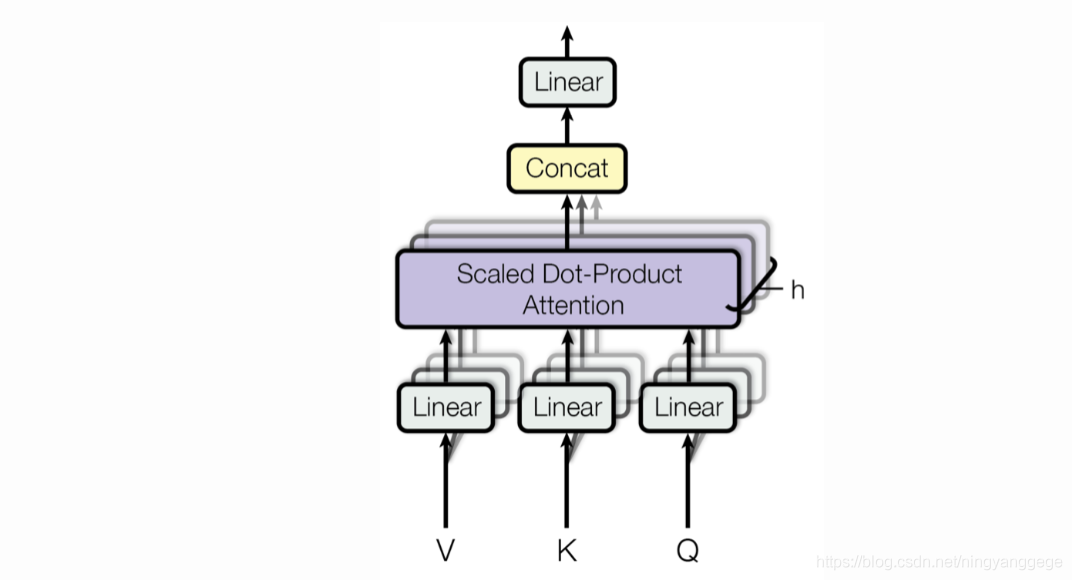
一、nn.MultiheadAttention 的理解
当然知道,nn.MultiheadAttention 是 PyTorch 中的一个模块,用于实现多头注意力机制(Multi-Head Attention)。这是 Transformer 模型的核心组件之一。
核心功能
多头注意力机制通过多个独立的注意力头计算输入特征之间的关系,最后将它们的结果组合起来。它能够捕获输入特征的不同方面,更好地表示复杂的关系。
模块定义
torch.nn.MultiheadAttention(embed_dim, num_heads, **kwargs)
参数
embed_dim: 输入特征的维度,也就是每个 token 的表示向量大小。num_heads: 注意力头的数量,embed_dim必须能被num_heads整除。dropout(optional): 在注意力权重上的 dropout 概率,默认是0.0。bias(optional): 是否在投影层使用偏置,默认为True。add_bias_kv(optional): 是否在键和值中添加可学习的偏置,默认是False。batch_first(optional): 如果为True,输入和输出张量的形状为(batch_size, seq_len, embed_dim),否则为(seq_len, batch_size, embed_dim),默认为False。
输入和输出
- 输入张量:
query(形状:(L, N, E)或(N, L, E)): 查询向量。key和value(形状:(S, N, E)或(N, S, E)): 键和值向量。L: 查询序列长度S: 键值序列长度N: 批量大小E: 嵌入维度
- 输出张量:
- 输出形状与
query相同((L, N, E)或(N, L, E))。
- 输出形状与
使用示例
import torch
from torch.nn import MultiheadAttention
# 参数
embed_dim = 16
num_heads = 4
seq_length = 10
batch_size = 2
# 创建 MultiheadAttention 实例
mha = MultiheadAttention(embed_dim=embed_dim, num_heads=num_heads, batch_first=True)
# 输入
query = torch.rand(batch_size, seq_length, embed_dim) # (batch_size, seq_length, embed_dim)
key = torch.rand(batch_size, seq_length, embed_dim)
value = torch.rand(batch_size, seq_length, embed_dim)
# 前向计算
output, attention_weights = mha(query, key, value)
print("Output shape:", output.shape) # (batch_size, seq_length, embed_dim)
print("Attention Weights shape:", attention_weights.shape) # (batch_size, num_heads, seq_length, seq_length)
常见用途
- Transformer 编码器: 处理输入特征的上下文依赖。
- Transformer 解码器: 在生成序列时关注过去的输出和编码器输出。
- 自注意力 (Self-Attention):
query = key = value的特殊情况。
二、输出形状为什么要与 query 相同 ?
