本专栏深入探究从循环神经网络(RNN)到Transformer等自然语言处理(NLP)模型的架构,以及基于这些模型构建的应用程序。
本系列文章内容:
- NLP自然语言处理基础
- 词嵌入(Word Embeddings)
- 循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU)
3.1 循环神经网络(RNN)
3.2 长短期记忆网络(LSTM)(本文)
3.3 门控循环单元(GRU) - 编码器 - 解码器架构(Encoder - Decoder Architecture)
- 注意力机制(Attention Mechanism)
- Transformer
- 编写Transformer代码
- 双向编码器表征来自Transformer(BERT)
- 生成式预训练Transformer(GPT)
- 大语言模型(LLama)
- Mistral
1. 长短期记忆网络(LSTMs,Long Short-Term Memory Networks)
在我们之前关于循环神经网络(RNNs)的讨论中,我们了解了它们的设计如何使其能够有效地处理序列数据。这使得它们非常适合处理数据的序列和上下文至关重要的任务,比如分析时间序列数据或处理自然语言。
现在,我们要探讨一种能够解决传统循环神经网络面临的重大挑战之一的RNN类型:处理长期数据依赖关系。这就是长短期记忆网络(LSTMs),其复杂程度更上一层楼。它们使用门控系统来控制信息在网络中的流动,从而决定在长序列中保留哪些信息以及遗忘哪些信息。
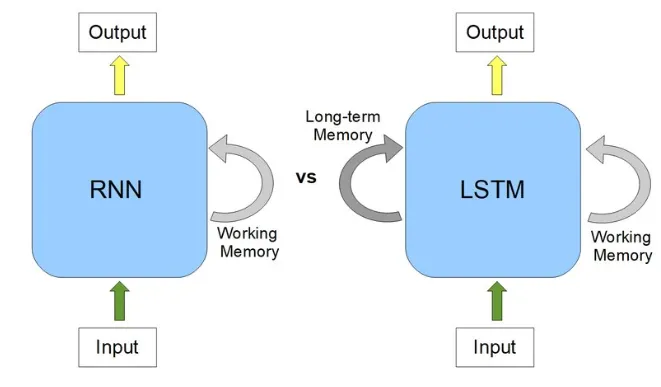
循环神经网络(RNN)与长短期记忆网络(LSTM)对比。
a:RNN利用其内部状态(记忆)来处理输入序列;
b:长短期记忆(LSTM)网络是RNN的一种变体,具有额外的长期记忆功能,可记住过去的数据
长短期记忆(LSTM)是循环神经网络(RNN)家族中的一员,或者说是一种特殊的循环神经网络。LSTM能够通过长时间记住重要且相关的信息,来学习长期依赖关系,这是其默认的能力。
让我们通过一个简单的故事来剖析LSTM背后的核心思想:
曾经,维克拉姆国王打败了XYZ国王,但随后去世了。他的儿子小维克拉姆继位,英勇作战,但也在战斗中牺牲了。他的孙子小小维克拉姆,没有那么强壮,但凭借智慧最终打败了XYZ国王,为家族报了仇。
当我们阅读这个故事或任何一系列事件时,我们的大脑首先会关注眼前的细节。例如,我们会先处理维克拉姆国王的胜利和死亡信息。但随着更多角色的出现,我们会调整对故事的长期理解,同时记住小维克拉姆和小小维克拉姆的情况。这种对上下文的不断更新,反映了LSTM的工作方式:当新信息流入时,它们会维护并更新短期记忆和长期记忆。
循环神经网络难以平衡短期和长期上下文信息。就像我们会清晰地记得电视剧的最新一集,但却会忘记早期的细节一样,当新数据到来时,RNN常常会丢失长期信息。LSTM通过创建两条路径来解决这个问题,一条用于短期记忆,一条用于长期记忆,这使得模型能够保留重要信息,并丢弃不太重要的信息。
在LSTM中,信息通过细胞状态流动,细胞状态就像一条传送带,在向前传递有用信息的同时,有选择地遗忘不相关的细节。与RNN中用新数据覆盖旧数据不同,LSTM会应用精心设计的数学运算(加法和乘法)来保留关键信息。这使得它们能够有效地对新数据和过去的数据进行优先级排序和管理。
每个细胞状态取决于三种不同的依赖关系,分别是:
