2025年1月26日,某首席经济学家在微博上写道:“DeepSeek以极低成本和少量芯片实现了与OpenAI等巨头可以媲美的性能,引发国际AI界关注。如果算力不再决定AI性能,那么之前无脑买英伟达芯片的投资逻辑很可能发生变化,其它业态也将改变。”
周一,“东大刺客”DeepSeek带来的冲击率先在亚洲市场显现。早盘,A股DeepSeek概念暴涨超11%,算力概念股则暴跌,AI算力、GPU、液冷服务器和ASIC芯片等板块均大跌超3%,光芯片、高速铜互联、光通信和光模块等板块暴跌5%以上;日本半导体ETF也大跌超3%。
DeepSeek给大洋彼岸的美国带来了焦虑,周一纳指期货跌近3%;准备为美国AI投资千亿美元的软银暴跌6%。
DeepSeek-R1之所以对AI界产生巨大影响,是因为它通过大规模强化学习技术,在极低的算力成本下实现了与OpenAI-o1等顶尖模型相媲美甚至超越的推理能力,同时开源策略降低了AI技术的应用门槛,推动了AI技术的普惠化和行业创新。
本文就最近兴起的Deepseek之风,结合众多解读DeepSeek-R1论文的文章,详细了解一下该模型的独特之处。

论文题目:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
论文链接:https://arxiv.org/abs/2501.12948
项目地址:GitHub - deepseek-ai/DeepSeek-R1
DeepSeek-R1整篇论文概况一下就是:DeepSeek团队为实现提高和改进AI模型的推理和思考能力,基于基础模型DeepSeek-V3-Base,使用其独创的"GRPO"纯强化学习方法,直接在该基础模型上应用RL,颠覆之前的监督微调的方式,无需任何的监督微调数据,训练出了性能极佳的DeepSeek-R1-zero模型。但训练出DeepSeek-R1-zero存在两个问题,即可读性差和语言混杂。
为了解决这些问题并进一步提升推理性能,DeepSeek进一步开发了DeepSeek-R1。该模型在强化学习之前加入了多阶段训练流程和冷启动数据(后文将详细介绍),在推理任务中的性能已达到与OpenAI-o1-1217相当的水平。

但不同于OpenAI的大模型,DeepSeek R1模型的开发过程全公开,并发布了技术论文,以便其他团队更全面地理解和复现该模型。这种相对开放的做法使得全球的研究人员能够打开模型的“黑盒”,去探究模型的内部工作机制,从而将模型适应到其他任务中。
1. 引言
1.1 论文贡献
首先先总结一下该论文的主要贡献:
1. 探索纯强化学习在提升LLMs推理能力方面的潜力
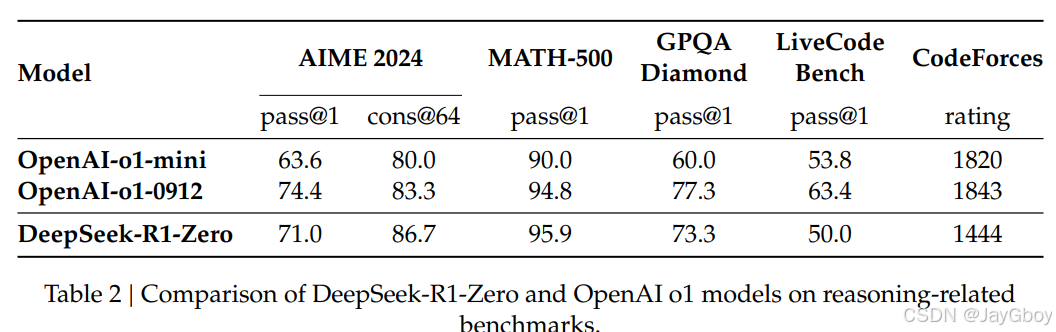
首次实现无需监督微调的推理能力提升,DeepSeek-R1-Zero是通过纯强化学习(RL)直接在基础模型上训练,无需任何监督微调(SFT)数据,成功展示了强大的推理能力。这是首次证明LLMs可以通过纯RL训练而无需依赖监督数据来发展推理能力。通过大规模RL训练,DeepSeek-R1-Zero在多个推理基准测试中表现出色,例如在AIME 2024中pass@1分数从15.6%提升至71.0%,接近OpenAI-o1-0912的性能,证明了RL在提升推理能力方面的巨大潜力。
