
newseg->xmit = 0; // 重传次数
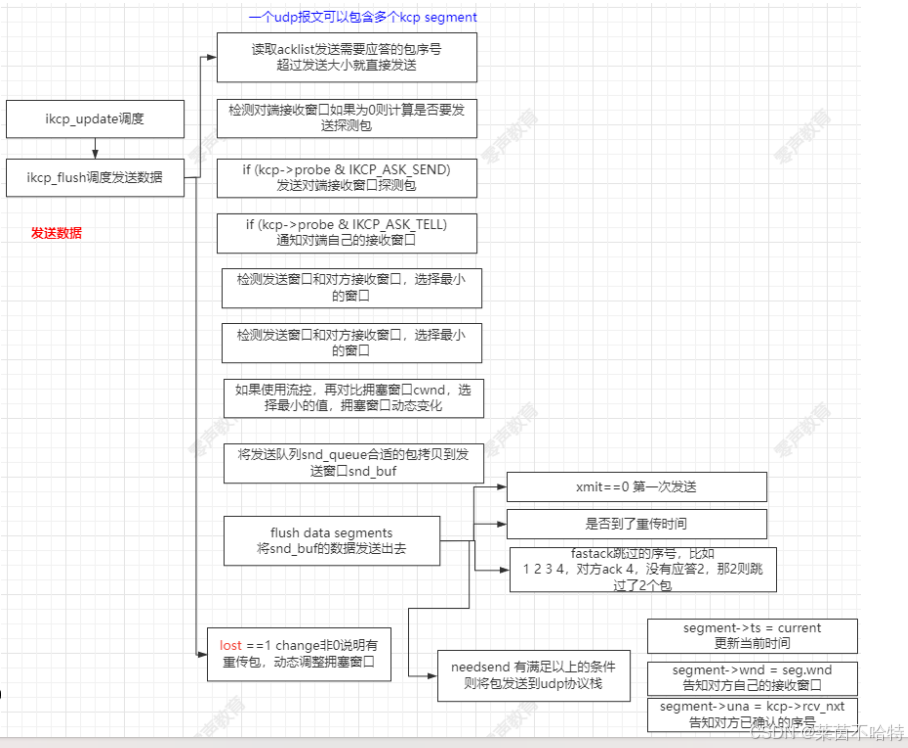
}7.8 kcp 接收数据过程
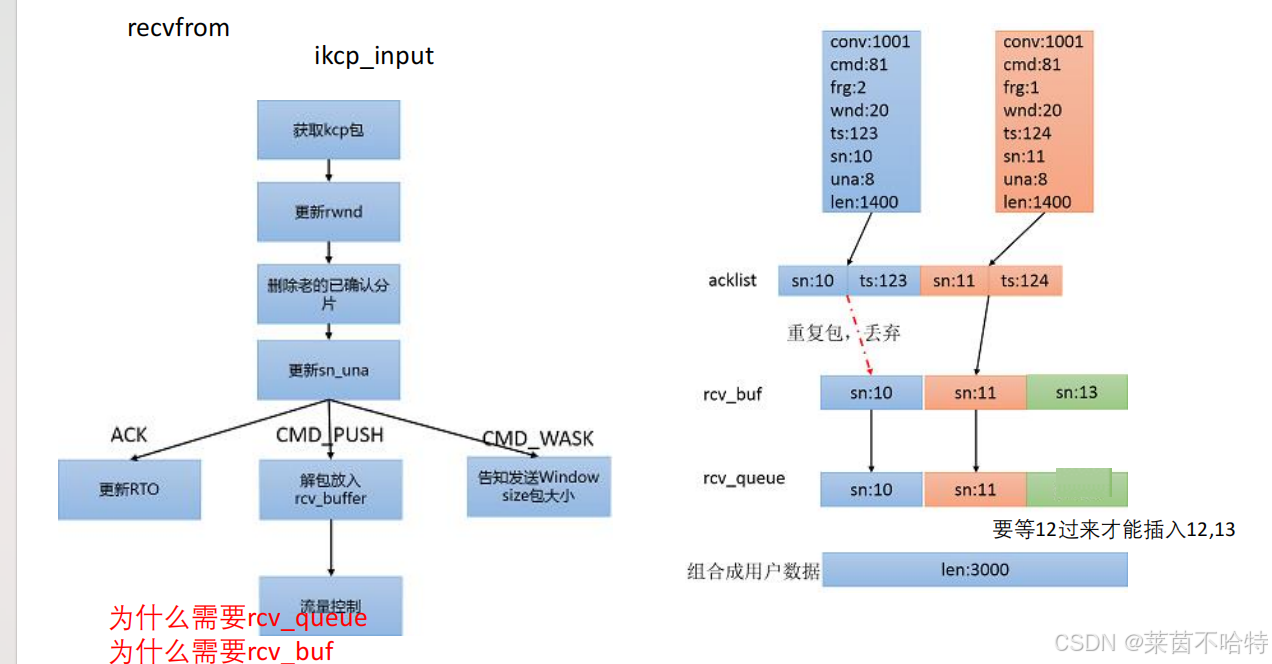 7.9接收窗口
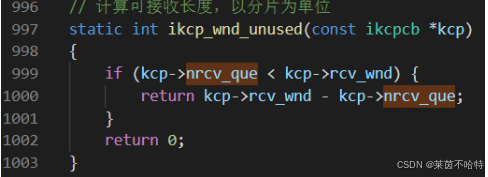
