| 第一篇 | 基于DeepSeek+GIS的建设项目用地报批辅助系统 【系统概述】 |
|---|---|
| 第二篇 | 基于DeepSeek+GIS的建设项目用地报批辅助系统 【合规性审查】 |
| 第三篇 | 基于DeepSeek+GIS的建设项目用地报批辅助系统 【智能交互】 |
| 第四篇 | 基于DeepSeek+GIS的建设项目用地报批辅助系统 【AI辅助选址】 |
基于DeepSeek+GIS的建设项目用地报批辅助系统 【合规性审查】
系统依据 GIS 与 DeepSeek 协同分析结果,对建设项目用地进行全面合规性审查。审查内容涵盖是否符合土地利用总体规划、是否违反基本农田保护规定、是否满足生态保护要求、是否符合城乡规划布局等多个方面。若项目存在合规性问题,系统不仅明确指出具体违规点,还关联对应的法规政策条款,详细解释违规原因,并提供针对性的整改建议。例如,若项目因占用基本农田不符合规定,系统会清晰列出《基本农田保护条例》中相关禁止条款,并根据项目实际情况,给出如调整项目选址、进行土地置换等可行的优化方案。
一,系统实现效果展示
合规性审查前端页面
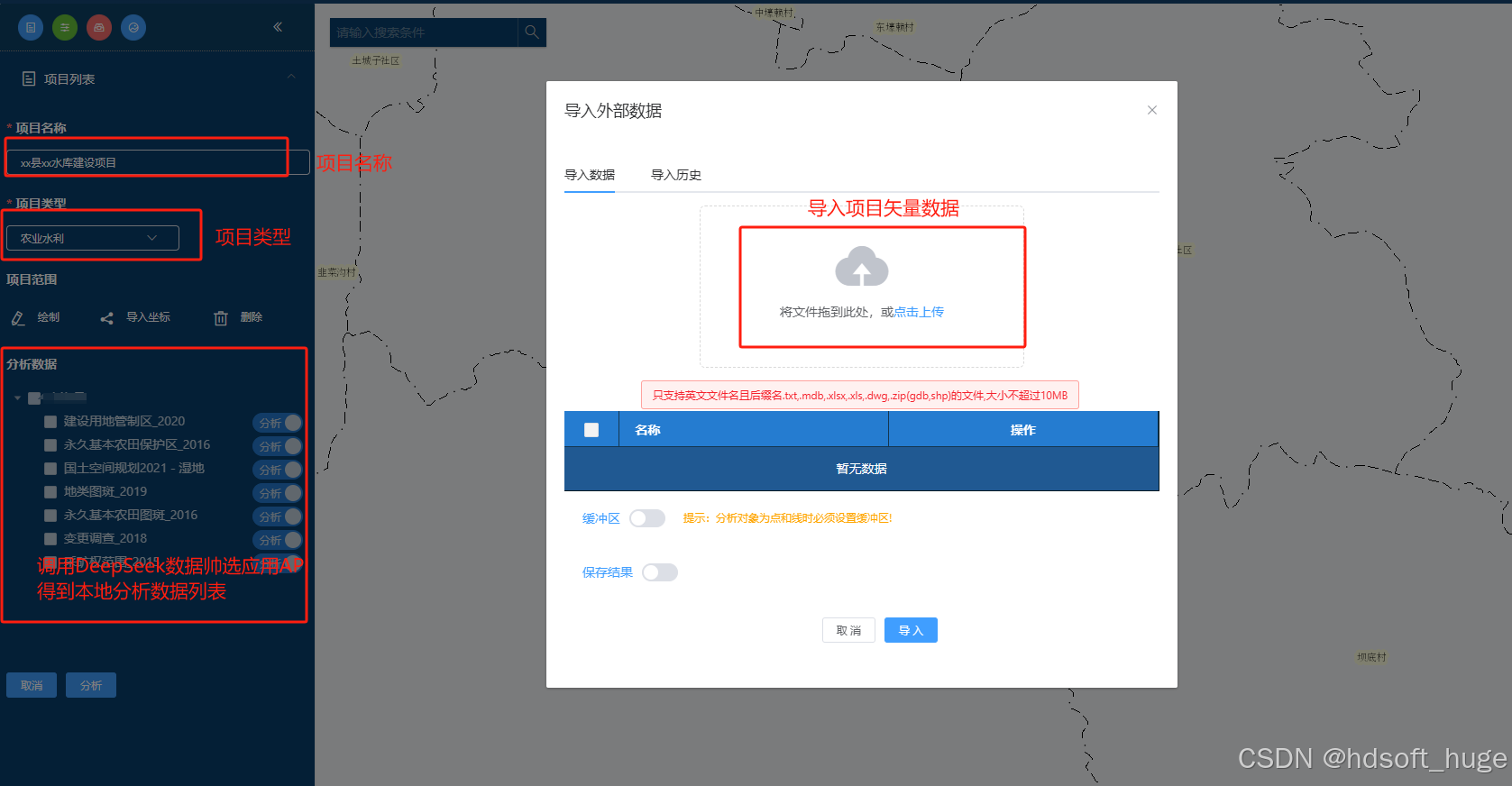
普通的水库建设项目分析效果
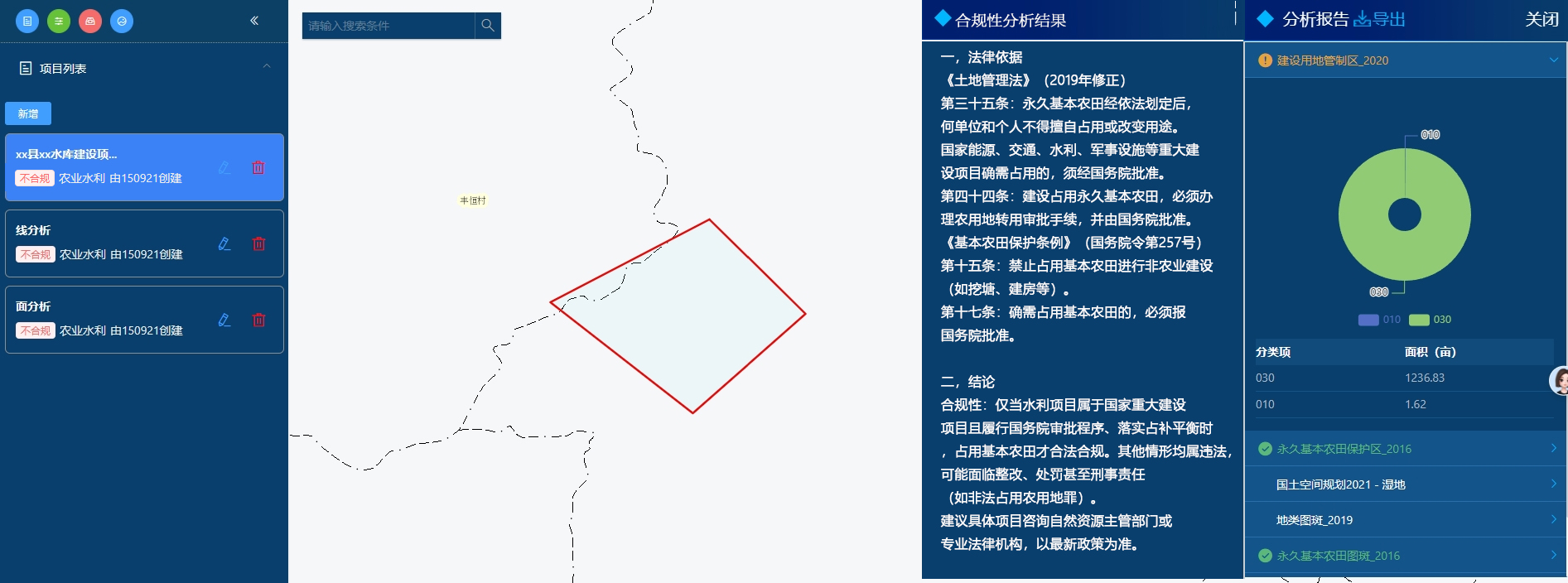
国家重点的水库建设项目分析效果
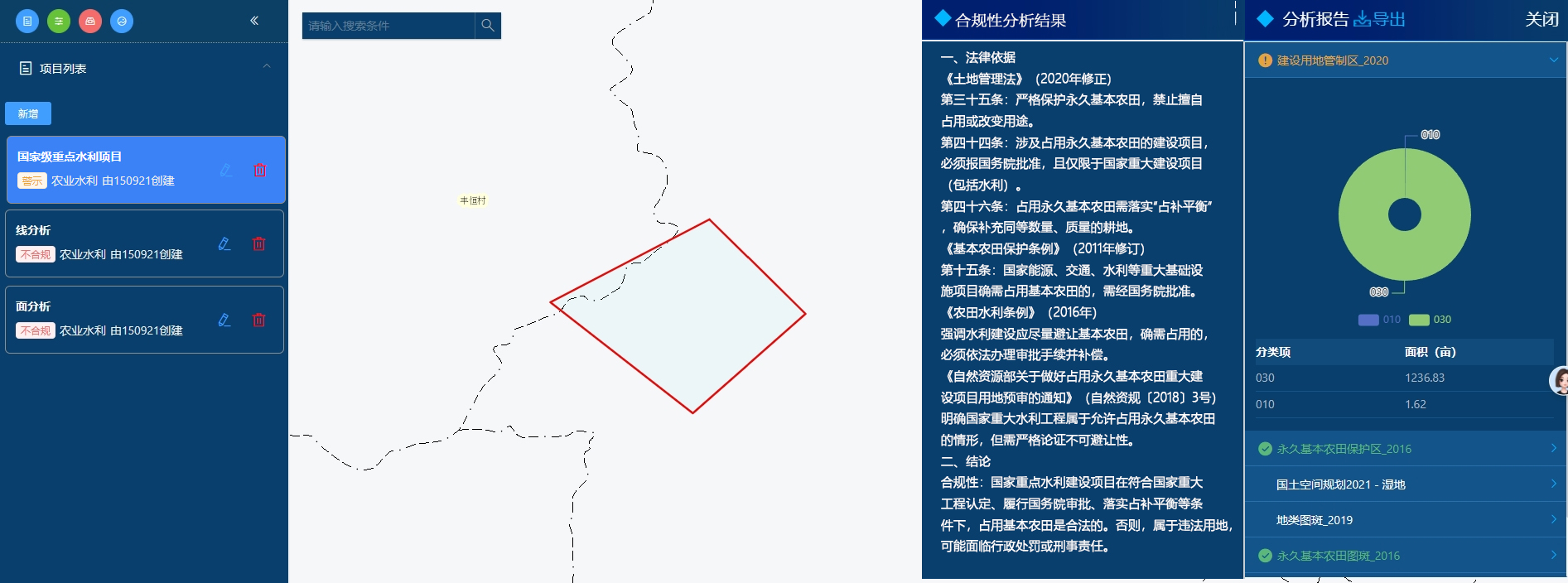
在对同类型但不同级别的项目进行分析时,两次评估结果存在差异。这清晰展现出,在特定条件下,项目对基本农田的占用符合法律法规和相关规章制度的要求。要是采用传统方法进行这类判断,不仅流程繁琐,还容易陷入困境。相较而言,借助 AI 开展分析,不仅大幅简化了操作流程,提升了分析效率,还确保了结果的准确性 。
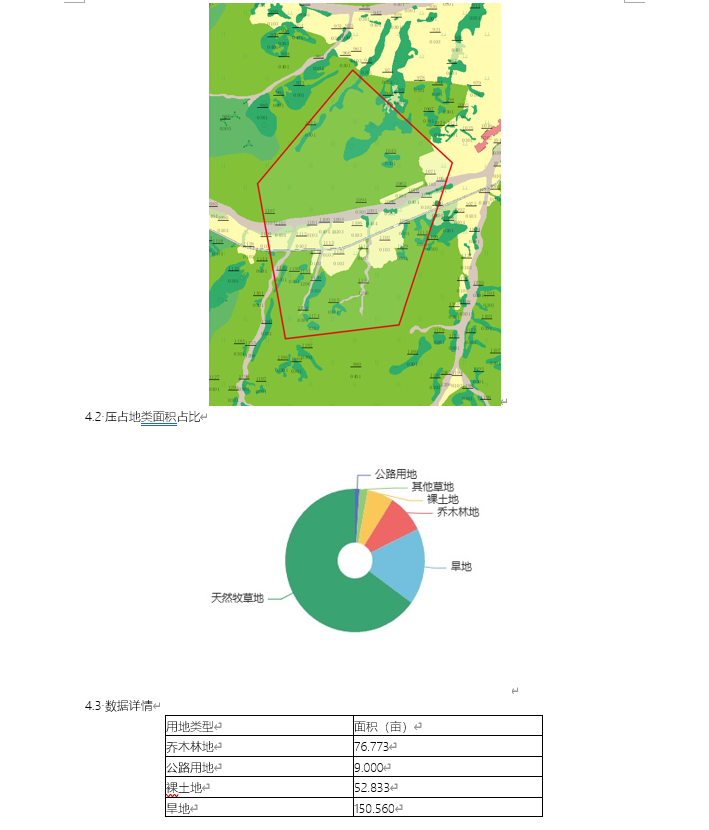
导出的报告(不是全部只粘贴了其中几页)




二,开发环境搭建
三,功能实现
该系统主要由 AI 智能数据筛选、叠加与缓冲分析,以及 AI 合规性分析三大核心部分构成。
- 在 AI智能数据筛选环节,系统依托先进的人工智能算法,能够从海量、繁杂的数据资源中,精准识别并筛选出与建设项目用地报批紧密相关的数据。这些数据涵盖土地利用现状、基本农田分布、生态保护红线范围、城乡规划布局以及土地权属等多方面信息。例如,在面对某大型建设项目时,系统可快速定位项目选址周边特定范围内的各类土地数据,确保后续分析数据的针对性与有效性。
- 叠加分析与缓冲分析模块中,系统运用 GIS 强大的空间分析能力开展工作。叠加分析通过将建设项目用地范围图层,与土地利用现状图层、基本农田保护区图层、生态保护红线图层等关键图层进行叠加操作,直观呈现项目与各类管控区域的空间关系,清晰展示项目是否占用特定土地类型或保护区。缓冲分析则针对河流、湖泊、文物保护区等具有特殊保护要求的区域,依据设定的缓冲距离生成缓冲区范围图层,再与项目用地范围进行叠加,以此判断项目是否侵入保护缓冲区,为后续合规性分析提供关键的空间分析基础。
- AI合规性分析部分,系统借助人工智能深度学习技术,对叠加分析与缓冲分析的结果进行深度解读。同时,结合对国家及地方相关土地法规政策的精准理解,以及对大量历史案例的学习,从多个维度对建设项目用地进行全面合规性评估。评估内容包含项目是否契合土地利用总体规划、是否违背基本农田保护规定、是否满足生态保护要求、是否符合城乡规划布局等重要方面。若项目存在合规性问题,系统不仅能明确指出具体违规点,关联对应的法规政策条款,详细解释违规原因,还能依据自身算法和经验,提供切实可行的整改建议。
(1) AI智能数据筛
在数据处理场景里,若采用传统方法,需依据数据类型,逐个整理并录入数据表。当数据处于高频变化的环境时,表格维护往往不及时,不仅流程繁琐,最终获取的数据也可能无法满足分析需求。
