源码与图片引自《EasyRL》:https://github.com/datawhalechina/easy-rl
【深度强化学习】系列
PPO近端策略优化算法:https://blog.csdn.net/qq_50001789/article/details/145192196
DQN深度Q网络算法:https://blog.csdn.net/qq_50001789/article/details/145186657
DDPG深度确定性策略梯度算法:https://blog.csdn.net/qq_50001789/article/details/145187074
AC演员-评论员算法:https://blog.csdn.net/qq_50001789/article/details/145187443
介绍
核心思想:直接训练决策函数 V π ( s ) V_\pi(s) Vπ(s)(演员-actor,执行动作),并且训练评价网络去估计动作执行的好坏,对每个动作损失起到加权的作用(评论员-critic),例如价值函数 V θ ( s ) V_\theta(s) Vθ(s)(衡量状态 s s s的价值量,用于评估动作的好坏)、动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)(衡量在状态 s s s去执行动作 a a a会产生的积累价值)。
每个动作的权重又称优势函数,计算方法为:当前动作所产生的积累价值减去当前状态的价值量(又可以看成状态 s s s的动作空间中所有动作可以产生的平均价值),如果优势函数为正,则说明该动作所产生的积累价值大于平均量,属于”好动作“,需要进一步鼓励网络多做这种动作,产生正向优化,否则产生负向优化。
AC算法:用 Q π ( s t n , a t n ) Q_\pi(s^n_t,a^n_t) Qπ(stn,atn)来估计执行动作 a t a_t at之后可获得的积累奖励(利用SARSA算法训练,属于同策略,不能用经验回放,和DQN中的Q学习算法相区分),并且利用积累奖励来对每个动作概率做加权,利用梯度上升策略优化参数;
A2C算法做出的改进:相对于AC算法,引入了基线策略,利用 V θ ( s t n ) V_\theta(s_t^n) Vθ(stn)来估计当前状态的价值,用于计算动作的积累估计量,和PPO算法中的 b b b做好区分,将积累奖励与基线做差,得到优势函数,再利用做差后的结果对损失做加权。但此时需要同时优化两个网络,模型在训练过程中稳定性不高,因此本算法又利用 r t n + V θ ( s t + 1 n ) r^n_t+V_\theta(s_{t+1}^n) rtn+Vθ(st+1n)近似代替动作 a t a_t at的积累奖励 Q π ( s t n , a t n ) Q_\pi(s^n_t,a^n_t) Qπ(stn,atn),这样在训练过程中只需要更新一组参数 V θ ( s ) V_\theta(s) Vθ(s),提升了稳定性;
注:优势函数结果有正负,可以区分动作的好坏,否则权重全是非负数,没有对不好动作的“抑制作用”
A3C算法做出的改进:参考多线程模式,设置多个子网络去不同的环境中学习,所有的网络并行探索,提升了模型参数的训练速度以及训练的稳定性。
优化目标:
- 决策函数 V π ( s ) V_\pi(s) Vπ(s)的优化目标:
L π = 1 N ∑ n = 1 N ∑ t = 1 T n ( R − V θ ( s t n ) ) log p π ( a t n ∣ s t n ) L_{\pi}=\frac1 N\sum^N_{n=1}\sum^{T_n}_{t=1}(R-V_{\theta}(s_t^n))\log p_\pi(a_t^n|s_t^n) Lπ=N1n=1∑Nt=1∑Tn(R−Vθ(stn))logpπ(atn∣stn)
其中, R = ∑ t ′ = t T n γ t ′ − t r t ′ n + γ T n − t V θ ( s t + 1 n ) R=\sum_{t'=t}^{T_n}\gamma^{t'-t}r^n_{t'}+\gamma^{T_n-t}V_\theta(s^n_{t+1}) R=∑t′=tTnγt′−trt′n+γTn−tVθ(st+1n),表示动作 a t a_t at的积累收益,下面的 R R R相同。
注: L π L_\pi Lπ只用于更新决策函数,两个状态价值 V θ ( s t ) V_\theta(s_t) Vθ(st)只用于对动作损失做加权,实际执行时会切断梯度,反向传播过程不对价值函数产生影响。
- 价值函数 V θ ( s ) V_\theta(s) Vθ(s)的优化目标:
L θ = 1 N ∑ n = 1 N ∑ t = 1 T n 1 2 ( R − V θ ( s t n ) ) 2 L_\theta=\frac1N\sum^N_{n=1}\sum^{T_n}_{t=1}\frac12(R -V_\theta(s_t^n))^2 Lθ=N1n=1∑Nt=1∑Tn21(R−Vθ(stn))2
- 熵(用于辅助训练):
L e n = − H ( p π ( a t n ∣ s t n ) ∗ log p π ( a t n ∣ s t n ) ) L_{en}=-H(p_\pi(a_t^n|s_t^n)*\log{p_\pi(a_t^n|s_t^n)}) Len=−H(pπ(atn∣stn)∗logpπ(atn∣stn))
总损失函数:
L = − L π + α L θ − β L e n L=-L_\pi+\alpha L_\theta-\beta L_{en} L=−Lπ+αLθ−βLen
