FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents”

自动化交易代理利用强化学习(RL)越来越普遍,但常忽略两个方面:一是整合如金融新闻等另类数据源;二是风险管理。本文提出一种新型混合RL-LLM交易代理,结合金融新闻洞察于行动和风险层面。使用FNSPID数据集的金融新闻数据以及DeepSeek V3、Qwen 2.5和Llama 3.3语言模型在纳斯达克-100指数基准上进行回测。

摘要
本文提出了一种结合强化学习和大型语言模型(LLM)的风险敏感交易代理。扩展了条件风险价值(Conditional Value-at-Risk Proximal)的近端策略优化(CPPO)算法,增加了由LLM生成的风险评估和交易建议信号。在纳斯达克100指数基准上进行回测,使用FNSPID数据集的金融新闻数据。应用DeepSeek V3、Qwen 2.5和Llama 3.3语言模型。
简介
自动交易代理利用强化学习(RL),但常忽视金融新闻等替代数据源的整合和风险管理。本文提出一种新型混合RL-LLM交易代理,结合金融新闻洞察于行动和风险层面。主要贡献是引入基于LLM的风险评估分数和交易建议,展示LLM在新闻特征提取中的潜力,超越标准情感分析,通过精心设计的提示实现。
相关工作
LLM增强的RL代理研究逐渐增多,当前方法相对简单。FinGPT将RL应用于LLM的股票价格训练,复杂度高于本研究,后者利用现有LLM API。其他混合RL-LLM方法如FinCon通过多智能体协作机制进行复杂信息提炼,本研究仅使用简单提示。与“纯LLM”代理不同,后者仅依赖LLM推荐。
数据和LLM提示
使用FNSPID数据集,包含1999-2023年间1570万条时间对齐的金融新闻记录。为降低LLM API成本,随机选择每只股票每天一篇代表性新闻,减少至200万条记录。
利用LLM(DeepSeek V3, Qwen 2.5 72B, Llama 3.3 70B)提取股票推荐和风险评估。我们使用以下提示提取股票建议和风险评估:
股票推荐提示