那么,该如何应对这一难题?将问题交由 DeepSeek 处理不失为理想之策。作为前沿的人工智能解决方案,DeepSeek 凭借多项技术优势,能够实现对动态数据的高效收集与精准分析,既节省时间,又保障数据的时效性与准确性 。
写了这么多至此来点实际的:
1,登录MaxKb 创建一个高级编排应用并设置基本信息
2,创建自定义函数查询空间数据库中的所有图层表及备注
先看样例数据(postgresql 数据库为例)
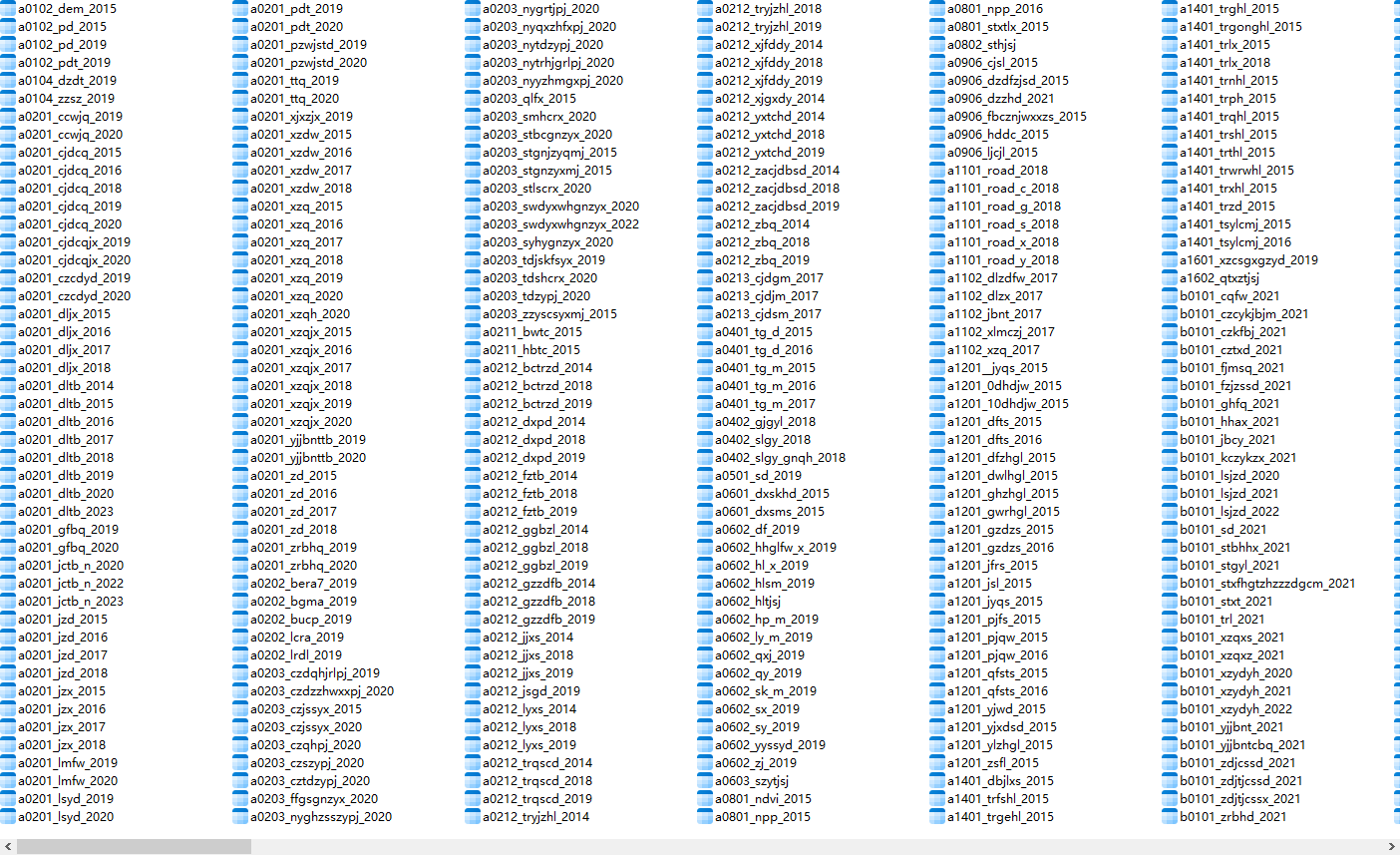
查询结果如下图(这个库中备注的表很有限但够演示效果,在正式应用环境中建议备注所有表)
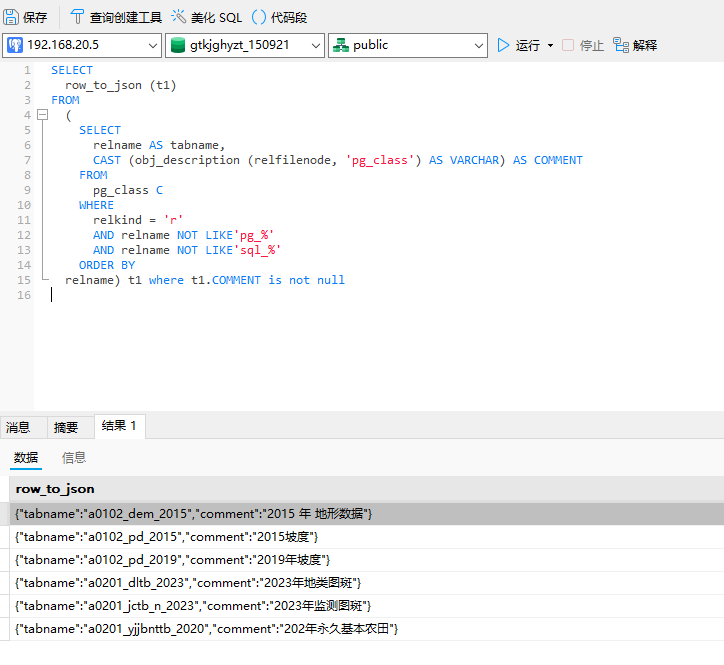
SELECT
row_to_json (t1)
FROM
(
SELECT
relname AS tabname,
CAST (obj_description (relfilenode, 'pg_class') AS VARCHAR) AS COMMENT
FROM
pg_class C
WHERE
relkind = 'r'
AND relname NOT LIKE'pg_%'
AND relname NOT LIKE'sql_%'
ORDER BY
relname) t1 where t1.COMMENT is not null
创建自定义函数

自定义函数代码如下(查询Postgresql 数据库中的所有表信息(表名、备注)):
# -*- coding: utf-8 -*-
import psycopg2
def execute_sql_query():
conn = psycopg2.connect(
host="192.168.20.5",
port="5432",
dbname="gtkjghyzt_150921",
user="postgres",
password="postgres"
)
cursor = conn.cursor()
query = "SELECT row_to_json (t1) FROM ( SELECT relname AS tabname, CAST (obj_description (relfilenode, 'pg_class') AS VARCHAR) AS COMMENT FROM pg_class C WHERE relkind = 'r' AND relname NOT LIKE'pg_%' AND relname NOT LIKE'sql_%' ORDER BY relname) t1 where t1.COMMENT is not null"
cursor.execute(query)
results = cursor.fetchall()
# print(results)
# for row in results:
# print(row)
# 提交事务(如果有数据修改操作)
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
return results
3,创建根据给出问题回答相关数据的AI节点
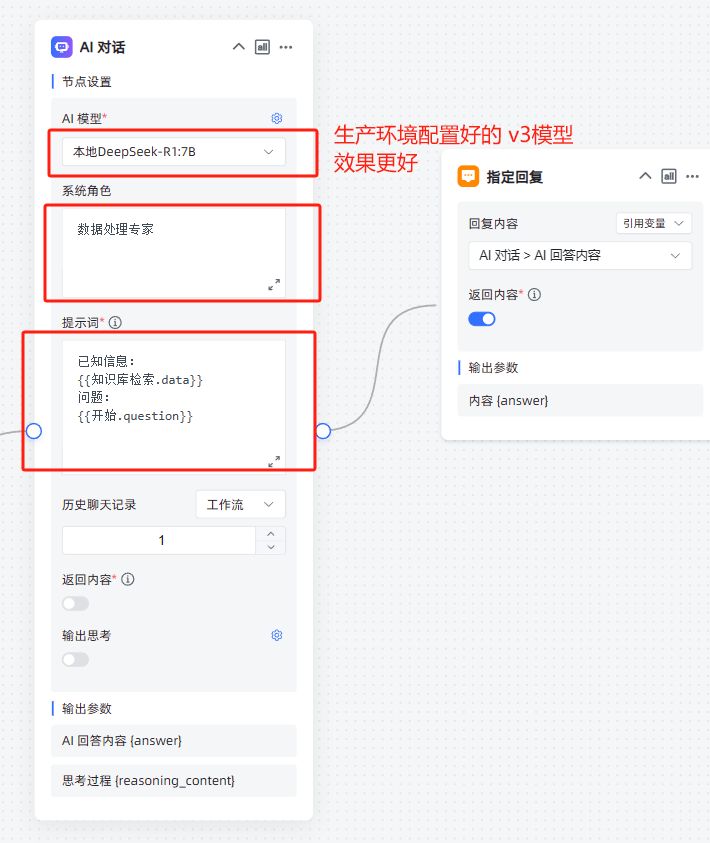
节点提示词如下:
角色定义:你是一个自然资源合规性分析业务专家。
任务描述:{
{
开始.question}} 项目合规性分析关数据有那些?。
输出要求:
1. 请详细列出所有相关数据的名称,多个数据则使用逗号隔开。
2. 请确保返回的内容中不包含任何代码框(如 ```或 ` 符号),仅返回纯文本。
4,创建根据回答数据帅选本地数据的AI节点
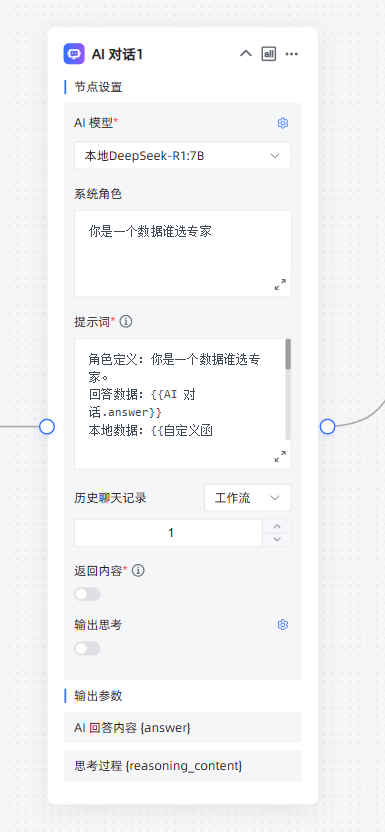
提示此如下:
角色定义:你是一个数据谁选专家。
回答数据:{
{
