
文章目录
源码地址:https://github.com/chatchat-space/Langchain-Chatchat
零、预备
我这里是基于xinference的大模型推理环境,部署的模型是:deepseek-r1-distill-qwen。
如果不了解部署的童鞋参考:xinference部署教学传送门
注意最好在新的环境(conda)中部署,以防止依赖包版本冲突(官方也有强调)。
其中包括了deepseek各种版本所需的配置,以及手把手教你部署。
一、搭建开发环境
参考官方源代码部署开发环境:传送门
按照官方的搭建开发环境即可,这里注意一定要按照这个步骤:
- 安装Poetry(我用pip)
- 安装所需依赖包
- 一般来说直接进入2设置源代码根目录 然后一直按步骤往后面走就好了
二、运行
安装完之后,就可以运行了,可以试试与数据库对话,肯定报错,因为还没配置呢,嘿嘿~
cd Langchain-Chatchat/libs/chatchat-server/chatchat
python cli.py start -a
三、修改配置
位置:在你环境变量CHATCHAT_ROOT下的data(这个文件是初始化生成的)里面。
3.1 修改model_settings.yaml
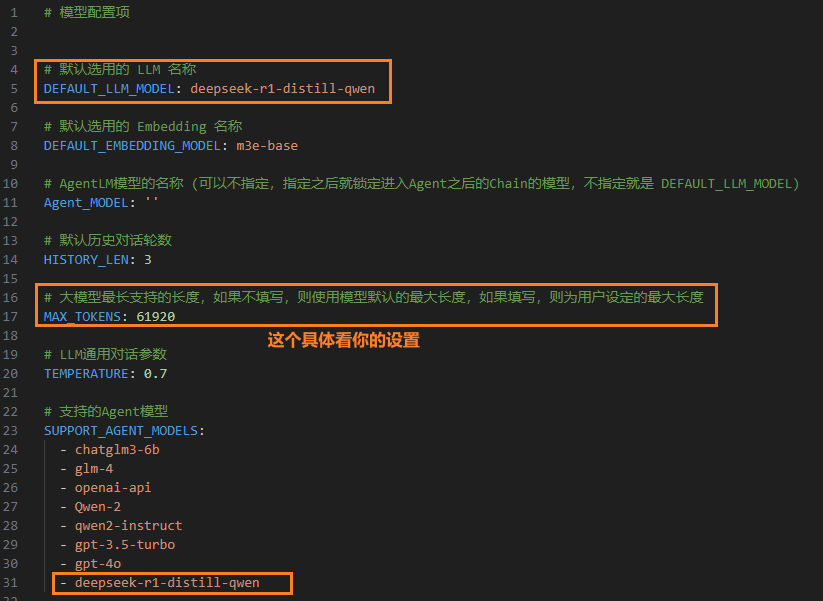
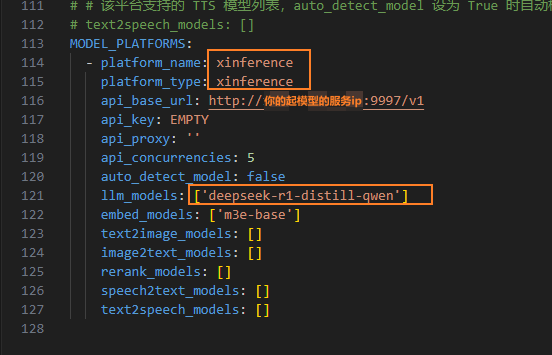
3.2 tool_settings.yaml

四、修改代码
1. qwen_agent.py
libs/chatchat-server/chatchat/server/agent/agent_factory/qwen_agent.py
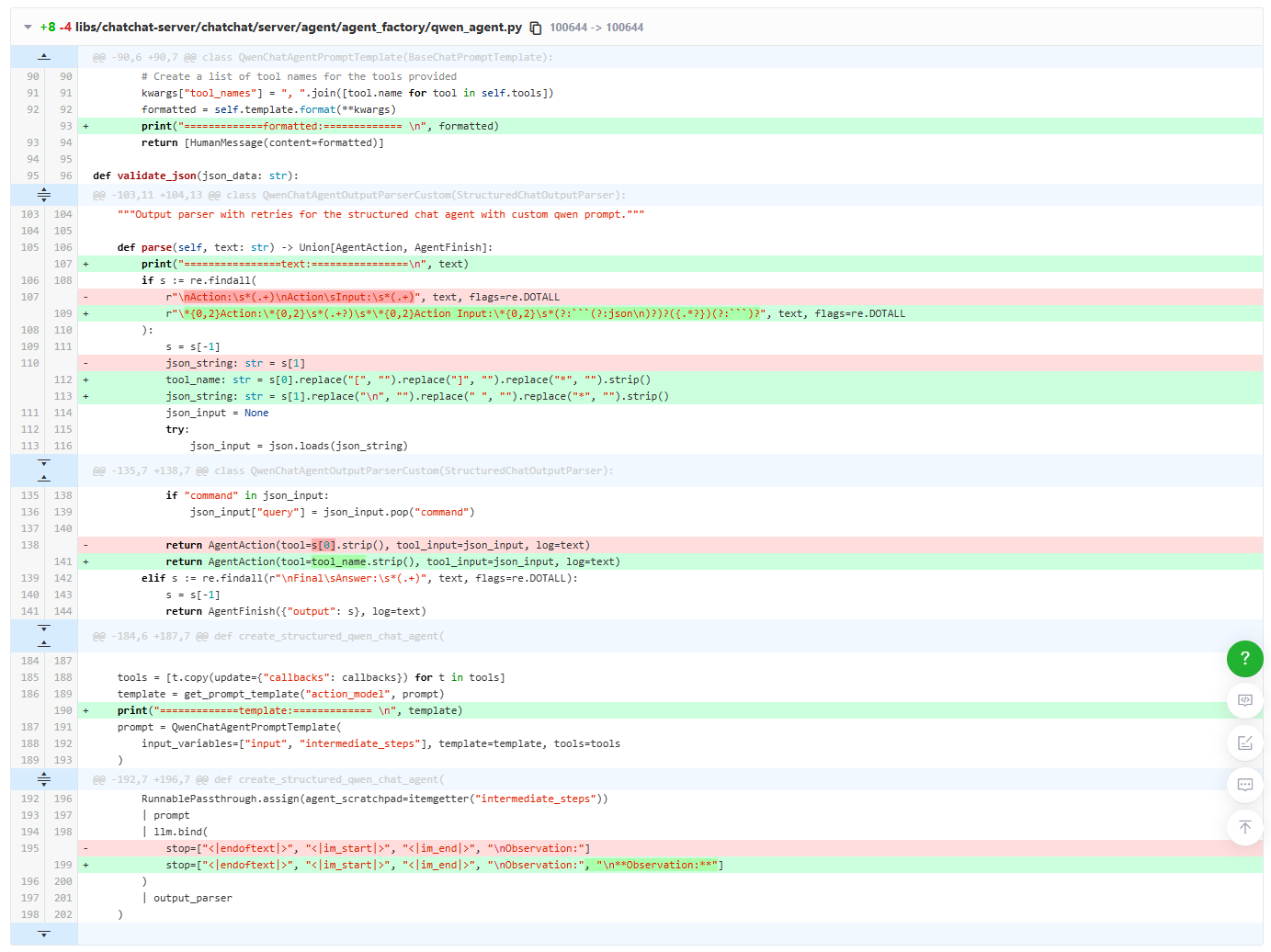
方便复制:
\*{0,2}Action:\*{0,2}\s*(.+?)\s*\*{0,2}Action Input:\*{0,2}\s*(?:```(?:json\n)?)?({.*?})(?:```)?