注:
- 默认使用梯度下降法更新网络参数,因此,损失中的负号表示要提升该目标值,正号表示要降低该目标值
- 每走 T n T_n Tn步再更新网络参数, t t t为时间步,若 T n T_n Tn为1,则为单步更新一次
A2C步骤:
- 初始化决策网络 V π ( s ) V_\pi(s) Vπ(s)以及动作网络 V θ ( s ) V_\theta(s) Vθ(s),面对状态维数过大的情况(如图像),两个网络可以共享特征提取部分的参数
- 遍历每个episodes,假设 t t t为当前的时间步
- 将状态 s t s_t st传入两个网络,得到动作概率分数 V π ( s t ) V_\pi(s_t) Vπ(st)以及状态价值 V θ ( s t ) V_\theta(s_t) Vθ(st),按概率采样,得到当前状态下所执行的动作 a t a_t at
- 动作与环境交互,得到当前的反馈 r t r_t rt以及下一阶段的状态 s t + 1 s_{t+1} st+1
- 将同一个 T n T_n Tn内的 ( V π ( s t ) , V θ ( s t ) , r t ) (V_\pi(s_t),V_\theta(s_t),r_t) (Vπ(st),Vθ(st),rt)存起来,迭代 T n T_n Tn之后计算总损失 L L L,更新网络参数
A3C步骤:
- 首先要预设一个全局网络,之后分成 n n n个环境(类似线程)以及 n n n个子网络,子网络结构与全局网络结构相同
- 对于每个子网络都要分配一个环境,并且在每走 T n T_n Tn步之前都加载一次全局网络的参数
- 每个子网络都要在所分配的环境下走 T n T_n Tn步,计算损失,步骤与A2C的步骤相同
- 损失所产生的梯度赋值到全局网络上面,更新全局网络的参数
注:A3C相当于实现了多线程更新参数的目的。
补充
路径衍生策略梯度
利用动作价值函数 Q ( s , a ) Q(s,a) Q(s,a)来优化决策网络 V π ( s ) V_\pi(s) Vπ(s)。首先让决策网络与环境做互动,利用 Q Q Q学习算法去优化动作价值函数 Q ( s , a ) Q(s,a) Q(s,a),之后固定价值函数的参数,以最大化Q值输出的目的去优化决策网络 V π ( s ) V_\pi(s) Vπ(s)的参数,与对抗生成网络思想很像,具体流程如下:
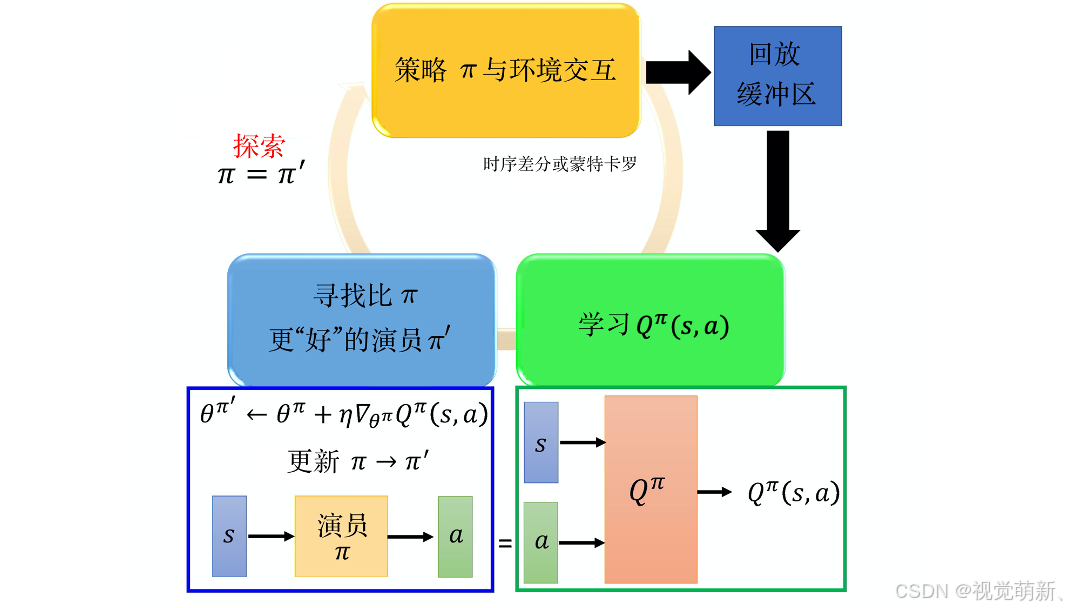
步骤:
-
初始化 Q Q Q网络、目标 Q ^ \hat Q Q^网络,令 Q ^ = Q \hat Q=Q Q^=Q,并且初始化决策网络 V π ( s ) V_\pi(s) Vπ(s)、目标决策网络KaTeX parse error: Got function '\hat' with no arguments as subscript at position 3: V_\̲h̲a̲t̲ ̲\pi(s),令 π ^ = π \hat \pi=\pi π^=π
-
遍历每个episodes,假设 t t t为当前的时间步
-
给定一个状态 s t s_t st,根据决策网络的决策结果执行动作 a t a_t at,并且与环境做交互,得到奖励 r t r_t rt以及下一个阶段 s t + 1 s_{t+1} st+1;
-
将 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)存入缓冲区,并且按批量形式从缓冲区采样(具体细节可见DQN算法),得到 ( s i , a i , r i , s i + 1 ) (s_i,a_i,r_i,s_{i+1}) (si,ai,ri,si+1)
-
计算目标值 y = r i + Q ^ ( s i + 1 , V π ^ ( s i + 1 ) ) y=r_i+\hat Q(s_{i+1},V_{\hat \pi}(s_{i+1})) y=ri+Q^(si+1,Vπ^(si+1)),更新 Q Q Q网络的参数,使得 Q ( s i , a i ) Q(s_i,a_i) Q(si,ai)向目标值 y y y靠近
-
更新决策网络 V π ( s ) V_\pi(s) Vπ(s)的参数,使得 Q ( s i , V π ( s i ) ) Q(s_i,V_{\pi}(s_i)) Q(si,Vπ(si))的值最大
-
每更新 C C C次参数就更新两个目标网络的参数,令 Q ^ = Q \hat Q=Q Q^=Q、 π ^ = π \hat \pi=\pi π^=π
A2C源码实现
网络结构
class ActorCritic(nn.Module):
"""
A2C网络模型,包含一个Actor和Critic
"""
def __init__(self, input_dim, output_dim, hidden_dim):
super(ActorCritic, self).__init__()
# 两个网络的输入维度均为状态s的数据维度
# 评价网络的输出为1,输出当前状态的价值
self.critic = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
# 决策函数的输出维度为动作空间的维度大小
# 输出数据表示在当前状态下每个动作所被选取的概率
self.actor = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim),
nn.Softmax(dim=1),
)
def forward(self, x):
value = self.critic(x)
probs = self.actor(x)