- 先前的细胞状态(上一个时间步结束时存储的信息)
- 先前的隐藏状态(与上一个细胞的输出相同)
- 当前时间步的输入(当前时间步的新信息/输入)
说了这么多,让我们更详细地讨论LSTM的架构和功能。
2. LSTM架构
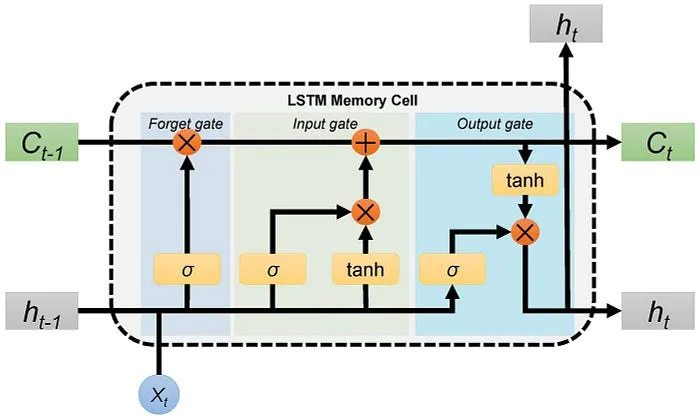
循环神经网络(RNN)的架构是由一连串重复的神经网络组成。这个重复的模块具有一个简单且单一的功能:使用tanh激活函数。
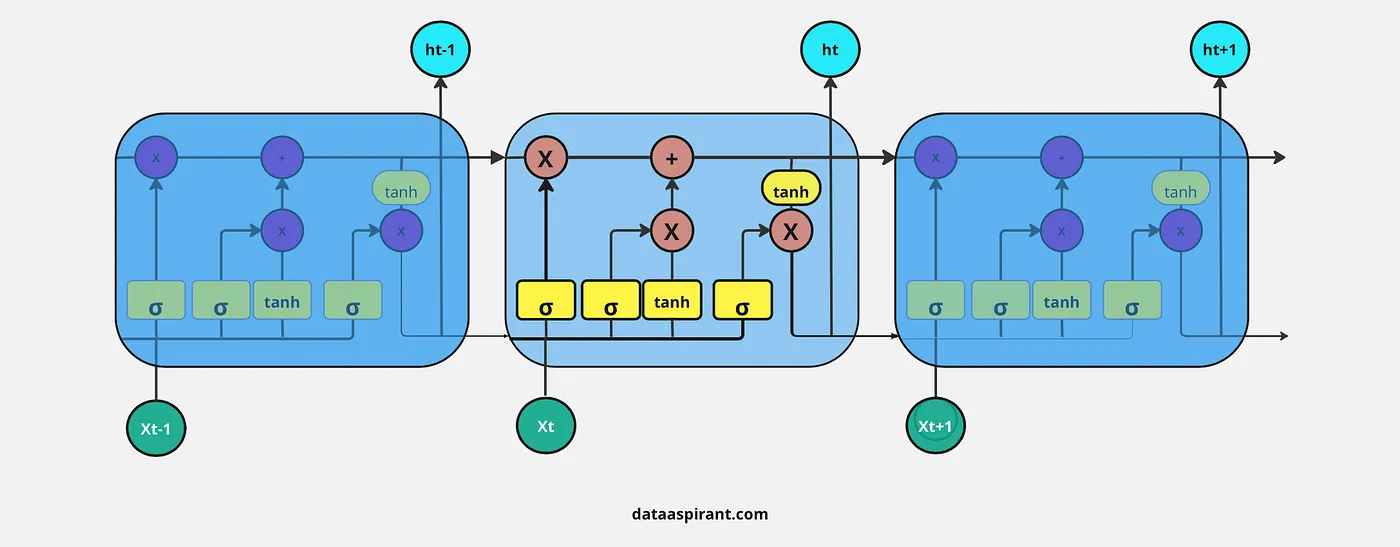
LSTM的架构也和RNN类似,同样是由一连串重复的模块/神经网络组成。但LSTM的重复模块并非只有一个tanh层,而是包含四个不同的功能。
这四个功能操作之间有着特殊的连接,它们分别是:
- Sigmoid激活函数
- Tanh激活函数
- 逐元素乘法
- 逐元素加法
在整个网络中,信息以向量的形式进行传递。让我们来讨论一下上图中提到的不同符号的含义:
- 方形框:表示单个神经网络
- 圆形:表示逐元素操作,意味着操作是逐个元素进行的
- 箭头标记:表示向量信息从一层传递到另一层
- 两条线合并为一条线:表示连接两个向量
- 一条线分为两条线:表示将相同的信息传递到两个不同的操作或层中
首先,让我们讨论一下LSTM架构中的主要功能和操作。
2.1 激活函数和线性操作

Sigmoid函数
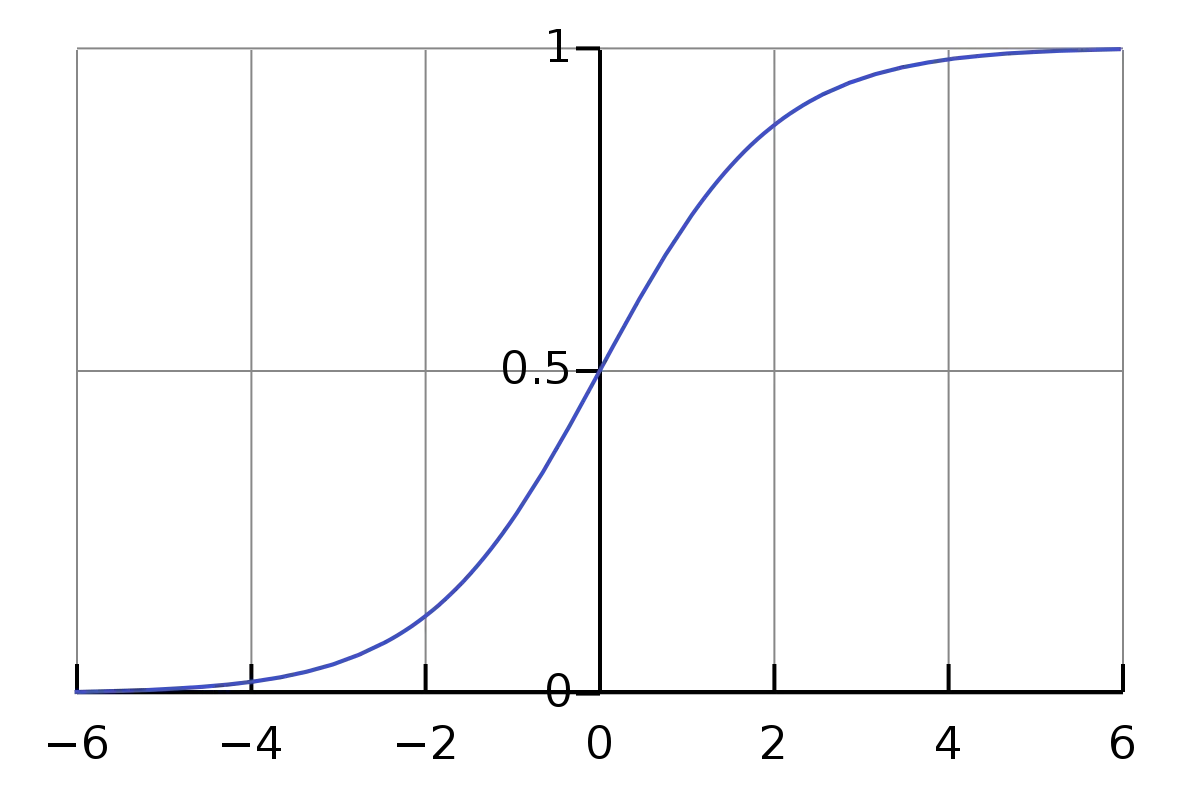
Sigmoid函数也被称为逻辑激活函数。这个函数有一条平滑的“S”形曲线。
Sigmoid函数的输出结果始终在0到1的范围内。
Sigmoid激活函数主要用于那些我们必须将概率作为输出进行预测的模型中。由于任何输入的概率只存在于0到1的范围内,所以Sigmoid或逻辑激活函数是正确且最佳的选择。
Tanh激活函数
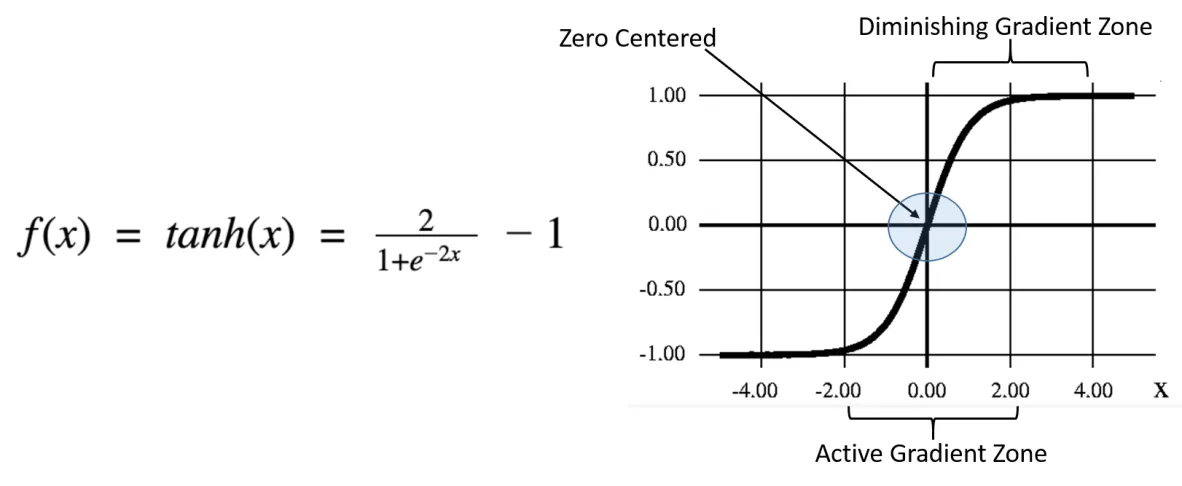
Tanh激活函数看起来也与Sigmoid/逻辑函数相似。实际上,它是一个经过缩放的Sigmoid函数。我们可以将tanh函数的公式写成Sigmoid函数的形式。
Tanh函数的结果值范围是-1到+1。使用这个tanh函数,我们可以判断输入是强正、中性还是负。
逐元素乘法
两个向量的逐元素乘法是对两个向量的各个元素分别进行乘法运算。例如:
A = [1,2,3,4]
B = [2,3,4,5]
逐元素乘法结果 : [2,6,12,20]
逐元素加法
两个向量的逐元素加法是将两个向量的元素分别相加的过程。例如:
A = [1,2,3,4]
B = [2,3,4,5]
逐元素加法结果 : [3,5,7,9]
2.2 LSTM算法背后的关键概念

LSTM的主要独特之处在于细胞状态;它就像一条传送带,进行一些轻微的线性交互。
这意味着细胞状态通过加法和乘法等基本运算来传递信息;这就是为什么信息能够沿着细胞状态平稳流动,与原始信息相比不会有太多变化。
LSTM的细胞状态或传送带是下图中突出显示的水平线。
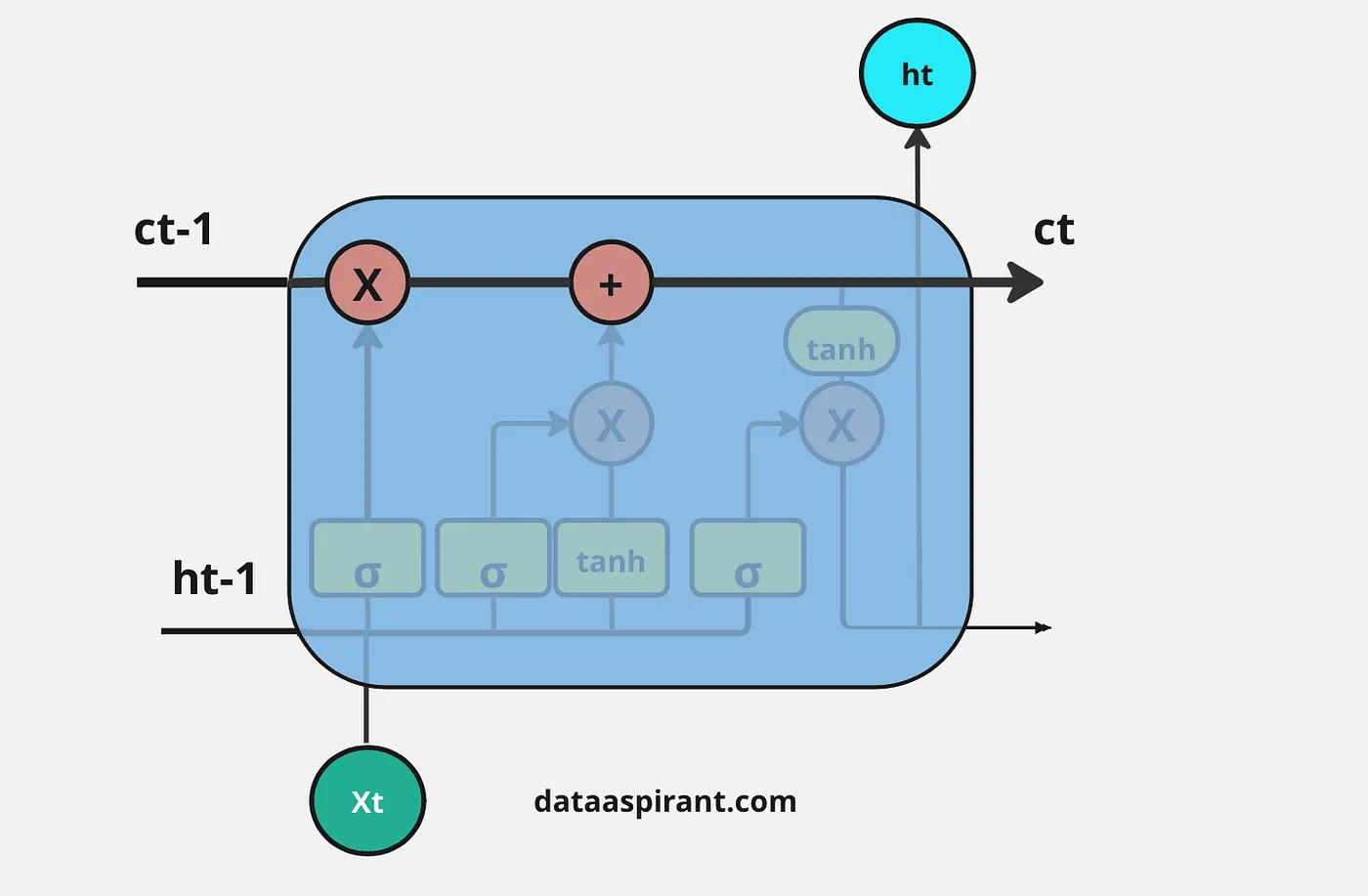
LSTM具有独特的结构,能够识别哪些信息是重要的,哪些是不重要的。LSTM可以根据信息的重要性,对细胞状态进行信息的删除或添加。这些特殊的结构被称为门。
门是一种独特的信息转换方式,LSTM利用这些门来决定哪些信息需要记住、删除,以及传递到另一层等等。