”You are a financial expert with stock recom-mendation experience. Based on a specific stock,score for range from 1 to 5, where 1 is negative, 2is somewhat negative, 3 is neutral, 4 is somewhatpositive, 5 is positive”
风险评估提示
”You are a financial expert specializing in risk as-sessment for stock recommendations. Based ona specific stock, provide a risk score from 1 to5, where: 1 indicates very low risk, 2 indicateslow risk, 3 indicates moderate risk (default if thenews lacks any clear indication of risk), 4 indi-cates high risk, and 5 indicates very high risk.”
交易算法
仅基于价格数据的强化学习代理
近端策略优化(PPO)
PPO目标通过剪切概率比率确保稳定的策略更新:
![]()
关键要素:
-
r_t(θ):新旧策略的概率比率。
-
A_t:时间t的优势估计。
-
ϵ:限制策略大幅更新的剪切参数。
条件风险价值-近端策略优化(CONDITIONAL VALUE AT RISK-PROXIMAL POLICY OPTIMIZATION, CVAR-PPO)
CVaR-PPO在PPO基础上引入风险约束,惩罚高损失轨迹。目标函数包括PPO目标和CVaR损失,CVaR损失计算公式为:
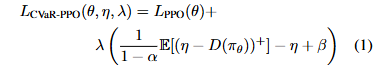
关键参数:
-
L_{PPO}(theta):PPO目标。
-
D(pi_theta):轨迹回报。
-
eta:CVaR阈值。
-