# 将概率转为分布,用于后续的采样,得到所执行的动作
dist = Categorical(probs)
return dist, value
训练流程
def train(cfg, envs):
print('开始训练!')
print(f'环境:{
cfg.env_name}, 算法:{
cfg.algo_name}, 设备:{
cfg.device}')
env = gym.make(cfg.env_name) # a single env
env.seed(10)
state_dim = envs.observation_space.shape[0]
action_dim = envs.action_space.n
# 定义模型以及优化器
model = ActorCritic(state_dim, action_dim, cfg.hidden_dim).to(cfg.device)
optimizer = optim.Adam(model.parameters())
frame_idx = 0
test_rewards = []
test_ma_rewards = []
state = envs.reset()
while frame_idx < cfg.max_frames:
log_probs = []
values = []
rewards = []
masks = []
entropy = 0
# rollout trajectory
# 按Tn遍历
for _ in range(cfg.n_steps):
state = torch.FloatTensor(state).to(cfg.device)
# 根据状态来评估动作概率以及状态价值
dist, value = model(state)
# 对分布做采样,得到执行动作的序号
action = dist.sample()
# 与环境做交互,得到下一个状态、奖励值、当前动作是否完成
next_state, reward, done, _ = envs.step(action.cpu().numpy())
# 计算对数概率
log_prob = dist.log_prob(action)
# 计算熵
entropy += dist.entropy().mean()
# 储存同一个Tn中的数据
log_probs.append(log_prob)
values.append(value)
rewards.append(torch.FloatTensor(reward).unsqueeze(1).to(cfg.device))
masks.append(torch.FloatTensor(1 - done).unsqueeze(1).to(cfg.device))
state = next_state
frame_idx += 1
if frame_idx % 100 == 0:
test_reward = np.mean([test_env(env, model) for _ in range(10)])
print(f"frame_idx:{
frame_idx}, test_reward:{
test_reward}")
test_rewards.append(test_reward)
if test_ma_rewards:
test_ma_rewards.append(0.9 * test_ma_rewards[-1] + 0.1 * test_reward)
else:
test_ma_rewards.append(test_reward)
# plot(frame_idx, test_rewards)
next_state = torch.FloatTensor(next_state).to(cfg.device)
_, next_value = model(next_state)
# returns里共有n_steps个元素,表示每个时间步的近似动作价值量,即损失公式中的R
returns = compute_returns(next_value, rewards, masks)
log_probs = torch.cat(log_probs)
returns = torch.cat(returns).detach()
values = torch.cat(values)
# 近似动作价值量R减去状态价值,得到优势函数
advantage = returns - values
# 决策函数损失
actor_loss = (log_probs * advantage.detach()).mean()
# 价值函数损失
critic_loss = advantage.pow(2).mean()
# 总损失
loss = -actor_loss + 0.5 * critic_loss - 0.001 * entropy
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('完成训练!')
return test_rewards, test_ma_rewards
迭代计算近似动作价值量R
def compute_returns(next_value, rewards, masks, gamma=0.99):
R = next_value
returns = []
for step in reversed(range(len(rewards))):
R = rewards[step] + gamma * R * masks[step]
returns.insert(0, R)
return returns
注:以上仅是笔者个人见解,若有错误,欢迎指正