LSTM会根据这些信息对传送带(细胞状态)进行信息的删除或添加。每个门都由一个Sigmoid神经网络层和一个逐元素乘法操作组成。
LSTM有三种门,分别是:
- 遗忘门
- 输入门
- 输出门
2.2.1 遗忘门

在LSTM架构的重复模块中,第一个门是遗忘门。这个门的主要任务是决定哪些信息应该被保留,哪些信息应该被丢弃。
这意味着要决定将哪些信息发送到细胞状态以便进一步处理。遗忘门的输入是来自上一个隐藏状态的信息和当前输入,它将这两个状态的信息结合起来,然后通过Sigmoid函数进行处理。
Sigmoid函数的结果介于0和1之间。如果结果接近0,则表示遗忘;如果结果接近1,则表示保留/记住。
2.2.2 输入门

LSTM架构中有一个输入门,用于在遗忘门之后更新细胞状态信息。输入门有两种神经网络层,一种是Sigmoid层,另一种是Tanh层。这两个网络层都以上一个隐藏状态的信息和当前输入的信息作为输入。
Sigmoid网络层的结果范围在0到1之间,而Tanh层的结果范围是-1到1。Sigmoid层决定哪些信息是重要的并需要保留,Tanh层则对网络进行调节。
在对上一个隐藏状态信息和当前输入信息应用Sigmoid函数和Tanh函数之后,我们将两个输出相乘。最后,Sigmoid层的输出将决定从Tanh层的输出中保留哪些重要信息。
2.2.3 输出门


LSTM中的最后一个门是输出门。输出门的主要任务是决定下一个隐藏状态中应该包含哪些信息。这意味着输出层的输出将作为下一个隐藏状态的输入。
输出门也有两个神经网络层,与输入门相同。但操作有所不同。从输入门我们得到了更新后的细胞状态信息。
在这个输出门中,我们需要将隐藏状态和当前输入信息通过Sigmoid层,将更新后的细胞状态信息通过Tanh层。然后将Sigmoid层和Tanh层的两个结果相乘。
最终结果将作为输入发送到下一个隐藏层。
3. LSTM的工作过程
LSTM架构中的首要步骤是决定哪些信息是重要的,哪些信息需要从上一个细胞状态中丢弃。在LSTM中执行这一过程的第一个门是“遗忘门”。
遗忘门的输入是上一个时间步的隐藏层信息( h t − 1 h_{t-1} ht−1)和当前时间步的输入( x t x_t xt),然后将其通过Sigmoid神经网络层。
结果是以向量形式呈现,包含0和1的值。然后,对上一个细胞状态( C t − 1 C_{t-1} Ct−1)的信息(向量形式)和Sigmoid函数的输出( f t f_t ft)进行逐元素乘法操作。
遗忘门的最终输出中,1表示“完全保留这条信息”,0表示“不保留这条信息”。
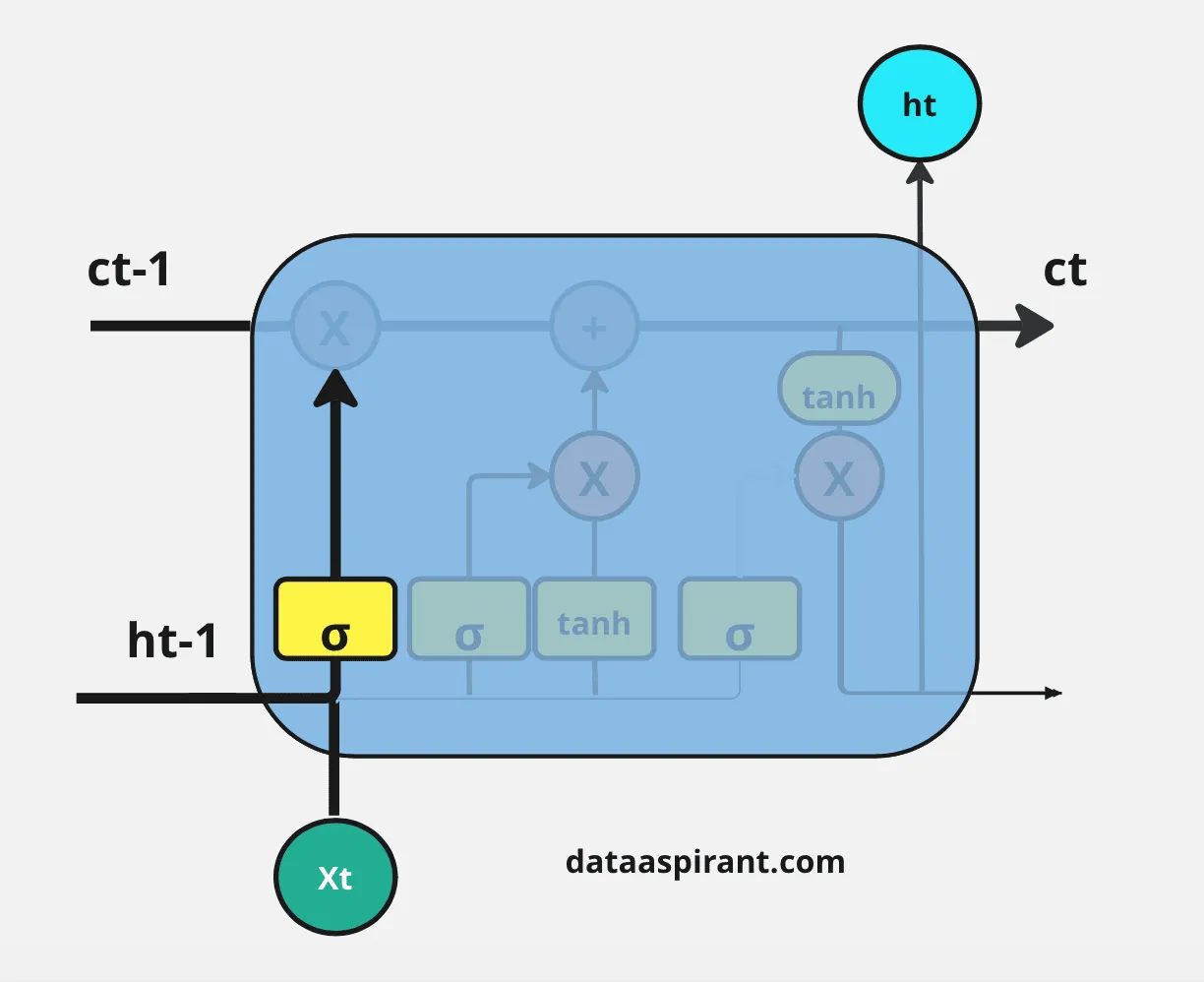
接下来的步骤是决定将哪些信息存储在当前细胞状态( C t C_t Ct)中。另一个门会执行这个任务,LSTM架构中的第二个门是“输入门”。
用新的重要信息更新细胞状态的整个过程将通过两种激活函数/神经网络层来完成,即Sigmoid神经网络层和Tanh神经网络层。
首先,Sigmoid网络层的输入和遗忘门一样:上一个时间步的隐藏层信息( h t − 1 h_{t-1} ht−1)和当前时间步( x t x_t xt)。
这个过程决定了我们将更新哪些值。然后,Tanh神经网络层也接收与Sigmoid神经网络层相同的输入。它以向量( C ~ t \tilde{C}_t C~t)的形式创建新的候选值,以调节网络。
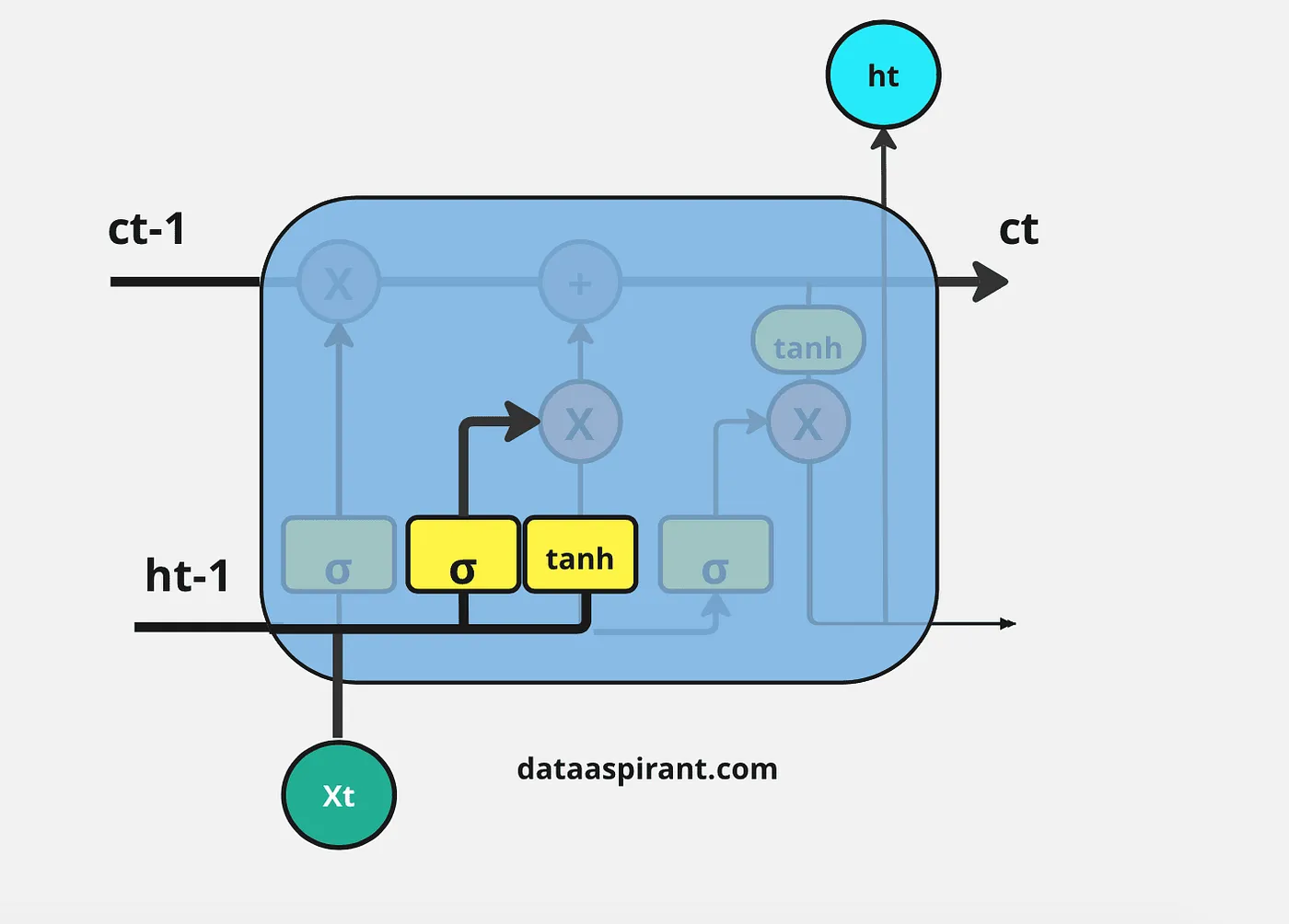
