文章总结
主要内容
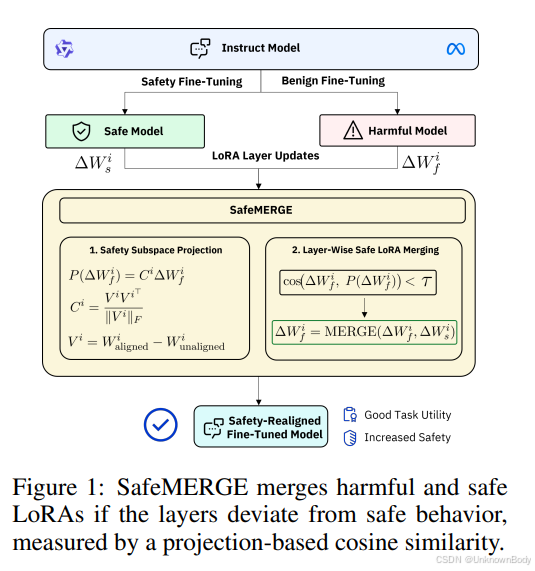
本文提出了一种名为SafeMERGE的后微调框架,旨在解决微调大型语言模型(LLMs)时无意中导致的安全对齐退化问题。通过选择性地合并微调模型与安全对齐模型的层(仅在偏离安全行为时合并),SafeMERGE在保持任务性能的同时显著减少有害输出。实验表明,该方法在Llama-2-7B-Chat和Qwen-2-7B-Instruct模型上对GSM8K和PubMedQA任务的效果优于现有基线,实现了安全性与实用性的最佳平衡。
创新点
- 选择性分层合并:通过余弦相似性准则识别不安全的层,仅对这些层进行安全模型合并,避免全局调整,减少性能损失。
- 模型无关性:无需定制微调或对齐技术,可与开源库(如Llama-Factory)无缝集成,提升实用性。
- 安全子空间指导:利用安全对齐子空间(基于基础模型与指令模型的权重差异)量化安全偏离ÿ