tool_name: str = s[0].replace("[", "").replace("]", "").replace("*", "").strip()
json_string: str = s[1].replace("\n", "").replace(" ", "").replace("*", "").strip()
return AgentAction(tool=tool_name.strip(), tool_input=json_input, log=text)
stop=["<|endoftext|>", "<|im_start|>", "<|im_end|>", "\nObservation:", "\n**Observation:**"]
2. text2sql.py
libs/chatchat-server/chatchat/server/agent/tools_factory/text2sql.py
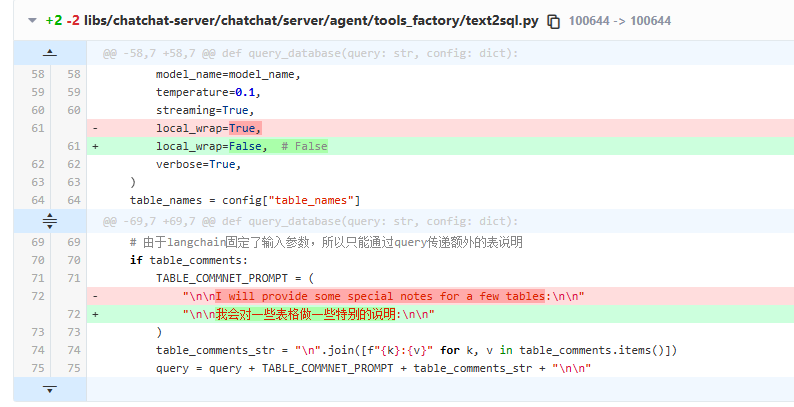
"\n\n我会对一些表格做一些特别的说明:\n\n"
3. chat.py
libs/chatchat-server/chatchat/server/chat/chat.py
不改也行,是个bug,导致模型的参数不生效,但是也有默认参数
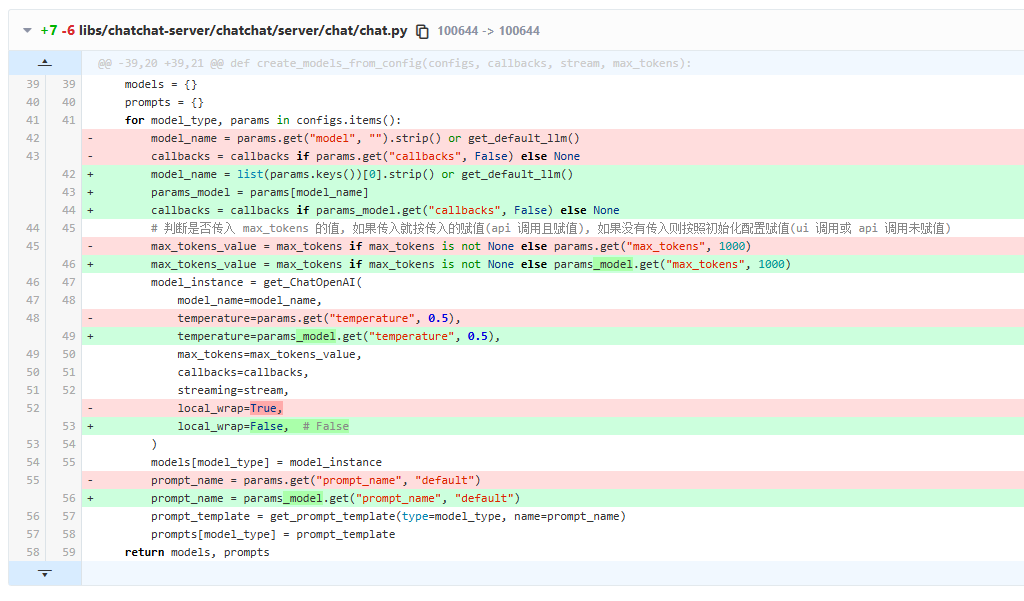
models = {
}
prompts = {
}
for model_type, params in configs.items():
model_name = params.get("model", "").strip() or get_default_llm()
callbacks = callbacks if params.get("callbacks", False) else None
model_name = list(params.keys())[0].strip() or get_default_llm()
params_model = params[model_name]
callbacks = callbacks if params_model.get("callbacks", False) else None