7.9接收窗口
7.10KCP确认包处理流程
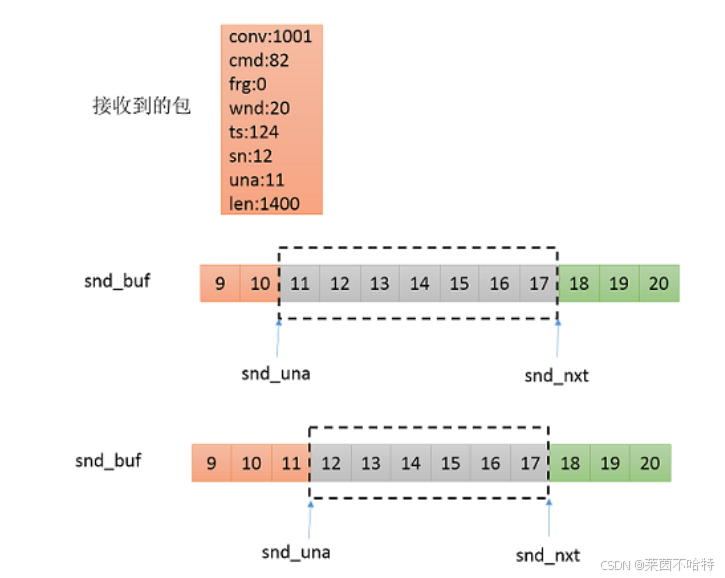
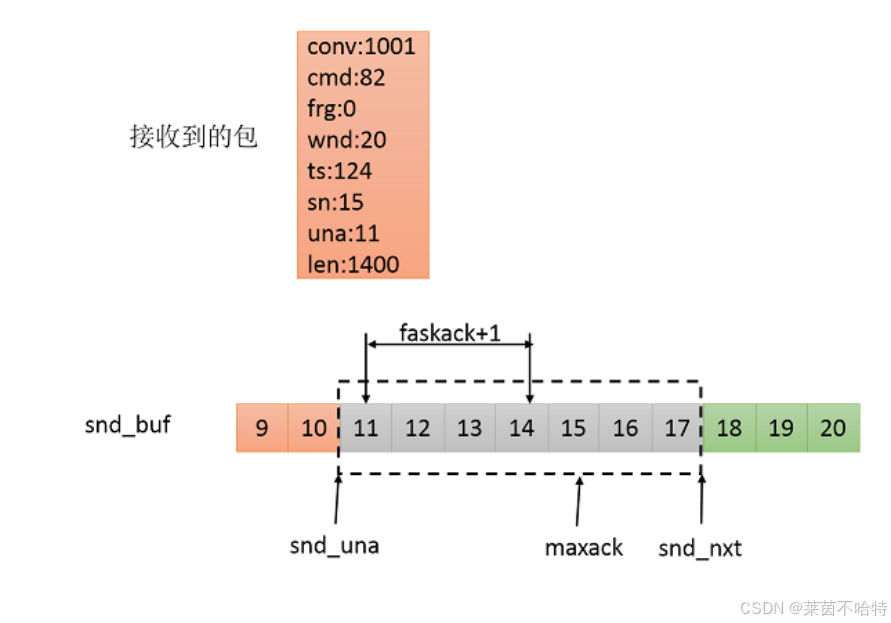
7.11 kcp快速确认
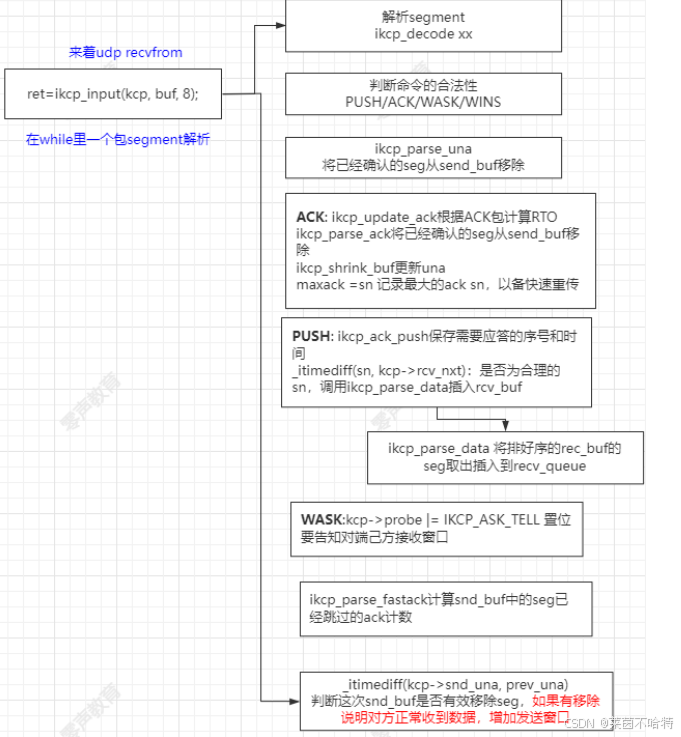
7.12 ikcp_inp