nn.MultiheadAttention 的输出形状与 query 相同,这是设计上的要求,原因与多头注意力机制的计算过程密切相关。以下是详细的解释:
1. 多头注意力机制的核心公式
多头注意力的计算公式如下:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQK⊤)V
其中:
- Q Q Q 是查询矩阵(Query),来自
query。 - K K K 是键矩阵(Key),来自
key。 - V V V 是值矩阵(Value),来自
value。 - d k d_k dk 是每个注意力头的键向量维度。
输出的维度取决于 Q Q Q,因为注意力机制的本质是:
- 每个查询向量 q i q_i qi(来自 Q Q Q)得到一个加权值向量 v i v_i vi。
- 因此,最终输出的特征数目和每个特征的维度与 Q Q Q 一致。
2. 多头注意力模块的设计
nn.MultiheadAttention 的设计目标是对输入特征进行映射,保持序列长度和每个 token 表示的特征维度不变。因此:
- 输入的
query决定了输出的 序列长度和特征维度。
具体步骤:
-
投影:
在多头注意力中,query、key和value会分别通过三个线性投影层映射到同样的维度:Q ′ = Q W Q , K ′ = K W K , V ′ = V W V Q' = QW_Q, \quad K' = KW_K, \quad V' = VW_V Q′=QWQ,K′=KWK,V′=VWV
- Q ′ , K ′ , V ′ Q', K', V' Q′,K′,V′ 的维度都是 ( L , N , d head × num_heads ) (L, N, d_{\text{head}} \times \text{num\_heads}) (L,N,dhead×num_heads)。
-
分头计算:
每个头单独计算注意力并得到中间结果,维度是 ( L , N , d head ) (L, N, d_{\text{head}}) (L,N,dhead)。 -
合并头:
将所有头的结果拼接后通过最后的线性层:
output = Concat ( head 1 , head 2 , . . . , head h ) W O \text{output} = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W_O output=Concat(head1,head2,...,headh)WO
最终输出的形状变回与query一致,即 ( L , N , E ) (L, N, E) (L,N,E)。
3. 为什么保持形状一致
实用性
- Transformer 模型的结构通常是对相同形状的输入和输出堆叠多个编码器/解码器层。因此,保持
query的输入和输出形状一致,可以让模块方便地串联。
对齐查询和注意力输出
- 输出需要与
query一一对应:query的第 i i i 个向量关注了key的所有向量,然后输出的是综合后的结果,维度仍然与query对应。
总结
nn.MultiheadAttention 输出的形状与 query 相同是因为:
- 注意力机制的设计使得每个查询向量有一个对应的输出向量。
- Transformer 模型需要在多个层中保持输入输出的形状一致,方便堆叠使用。
三、q k v的维度有什么要求?
在使用多头注意力机制(nn.MultiheadAttention)时,query(Q)、key(K)和value(V)矩阵的维度有一定的要求,主要与模型的设计和参数配置相关。下面是详细的要求和解释:
1. 输入维度要求
对于 nn.MultiheadAttention,query、key 和 value 都有相同的基本维度要求。一般来说,它们的维度是 (seq_len, batch_size, embed_dim) 或 (batch_size, seq_len, embed_dim),具体取决于 batch_first 参数的设置。
query:(L, N, E)或(N, L, E)key:(S, N, E)或(N, S, E)value:(S, N, E)或(N, S, E)
其中:
L是查询序列的长度(query的序列长度),S是键和值序列的长度(key和value的序列长度),N是批量大小(batch size),E是嵌入维度(embedding dimension)。
2. key 和 query 的维度要求
query和key的维度必须匹配,至少在某些维度上是兼容的。- 具体来说,
query和key的嵌入维度E必须是能够被num_heads整除的,这样才能正确分割成多个注意力头的子空间。
3. query、key 和 value 的嵌入维度 (Embedding Dimension)
query、key和value的 嵌入维度(E)通常会一致,但并不强制要求它们必须完全相同。query、key和value的嵌入维度会经过投影操作(通过线性层)。为了简化理解,通常它们的维度是相同的,以保持一致性和计算效率。
注意力头分配 (Attention Heads)
在多头注意力中,每个注意力头将负责 E // num_heads 维度的计算,因此:
E必须能够被num_heads整除。即E % num_heads == 0,确保每个头的维度一致。
4. value 的维度要求
value的维度一般不需要与key完全相同,理论上value的维度可以和key不同,但实际应用中,key和value通常是相同的,因为它们来自同一组信息。- 如果你想设置
key和value的维度不同,nn.MultiheadAttention会使用线性层将value投影到key的维度。
5. output 的维度要求
output的维度会根据query和num_heads来决定。通常,output的维度与query相同,特别是在计算完所有头的输出并拼接后,经过线性层得到的最终输出,形状保持与query相同。
6. 总的来说,Q、K、V 的维度要求
query和key的维度必须兼容,即嵌入维度可以相同,且必须能被num_heads整除。value和key的维度可以相同,但也可以不同,只要通过线性投影来适配。num_heads必须能整除嵌入维度,以便能够均匀划分每个头的维度。
总结示例
假设你有以下配置:
embed_dim = 16(嵌入维度)num_heads = 4(注意力头数)
那么:
- 每个头的维度应该是
16 // 4 = 4。 query、key和value的维度应为(L, N, 16),其中L是序列长度,N是批量大小,16是嵌入维度。embed_dim必须能被num_heads整除。
四、查询向量 和 键向量 求点积后为什么还要跟 值向量求积?