# 判断是否传入 max_tokens 的值, 如果传入就按传入的赋值(api 调用且赋值), 如果没有传入则按照初始化配置赋值(ui 调用或 api 调用未赋值)
max_tokens_value = max_tokens if max_tokens is not None else params.get("max_tokens", 1000)
max_tokens_value = max_tokens if max_tokens is not None else params_model.get("max_tokens", 1000)
model_instance = get_ChatOpenAI(
model_name=model_name,
temperature=params.get("temperature", 0.5),
temperature=params_model.get("temperature", 0.5),
max_tokens=max_tokens_value,
callbacks=callbacks,
streaming=stream,
local_wrap=True,
local_wrap=False, # False
)
models[model_type] = model_instance
prompt_name = params.get("prompt_name", "default")
prompt_name = params_model.get("prompt_name", "default")
prompt_template = get_prompt_template(type=model_type, name=prompt_name)
prompts[model_type] = prompt_template
return models, prompts
4. prompt.py (langchain包中的)
环境路径->lib/python3.9/site-packages/langchain/chains/sql_database/prompt.py
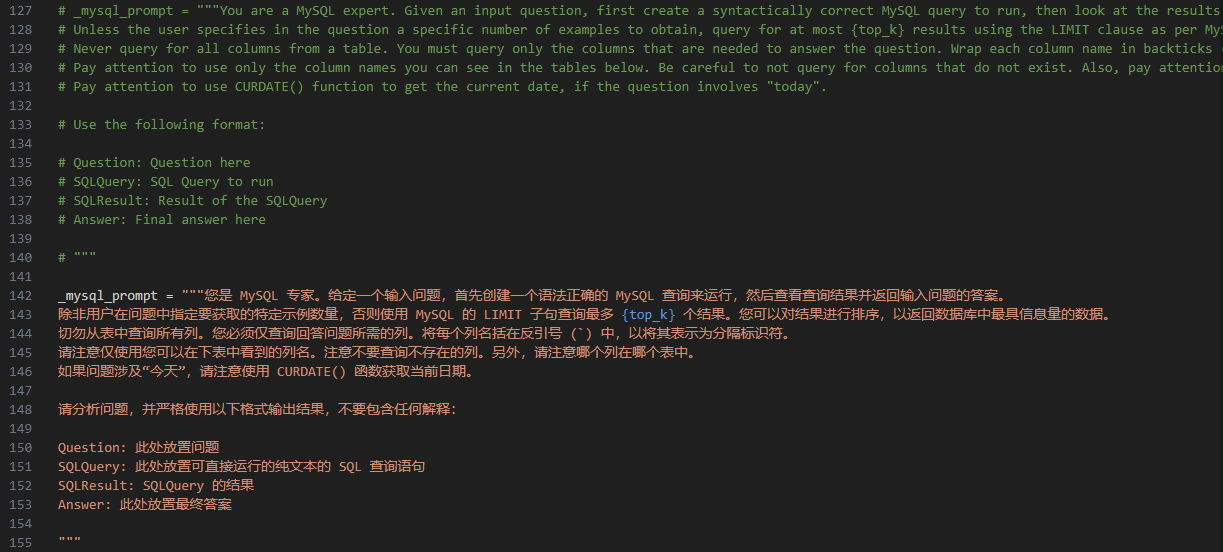
_mysql_prompt = """您是 MySQL 专家。给定一个输入问题,首先创建一个语法正确的 MySQL 查询来运行,然后查看查询结果并返回输入问题的答案。
除非用户在问题中指定要获取的特定示例数量,否则使用 MySQL 的 LIMIT 子句查询最多 {top_k} 个结果。您可以对结果进行排序,以返回数据库中最具信息量的数据。
切勿从表中查询所有列。您必须仅查询回答问题所需的列。将每个列名括在反引号 (`) 中,以将其表示为分隔标识符。
请注意仅使用您可以在下表中看到的列名。注意不要查询不存在的列。另外,请注意哪个列在哪个表中。
如果问题涉及“今天”,请注意使用 CURDATE() 函数获取当前日期。
请分析问题,并严格使用以下格式输出结果,不要包含任何解释:
Question: 此处放置问题
SQLQuery: 此处放置可直接运行的纯文本的 SQL 查询语句
SQLResult: SQLQuery 的结果
Answer: 此处放置最终答案
"""
5. base.py (langchain_experimental包中的)
环境路径->lib/python3.9/site-packages/langchain_experimental/sql/base.py
加一行:
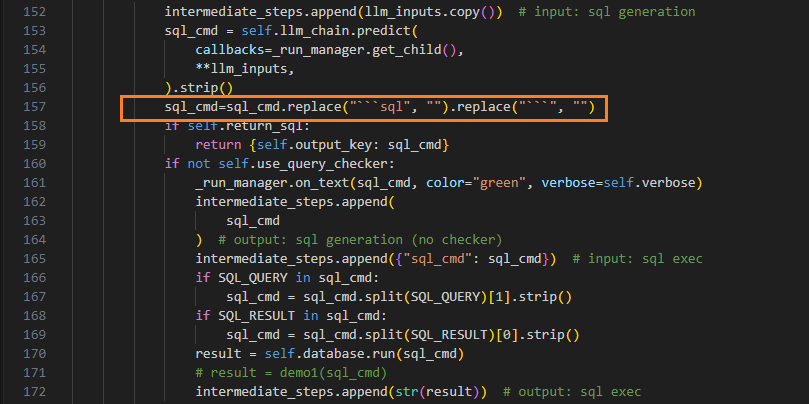
sql_cmd=sql_cmd.replace("```sql", "").replace("```", "")
五、Agent理解
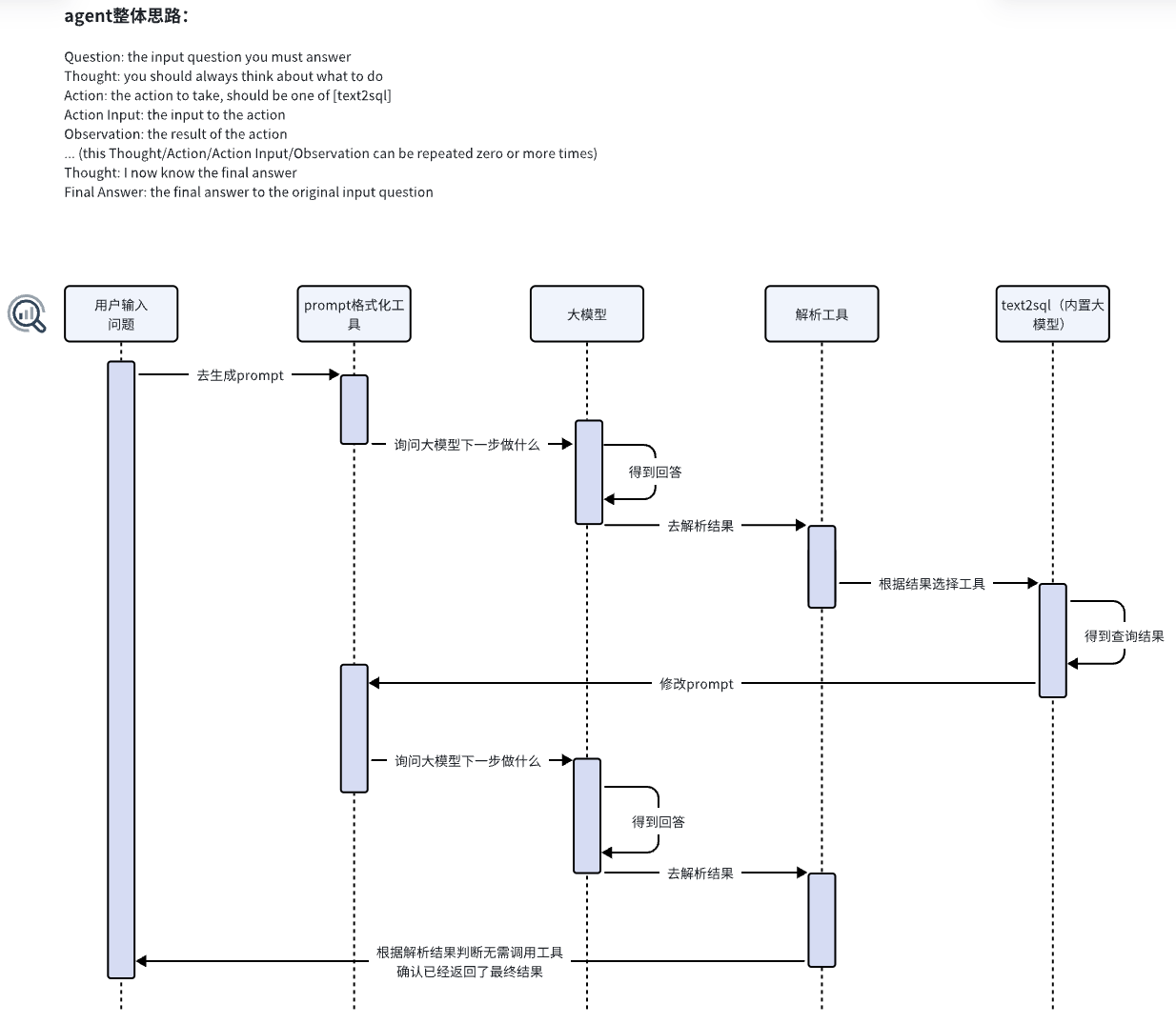
5.1. Agent 的工作流程:
我来为您解释这个 agent 的工作流程:
从代码中可以看出,这是一个基于 Qwen (通义千问) 模型的 agent 实现。让我为您详细分析其工作流程:
- 初始化阶段:
- 创建所需的工具集合 (tools)
- 设置输出解析器 (output parser)
- 配置 prompt 模板
- 初始化 agent 执行器
- 执行流程:
用户输入 -> Prompt组装 -> LLM处理 -> 输出解析 -> 工具执行 -> 结果处理 -> 循环或完成