现在,我们对Sigmoid层和Tanh层的输出进行逐元素乘法操作。之后,我们需要对遗忘门的输出和输入门中逐元素乘法的结果进行逐元素加法操作,以更新当前细胞状态信息( C t C_t Ct)。
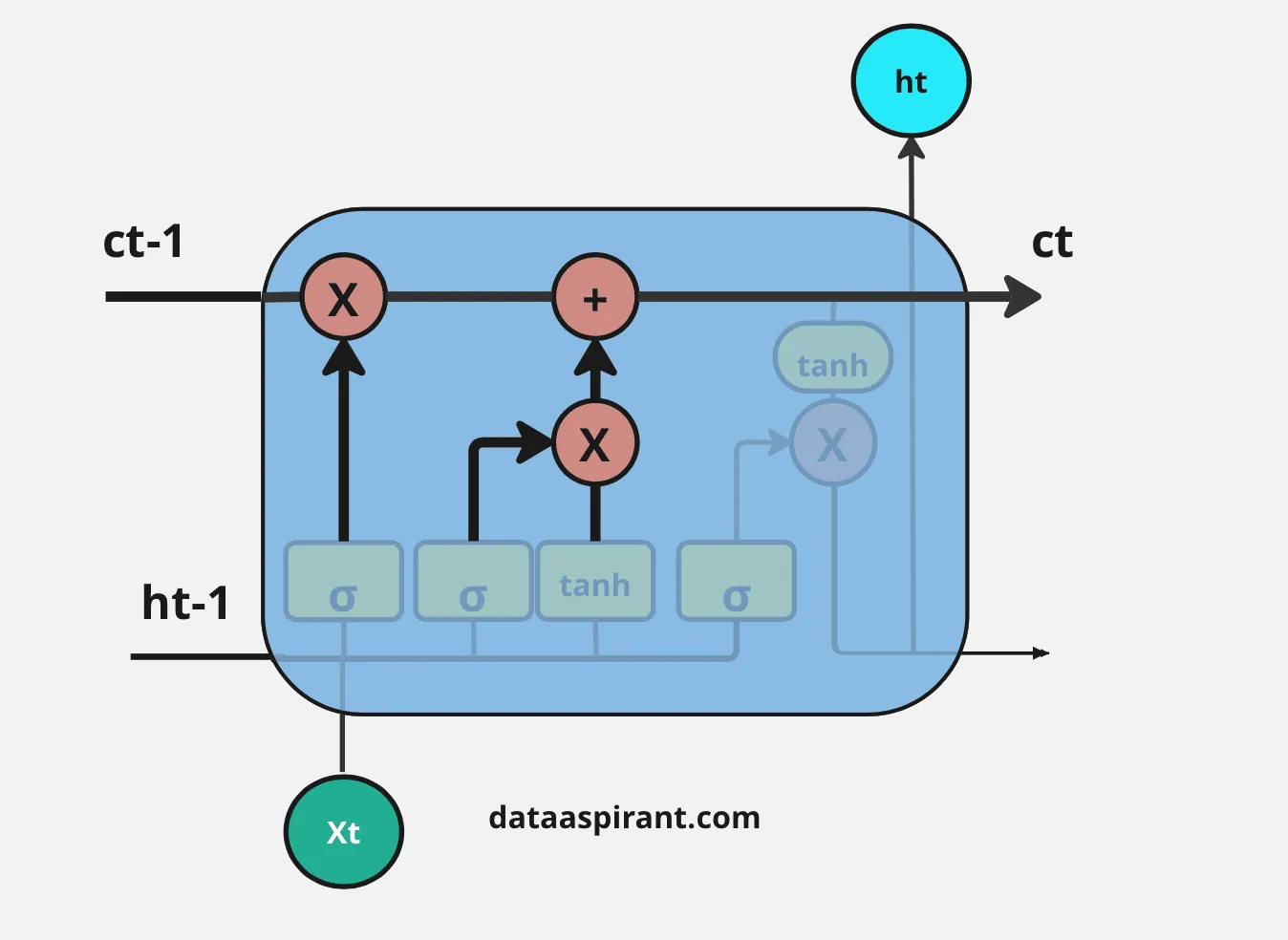
LSTM架构中的最后一步是决定将哪些信息作为输出;在LSTM中执行这一过程的最后一个门是“输出门”。这个输出将基于我们的细胞状态,但会是经过筛选的版本。
在这个门中,我们首先应用Sigmoid神经网络,它的输入和之前门的Sigmoid层一样:上一个时间步的隐藏层信息( h t − 1 h_{t-1} ht−1)和当前时间输入( x t x_t xt),以决定细胞状态信息的哪些部分将作为输出。
然后将更新后的细胞状态信息通过Tanh神经网络层进行调节(将值压缩到-1和1之间),然后对Sigmoid神经网络层和Tanh神经网络层的两个结果进行逐元素乘法操作。
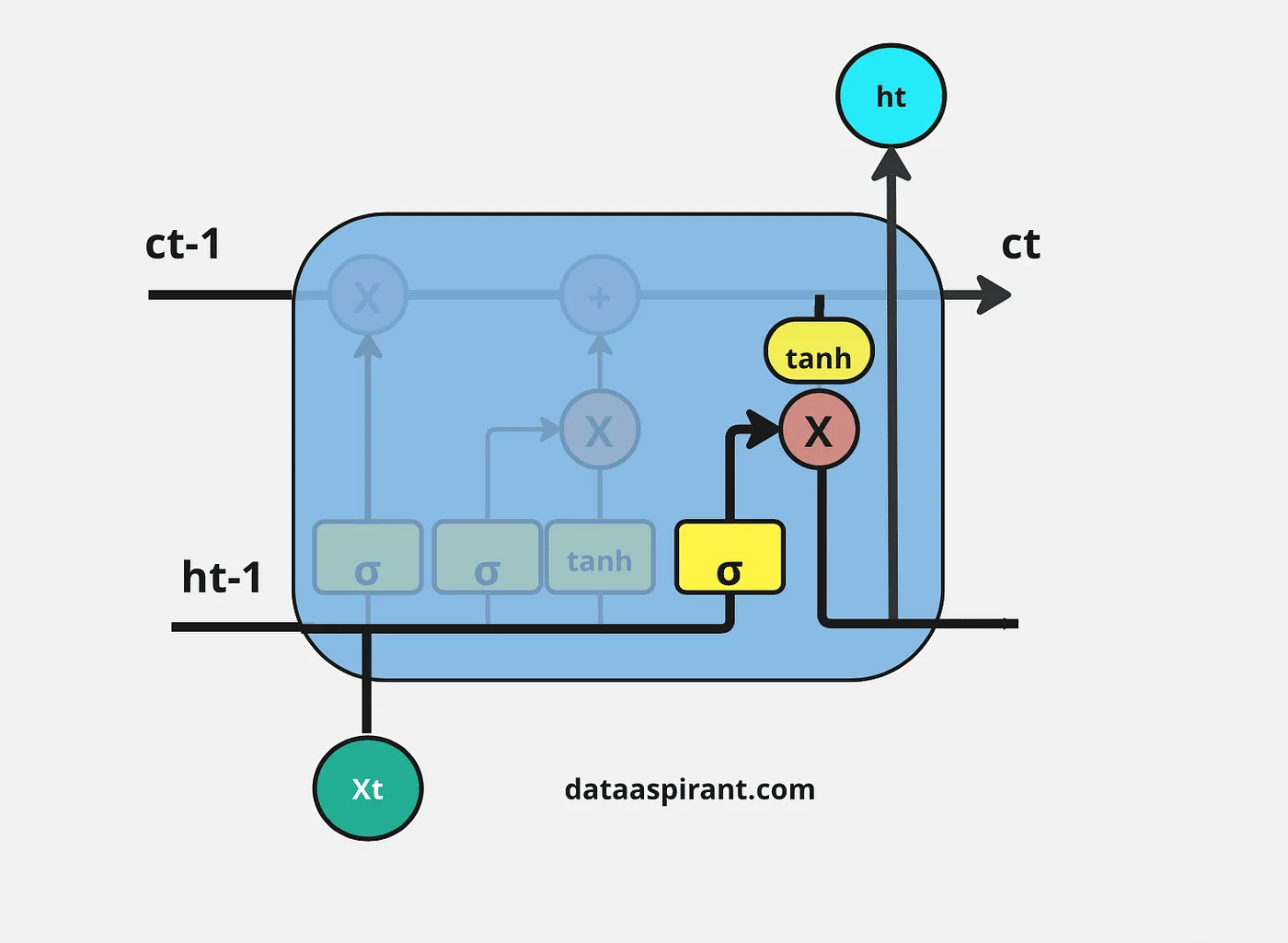
整个过程在LSTM架构的每个模块中重复进行。
4. LSTM架构的类型
LSTM是解决或处理序列预测问题的一个非常有趣的切入点。根据LSTM网络作为层的使用方式,我们可以将LSTM架构分为多种类型。

本节将讨论最常用的五种不同类型的LSTM架构,它们分别是:
- 普通LSTM(Vanilla LSTM):普通LSTM架构是基本的LSTM架构,它只有一个隐藏层和一个输出层来预测结果。
- 堆叠式LSTM(Stacked LSTM):堆叠式LSTM架构是一种将多个LSTM层压缩成一个列表的LSTM网络模型,也被称为深度LSTM网络模型。在这种架构中,每个LSTM层预测输出序列并将其发送到下一个LSTM层,而不是预测单个输出值。然后,最后一个LSTM层预测单个输出。
- 卷积神经网络与LSTM结合的架构(CNN LSTM):CNN LSTM架构是CNN和LSTM架构的结合。这种架构使用CNN网络层从输入中提取关键特征,然后将这些特征发送到LSTM层,以支持序列预测。这种架构的一个应用示例是为输入图像或图像序列(如视频)生成文本描述。
- 编码器-解码器LSTM(Encoder-Decoder LSTM):编码器-解码器LSTM架构是一种特殊的LSTM架构,主要用于解决序列到序列的问题,如机器翻译、语音识别等。编码器-解码器LSTM的另一个名称是seq2seq(序列到序列)。序列到序列的问题在自然语言处理领域是具有挑战性的问题,因为在这些问题中,输入和输出项的数量可能会有所不同。编码器-解码器LSTM架构有一个编码器,用于将输入转换为中间编码器向量。然后,一个解码器将中间编码器向量转换为最终结果。编码器和解码器都是堆叠式的LSTM。
- 双向LSTM(Bidirectional LSTM):双向LSTM架构是传统LSTM架构的扩展。这种架构更适合于序列分类问题,如情感分类、意图分类等。双向LSTM架构使用两个LSTM,而不是一个LSTM,一个用于前向(从左到右),另一个用于后向(从右到左)。这种架构比传统的LSTM能够为网络提供更多的上下文信息,因为它会从单词的左右两侧收集信息。这将提高序列分类问题的性能。
5. 用Python从零构建LSTM
在本节中,我们将参考本文前面介绍的数学基础和概念,逐步剖析在Python中实现LSTM的过程。我们将使用谷歌股票数据来训练我们从零构建的模型。该数据集是从Kaggle上获取的,可免费用于商业用途。