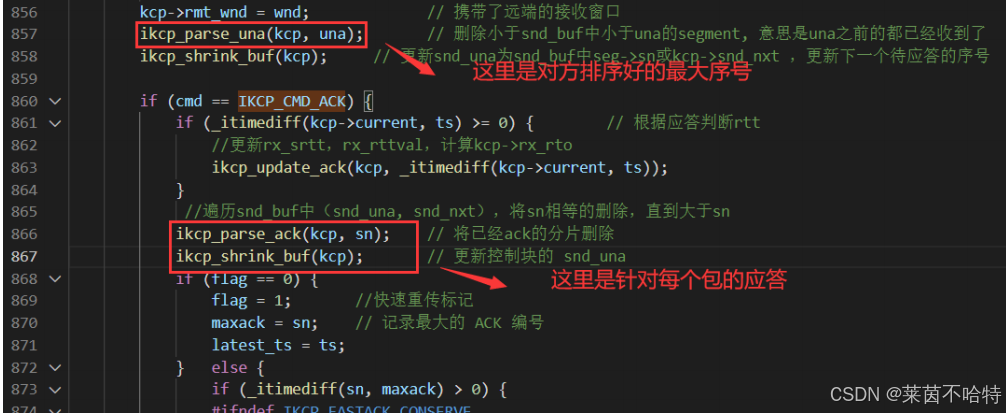
7.13 应答列表acklist
7.14 流量控制和拥塞控制
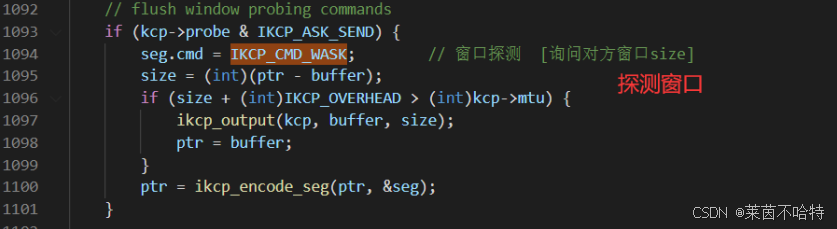
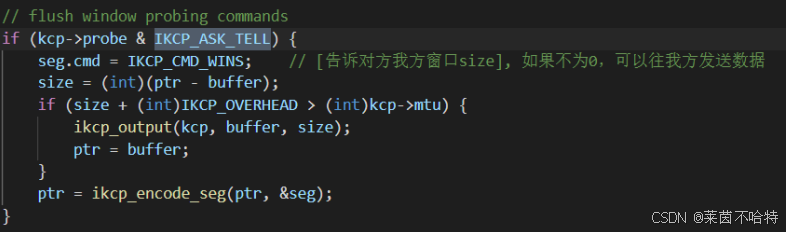
7.15 探测对方接收窗口
三 在项目中集成KCP协议栈!