2. 提出了一种结合冷启动数据和多阶段训练的推理模型DeepSeek-R1
DeepSeek-R1-Zero虽然推理能力强,但存在可读性差、语言混杂等问题。DeepSeek-R1通过引入冷启动数据和多阶段训练(包括两次RL和两次SFT),解决了这些问题,同时进一步提升了推理性能。DeepSeek-R1在多个推理任务上达到了与OpenAI-o1-1217相当的性能,例如在AIME 2024中pass@1分数达到79.8%,在MATH-500中达到97.3%,证明了其在推理任务上的竞争力。
3. 探索将推理能力迁移到小型模型的蒸馏技术
通过将DeepSeek-R1的推理能力蒸馏到小型模型(如Qwen和Llama系列),显著提升了这些小型模型的推理性能。例如,DeepSeek-R1-Distill-Qwen-7B在AIME 2024中pass@1分数达到55.5%,超过了QwQ-32B-Preview。
2. 实验方法
以往的研究通常依赖大量监督数据来提升模型性能。DeepSeek证明了即使不使用监督微调作为冷启动,通过大规模强化学习依然可以显著提升模型的推理能力(DeepSeek-R1-Zero)。此外,适量冷启动数据的引入可以进一步提高性能(DeepSeek-R1)。接下来的部分将介绍:
(1)DeepSeek-R1-Zero:直接在基础模型上应用 RL,而无需任何 SFT 数据;
(2)DeepSeek-R1:从经过数千条长推理链样本微调的检查点开始进行 RL;
(3)推理能力蒸馏:将 DeepSeek-R1 的推理能力转移到小型密集模型中。
2.1 DeepSeek-R1-Zero:在基础模型上的强化学习
DeepSeek探索了大语言模型在没有任何监督数据的情况下发展推理能力的潜力,重点关注其通过纯强化学习过程实现的自我演化。
2.1.1 强化学习算法:(GRPO算法)
为了降低强化学习的训练成本,DeepSeek采用了群相对策略优化 Group Relative Policy Optimization(GRPO)。这种方法放弃了通常与策略模型大小相同的评价模型,而是通过群体得分来估计基线。具体而言,对于每个问题 ,GRPO从旧策略中采样一组输出 ,然后通过最大化目标来优化策略模型。
GRPO的关键步骤:
-
采样输出:对于每个问题 i,从旧策略 πθold 中采样一组输出 {i1,i2,…,iAi}。
-
计算奖励:为每个输出计算奖励 R(ij),奖励可以是基于规则的准确性奖励或格式奖励。
-
计算优势:计算每个输出的优势 Ai,优势是该输出的奖励与组内所有输出奖励的平均值的差值:
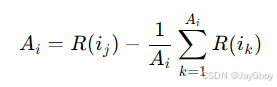
4.优化策略模型:通过最大化以下目标函数来更新策略模型 πθ:
![]()
![]()
其中:
ϵ 和 β 是超参数,用于控制策略更新的幅度和KL散度的惩罚。
DKL 是Kullback-Leibler散度,用于防止策略更新过大。
举例来说:
我们用一个贴近实际应用场景的例子来解释GRPO(Group Relative Policy Optimization),以一个简单的编程问题为例。
示例场景
假设我们正在训练一个语言模型来解决编程问题,目标是让模型生成正确的代码,问题如下:
问题:编写一个Python函数,计算一个整数列表中所有元素的平均值。
GRPO的步骤
1. 采样输出
从当前策略模型 πθold 中采样3个不同的输出:
输出1
def average(numbers):
return sum(numbers) / len(numbers)输出2
def average(nums):
total = 0
for num in nums:
total += num
return total / len(nums)输出3
def average(lst):
if len(lst) == 0:
return 0
return sum(lst) / len(lst)2. 计算奖励
假设奖励函数是基于代码的正确性和可读性:
输出1:代码正确且简洁,奖励 R(i1)=1.0。
输出2:代码正确但稍显冗长,奖励 R(i2)=0.8。
输出3:代码正确且考虑了边界情况(空列表),奖励 R(i3)=1.2。
3. 计算优势
计算每个输出的优势 Ai:![]()
输出1:
A1=1.0−31.0+0.8+1.2=1.0−1.0=0
输出2:
A2=0.8−31.0+0.8+1.2=0.8−1.0=−0.2
输出3:
A3=1.2−31.0+0.8+1.2=1.2−1.0=0.2
4. 优化策略模型
使用上述优势值更新策略模型。假设超参数 ϵ=0.1 和 β=0.01,则具体计算如下:
输出1:
![]()
输出2:
![]()
输出3:
![]()
最终的目标函数为:
![]()
![]()
解释
-
输出1:虽然代码简洁且正确,但没有额外的奖励(如边界情况处理),因此优势为0,对策略更新的贡献为0。
-
输出2:代码冗长但正确,奖励较低,因此优势为负值(-0.2),这会减少策略模型生成类似输出的概率。
-
输出3:代码不仅正确,还考虑了边界情况(空列表),奖励最高,优势为正值(0.2),这会增加策略模型生成类似输出的概率。
2.1.2 奖励建模
奖励建模的目标是通过设计合理的奖励函数,引导模型生成高质量的输出。在DeepSeek的研究中,奖励函数主要分为两类:
-
准确性奖励(Accuracy Rewards):评估模型输出的正确性。
-
格式奖励(Format Rewards):确保模型输出符合特定的格式要求。
举例说明
1. 准确性奖励(Accuracy Rewards)
假设我们正在训练一个模型来解决数学问题,例如求解一个二次方程的根。问题如下:
问题:求解二次方程 ax2+bx+c=0 的根,其中 a=1,b=−3,c=2。
正确答案:根为 x=1 和 x=2。
模型输出:
输出1:根为 x=1 和 x=2。
输出2:根为 x=1 和 x=3。
输出3:根为 x=2 和 x=3。
奖励计算:
输出1:答案完全正确,奖励 R(i1)=1.0。
输出2:部分正确,奖励 R(i2)=0.5(假设部分正确给予一定的奖励)。
输出3:部分正确,奖励 R(i3)=0.5。
2. 格式奖励(Format Rewards)
假设我们要求模型在输出答案时,必须将解题过程放在特定的标记之间,例如 <think> 和 </think>,并将最终答案放在 <answer> 和 </answer> 之间。问题如下:
问题:求解二次方程 ax2+bx+c=0 的根,其中 a=1,b=−3,c=2。
模型输出:
输出1:
<think>使用求根公式 x = (-b ± √(b² - 4ac)) / 2a</think>
<answer>根为 x = 1 和 x = 2</answer>
输出2:
使用求根公式 x = (-b ± √(b² - 4ac)) / 2a
根为 x = 1 和 x = 3
输出3:
<think>使用求根公式 x = (-b ± √(b² - 4ac)) / 2a</think>
根为 x = 2 和 x = 3
奖励计算:
输出1:格式正确且答案正确,奖励 R(i1)=1.0。
输出2:格式不正确,即使答案部分正确,奖励 R(i2)=0.0(格式错误直接导致奖励为0)。
输出3:格式正确但答案部分正确,奖励 R(i3)=0.5。
综合奖励
在实际应用中,奖励函数通常是准确性和格式奖励的综合。例如,可以将格式奖励作为一个乘性因子,只有当格式正确时,才考虑准确性奖励。具体公式可以表示为:
![]()
其中:
Raccuracy(i) 是准确性奖励。
Rformat(i) 是格式奖励,通常取值为0或1。
综合奖励计算:
-
输出1:格式正确且答案正确,奖励 R(i1)=1.0×1.0=1.0。
-
输出2:格式不正确,奖励 R(i2)=0.5×0.0=0.0。
-
输出3:格式正确但答案部分正确,奖励 R(i3)=0.5×1.0=0.5。
2.1.3 训练模板
为了训练 DeepSeek-R1-Zero,首先设计了一个简单的模板,引导基础模型遵循指定的指令。如表 1 所示,该模板要求 DeepSeek-R1-Zero 先生成推理过程,然后给出最终答案。通过有意将约束限制在这一结构化格式内,避免内容上的特定偏向(例如,要求反思性推理或推广特定问题解决策略),以便准确观察模型在强化学习过程中的自然发展。

2.1.4 DeepSeek-R1-Zero 的性能、自我进化过程和顿悟时刻
性能表现:DeepSeek-R1-Zero在AIME 2024基准测试中表现出色,pass@1分数从15.6%提升至71.0%,接近OpenAI-o1-0912的性能。
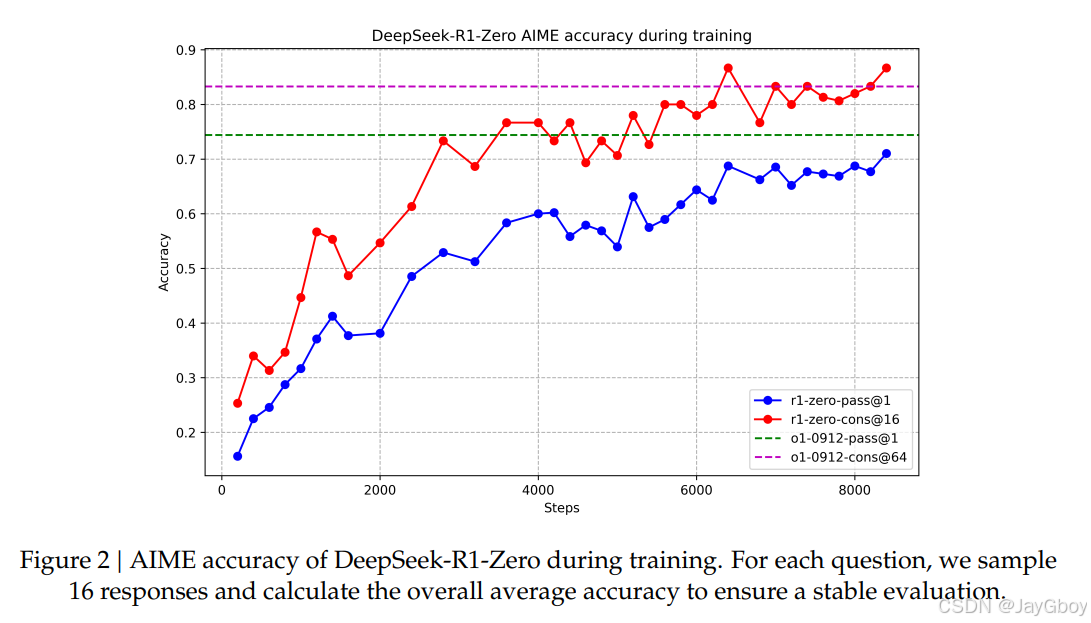
自我进化过程:模型在RL训练过程中自然地发展出更复杂的推理行为,如反思和探索多种解题方法。