AI 对话.answer}}
本地数据:{
{
自定义函数.result}}
任务描述:本地数据为JSON格式其中tablename为表名,comment为注释,根据回答的数据与comment筛选本地数据最终获取tablename。
输出要求:
1. 请详细列出所有相关数据的名称,多个数据则使用逗号隔开。
2. 请确保返回的内容中不包含任何代码框(如 ```或 ` 符号),仅返回纯文本。
5,创建一个指定回复
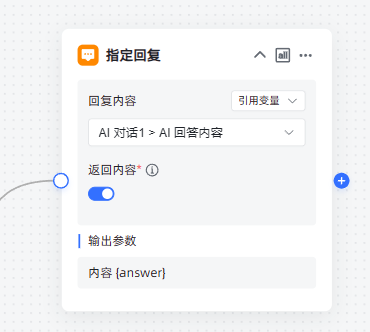
最终完整的流程图若下图:
到这里,前期数据筛选工作就完成了。接下来,保存代码并进行调试,检验实际效果。由于不同模型适用场景有别,在不同条件下运行,会产生各异结果。建议大家在调试过程中自主探索、灵活调整,让模型发挥出最佳效能 。也可以关注我在评论区共同探讨。
6,调试并优化
下面展示的,便是本次得出的结果。经比对,其与我预先设定的目标结果一致 。
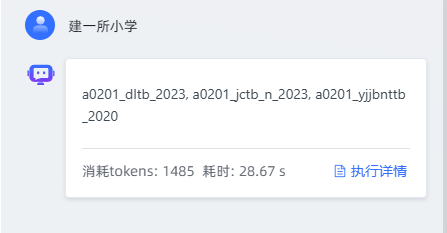
下面是执行详情及思考过程:
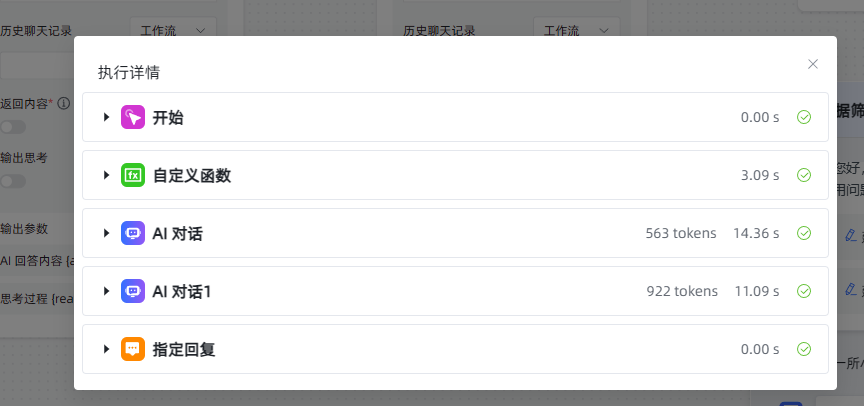
自定义函数输出结果的与设想结果一致
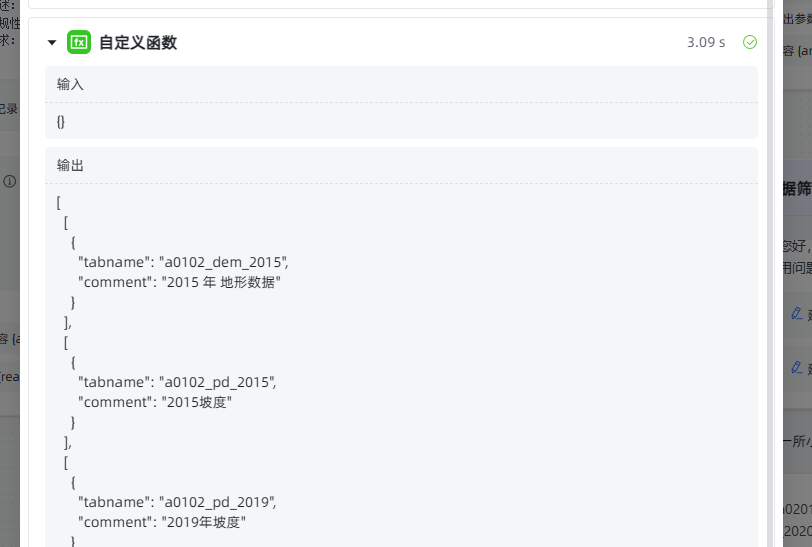
AI 针对问题所输出的数据信息,不仅条理清晰,且完全契合正常标准。

数据筛选环节运行正常。由于我使用的测试数据量有限,目前仅返回了三条数据。但可以确定,在数据充足的情况下,它在数据筛选方面,展现出的能力远超我们预期,能实现更高效、精准的筛选。
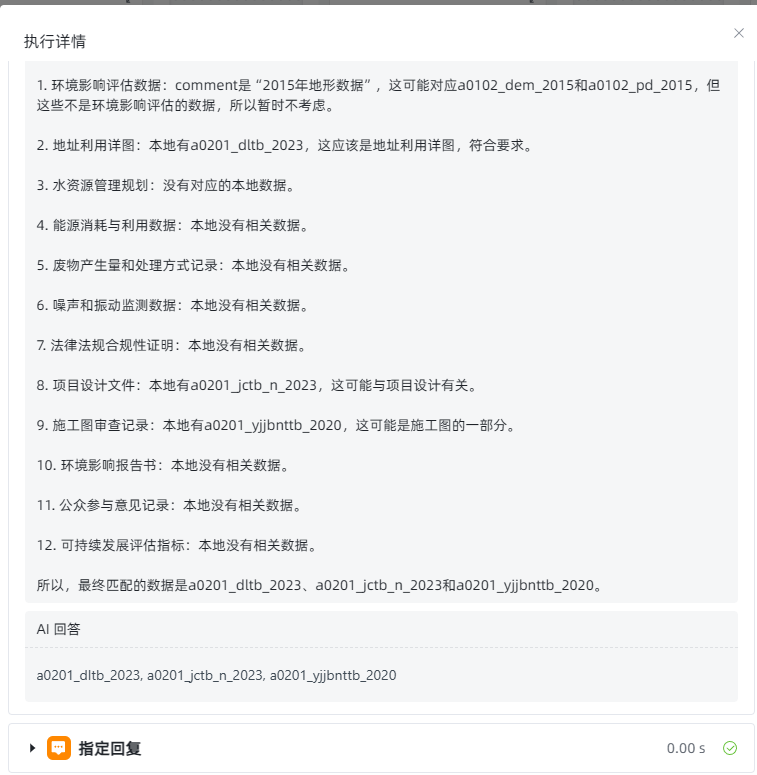
7,前端对接应用接口
这个步骤官方文档也有说明。步骤也比较简单如下图:
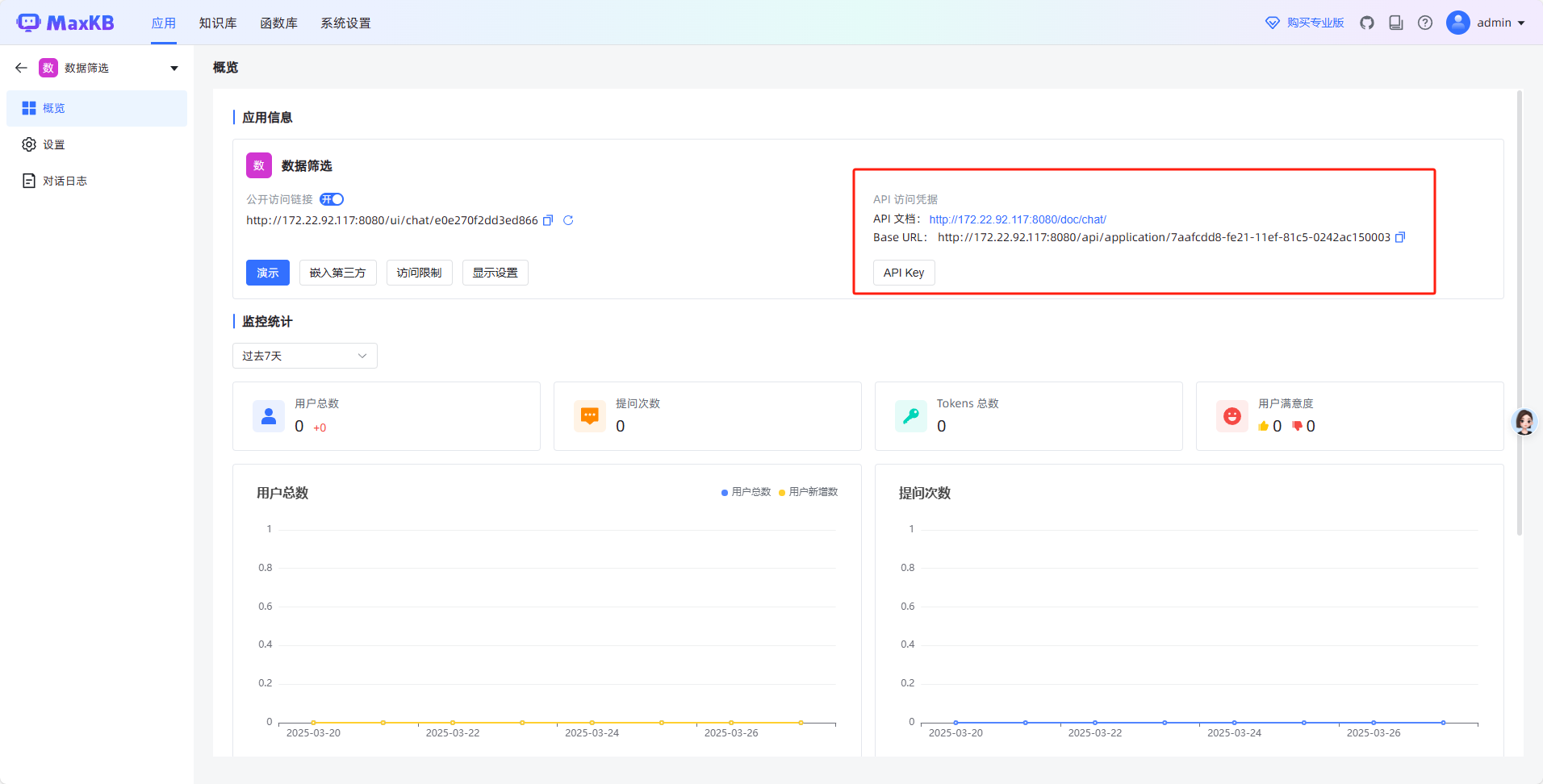
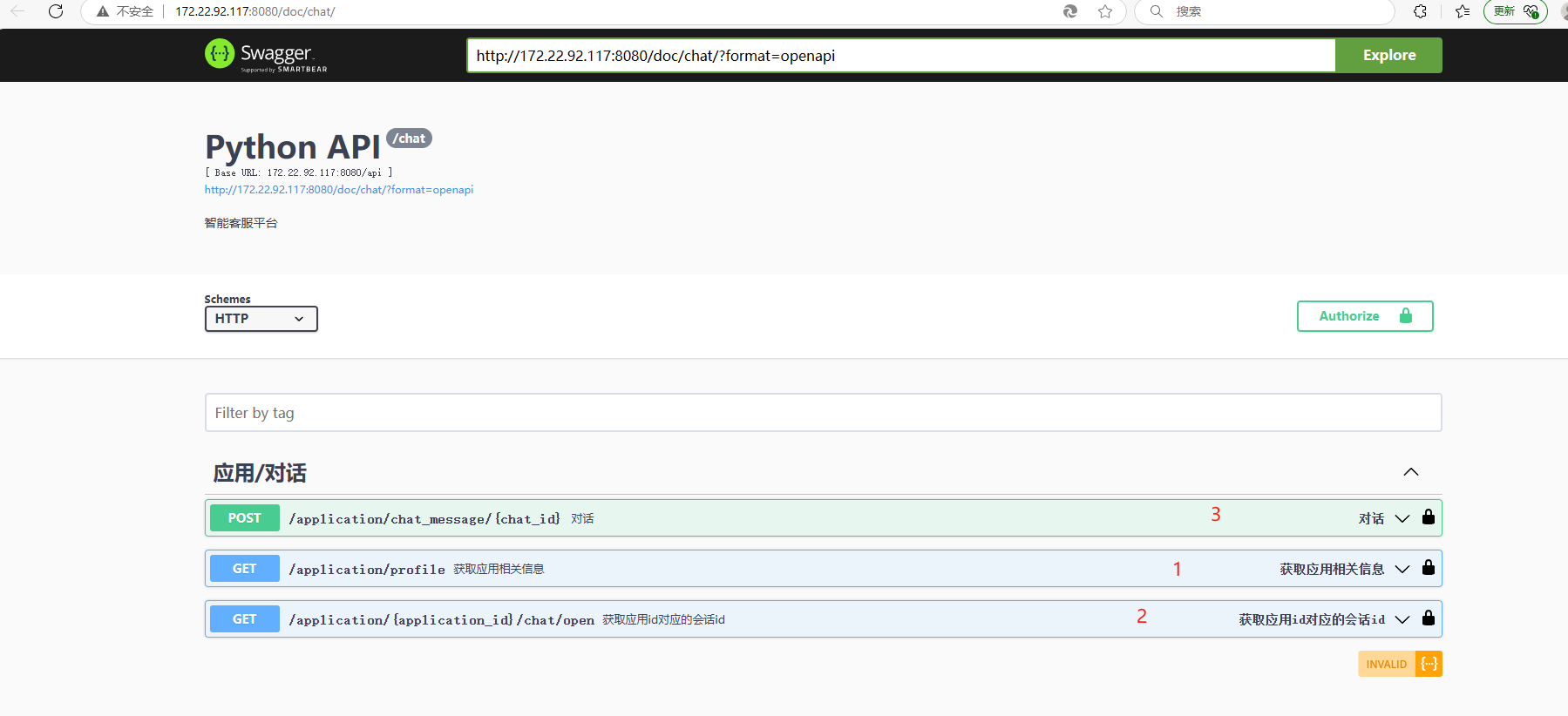
按步骤调用把建设项目信息传参过去就得到项目相关分析数据了,前端解析并展示即可:

(2)叠加分析与缓冲分析
在本次分析工作中,叠加分析和缓冲分析,我们沿用传统分析方式。熟悉地理信息系统(GIS)的同行,对这类分析方法的操作流程都较为熟悉,在此便不再赘述,我是使用arcpy实现的废话少说,直接上代码
# _*_ coding: utf-8 _*_
# @DateTime : 2021/11/22 8:42
# @Site: [email protected]
# @Author : huge
# @Version:V 0.1
# software: PyCharm
# @desc :
from bottle import Bottle, request
special_analysis_controller = Bottle()
from controller.ResultBody import *
import os, json, decimal
import arcpy
from utils.file_utils import *
import utils.globalvar as gl
upload_file_path = os.path.join(gl.get_upload_file_path(), datetime.datetime.now().strftime('%Y-%m-%d'))
# 叠加分析-相交
@special_analysis_controller.route('/intersect_analysis', method='POST')
def IntersectAnalysis():
del_file(upload_file_path)
print "请求开始"
parentId = request.forms.parentId