1. 范例演示
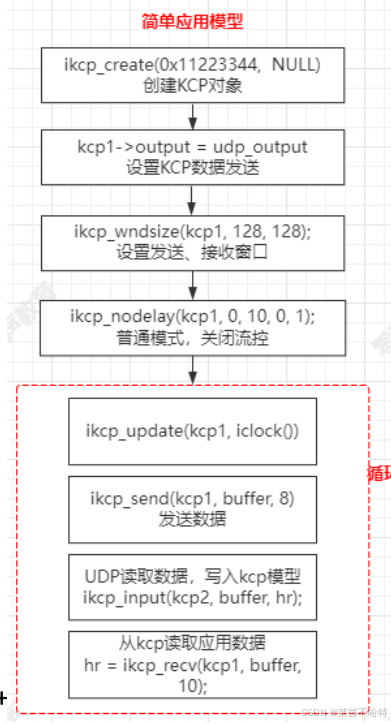
2 如何集成到项目中,参考代码的chat_server.cc和chat_client.cc两个代码实现聊天室功能
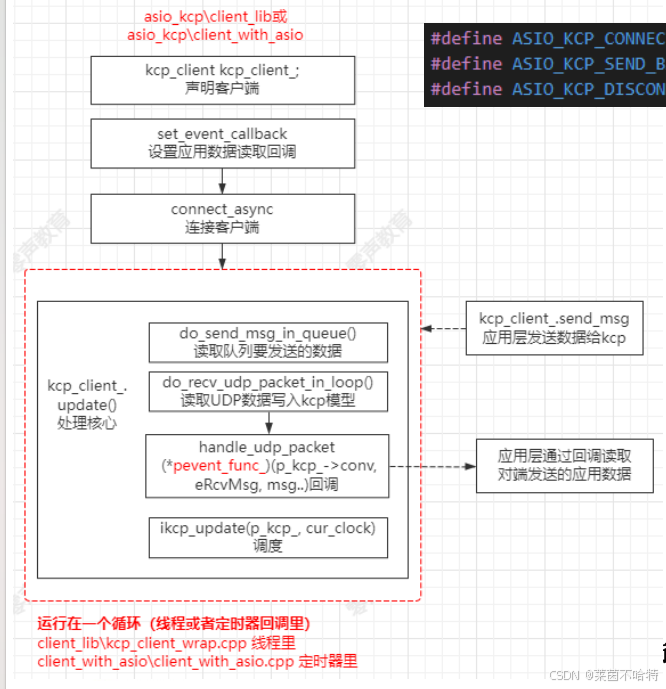