5.1 导入库和初始设置
numpy(np)和pandas(pd):用于所有数组和数据帧操作,这在任何类型的数值计算中都是基础操作,尤其是在神经网络的实现中。WeightInitializer、PlotManager和EarlyStopping类是自定义类。
WeightInitializer类:
import numpy as np
import pandas as pd
from src.model import WeightInitializer
from src.trainer import PlotManager, EarlyStopping
class WeightInitializer:
def __init__(self, method='random'):
self.method = method
def initialize(self, shape):
if self.method == 'random':
return np.random.randn(*shape)
elif self.method == 'xavier':
return np.random.randn(*shape) / np.sqrt(shape[0])
elif self.method == 'he':
return np.random.randn(*shape) * np.sqrt(2 / shape[0])
elif self.method == 'uniform':
return np.random.uniform(-1, 1, shape)
else:
raise ValueError(f'Unknown initialization method: {
self.method}')
WeightInitializer是一个自定义类,用于处理权重的初始化。这一点至关重要,因为不同的初始化方法会显著影响LSTM的收敛行为。
PlotManager类:
class PlotManager:
def __init__(self):
self.fig, self.ax = plt.subplots(3, 1, figsize=(6, 4))
def plot_losses(self, train_losses, val_losses):
self.ax.plot(train_losses, label='Training Loss')
self.ax.plot(val_losses, label='Validation Loss')
self.ax.set_title('Training and Validation Losses')
self.ax.set_xlabel('Epoch')
self.ax.set_ylabel('Loss')
self.ax.legend()
def show_plots(self):
plt.tight_layout()
这是src.trainer中的实用类,用于管理绘图,它使我们能够绘制训练损失和验证损失的图像。
EarlyStopping类:
class EarlyStopping:
"""
Early stopping to stop the training when the loss does not improve after
Args:
-----
patience (int): Number of epochs to wait before stopping the training.