sde_file = gl.get_sde_file_path() + "_" + request.forms.orgCode + ".sde"
# print parentId
# print sde_file
analysisFeatures = request.forms.analysisFeatures
print analysisFeatures
clipFeatures = json.loads(request.forms.clipFeatures)['rings']
print clipFeatures
caseField = request.forms.caseField
print caseField
result = []
arcpy.env.overwriteOutput = True
temp_file_path = os.path.join(upload_file_path, "specialAnalysis")
isExists(temp_file_path)
arcpy.env.workspace = temp_file_path
print arcpy.env.workspace
analysisFeatures1_name = []
for feature in clipFeatures:
analysisFeatures1_name.append(
arcpy.Polygon(
arcpy.Array([arcpy.Point(*coords) for coords in feature])))
analysisFeatures_name = os.path.join(sde_file, analysisFeatures)
# analysisFeatures_name = "D:\\IDEAProjects\gtkjgh_python_project\static\data\sde\gtkjghyzt_150921.sde\A0201_DLTB_2018"
print analysisFeatures_name
# 裁切
outClipFeature = arcpy.Clip_analysis(in_features=analysisFeatures_name, clip_features=analysisFeatures1_name)
# print "裁切完成"
print caseField
if caseField != '0':
# 添加字段
arcpy.AddField_management(in_table=outClipFeature, field_name="cxjsmj", field_type="DOUBLE")
# 计算面积
arcpy.CalculateField_management(in_table=outClipFeature, field="cxjsmj", expression="!shape.area!",
expression_type="PYTHON_9.3")
# print "计算面积完成"
# 统计各地类的面积
outTable = arcpy.Statistics_analysis(in_table=outClipFeature, statistics_fields=[["cxjsmj", "SUM"]],
case_field=caseField)
print outTable
dlmjCursor = arcpy.da.SearchCursor(in_table=outTable.getOutput(0), field_names=[caseField, "SUM_cxjsmj"])
# print "统计各地类的面积完成"
for row in dlmjCursor:
dict = {
}
dict["parentId"] = parentId
dict["label"] = row[0]