“顿悟时刻”:模型在训练过程中出现了“顿悟时刻”,即模型学会了重新评估初始解题方法,分配更多思考时间。

2.2 DeepSeek-R1:具有冷启动的强化学习
虽然 DeepSeek-R1-Zero 展示了强大的推理能力,并能自主发展出意想不到且强大的推理行为,但仍面临一些问题。例如,DeepSeek-R1-Zero 在可读性和语言混杂等方面存在挑战。为了让推理过程更加易读并与研究社区共享,DeepSeek开发了 DeepSeek-R1,这种方法结合了具有用户友好特性的冷启动数据和强化学习。
2.2.1 冷启动阶段
在论文中提到的“冷启动”(Cold Start)是指在强化学习(RL)训练之前,使用少量高质量的数据对模型进行预训练,以便为后续的RL训练提供一个良好的初始状态。这种预训练过程可以帮助模型更快地收敛,并在RL训练的早期阶段避免不稳定的行为。
在DeepSeek的研究中,冷启动过程包括以下几个关键步骤:
1. 收集冷启动数据
冷启动数据通过以下几种方式收集:
人工标注:由人类专家标注少量高质量的推理样本,这些样本包含详细的推理过程和正确的答案。
模型生成:使用现有的模型(如DeepSeek-V3)生成高质量的推理样本,并通过人工审核或自动筛选来确保数据质量。
混合方法:结合人工标注和模型生成的数据,以确保数据的多样性和质量。
2. 数据格式设计
冷启动数据的设计需要考虑模型的输出格式和人类的可读性。例如,数据可以设计为以下格式:
|special_token|<reasoning_process>|special_token|<summary>
其中:
<reasoning_process> 是详细的推理过程。
<summary> 是推理结果的简洁总结。
这种格式不仅有助于模型学习推理过程,还能提高输出的可读性。
2.2.2 面向推理的强化学习阶段(第一段强化学习)
此阶段目的是专注于提升模型在推理密集型任务(如编程、数学等)中的能力。在用冷启动数据微调 DeepSeek-V3-Base 后,应用与 DeepSeek-R1-Zero 中相同的大型强化学习训练过程。
在训练过程中,DeepSeek团队观察到 CoT 经常出现语言混用,特别是当 RL 提示涉及多种语言时。为了解决语言混用问题,在 RL 训练期间引入了语言一致性奖励,该奖励计算为 CoT 中目标语言单词的比例。尽管消融实验表明这种对齐会导致模型性能略有下降,但该奖励与人类偏好一致,使其更易于阅读。最后,将推理任务的准确性奖励和语言一致性奖励直接相加,形成最终奖励,然后在推理任务上对微调后的模型进行 RL 训练,直到收敛。
2.2.3 拒绝采样与监督微调阶段
此阶段的目的是在强化学习(RL)的基础上,进一步提升模型的通用性能,特别是在推理任务的准确性和输出的可读性方面。
拒绝采样:从强化学习阶段生成的大量输出中筛选出高质量的样本。这些样本将用于后续的监督微调,以确保模型在推理任务上的表现更加稳定和准确。本论文中,在这一阶段,通过加入一些使用生成式奖励模型的数据来扩展在之前的阶段中,仅包含基于规则奖励验证的数据,通过将真实值和模型预测输入 DeepSeek-V3 进行判断。此外,由于模型输出有时混乱且难以阅读,过滤掉了带有混用语言、长段落和代码块的思维链。对于每个提示,采样多个响应并仅保留正确的响应。总共,收集了大约 600k 推理相关训练样本(高质量样本)。