verbose (bool): If True, prints a message for each epoch where the loss
does not improve.
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
"""
def __init__(self, patience=7, verbose=False, delta=0):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.delta = delta
def __call__(self, val_loss):
"""
Determines if the model should stop training.
Args:
val_loss (float): The loss of the model on the validation set.
"""
score = -val_loss
if self.best_score is None:
self.best_score = score
elif score < self.best_score + self.delta:
self.counter += 1
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.counter = 0
这是src.trainer中的实用类,用于在训练过程中处理提前停止操作,以防止过拟合。你可以在这篇文章中了解更多关于EarlyStopping的信息,以及它的功能对深度神经网络为何极其有用。
5.2 LSTM类
首先,让我们看看整个类的样子,然后将其分解为更易于管理的步骤:
class LSTM:
"""
Long Short-Term Memory (LSTM) network.
Parameters:
- input_size: int, dimensionality of input space
- hidden_size: int, number of LSTM units
- output_size: int, dimensionality of output space
- init_method: str, weight initialization method (default: 'xavier')
"""
def __init__(self, input_size, hidden_size, output_size, init_method='xavier'):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.weight_initializer = WeightInitializer(method=init_method)
# Initialize weights
self.wf = self.weight_initializer.initialize((hidden_size, hidden_size + input_size))
self.wi = self.weight_initializer.initialize((hidden_size, hidden_size + input_size))
self.wo = self.weight_initializer.initialize((hidden_size, hidden_size + input_size))
self.wc = self.weight_initializer.initialize((hidden_size, hidden_size + input_size))
# Initialize biases
self.bf = np.zeros((hidden_size, 1))
self.bi = np.zeros((hidden_size, 1))
self.bo = np.zeros((hidden_size, 1))
self.bc = np.zeros((hidden_size, 1))
# Initialize output layer weights and biases
self.why = self.weight_initializer.initialize((output_size, hidden_size))
self.by = np.zeros((output_size, 1))
@staticmethod
def sigmoid(z):
"""
Sigmoid activation function.
Parameters:
- z: np.ndarray, input to the activation function
Returns:
- np.ndarray, output of the activation function
"""
return 1 / (1 + np.exp(-z))
@staticmethod
def dsigmoid(y):
"""
Derivative of the sigmoid activation function.
Parameters:
- y: np.ndarray, output of the sigmoid activation function
Returns:
- np.ndarray, derivative of the sigmoid function
"""
return y * (1 - y)
@staticmethod
def dtanh(y):
"""
Derivative of the hyperbolic tangent activation function.
Parameters:
- y: np.ndarray, output of the hyperbolic tangent activation function
Returns:
- np.ndarray, derivative of the hyperbolic tangent function
"""
return 1 - y * y
def forward(self, x):
"""
Forward pass through the LSTM network.
Parameters:
- x: np.ndarray, input to the network
Returns:
- np.ndarray, output of the network
- list, caches containing intermediate values for backpropagation
"""
caches = []
h_prev = np.zeros((self.hidden_size, 1))
c_prev = np.zeros((self.hidden_size, 1))
h = h_prev
c = c_prev
for t in range(x.shape[0]):
x_t = x[t].reshape(-1, 1)
combined = np.vstack((h_prev, x_t))
f = self.sigmoid(np.dot(self.wf, combined) + self.bf)
i = self.sigmoid(np.dot(self.wi, combined) + self.bi)
o = self.sigmoid(np.dot(self.wo, combined) + self.bo)
c_ = np.tanh(np.dot(self.wc, combined) + self.bc)
c = f * c_prev + i * c_
h = o * np.tanh(c)
cache = (h_prev, c_prev, f, i, o, c_, x_t, combined, c, h)
caches.append(cache)
h_prev, c_prev = h, c
y = np.dot(self.why, h) + self.by
return y, caches
def backward(self, dy, caches, clip_value=1.0):
"""
Backward pass through the LSTM network.
Parameters:
- dy: np.ndarray, gradient of the loss with respect to the output
- caches: list, caches from the forward pass
- clip_value: float, value to clip gradients to (default: 1.0)
Returns:
- tuple, gradients of the loss with respect to the parameters
"""
dWf, dWi, dWo, dWc = [np.zeros_like(w) for w in (self.wf, self.wi, self.wo, self.wc)]
dbf, dbi, dbo, dbc = [np.zeros_like(b) for b in (self.bf, self.bi, self.bo, self.bc)]
dWhy = np.zeros_like(self.why)
dby = np.zeros_like(self.by)
# Ensure dy is reshaped to match output size
dy = dy.reshape(self.output_size, -1)
dh_next = np.zeros((self.hidden_size, 1)) # shape must match hidden_size
dc_next = np.zeros_like(dh_next)
for cache in reversed(caches):
h_prev, c_prev, f, i, o, c_, x_t, combined, c, h = cache
# Add gradient from next step to current output gradient
dh = np.dot(self.why.T, dy) + dh_next
dc = dc_next + (dh * o * self.dtanh(np.tanh(c)))
df = dc * c_prev * self.dsigmoid(f)
di = dc * c_ * self.dsigmoid(i)
do = dh * self.dtanh(np.tanh(c))
dc_ = dc * i * self.dtanh(c_)
dcombined_f = np.dot(self.wf.T, df)
dcombined_i = np.dot(self.wi.T, di)
dcombined_o = np.dot(self.wo.T, do)
dcombined_c = np.dot(self.wc.T, dc_)
dcombined = dcombined_f + dcombined_i + dcombined_o + dcombined_c
dh_next = dcombined[:self.hidden_size]
dc_next = f * dc
dWf += np.dot(df, combined.T)
dWi += np.dot(di, combined.T)
dWo += np.dot(do, combined.T)
dWc += np.dot(dc_, combined.T)
dbf += df.sum(axis=1, keepdims=True)
dbi += di.sum(axis=1, keepdims=True)
dbo += do.sum(axis=1, keepdims=True)
dbc += dc_.sum(axis=1, keepdims=True)
dWhy += np.dot(dy, h.T)
dby += dy
gradients = (dWf, dWi, dWo, dWc, dbf, dbi, dbo, dbc, dWhy, dby)
# Gradient clipping
for i in range(len(gradients)):
np.clip(gradients[i], -clip_value, clip_value, out=gradients[i])
return gradients
def update_params(self, grads, learning_rate):
"""
Update the parameters of the network using the gradients.