这个问题涉及到多头注意力机制的核心思想。首先,点积和加权计算(即与 value 向量求积)是自注意力机制的关键步骤。我们来逐步解答这个问题。
1. 点积计算的意义:
在自注意力机制中,query、key 和 value 向量都是由输入数据的表示学习得到的。
查询 (Query):
query向量表示了当前时刻(或当前词语)对于上下文信息的需求或注意力。
键 (Key):
key向量则表示了所有可能的信息(或词语)的特征。可以认为是对上下文中每个位置(或每个词)进行编码得到的。
值 (Value):
value向量是与key对应的实际信息内容。当模型决定关注某个key时,我们需要根据它选择和聚合对应的value信息。
2. 点积操作:
- 当计算查询向量和键向量的点积时,实质上是衡量查询向量和每个键向量之间的 相似度 或 相关性。这反映了查询向量与各个键向量之间的匹配程度。
公式:
attention_score ( Q , K ) = Q K T d k \text{attention\_score}(Q, K) = \frac{QK^T}{\sqrt{d_k}} attention_score(Q,K)=dkQKT
- 这里,
Q是查询向量,K是键向量,d_k是键向量的维度。点积后我们得到的是一个注意力得分,用来衡量查询和键之间的匹配程度。
为什么要使用点积?
- 相似度衡量:查询向量
Q和键向量K的点积反映了它们在向量空间中的相似度,匹配程度高的键会得到较高的注意力分数。 - 放缩:将点积结果除以
√d_k是为了防止随着维度增大,点积值变得过大,导致梯度更新困难。
3. Softmax 函数:
- 通过 softmax 操作,我们将点积得到的相似度得分转换成概率分布。这确保了注意力分数在 0 到 1 之间,并且总和为 1,保证了注意力机制的 加权求和 特性。
α i = softmax ( Q K T ) \alpha_i = \text{softmax}(QK^T) αi=softmax(QKT)
为什么需要 softmax?
- 归一化:softmax 确保每个键向量的权重在 0 到 1 之间,并且所有权重的总和为 1。这样做可以避免过大的注意力分数影响模型的训练。
4. 与值向量 (Value) 求积:
最终,点积结果(通过 softmax 归一化后的注意力权重)会与值向量 V 进行加权求和,得到输出。这是为了聚合输入信息并生成最终的 加权输出。
公式:
output = α 1 V 1 + α 2 V 2 + ⋯ + α n V n \text{output} = \alpha_1 V_1 + \alpha_2 V_2 + \dots + \alpha_n V_n output=α1V1+α2V2+⋯+αnVn
其中:
- α i \alpha_i αi 是每个键的注意力得分,反映了每个值在最终输出中的重要性。
- V i V_i Vi 是对应的值向量。
为什么与 value 向量求积?
-
聚合信息:
value向量包含了每个键所代表的实际信息,而点积的结果(经过 softmax 后)则决定了各个value向量在最终输出中的重要性。我们通过加权求和来汇聚不同value的信息。 -
加权平均:这种方式实际上就是一种加权平均,注意力机制通过计算查询与键的相似度来决定各个值向量的权重。
5. 总结
- 点积:计算查询向量与键向量的相似度,衡量查询与各个位置(或信息)的相关性。
- Softmax:对相似度得分进行归一化,得到每个位置的注意力权重。
- 与
value求积:根据注意力权重对value向量进行加权求和,得到最终的输出。这一步聚合了不同的信息。
通过这三步,模型能够灵活地决定在每个时刻关注哪些部分的信息,并将这些信息结合成一个新的表示。这就是自注意力机制的核心思想。