监督微调:使用筛选出的高质量样本(包括详细的推理过程和正确的答案)对模型进行进一步的微调训练,微调的目标是让模型学习到高质量样本的模式和特征,从而在推理任务上表现得更准确和稳定。
2.2.4 面向所有场景的强化学习阶段(第二段强化学习)
这一阶段的目的是在推理任务的基础上,进一步提升模型在各种场景下的综合性能,包括但不限于推理任务、写作任务、问答任务等。这一阶段的目标是让模型在保持推理能力的同时,提升其在其他任务中的表现,确保模型在实际应用中能够更全面地满足用户的需求。
具体来说,通过结合多种奖励信号和多样化的提示分布来训练模型:
对于推理数据,遵循 DeepSeek-R1-Zero 的方法,使用基于规则的奖励来指导模型在数学、编程和逻辑推理领域的学习。
对于通用数据,采用奖励模型捕捉人类在复杂和细微场景中的偏好。基于 DeepSeek-V3 管道构建了偏好对和训练提示的分布。
在评估有用性时,专注于最终的摘要部分,确保评估重点关注响应对用户的实用性和相关性,同时尽量减少对底层推理过程的干扰。在评估无害性时,对模型的整个输出进行评估,包括推理过程和摘要,以识别并减轻生成过程中可能出现的风险、偏见或有害内容。
通过将奖励信号和多样化的数据分布相结合,DeepSeek成功训练出了一种既在推理任务中表现卓越,又能优先保证有用性和无害性的模型。
2.3 蒸馏:赋予小型模型推理能力
蒸馏技术:
知识蒸馏(Knowledge Distillation,简称KD)是由AI领域的三位大佬Geoffrey Hinton、Oriol Vinyals和Jeff Dean在2015年提出的技术,旨在通过将复杂教师模型的知识迁移到较简单的学生模型中,使学生模型在保持高性能的同时,能够实现更小的模型规模和更快的推理速度。
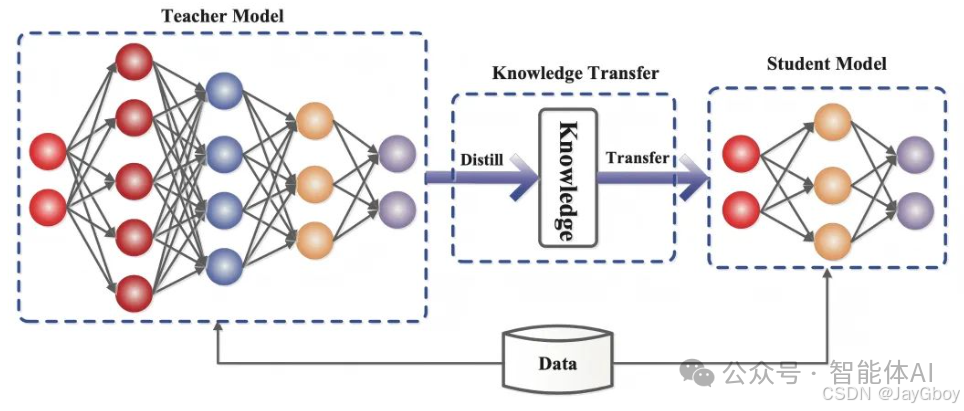
简单来说,蒸馏技术就像是学校里的学习过程:老师拥有丰富的知识和经验,学生通过学习老师的知识逐渐成长。AI中的“教师模型”相当于知识渊博的老师,它通过大量的数据训练,掌握了复杂的模式和特征;而“学生模型”则像是一个刚刚起步的学生,虽然知识面不如老师丰富,但通过学习老师的“思考方式”和“经验”,可以在没有过多计算资源的情况下取得不错的成绩。
本论文中为了让更高效的小型模型具备与 DeepSeek-R1 类似的推理能力,DeepSeek使用80 万条DeepSeek-R1数据集,对开源模型进行了直接微调。研究结果表明,这种简单的蒸馏方法显著增强了小型模型的推理能力。
DeepSeek选择了多个开源模型作为蒸馏的目标模型,包括Qwen 系列(Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B)和Llama 系列(Llama-3.1-8B 和 Llama-3.3-70B-Instruct)。
