写在前面
由于硬件水较深(供货商是否靠谱、是否为二手翻修、显卡价格波动等因素),本次为大家提供一个参考值。
需要注意的是,技术的提升能大幅降低硬件成本!
如九天老师已经进行过公开课讲解的Ktransformer、Unsloth、KT+UN部署方案,都是竞价比极高的部署方案!
完整部署教学,及动态量化版本部署,点击“阅读原文”观看九天老师公开课内容!
而到了需要考虑并发的阶段,架构等的优化也至关重要!
而同时本地部署也只是第一步,后续基于DeepSeek进行微调、RAG、Agent开发,软件技术的提升同样节省大量成本哦~
一、主流版本配置与预算
1. 满血版DeepSeek-R1 671B
适用场景:超大规模AI训练/科研计算/高性能要求的商业场景
硬件配置 :

CPU: 多路至强/EPYC处理器
内存: ≥2TB DDR5 ECC
存储: ≥1TB NVMe SSD阵列
参考成本(以FP 16精度,仅部署推理,多卡集群部署为例):
A100单价:约¥10-12万/张 → 16张 ≈ ¥160-192万
服务器单价:约¥15万/台(含CPU/内存/存储) → 8台 ≈ ¥120万
总计:280-312万
2. 蒸馏版DeepSeek-R1 70B
• 适用场景:企业级高精度推理/中型任务
• 硬件配置 :

CPU: 32核至强/EPYC
内存: ≥256GB DDR5
存储: 500GB NVMe SSD
参考成本(以FP 16精度,仅部署推理,单机多卡部署为例):
A100单价:约¥10-12万/张 → 2张 ≈ ¥20-24万
服务器单价:约¥15万/台(含CPU/内存/存储) → 1台 ≈ ¥15万
总计:50-100万
3. 轻量版DeepSeek-R1 32B
适用场景:小微企业/开发测试
硬件配置:

CPU: 6核i5/Ryzen 5
内存: 32GB DDR4
存储: 100GB SSD
参考成本(以FP 16精度,仅部署推理,单机本地部署为例):
显卡:价格不稳定,同时要当心翻修的二手卡
总计:各凭本事,英伟达主流显卡性能对比参考下图
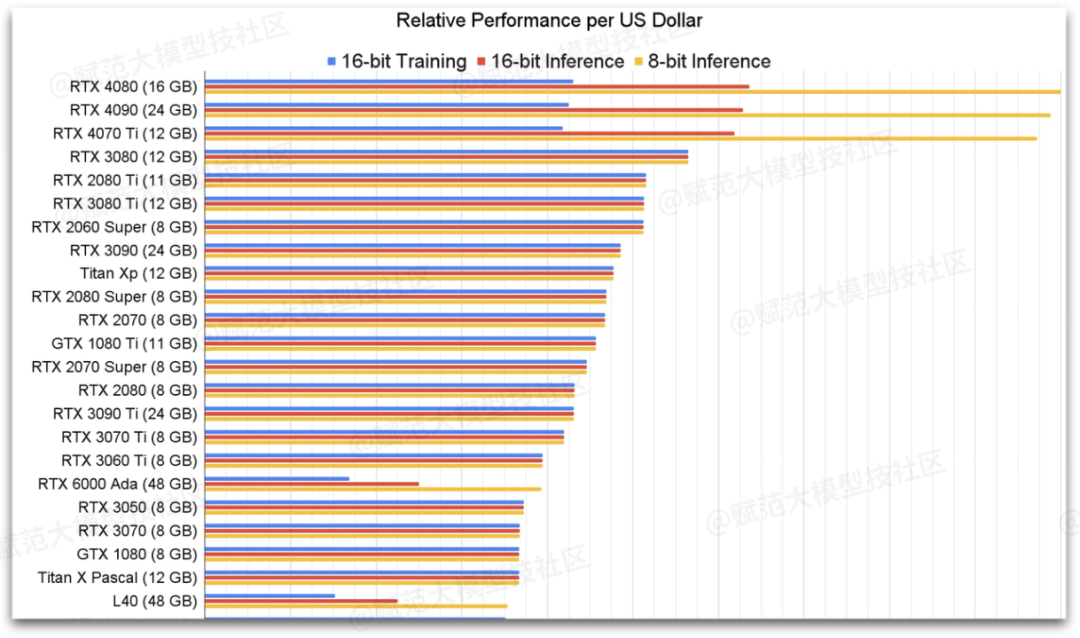
4. 入门版DeepSeek-7B/14B
• 适用场景:个人开发者/轻量应用/高校实验室&小型团队适用
• 硬件配置

• CPU:6核i5/Ryzen 5
• 内存:32GB DDR4
• 存储:100GB SSD
参考成本(以FP 16精度,仅部署推理,单机多卡部署为例):
显卡:价格不稳定,同时要当心翻修的二手卡
总计:各凭本事,对应性能参考上图
DeepSeek R1硬件选配思维导图

二、关键注意事项
1. 硬件选型原则
• 显存优先:参考公式:参数规模×精度位数×1.2缓冲系数
• 例:70B+FP16需约168GB显存
• 互联技术:多卡需NVLink/InfiniBand(单机扩展≤8卡,多节点需200Gbps网络)
• 存储优化:NVMe SSD比SATA SSD提速3-5倍,建议全闪存阵列
2. 部署优化策略
• 量化技术:4-bit量化可降低显存占用至1/4,但生成质量下降10-15%
• 推理加速:使用vLLM/TensorRT-LLM框架支持动态批处理,吞吐量提升3倍
• 混合计算:CPU/GPU协同推理(如LoRA微调),降低GPU资源压力
3. 国产化适配
• 芯片支持:昇腾910B、海光DCU等已适配70B模型,性能达国际水平80%
• 软件生态:MindSpore、PaddlePaddle支持昇腾芯片,Colossal-AI适配国产硬件
4. 稳定性与成本控制
• 冗余设计:企业级配置需预留20%预算用于RAID存储和容灾方案
• 长尾延迟:监控TP99指标,通过优先级队列调度高价值请求
• 云边协同:敏感数据本地处理,通用任务通过云API调用(成本约0.05元/千token)
5. 部署流程避坑
• 环境配置:Linux系统需CUDA 12.2驱动,Windows仅支持高性能GPU
• 模型加载:使用GPU流式加载技术,避免磁盘I/O瓶颈
• 报错处理:常见问题包括显存不足(需量化)、API地址配置错误(检查本地IP)
6.额外嘱咐
报价基于2025年2月市场行情,含硬件采购及基础运维成本;
企业级配置需额外考虑冗余电源、RAID存储和容灾方案(+20%预算);
个人用户推荐从量化小模型(如7B-4bit)起步,逐步升级硬件。
以上这些,【公益】大模型技术社区已涵盖!扫描下方二维码即可进入大模型技术社区!
本篇文章中用到的图片,同样可以扫描下方二维码获得哦~