3. 如何集成到项目中,参考asio_kcp

四 QUIC协议
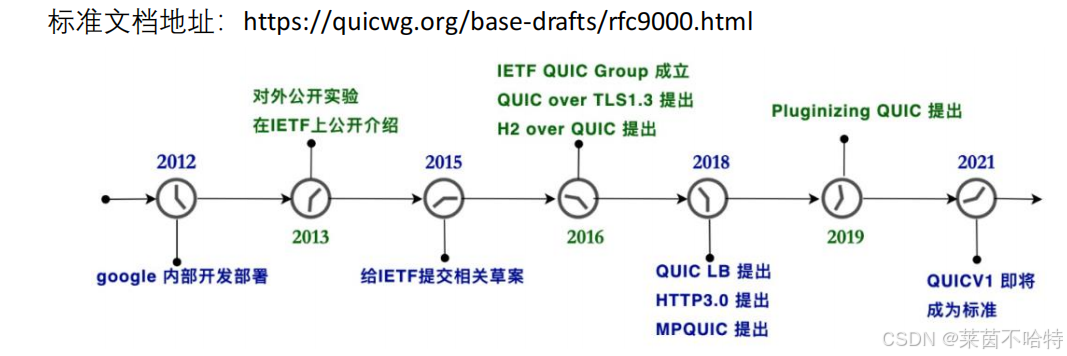
1.QUIC前世今生
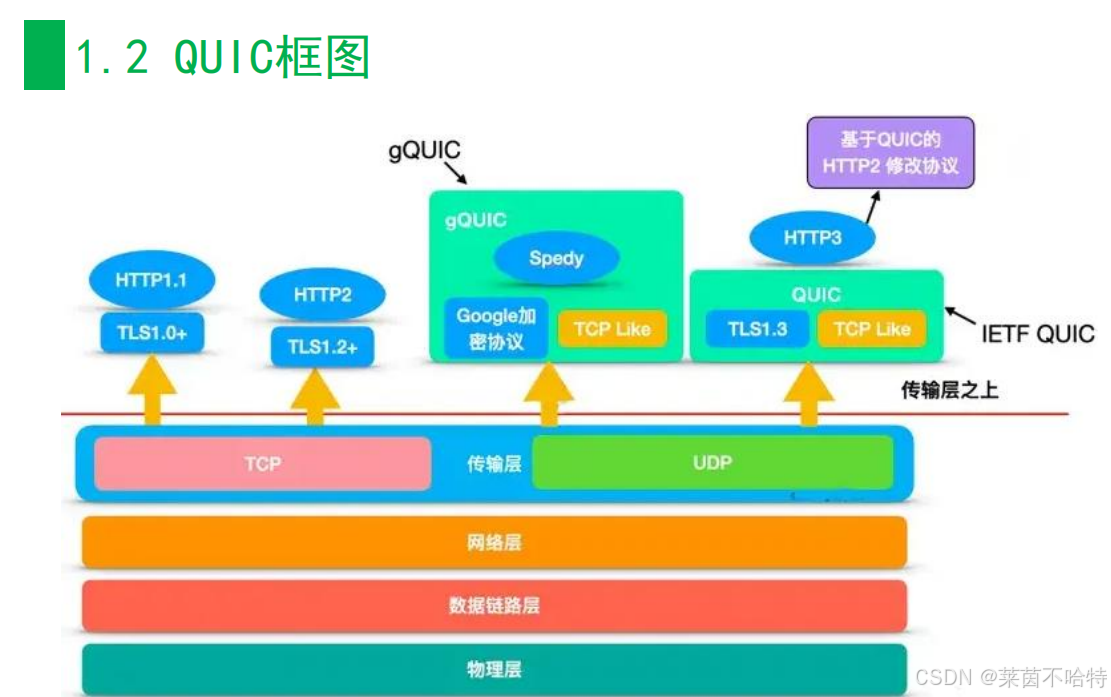
