源码引自《EasyRL》:https://github.com/datawhalechina/easy-rl
【深度强化学习】系列
PPO近端策略优化算法:https://blog.csdn.net/qq_50001789/article/details/145192196
DQN深度Q网络算法:https://blog.csdn.net/qq_50001789/article/details/145186657
DDPG深度确定性策略梯度算法:https://blog.csdn.net/qq_50001789/article/details/145187074
AC演员-评论员算法:https://blog.csdn.net/qq_50001789/article/details/145187443
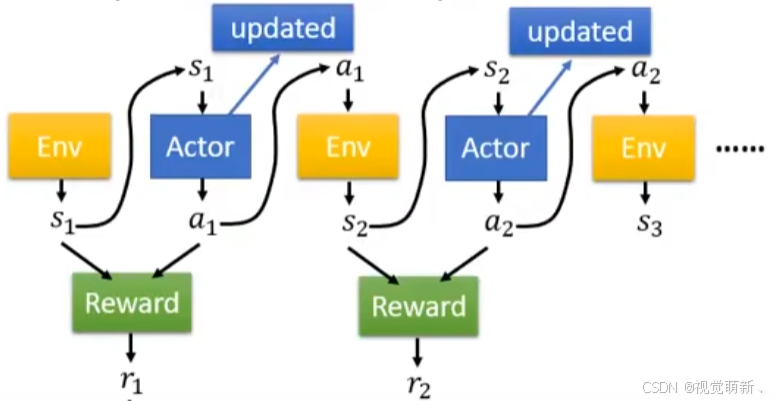
介绍
核心思想:PPO算法(Proximal Policy Optimization)是一种策略学习算法,利用策略函数 V π ( s ) V_\pi(s) Vπ(s)来决策使用哪种动作,通过设计一个奖励函数,让网络朝着最大化奖励的目标的方向来优化网络的参数, 比如在导航任务中,可以利用机器人与目标位置之间距离的倒数充当奖励,用于鼓励机器人不断靠近导航目标点。在实施阶段,我们通常利用奖励值来计算当前动作的优势值 A ( s , a ) A(s,a) A(s,a),用于衡量某个特定动作 a t a_t at相比于当前策略在状态 s t s_t st下的预期回报的优劣,之后利用该优势值来加权每个动作策略的概率分布,充当优化目标。并且通过对策略更新的幅度进行限制,实现稳定且高效的策略优化。
PPO优化目标:
J PPO ( π ) = ∑ ( s t , a t ) p π ( a t ∣ s t ) p π k ( a t ∣ s t ) A π k ( s t , a t ) − β KL ( π , π k ) \begin{aligned} J_{\text{PPO}}(\pi)=\sum_{\left(s_{t}, a_{t}\right)} \frac{p_{\pi}\left(a_{t} \mid s_{t}\right)}{p_{\pi^{k}}\left(a_{t} \mid s_{t}\right)} A^{\pi^{k}}\left(s_{t}, a_{t}\right)-\beta \text{KL}\left(\pi, \pi^{k}\right) \\ \end{aligned} JPPO(π)=(st,at)∑pπk(at∣st)pπ(at∣st)Aπk(st,at)−βKL(π,πk)
PPO2优化目标:
J P P O 2 ( π ) ≈ ∑ ( s t , a t ) min ( p π ( a t ∣ s t ) p π k ( a t ∣ s t ) A π k ( s t , a t ) , clip ( p π ( a t ∣ s t ) p π k ( a t ∣ s t ) , 1 − ε , 1 + ε ) A π k ( s t , a t ) ) \begin{aligned} J_{\mathrm{PPO2}}(\pi) \approx \sum_{\left(s_{t}, a_{t}\right)} \min &\left(\frac{p_{\pi}\left(a_{t} | s_{t}\right)}{p_{\pi^{k}}\left(a_{t} | s_{t}\right)} A^{\pi^{k}}\left(s_{t}, a_{t}\right),\right.\\ &\left.\operatorname{clip}\left(\frac{p_{\pi}\left(a_{t} | s_{t}\right)}{p_{\pi^{k}}\left(a_{t} | s_{t}\right)}, 1-\varepsilon, 1+\varepsilon\right) A^{\pi^{k}}\left(s_{t}, a_{t}\right)\right) \end{aligned} JPPO2(π)≈(st,at)∑min(pπk(at∣st)pπ(at∣st)Aπk(st,at),clip(pπk(at∣st)pπ(at∣st),1−ε,1+ε)Aπk(st,at))
其中 A π k ( s t , a t ) = ∑ t ′ = t T n γ t ′ − t r t ′ k − V θ ( s t ) A^{\pi^{k}}\left(s_{t}, a_{t}\right)=\sum_{t'=t}^{T_n}\gamma^{t'-t}r^k_{t'}-V_\theta(s_t) Aπk(st,at)=∑t′=tTnγt′−trt′k−Vθ(st),上标 k k k表示利用旧参数所采的样本(即利用目标网络采得的样本),PPO中的KL散度用于限制网络参数的更新幅度不能太大,稳定整个训练过程。 V θ ( s t ) V_\theta(s_t) Vθ(st)表示状态函数,用于评估当前状态下的预期回报, ∑ t ′ = t T n γ t ′ − t r t ′ k \sum_{t'=t}^{T_n}\gamma^{t'-t}r^k_{t'} ∑t′=tTnγt′−trt′k表示执行了当前动作后的实际回报,二者作差的结果可以反映当前动作的优劣,之后该目标优化模型,可以让模型的高优势动作的概率越来越大,这也是模型优化参数的核心目的。
注:不用真实的奖励值做加权的原因就在于,优势函数的变化幅度低,方差小,训练更稳定。
注:算法要朝着提高优化目标的方向来优化网络参数,因此如果利用此目标来计算损失,利用梯度下降法来优化参数,那么需要先对优化目标取个负数,当做损失值,这样优化过程中损失不断变低,优化目标不断变大,刚好可以符合我们的预期。
价值函数 V θ ( s ) V_\theta(s) Vθ(s)的优化目标:
L ( θ ) = ∑ t = 1 T n 1 2 ( ∑ t ′ = t T n γ t ′ − t r t ′ n − V θ ( s ) ) 2 L(\theta)=\sum^{T_n}_{t=1}\frac12(\sum_{t'=t}^{T_n}\gamma^{t'-t}r^n_{t'}-V_\theta(s))^2 L(θ)=t=1∑Tn21(t′=t∑Tnγt′−trt′n−Vθ(s))2
更新步骤:
- 初始化决策网络 V π ( s ) V_\pi(s) Vπ(s)以及动作网络 V θ ( s ) V_\theta(s) Vθ(s),面对状态维数过大的情况(如图像),两个网络可以共享特征提取部分的参数
- 遍历每个episodes,假设 t t t为当前的时间步
- 将状态 s t s_t st传入决策函数,得到动作概率分数 p π k ( a t ∣ s t ) p_{\pi^{k}}\left(a_{t}|s_{t}\right) pπk(at∣st)
