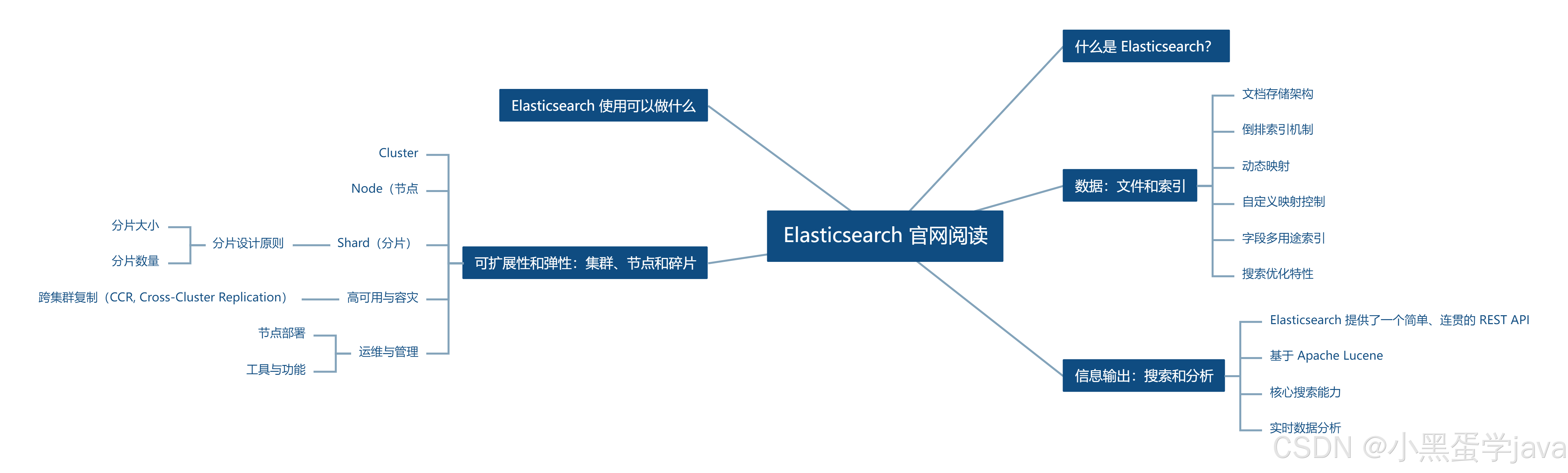
Elasticsearch 官网阅读学习笔记01
-
什么是 Elasticsearch?
- Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。
- Elasticsearch 可为所有类型的数据提供近乎实时的搜索和分析。无论您拥有的是结构化或非结构化文本、数值数据还是地理空间数据
-
Elasticsearch 使用可以做什么
- 在应用程序或网站中添加搜索框
- 存储和分析日志、指标和安全事件数据
- 使用 Elasticsearch 作为存储引擎,实现业务工作流程自动化
- 将 Elasticsearch 作为地理信息系统 (GIS) 来管理、整合和分析空间信息
-
数据:文件和索引
-
关键内容提取
-
Elasticsearch 是一种分布式文档存储。Elasticsearch 存储的是序列化为 JSON 文档的复杂数据结构,而不是以列数据行的形式存储信息
-
文档存储后,会在 1 秒钟内编制索引并进行完全实时搜索Elasticsearch 使用一种称为倒排索引的数据结构,支持非常快速的全文检索
-
索引可以看作是文档的优化集合,而每个 文档又是字段的集合 ,即包含数据的键值对
-
Elasticsearch 会为每个字段中的所有数据建立索引,每个索引字段都有一个专用的优化数据结构。
- 文本字段存储在倒排索引中
- 数字和地理字段存储在 BKD 树中
-
启用动态映射后,Elasticsearch 会自动检测新字段并将其添加到索引中
-
定义映射可以作什么
- 区分全文字符串字段和精确值字符串字段
- 进行特定语言的文本分析
- 优化字段以进行部分匹配
- 使用自定义日期格式
- 使用 geo_point(用于存储单个地理坐标点(经纬度),例如:一个商店的位置、用户的实时坐标等。 适合场景:快速查询“附近的地点”、计算两点距离、聚合地理位置数据。) 和 geo_shape (用于存储复杂的地理形状(如多边形、线、圆形等),例如:国家边界、配送区域、地理围栏。 适合场景:判断地理空间关系(如“某个点是否在某个区域内”或“两个区域是否相交”)。)等无法自动检测的数据类型
-
-
总结:
-
文档存储架构
- 分布式文档存储,数据以序列化JSON文档形式存储
- 支持跨节点分布式存储,数据可被集群内任意节点实时访问
- 近实时搜索(1秒内完成索引)
-
倒排索引机制
-
核心数据结构支持快速全文搜索
-
通过记录单词与文档的映射关系实现快速检索
-
所有字段默认被索引,不同字段类型使用不同数据结构:
- 文本字段 → 倒排索引
- 数值/地理位置 → BKD树
-
-
动态映射(Schema-less)
- 自动检测字段类型(布尔值、数值、日期、字符串等)
- 自动添加新字段到索引
- 适合快速探索数据的场景
-
自定义映射控制
-
可覆盖自动映射规则,实现更精确控制:
- 区分全文检索(text)与精确值(keyword)字段
- 执行语言特定的文本分析
- 优化部分匹配
- 自定义日期格式
- 支持特殊类型(geo_point/geo_shape)
-
-
字段多用途索引
-
持同一字段不同索引方式:
- 文本字段同时用于全文搜索和排序/聚合
- 多语言分析器处理混合语言内容
-
索引和分析链在查询时保持一致
-
-
搜索优化特性
- 查询文本会经过与索引时相同的分析处理
- 字段级数据结构优化查询性能
- 支持复杂数据类型的地理空间查询
-
-
-
信息输出:搜索和分析
-
基于 Apache Lucene 搜索引擎库的全套搜索功能。
-
Elasticsearch 提供了一个简单、连贯的 REST API,用于管理集群以及索引和搜索数据
-
简短说明 REST请求 RESTful 风格
-
资源导向 : 所有数据/服务抽象为资源,通过URI唯一标识 示例:
/users/123 表示ID为123的用户资源 -
HTTP方法映射操作
-
通过标准HTTP方法实现CRUD:
-
GET → 获取资源 -
POST → 创建资源 -
PUT → 更新资源 -
DELETE → 删除资源
-
-
-
-
说明应用程序可以通过简单网络请求获取到数据
-
Elasticsearch 客户端:Java、JavaScript、Go、.NET、PHP、Perl、Python 或 Ruby
-
-
数据搜索
-
Elasticsearch REST API 支持结构化查询、全文本查询以及将二者结合起来的复杂查询
- 结构化查询类似于在 SQL 中构建的查询类型。例如,您可以搜索 employee 索引中的 gender 和 age 字段,并根据 hire_date 字段对匹配结果进行排序
- 全文查询可查找与查询字符串匹配的所有文档,并按相关性(即与搜索条件的匹配程度)排序返回。
-
支持 支持高性能地理和数值查询。
-
查询方式
- Elasticsearch 的综合 JSON 风格查询语言( 查询 DSL )访问所有这些搜索功能
- 内部构建 SQL 风格 的查询
- JDBC 和 ODBC 驱动程序可让大量第三方应用程序通过 SQL 与 Elasticsearch 进行交互。
-
-
分析数据
- 概述 : Elasticsearch 聚合使您能够建立复杂的数据摘要,并深入了解关键指标、模式和趋势
-
总结:
- 核心搜索能力
- 支持结构化查询(类SQL)与全文搜索(基于相关性排序)
- 提供短语搜索、模糊匹配、前缀搜索及自动补全功能
- 专为地理空间/数值数据优化,支持高性能地理查询
- 提供Query DSL(JSON风格)和SQL双查询模式
- 支持JDBC/ODBC驱动实现第三方工具集成
- 实时数据分析
- 聚合分析功能可生成多维数据洞察:
▪ 统计聚合(数量/平均值/中位数)
▪ 时间趋势分析(如按月统计)
▪ 制造商分布等商业洞察 - 搜索与聚合在单请求中同步执行
- 分析结果实时更新,支持动态数据可视化
-
-
可扩展性和弹性:集群、节点和碎片
核心概念
-
Cluster(集群)
- 分布式架构,支持横向扩展和高可用性。
- 自动分配数据和查询负载到所有节点。
- 节点增减时自动重平衡分片(Shard)分布。
-
Node(节点)
- 集群中的单个服务器,可动态加入或移除。
- 节点越多,集群容量和查询能力越强(冗余性提升)。
-
Shard(分片)
-
逻辑索引(Index)由多个物理分片组成。
-
分片分为两类:
- Primary Shard(主分片) :存储文档的唯一副本,数量在索引创建时固定。
- Replica Shard(副本分片) :主分片的冗余副本,提供数据保护和读请求负载均衡,数量可动态调整。
-
分片分布在多个节点上,实现冗余和性能优化。
-
2. 分片设计原则
-
分片大小
- 推荐范围:几GB到几十GB(时间序列数据建议20-40GB)。
- 过大问题:集群重平衡时迁移时间变长。
- 过小问题:维护开销高(如大量小分片导致查询性能下降)。
-
分片数量
- 主分片数:索引创建时确定,不可修改。
- 副本分片数:可随时调整,不影响读写操作。
- 分片与堆内存关系:每GB堆内存建议不超过20个分片(避免“海量分片”问题)。
- 测试验证:需根据实际数据和查询场景测试最佳配置。
3. 高可用与容灾
-
跨集群复制(CCR, Cross-Cluster Replication)
-
作用:主集群(Active Leader)到备用集群(Passive Follower)的热备份,支持故障转移和地理邻近读请求。
-
模式:
- 主集群处理写请求,副本集群只读。
- 主集群故障时,副本集群可接管。
-
4. 运维与管理
-
节点部署
- 节点间需高可靠、低延迟连接(建议同数据中心或邻近数据中心)。
- 避免单点故障(多区域部署需结合CCR)。
-
工具与功能
- Kibana:集群管理控制中心,集成安全、监控、管理功能。
- 索引生命周期管理:自动管理数据(如滚动更新、归档)。
- 数据汇总(Rollups) :优化历史数据存储与查询效率。
-