2.QUIC为什么在应用层实现
3.QUIC协议术语
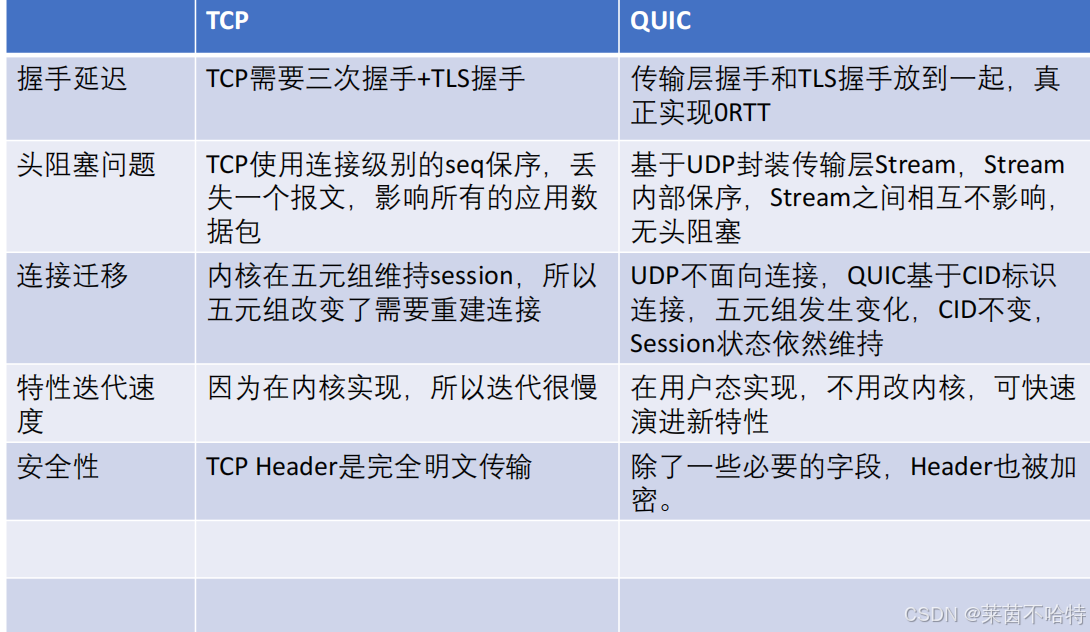
4.QUIC和TCP对比
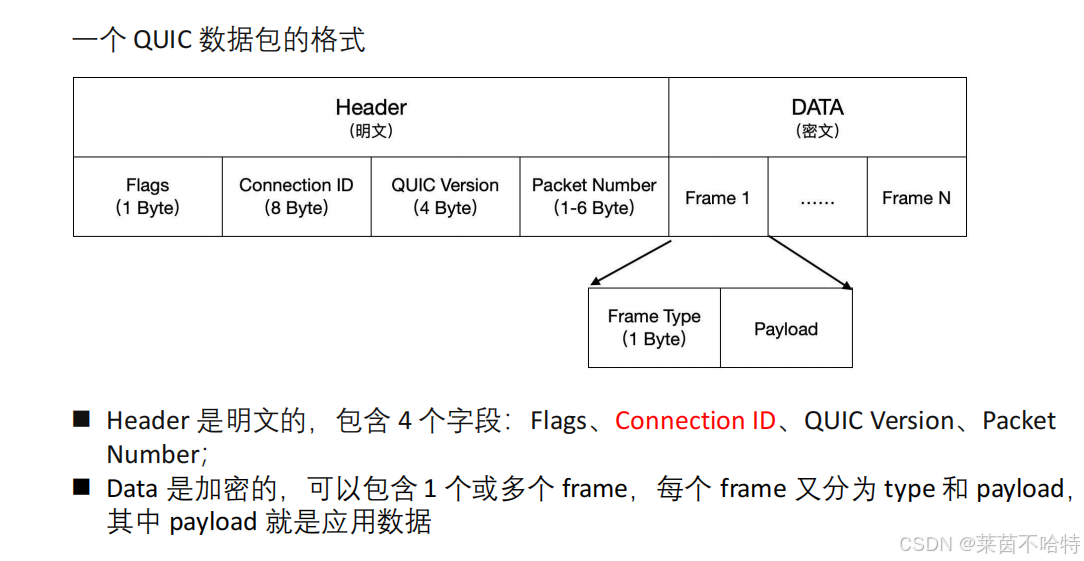