# dict["result"] = "占用{0}平方米".format(str(round(decimal.Decimal(row[1]), 2)))
dict["result"] = round(decimal.Decimal(row[1]), 2)
result.append(dict)
if caseField == '0' or caseField == '':
# 添加字段
arcpy.AddField_management(in_table=outClipFeature, field_name="cxjsmj", field_type="DOUBLE")
# 计算面积
arcpy.CalculateField_management(in_table=outClipFeature, field="cxjsmj", expression="!shape.area!",
expression_type="PYTHON_9.3")
areaList = []
with arcpy.da.SearchCursor(in_table=outClipFeature, field_names=["cxjsmj"]) as cursor:
for row in cursor:
areaList.append(round(decimal.Decimal(row[0]), 2))
# print(u'{0}'.format(sum(areaList)))
dict = {
}
dict["parentId"] = parentId
dict["label"] = '总面积'
dict["result"] = sum(areaList)
result.append(dict)
if len(result) == 0:
dict = {
}
dict["parentId"] = parentId
dict["label"] = ''
dict["result"] = 0
result.append(dict)
print result
return ResultBody(0, "成功", result)
# 分析二调土地利用现状压占情况
@special_analysis_controller.route('/analyze_tdlyxz_2d', method='POST')
def analyzeTdlyxzLayer():
year = request.forms.year
boundary_polygon = arcpy.AsShape(json.loads(request.forms.clipFeatures), True)
toolbox_file = os.path.join(gl.get_data_dir(), "Analyze.tbx")
dltb = os.path.join(sde_file, "A0201_DLTB_{0}".format(year))
xzdw = os.path.join(sde_file, "A0201_XZDW_{0}".format(year))
arcpy.AddToolbox(toolbox_file)
result = arcpy.AnalyzeLanduse2nd_skanalyze(dltb, xzdw, boundary_polygon)
with arcpy.da.SearchCursor(result, ["TARGET_FID"]) as cur:
values = [row[0] for row in cur]
uniqueIds = set(values)
dltb_list = []
for id in uniqueIds:
with arcpy.da.SearchCursor(result,
["TBBH", "DLMC", "DLBM", "QSXZ", "QSDWMC", "ZLDWMC", "TKXS", "POLY_AREA", "DLMC_1",