(eta - D(pi_theta))^+:超出阈值的CVaR损失。
-
lambda:强制约束的拉格朗日乘子。
-
alpha:CVaR置信水平(如0.05表示最坏5%)。
-
beta:辅助惩罚参数。
该方法首次应用于股票交易。
LLM-infused PPO
LLM-infused PPO通过FNSPID数据集计算股票推荐分数Sf,影响交易行为。交易行为公式
![]()
-
Sf > 1:正面推荐,放大动作;
-
Sf < 1:负面推荐,减弱动作;
-
Sf = 1:不变。
Sf选择接近1以保持算法稳定性。
-
Sf = 1.1:股票分数5且a t > 0或分数1且a t < 0。
-
Sf = 1.05:股票分数4且a t > 0或分数2且a t < 0。
-
Sf = 0.95:股票分数4且a t < 0或分数2且a t > 0。
-
Sf = 0.9:股票分数5且a t < 0或分数1且a t > 0。
LLM-infused CVaR-PPO(CPPO)
使用FNSPID数据集的金融新闻生成每只股票的风险评分Rif,评分接近1以保持算法稳定。
风险评分分类:
-
Rif = 1.1表示极高风险评分 5;
-
Rif = 1.05表示高风险评分 4;
-
Rif = 1表示中等风险评分 3;
-
Rif = 0.95表示低风险评分 2;
-
Rif = 0.9表示极低风险评分 1;
聚合风险评分定义为:
![]()
其中w i为股票i在投资组合中的权重,且∑w i = 1。
这些评分调整CVaR-PPO中的轨迹收益,以反映市场风险,调整后的收益为
![]()
金融新闻通过 Sf 和 Rf 影响交易行为。
结果
早期停止:400-500k训练步数
在这些测试中,我们使用10%的LLM输注,这意味着原PPO和CPPO达到10%
图1
-
训练周期:2019 - 2022
-
训练迭代:500k步(25个epoch,每个20k步)
-
交易周期:2023
图1与Qwen 2.5的初步结果表明,整合LLM股票推荐在累积收益方面持续提高PPO。然而,到目前为止,它还不足以击败纳斯达克100指数。
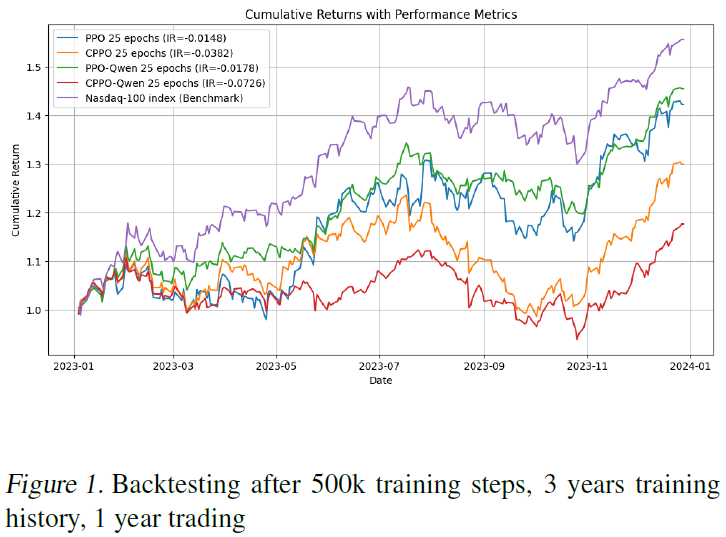