具体步骤如下:
-
Prompt 组装:
- 系统会将用户输入、可用工具列表和之前的执行历史组装成一个完整的 prompt
- 每个工具都会被格式化为特定格式:工具名称、描述和参数
- 之前的执行历史会被记录在
agent_scratchpad中
-
LLM 处理:
- prompt 被发送给 Qwen 模型处理
- 模型会根据 prompt 决定下一步行动
-
输出解析:
- 模型输出会被
QwenChatAgentOutputParserCustom或QwenChatAgentOutputParserLC解析 - 解析器会从输出中提取以下两种结果之一:
AgentAction:需要执行的工具操作AgentFinish:最终答案
- 模型输出会被
-
执行循环:
- 如果是
AgentAction,系统会:- 执行指定的工具
- 将执行结果添加到历史记录
- 继续下一轮决策
- 如果是
AgentFinish,则返回最终结果给用户
- 如果是
特别值得注意的是:
- 代码中包含了对 Qwen 模型的特殊处理,比如修复了 streaming 相关的问题
- 实现了对不规范 JSON 输出的修复机制
- 设置了特定的停止词来控制模型输出
- 支持自定义 prompt 和标准 prompt 两种模式
这个实现遵循了 LangChain 的 agent 框架,但针对 Qwen 模型做了特殊优化,使其能更好地处理中文场景和特定的输出格式。
5.2. Agent工作流程图
本修改也提交官方库,欢迎围观:https://github.com/chatchat-space/Langchain-Chatchat/pull/5257/files
∼ O n e p e r s o n g o f a s t e r , a g r o u p o f p e o p l e c a n g o f u r t h e r ∼ \sim_{One\ person\ go\ faster,\ a\ group\ of\ people\ can\ go\ further}\sim ∼One person go faster, a group of people can go further∼