"DLBM_1", "KCTBBH1", "KCTBBH2", "LENGTH", "KD", "KCBL", "QSXZ_1", "QSDWMC1",
"QSDWMC2", "SHAPE@JSON"], "TARGET_FID={0}".format(id)) as cursor:
length = 0
dltb_area = 0
for row in cursor:
(tbbh, dlmc, dlbm, qsxz, qsdwmc, zldwmc, tkxs, area_geo, dlmc1, dlbm1, kctbbh1,
kctbbh2, length_geo, kd, kcbl, qsxz1, qsdwmc1, qsdwmc2, geojson) = row
dltb = {
"dlmc": dlmc, "dlbm": dlbm, "qsxz": qsxz, "qsdwmc": qsdwmc,
"zldwmc": zldwmc, "type": "dltb", "area": dltb_area, "geom": geojson}
if tbbh == kctbbh1:
xzdw_area = length_geo * kd * kcbl
xzdw = {
"dlmc": dlmc1, "dlbm": dlbm1, "qsxz": qsxz1, "qsdwmc": qsdwmc1,
"zldwmc": zldwmc, "type": "xzdw", "area": xzdw_area, "geom": None}
elif tbbh == kctbbh2:
xzdw_area = length_geo * kd * kcbl
xzdw = {
"dlmc": dlmc1, "dlbm": dlbm1, "qsxz": qsxz1, "qsdwmc": qsdwmc2,
"zldwmc": zldwmc, "type": "xzdw", "area": xzdw_area, "geom": None}
else:
xzdw = None
if (length == 0):
dltb_area = area_geo
if xzdw is not None:
if dltb_area - xzdw["area"] > 0:
dltb_area -= xzdw["area"]
else:
xzdw["area"] = dltb_area
dltb_area = 0
dltb_list.append(xzdw)
length += 1
if tkxs > 0:
if tkxs >= 1:
tkxs = tkxs * 0.01
tk_area = dltb_area * tkxs
dltb_tk = {
"dlmc": "田坎".decode("utf8"), "dlbm": "123", "qsxz": qsxz, "geom": None,
"qsdwmc": qsdwmc, "zldwmc": zldwmc, "type": "dltb_tk", "area": tk_area}
dltb_list.append(dltb_tk)
dltb["area"] = dltb_area * (1 - tkxs)
dltb_list.append(dltb)
arcpy.Delete_management(result)
return ResultBody(0, "成功", dltb_list)
调用接口分析结果如下图

传递的参数

返回结果
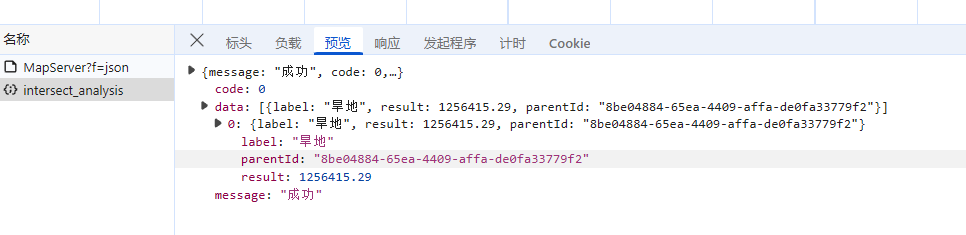
接下来,大家只需整合建设项目信息与分析所得数据,以文字形式提交给 AI,就能让其判断项目是否违规。整个流程感觉是不是很简便?感兴趣的同学不妨亲自上手操作,在实践中体验 AI 助力项目审查的高效性!