图2
-
训练周期:2013 - 2018
-
训练迭代:400k步(20个epoch,每个20k步)
-
交易周期:2019-2023
对于PPO和cppo进行较长的训练周期(6年vs. 3年),结果显示有显著改善。然而,PPO仍然太不稳定。在其他条件相同的情况下,DeepSeek V3比羊驼3.3稍微好一点。在这个测试中,使用LLM总是会降低性能。
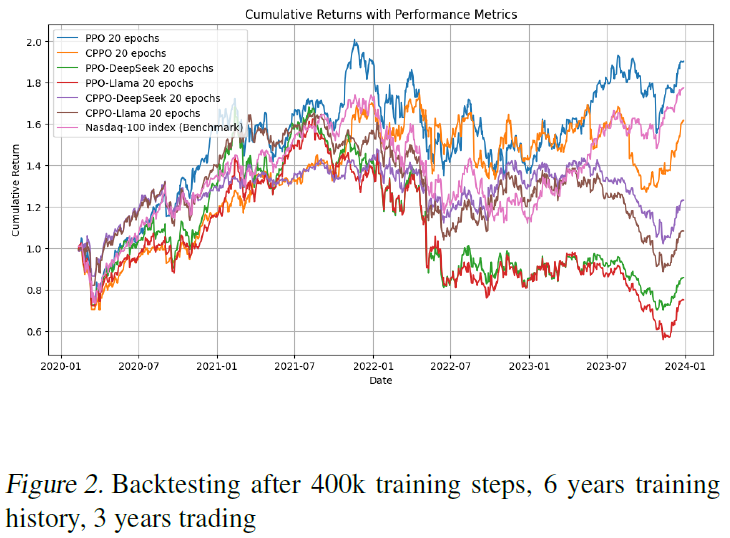
在训练了200万步之后
图3
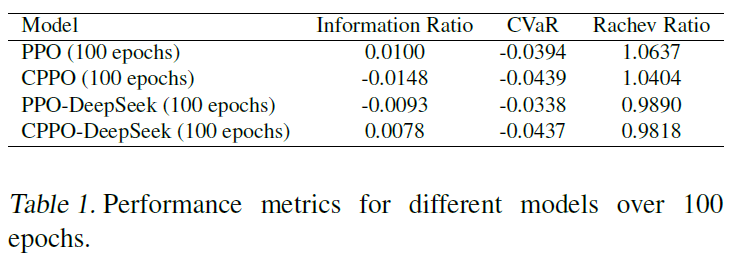
图4
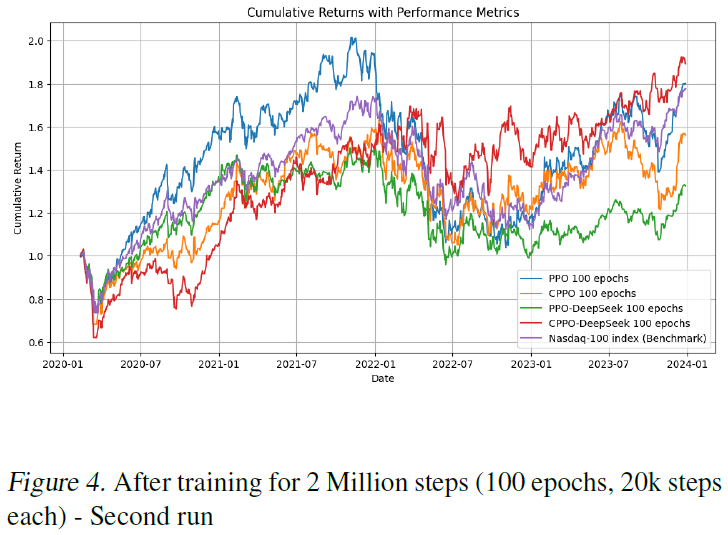
在这两次运行中(RL代理是随机的),PPO和CPPO-DeepSeek优于其他方法,包括纳斯达克100基准。PPO似乎在牛市中表现更好,而CPPO-DeepSeek在熊市中表现更好,过渡时间是在2021年底,在乌克兰战争和随后的危机之前。
LLM注射强度的影响
我们将LLM注入强度参数从10%调整到0.1%(即LLM扰动参数从0.9 - 1.1变化到0.999 - 1.001)。
图5
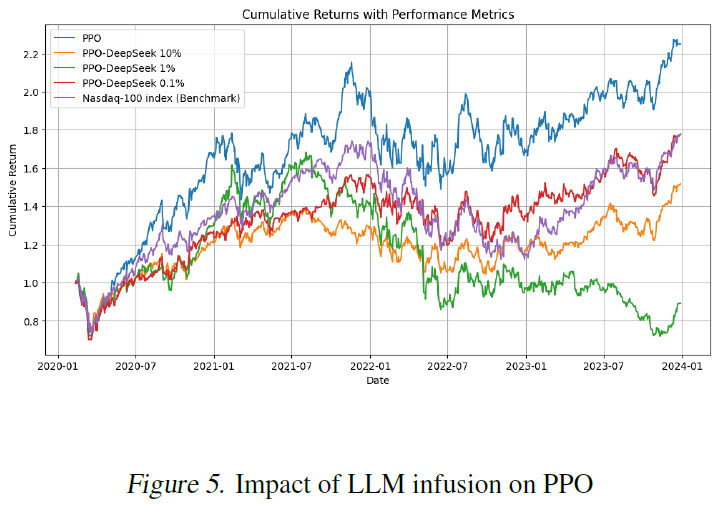
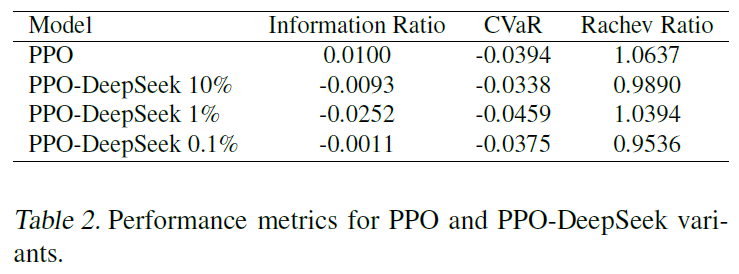
对于PPO-DeepSeek来说,更强的LLM注入大部分会降低性能,即使是微小的(0.1%)扰动。
图6
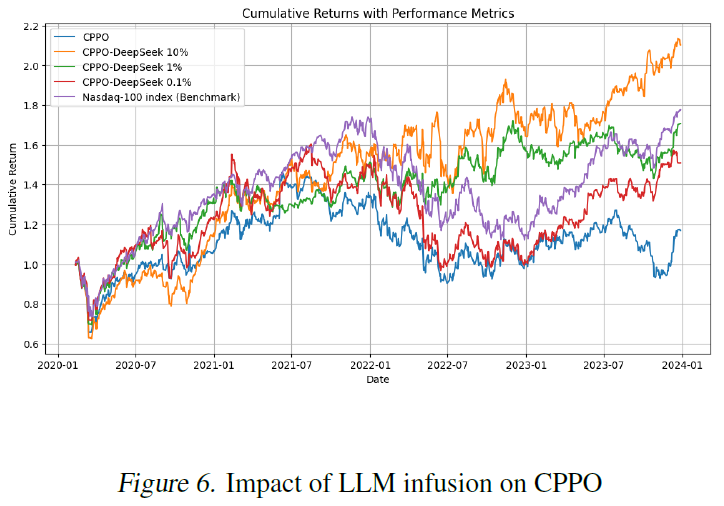
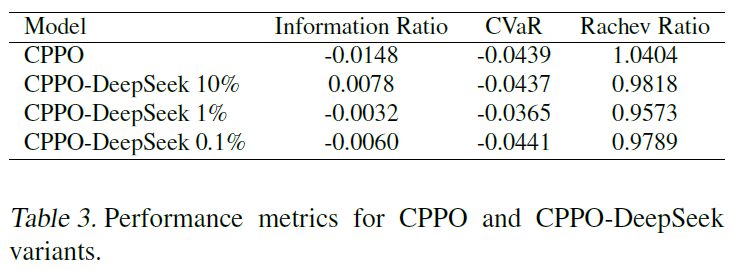
对于CPPO-DeepSeek,更强的LLM注入可以提高性能
总结
本文提出LLM-infused RL代理用于算法交易,结合股票交易建议和新闻风险评估。
未来工作方向:
-
优化RAM使用:长时间训练需更多内存,提升内存效率以实现可扩展性。
-
缩短决策时间:快速反应市场变化以提高交易表现。
-
改善新闻信号质量:提升FNSPID数据集中的新闻信号质量以增强市场表现。