5.QUIC报文格式
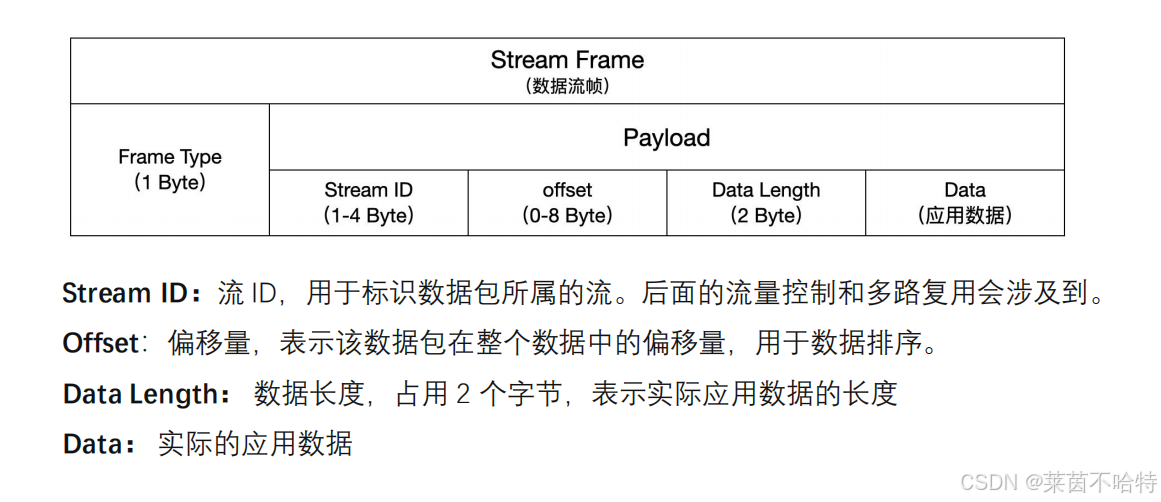
6.QUIC报文格式-Stream帧1
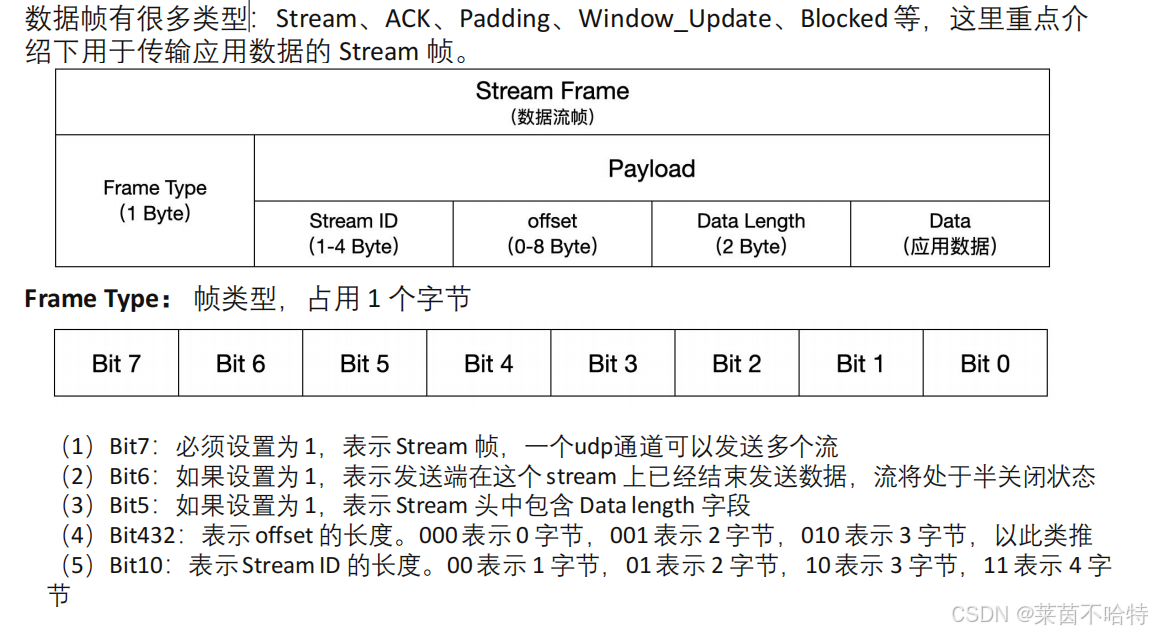
7.QUIC报文格式-Stream帧2