(3)AI合规性分析
至此,对技术原理领悟力较强的朋友,想必已经明晰整个操作思路了。
1,创建应用
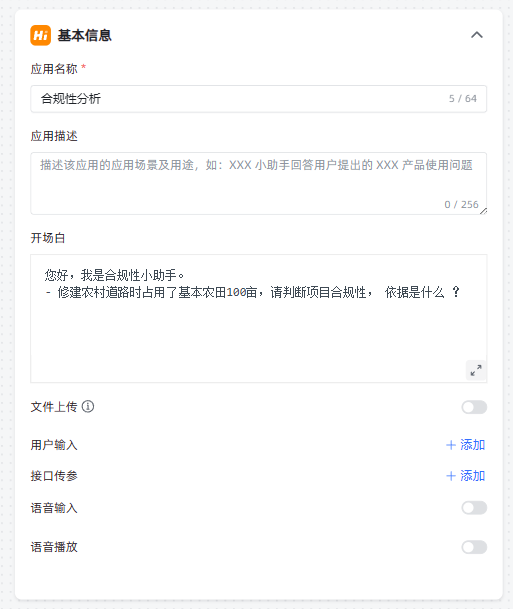
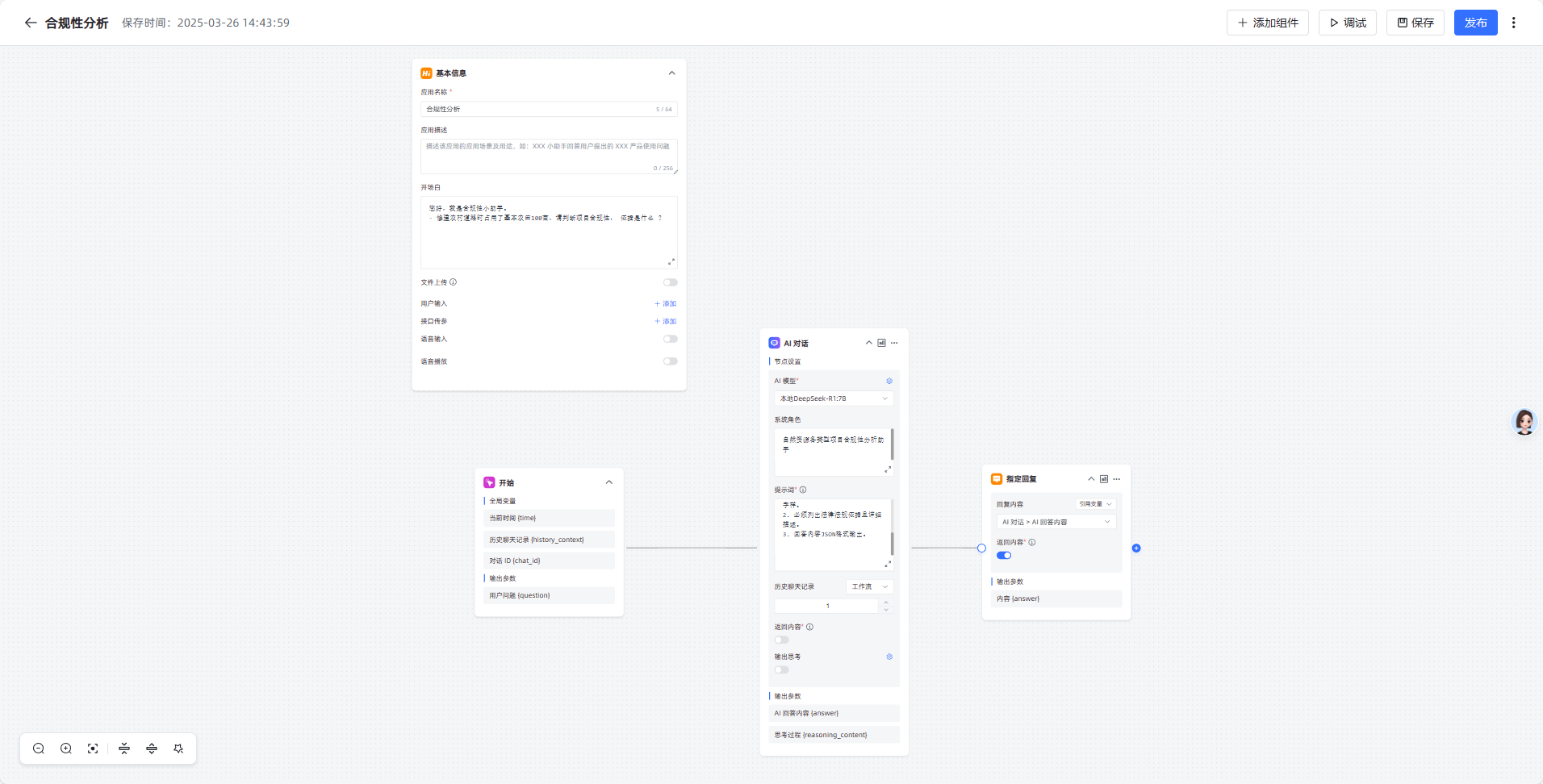
2,判断是否合规的AI节点
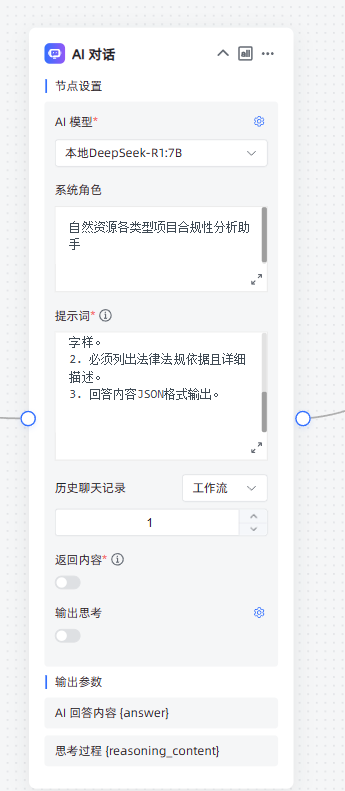
问题:
{
{
开始.question}}
角色定义:你是一个合规性分析专家,请严格按照现行法律法规规章制度回答。
任务描述:{
{
开始.question}}
输出要求:
1. 必须返回一个合规还是不合规字样。
2. 必须列出法律法规依据且详细描述。
3. 回答内容JSON格式输出。
最终调试结果如下图
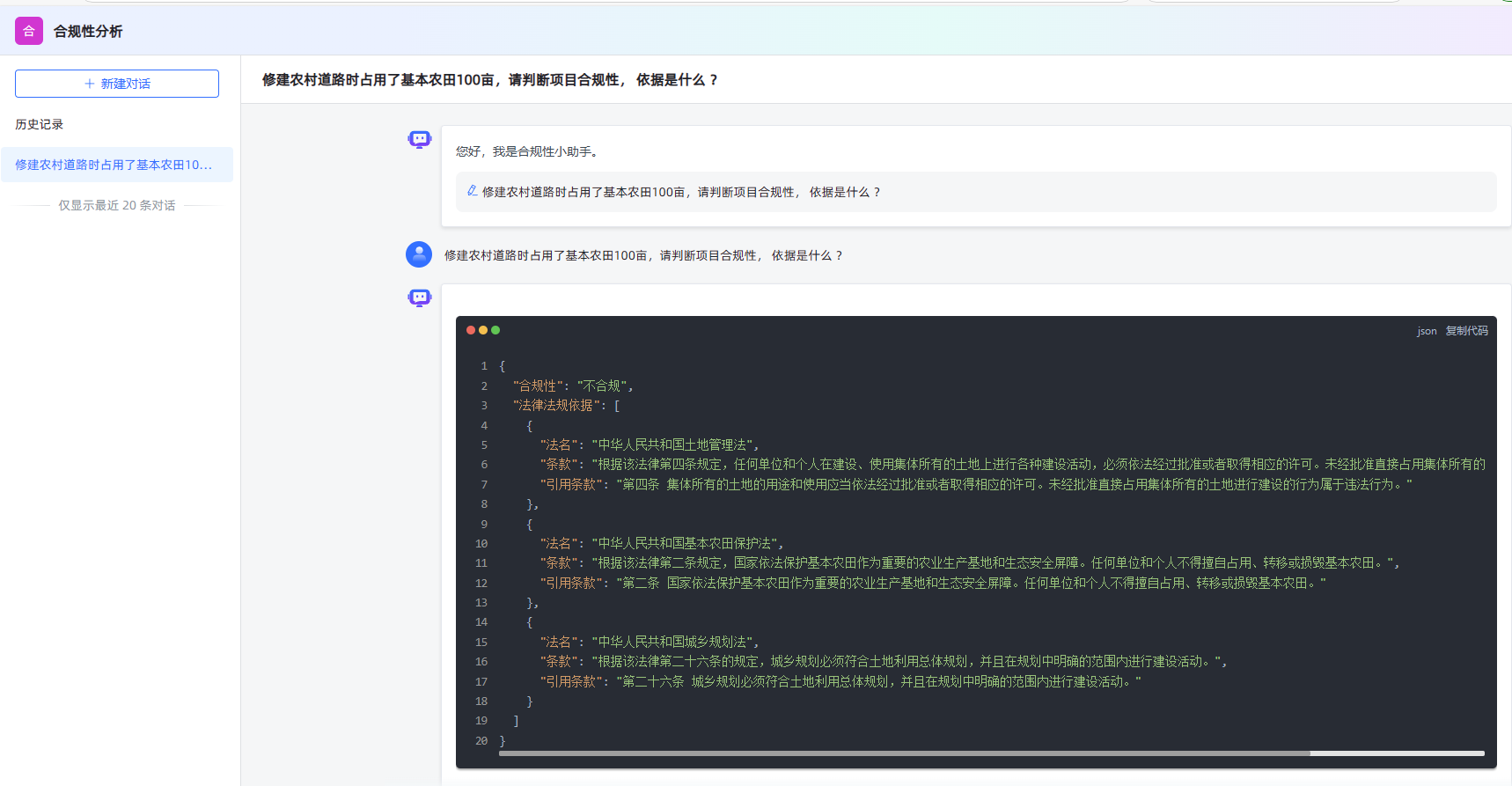
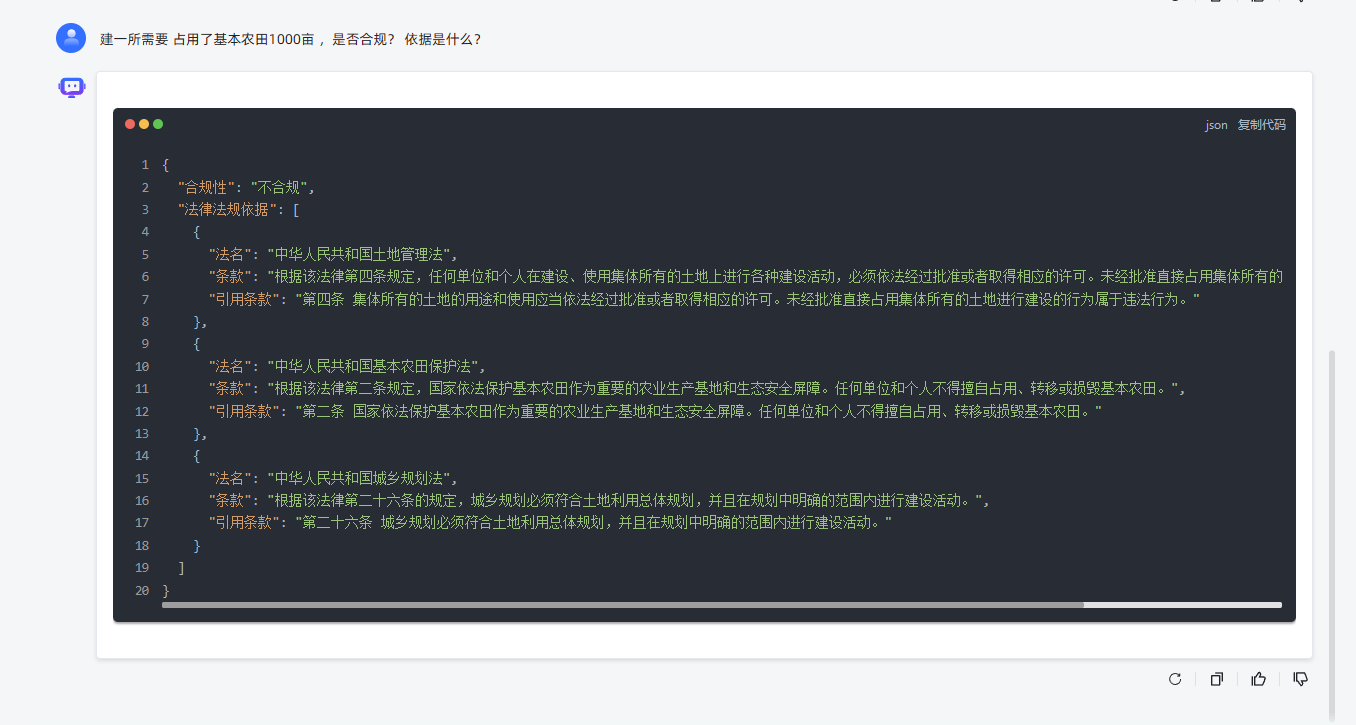
完成最终流程图如下:
2,前端对接合规性分析应用