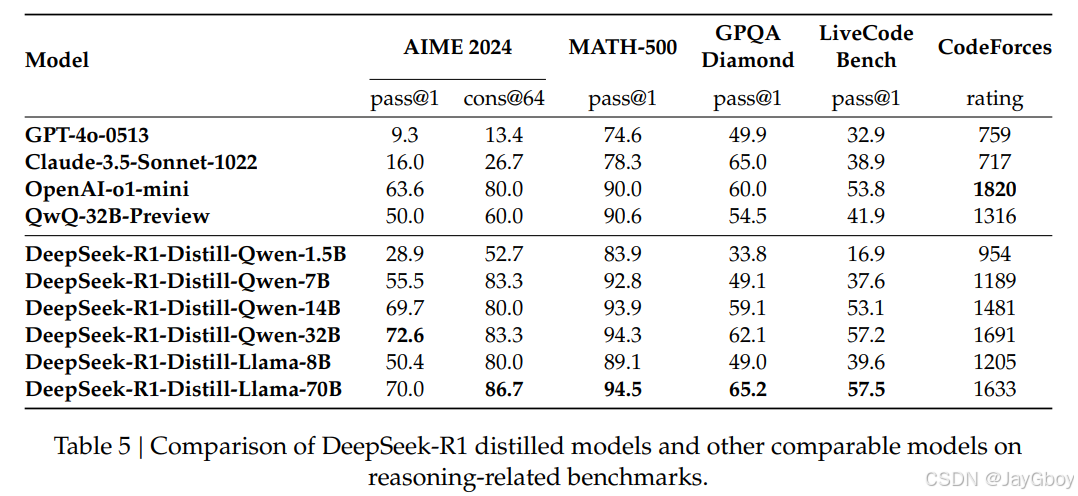
对于蒸馏模型,仅应用了监督微调,并未引入强化学习阶段。尽管引入强化学习可能会显著提升模型性能,但本研究的主要目标是验证蒸馏技术的有效性,进一步探索强化学习阶段的潜力则留给更广泛的研究社区。
3. 实验结果
3.1 DeepSeek-R1 评估结果
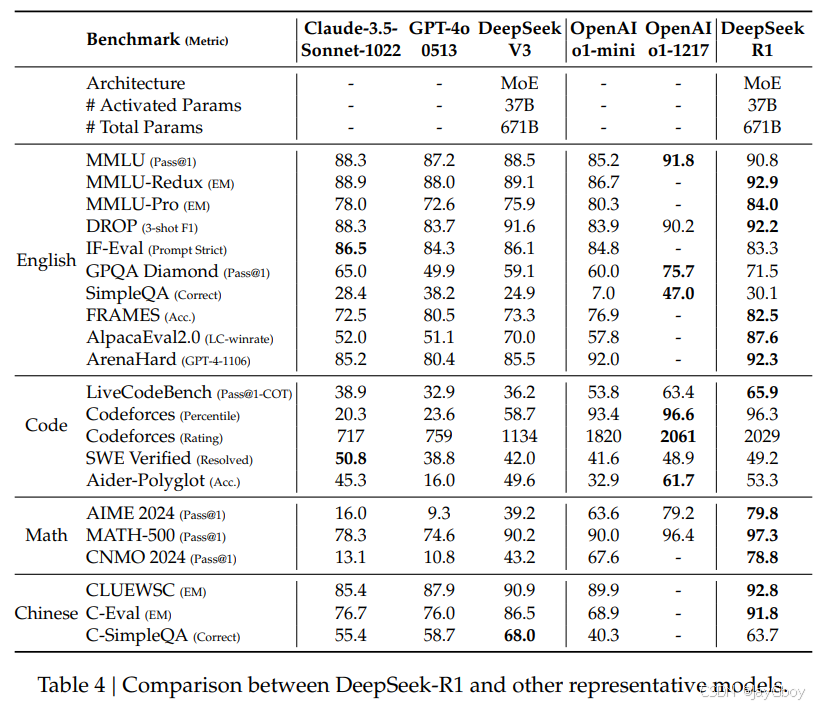
在面向教育的知识基准测试(如MMLU、MMLU-Pro和GPQA Diamond)中,DeepSeek-R1 的表现优于 DeepSeek-V3。这一提升主要归功于在 STEM 相关问题上的准确性增强,这些进步通过大规模强化学习实现。此外,DeepSeek-R1 在FRAMES(依赖长上下文的问答任务)中表现出色,展示了其在文档分析任务中的强大能力,表明推理模型在 AI 驱动的搜索和数据分析任务中具有巨大潜力。
在事实类基准测试SimpleQA上,DeepSeek-R1 的表现优于 DeepSeek-V3,展示了其处理基于事实查询的能力。类似的趋势也出现在 OpenAI-o1 超越 GPT-4o的测试中。然而,在中文SimpleQA基准测试上,DeepSeek-R1 的表现不如 DeepSeek-V3,这主要是因为模型在安全性强化学习后倾向于拒绝回答某些查询。如果不应用安全性强化学习,DeepSeek-R1 的准确率可超过 70%。
DeepSeek-R1在IF-Eval(用于评估模型遵循格式指令能力的基准测试)上也取得了出色的结果。这一改进与在监督微调和强化学习最终阶段中引入的指令遵循数据有关。此外,在AlpacaEval 2.0和ArenaHard上的表现表明了 DeepSeek-R1 在写作任务和开放领域问答中具有优势。
DeepSeek-R1 生成的摘要长度较为简洁:在ArenaHard上平均为689个token,在AlpacaEval 2.0上平均为2,218个字符。这表明 DeepSeek-R1 在基于 GPT 的评估中避免了长度偏差,从而进一步巩固了其在多任务中的稳健性。
在数学任务中,DeepSeek-R1 的表现与OpenAI-o1-1217相当,并远超其他模型。在编程算法任务(如LiveCodeBench和Codeforces)中,推理导向的模型在基准测试中占据主导地位。在面向工程的编程任务上,OpenAI-o1-1217 在Aider中表现优于 DeepSeek-R1,但在SWE Verified上表现相当。DeepSeek-R1 的工程类任务表现将在下一版本中进一步提升,因为目前相关的强化学习训练数据仍较为有限。
3.2 蒸馏模型评估结果
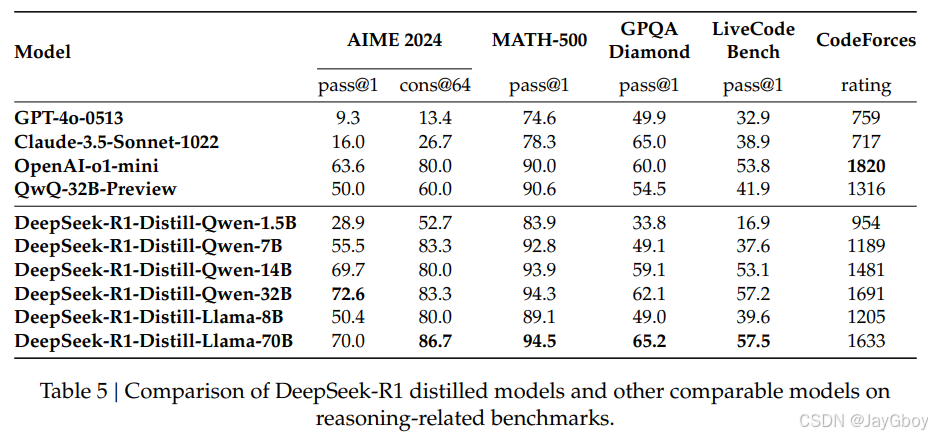