Parameters:
- grads: tuple, gradients of the loss with respect to the parameters
- learning_rate: float, learning rate
"""
dWf, dWi, dWo, dWc, dbf, dbi, dbo, dbc, dWhy, dby = grads
self.wf -= learning_rate * dWf
self.wi -= learning_rate * dWi
self.wo -= learning_rate * dWo
self.wc -= learning_rate * dWc
self.bf -= learning_rate * dbf
self.bi -= learning_rate * dbi
self.bo -= learning_rate * dbo
self.bc -= learning_rate * dbc
self.why -= learning_rate * dWhy
self.by -= learning_rate * dby
初始化
__init__方法使用指定的输入层、隐藏层和输出层的大小来初始化一个LSTM实例,并选择一种权重初始化方法。
为门(遗忘门wf、输入门wi、输出门wo和细胞门wc)以及将最后一个隐藏状态连接到输出的权重(why)初始化权重。通常选择Xavier初始化方法,因为它是保持各层激活值方差的一个很好的默认选择。
所有门和输出层的偏置都初始化为零。这是一种常见的做法,尽管有时会添加小的常数以避免在开始时出现神经元死亡的情况。
前向传播方法
我们首先将上一个隐藏状态h_prev和细胞状态c_prev设置为零,这对于第一个时间步来说是典型的做法。
def forward(self, x):
输入x按时间步进行处理,每个时间步都会更新门的激活值、细胞状态和隐藏状态。
for t in range(x.shape[0]):
x_t = x[t].reshape(-1, 1)
combined = np.vstack((h_prev, x_t))
在每个时间步,输入和上一个隐藏状态垂直堆叠,形成一个用于矩阵运算的单个组合输入。这对于一次性高效地执行线性变换至关重要。
f = self.sigmoid(np.dot(self.wf, combined) + self.bf)
i = self.sigmoid(np.dot(self.wi, combined) + self.bi)
o = self.sigmoid(np.dot(self.wo, combined) + self.bo)
c_ = np.tanh(np.dot(self.wc, combined) + self.bc)
c = f * c_prev + i * c_
h = o * np.tanh(c)
每个门(遗忘门、输入门、输出门)使用Sigmoid函数计算其激活值,这会影响细胞状态和隐藏状态的更新方式。
在这里,遗忘门(f)决定保留上一个细胞状态的多少。
输入门(i)决定添加多少新的候选细胞状态(c_)。
最后,输出门(o)计算将细胞状态的哪一部分作为隐藏状态输出。
细胞状态作为上一个状态和新候选状态的加权和进行更新。隐藏状态是通过将更新后的细胞状态通过一个Tanh函数,然后用输出门进行门控得到的。
cache = (h_prev, c_prev, f, i, o, c_, x_t, combined, c, h)
caches.append(cache)
我们将反向传播所需的相关值存储在cache中,这包括状态、门激活值和输入。
y = np.dot(self.why, h) + self.by
最后,输出y计算为最后一个隐藏状态的线性变换。该方法返回输出和缓存的值,以便在反向传播期间使用。
反向传播方法
此方法用于计算损失函数关于LSTM权重和偏置的梯度。在训练过程中,这些梯度对于更新模型参数是必不可少的。
def backward(self, dy, caches, clip_value=1.0):
dWf, dWi, dWo, dWc = [np.zeros_like(w) for w in (self.wf, self.wi, self.wo, self.wc)]
dbf, dbi, dbo, dbc = [np.zeros_like(b) for b in (self.bf, self.bi, self.bo, self.bc)]
dWhy = np.zeros_like(self.why)
dby = np.zeros_like(self.by)
所有权重(dWf、dWi、dWo、dWc、dWhy)和偏置(dbf、dbi、dbo、dbc、dby)的梯度都初始化为零。这是必要的,因为梯度是在序列的每个时间步上累加的。
dy = dy.reshape(self.output_size, -1)
dh_next = np.zeros((self.hidden_size, 1))
dc_next = np.zeros_like(dh_next)
在这里,我们确保dy的形状适合进行矩阵运算。dh_next和dc_next存储从后续时间步反向传播回来的梯度。
for cache in reversed(caches):
h_prev, c_prev, f, i, o, c_, x_t, combined, c, h = cache
从缓存中提取每个时间步的LSTM状态和门的激活值。处理从最后一个时间步开始并向前推进(reversed(caches)),这对于在循环神经网络中正确应用链式法则(通过时间的反向传播 - BPTT)至关重要。
dh = np.dot(self.why.T, dy) + dh_next
dc = dc_next + (dh * o * self.dtanh(np.tanh(c)))
df = dc * c_prev * self.dsigmoid(f)
di = dc * c_ * self.dsigmoid(i)
do = dh * self.dtanh(np.tanh(c))
dc_ = dc * i * self.dtanh(c_)
dh和dc分别是损失关于隐藏状态和细胞状态的梯度。每个门(df、di、do)和候选细胞状态(dc_)的梯度使用链式法则计算,涉及Sigmoid(dsigmoid)和双曲正切(dtanh)函数的导数,这些在门控机制部分已经讨论过。
dWf += np.dot(df, combined.T)
dWi += np.dot(di, combined.T)
dWo += np.dot(do, combined.T)
dWc += np.dot(dc_, combined.T)
dbf += df.sum(axis=1, keepdims=True)
dbi += di.sum(axis=1, keepdims=True)
dbo += do.sum(axis=1, keepdims=True)
dbc += dc_.sum(axis=1, keepdims=True)
这些代码行将每个权重和偏置在所有时间步上的梯度进行累加。
for i in range(len(gradients)):
np.clip(gradients[i], -clip_value, clip_value, out=gradients[i])
为了防止梯度爆炸,我们将梯度裁剪到指定的范围(clip_value),这是训练循环神经网络时的常见做法。
参数更新方法
def update_params(self, grads, learning_rate):
dWf, dWi, dWo, dWc, dbf, dbi, dbo, dbc, dWhy, dby = grads
...
self.wf -= learning_rate * dWf
...
每个权重和偏置通过减去相应梯度的一部分(learning_rate)来更新。这一步调整模型参数以最小化损失函数。
5.3 训练与验证
class LSTMTrainer:
"""
LSTM网络的训练器。
参数:
- model: LSTM,要训练的LSTM网络
- learning_rate: float,优化器的学习率
- patience: int,在提前停止训练前等待的轮数
- verbose: bool,是否打印训练信息
- delta: float,验证损失有改善的最小变化量
"""
def __init__(self, model, learning_rate=0.01, patience=7, verbose=True, delta=0):
self.model = model
self.learning_rate = learning_rate
self.train_losses = []
self.val_losses = []
self.early_stopping = EarlyStopping(patience, verbose, delta)
def train(self, X_train, y_train, X_val=None, y_val=None, epochs=10, batch_size=1, clip_value=1.0):
"""
训练LSTM网络。
参数:
- X_train: np.ndarray,训练数据
- y_train: np.ndarray,训练标签
- X_val: np.ndarray,验证数据
- y_val: np.ndarray,验证标签
- epochs: int,训练轮数
- batch_size: int,小批量的大小
- clip_value: float,梯度裁剪的值
"""
for epoch in range(epochs):
epoch_losses = []
for i in range(0, len(X_train), batch_size):
batch_X = X_train[i:i + batch_size]
batch_y = y_train[i:i + batch_size]
losses = []
for x, y_true in zip(batch_X, batch_y):
y_pred, caches = self.model.forward(x)
loss = self.compute_loss(y_pred, y_true.reshape(-1, 1))
losses.append(loss)
# 反向传播以获取梯度
dy = y_pred - y_true.reshape(-1, 1)
grads = self.model.backward(dy, caches, clip_value=clip_value)
self.model.update_params(grads, self.learning_rate)
batch_loss = np.mean(losses)
epoch_losses.append(batch_loss)
avg_epoch_loss = np.mean(epoch_losses)
self.train_losses.append(avg_epoch_loss)
if X_val is not None and y_val is not None:
val_loss = self.validate(X_val, y_val)
self.val_losses.append(val_loss)
print(f'轮数 {
epoch + 1}/{
epochs} - 损失: {
avg_epoch_loss:.5f}, 验证损失: {
val_loss:.5f}')
# 检查提前停止条件
self.early_stopping(val_loss)
if self.early_stopping.early_stop:
print("提前停止")
break
else:
print(f'轮数 {
epoch + 1}/{
epochs} - 损失: {
avg_epoch_loss:.5f}')
def compute_loss(self, y_pred, y_true):
"""
计算均方误差损失。
"""
return np.mean((y_pred - y_true) ** 2)
def validate(self, X_val, y_val):
"""
在单独的数据集上验证模型。
"""
val_losses = []
for x, y_true in zip(X_val, y_val):
y_pred, _ = self.model.forward(x)
loss = self.compute_loss(y_pred, y_true.reshape(-1, 1))
val_losses.append(loss)
return np.mean(val_losses)
训练器会在多个轮次中协调训练过程,处理数据批次,并可选择对模型进行验证。
for epoch in range(epochs):
...
for i in range(0, len(X_train), batch_size):
...
for x, y_true in zip(batch_X, batch_y):
y_pred, caches = self.model.forward(x)
...