参考: 7,前端对接应用接口
对接后的效果如下图:
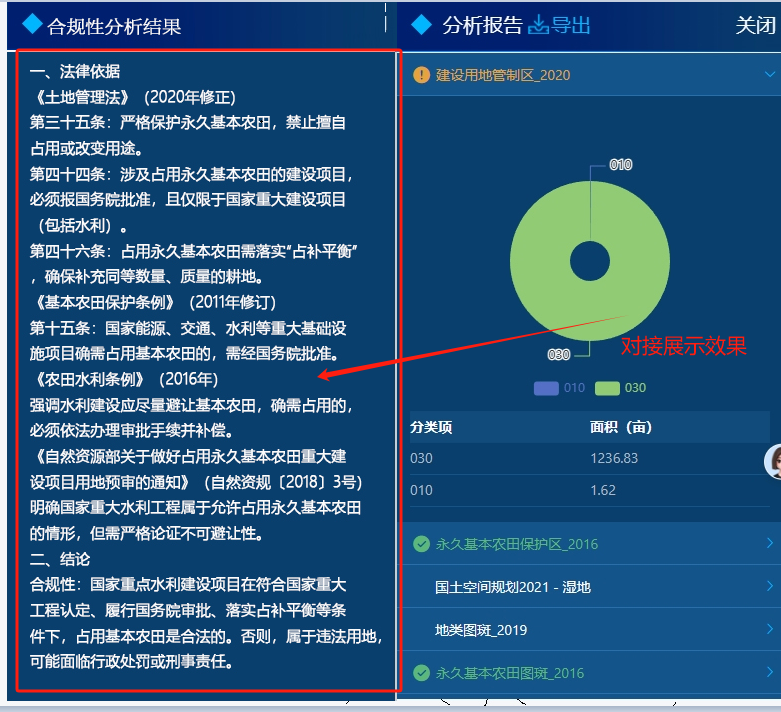
四,总结
与传统 GIS 应用相比,DeepSeek 在处理复杂任务时优势显著。传统 GIS 虽在空间分析上表现出色,但面对相关数据筛选工作时力不从心。因为数据来源广泛、种类繁杂,传统 GIS 很难快速从海量数据中精准选出对建设项目用地报批关键的数据,效率低下。在依据复杂海量的法律法规与规章制度进行合规性判断时,传统 GIS 缺乏智能解读能力,只能依靠人工,易出错且难度大。
而 DeepSeek 引入先进算法,能够高效简化数据筛选流程,快速精准识别并提取与建设项目用地报批紧密相关的数据。在合规性判断方面,借助深度学习技术,DeepSeek 可对法规政策进行学习理解,自动依据法规对项目用地情况进行合规分析,大大降低了合规性判断的难度,减少人工干预,提升准确性与效率,更能满足建设项目用地报批辅助系统的需求 。
别忘了关注收藏,后面的章节更精彩!