- 将 ( s t , a t , p π k ( a t ∣ s t ) ) \left(s_t,a_t,p_{\pi^{k}}\left(a_{t}|s_{t}\right)\right) (st,at,pπk(at∣st))存起来,当成利用旧参数所采的样本,用于计算上述公式中带上标 k k k的变量
- 所采的样本数量到达一定程度之后,转入更新步骤,提取之前采得的样本,重新将 s t s_t st传入两个网络,得到新的动作概率分数 p π ( a t ∣ s t ) p_{\pi}\left(a_{t} | s_{t}\right) pπ(at∣st)和状态分数 V θ ( s ) V_\theta(s) Vθ(s),计算损失,优化网络,这一步骤重复 K K K次
注:PPO和A2C算法中的优势函数计算方法类似,但是价值函数所表示的意义不同,PPO中的价值函数用于估计当前状态的基本价值(baseline),为了减小损失方差,而A2C中的价值函数用于衡量动作的积累价值量,因此在计算过程中有点差异,不是完全相同的。
源码实现
训练流程
memory = Memory()
ppo = PPO(state_dim, action_dim, n_latent_var, lr, betas, gamma, K_epochs, eps_clip)
# print(lr,betas)
# logging variables
running_reward = 0
avg_length = 0
timestep = 0
# training loop
for i_episode in range(1, max_episodes + 1):
# 初始化当前任务的状态
state = env.reset()
for t in range(max_timesteps):
timestep += 1
# Running policy_old:
# 利用旧参数执行采样,并且将样本存入memory中
action = ppo.policy_old.act(state, memory)
# 得到新的状态,奖励,是否终止,额外的调试信息
state, reward, done, _ = env.step(action)
# data = env.step(action)
# Saving reward and is_terminal:
memory.rewards.append(reward)
memory.is_terminals.append(done)
# 采到指定数量的样本,转入更新阶段
if timestep % update_timestep == 0:
ppo.update(memory)
memory.clear_memory()
timestep = 0
running_reward += reward
if render:
env.render()
if done:
break
avg_length += t
# stop training if avg_reward > solved_reward
if running_reward > (log_interval * solved_reward):
print("########## Solved! ##########")
torch.save(ppo.policy.state_dict(), './PPO_{}.pth'.format(env_name))
break
# logging
if i_episode % log_interval == 0:
avg_length = int(avg_length / log_interval)
running_reward = int((running_reward / log_interval))
print('Episode {} \t avg length: {} \t reward: {}'.format(i_episode, avg_length, running_reward))
running_reward = 0
avg_length = 0
更新阶段
def update(self, memory):
# Monte Carlo estimate of state rewards:
rewards = []
discounted_reward = 0
# 计算每个状态的积累价值量(利用旧参数所采的样本计算),用于后续计算优势函数
for reward, is_terminal in zip(reversed(memory.rewards), reversed(memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward) # 从后往前补充
rewards.insert(0, discounted_reward)
# Normalizing the rewards:
# 将奖励做标准化
rewards = torch.tensor(rewards, dtype=torch.float32).to(device)
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)
# convert list to tensor 提取旧参数所采得的样本
old_states = torch.stack(memory.states).to(device).detach()
old_actions = torch.stack(memory.actions).to(device).detach()
old_logprobs = torch.stack(memory.logprobs).to(device).detach()
# Optimize policy for K epochs:
for _ in range(self.K_epochs):
# Evaluating old actions and values :
# 将状态传入网络,得到新的动作概率分数和状态分数
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
# 计算损失
# Finding the ratio (pi_theta / pi_theta__old):
ratios = torch.exp(logprobs - old_logprobs.detach())
# 奖励值减去状态价值,得到动作的优势值,之后再对动作概率做一个加权
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantages
# 计算损失的时候,要对优化目标取一个负数
loss = -torch.min(surr1, surr2) + 0.5 * self.MseLoss(state_values, rewards) - 0.01 * dist_entropy
# take gradient step
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
# Copy new weights into old policy:
self.policy_old.load_state_dict(self.policy.state_dict())
注:以上仅是笔者个人见解,若有问题,欢迎指正