每一批数据都会输入到模型中。前向传播会生成预测结果,并缓存用于反向传播的中间值。
dy = y_pred - y_true.reshape(-1, 1)
grads = self.model.backward(dy, caches, clip_value=clip_value)
self.model.update_params(grads, self.learning_rate)
计算损失后,使用关于预测误差的梯度(dy)进行反向传播。得到的梯度用于更新模型参数。
print(f'轮数 {
epoch + 1}/{
epochs} - 损失: {
avg_epoch_loss:.5f}')
记录训练进度,以帮助长期监控模型的性能。
5.4 数据预处理
class TimeSeriesDataset:
"""
时间序列数据的数据集类。
参数:
- ticker: str,股票代码
- start_date: str,数据检索的开始日期
- end_date: str,数据检索的结束日期
- look_back: int,每个样本中包含的前几个时间步的数量
- train_size: float,用于训练的数据比例
"""
def __init__(self, start_date, end_date, look_back=1, train_size=0.67):
self.start_date = start_date
self.end_date = end_date
self.look_back = look_back
self.train_size = train_size
def load_data(self):
"""
加载股票数据。
返回:
- np.ndarray,训练数据
- np.ndarray,测试数据
"""
df = pd.read_csv('data/google.csv')
df = df[(df['Date'] >= self.start_date) & (df['Date'] <= self.end_date)]
df = df.sort_index()
df = df.loc[self.start_date:self.end_date]
df = df[['Close']].astype(float) # 使用收盘价
df = self.MinMaxScaler(df.values) # 将DataFrame转换为numpy数组
train_size = int(len(df) * self.train_size)
train, test = df[0:train_size,:], df[train_size:len(df),:]
return train, test
def MinMaxScaler(self, data):
"""
对数据进行最小 - 最大缩放。
参数:
- data: np.ndarray,输入数据
"""
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7)
def create_dataset(self, dataset):
"""
创建用于时间序列预测的数据集。
参数:
- dataset: np.ndarray,输入数据
返回:
- np.ndarray,输入数据
- np.ndarray,输出数据
"""
dataX, dataY = [], []
for i in range(len(dataset)-self.look_back):
a = dataset[i:(i + self.look_back), 0]
dataX.append(a)
dataY.append(dataset[i + self.look_back, 0])
return np.array(dataX), np.array(dataY)
def get_train_test(self):
"""
获取训练和测试数据。
返回:
- np.ndarray,训练输入
- np.ndarray,训练输出
- np.ndarray,测试输入
- np.ndarray,测试输出
"""
train, test = self.load_data()
trainX, trainY = self.create_dataset(train)
testX, testY = self.create_dataset(test)
return trainX, trainY, testX, testY
这个类负责获取数据并将其预处理成适合训练LSTM的格式,包括缩放数据以及将其划分为训练集和测试集。
5.5 模型训练
现在,让我们利用上述定义的所有代码来加载数据集、对其进行预处理,并训练我们的LSTM模型。
首先,让我们加载数据集:
# 实例化数据集
dataset = TimeSeriesDataset('2010-1-1', '2020-12-31', look_back=1)
trainX, trainY, testX, testY = dataset.get_train_test()
在这个实例中,它被配置为从Kaggle获取谷歌(GOOGL)从2010年1月1日到2020年12月31日的历史数据。
look_back = 1:这个参数设置了每个输入样本中包含的过去时间步的数量。在这里,每个输入样本将包含前一个时间步的数据,这意味着模型将使用一天的数据来预测下一天的数据。
get_train_test():这个方法会处理获取到的数据,对其进行归一化,并将其划分为训练集和测试集。这对于在数据的一部分上训练模型,并在另一部分上验证其性能以检查是否过拟合是至关重要的。
# 重塑输入,使其形状为 [样本数, 时间步, 特征数]
trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1))
这个重塑步骤将数据格式调整为LSTM所期望的格式。LSTM要求输入的形状为[样本数, 时间步, 特征数]。
这里:
- 样本数:数据点的数量。
- 时间步:每个样本中的时间步数量(
look_back)。 - 特征数:每个时间步的特征数量(在这种情况下为1,因为我们可能只关注像收盘价这样的一维数据)。
look_back = 1 # 每个样本中包含的前几个时间步的数量
hidden_size = 256 # LSTM单元的数量
output_size = 1 # 输出空间的维度
lstm = LSTM(input_size=1, hidden_size=hidden_size, output_size=output_size)
在这段代码中:
hidden_size:隐藏层中LSTM单元的数量,这里设置为256。这决定了模型的容量,更多的单元可能会捕捉到更复杂的模式,但也需要更多的计算能力和数据来有效训练。output_size:输出维度,这里为1,表明模型每个输入样本预测一个单一的值,例如第二天的股票价格。
trainer = LSTMTrainer(lstm, learning_rate=1e-3, patience=50, verbose=True, delta=0.001)
trainer.train(trainX, trainY, testX, testY, epochs=1000, batch_size=32)
这里我们将学习率设置为1e - 3(0.001)。学习率过高会导致模型过快收敛到一个次优解,而过低则会使训练过程变慢,甚至可能陷入停滞。我们还将patience设置为50,如果验证损失在50个轮次内没有改善,模型训练将停止。
train()方法会在指定的轮数和批次大小下执行训练过程。在训练期间,模型会每10个轮次打印一次模型性能,输出结果类似于:
轮数 1/1000 - 损失: 0.25707, 验证损失: 0.43853
轮数 11/1000 - 损失: 0.06463, 验证损失: 0.06056
轮数 21/1000 - 损失: 0.05313, 验证损失: 0.02100
轮数 31/1000 - 损失: 0.04862, 验证损失: 0.01134
轮数 41/1000 - 损失: 0.04512, 验证损失: 0.00678
轮数 51/1000 - 损失: 0.04234, 验证损失: 0.00395
轮数 61/1000 - 损失: 0.04014, 验证损失: 0.00210
轮数 71/1000 - 损失: 0.03840, 验证损失: 0.00095
轮数 81/1000 - 损失: 0.03703, 验证损失: 0.00031
轮数 91/1000 - 损失: 0.03595, 验证损失: 0.00004
轮数 101/1000 - 损失: 0.03509, 验证损失: 0.00003
轮数 111/1000 - 损失: 0.03442, 验证损失: 0.00021
轮数 121/1000 - 损失: 0.03388, 验证损失: 0.00051
轮数 131/1000 - 损失: 0.03346, 验证损失: 0.00090
轮数 141/1000 - 损失: 0.03312, 验证损失: 0.00133
提前停止
最后,让我们绘制训练损失和验证损失,以便更好地了解模型可能的收敛或发散情况。我们可以使用以下代码实现:
plot_manager = PlotManager()
# 在训练循环中
plot_manager.plot_losses(trainer.train_losses, trainer.val_losses)
# 在训练循环结束后
plot_manager.show_plots()
这将绘制一个类似于下面的图表:
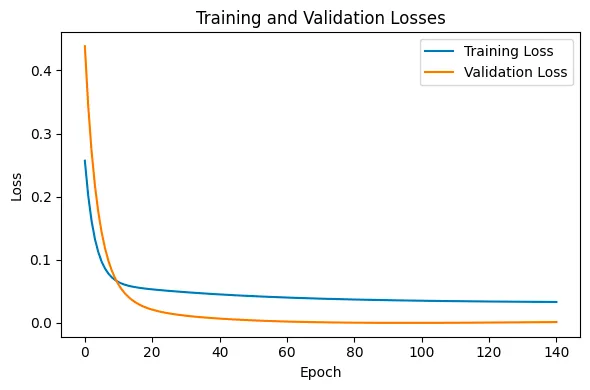
从图表中我们可以看到,在早期轮次中,训练损失和验证损失都迅速下降,这表明我们的初始化技术(Xavier)可能不太适合这个任务。尽管在大约90个轮次后触发了提前停止,取得了一些令人印象深刻的性能,但我们可以尝试降低学习率并增加训练轮数。此外,我们还可以尝试使用其他技术,如学习率调度器或Adam优化器。