仅通过蒸馏 DeepSeek-R1 的输出,就使得高效的DeepSeek-R1-7B(即DeepSeek-R1-Distill-Qwen-7B,下文使用类似缩写)在各个方面都优于非推理优化模型(如 GPT-4o-0513)。DeepSeek-R1-14B在所有评估指标上都超过了QwQ-32B-Preview,而DeepSeek-R1-32B和DeepSeek-R1-70B在大多数基准测试中显著优于o1-mini。这些结果表明蒸馏技术具有很大的潜力。
此外,对这些蒸馏模型应用强化学习可以进一步显著提高性能,在此作者仅展示了基于简单监督微调的蒸馏模型的结果。
4. 讨论
4.1 蒸馏与强化学习的比较
以上的实验结果表明,通过对 DeepSeek-R1 进行蒸馏,小型模型能够取得强大的推理能力。但仍然存在一个问题:模型是否可以通过文中讨论的大规模强化学习(而不依赖蒸馏)达到类似的性能?
为了解答这一问题,DeepSeek在Qwen-32B-Base模型上进行了大规模强化学习,使用数学、代码和 STEM数据进行了超过10,000步的训练,生成了DeepSeek-R1-Zero-Qwen-32B。实验结果(见表 6)表明,该模型经过大规模 RL 训练后,其性能与QwQ-32B-Preview相当。然而,从 DeepSeek-R1 蒸馏得到的DeepSeek-R1-Distill-Qwen-32B在所有基准测试中都明显优于DeepSeek-R1-Zero-Qwen-32B。

因此可以得出两个结论:
第一,将强大的模型能力蒸馏到小型模型中是一个高效且效果显著的方法,而小型模型依赖于文中提到的大规模 RL 训练可能需要巨大的计算资源,且其性能可能难以达到蒸馏模型的水平。
第二,尽管蒸馏策略既经济又有效,但要突破智能边界,可能仍需依赖更强大的基础模型和更大规模的强化学习。
5. 未来的研究方向
未来,DeepSeek计划在以下方向上进一步研究 DeepSeek-R1:
通用能力:目前,DeepSeek-R1 在函数调用、多轮对话、复杂角色扮演和 JSON 输出等任务中的能力不及 DeepSeek-V3。未来,DeepSeek计划探索如何利用长推理链来增强在这些任务的表现。
语言混杂:DeepSeek-R1 当前针对中文和英文进行了优化,这可能在处理其他语言的查询时导致语言混杂问题。例如,即使查询使用的是非中英文,DeepSeek-R1 也可能在推理和响应中使用英语。DeepSeek计划在未来的更新中解决这一局限。
提示工程:目前模型对提示较为敏感,少样本提示会持续降低其性能。因此,建议用户使用零样本设置,直接描述问题并指定输出格式,以获得最佳效果。
软件工程任务:由于评估时间较长影响了强化学习过程的效率,大规模强化学习尚未广泛应用于软件工程任务。因此,DeepSeek-R1 在软件工程基准测试中的表现未能显著超越 DeepSeek-V3。未来版本将通过在软件工程数据上实施拒绝采样或在强化学习过程中引入异步评估来提高效率。
本文参考:
DeepSeek-R1技术报告快速解读_deepseek r1 技术报告-CSDN博客
DeepSeek R1论文阅读后产生的有趣想法、实验和吐槽(上)
https://mp.weixin.qq.com/s/x5wWXdw65joiiHQkrgfi8w