一、聚类分析的核心概念与算法选择
聚类分析是一种无监督学习方法,旨在通过数据内在相似性将对象分组,使组内差异最小化、组间差异最大化。
常用算法及适用场景:
- K-means:适用于数值型数据,如车辆性能参数(续航、电机功率)的快速分类,但对噪声敏感。
- 层次聚类:适合小规模数据,可通过树状图展示分类过程,用于测试结果的多层级细分。
- K-prototype:处理混合型数据(数值+分类),如同时分析车型参数(续航)与市场属性(品牌定位),避免哑变量转换的复杂性。
- 二阶段聚类:自动优化聚类数,适合高维数据(如整合车辆性能、用户偏好、政策影响的多维度分析)。
二、新能源汽车研发测试中的典型应用
1. 测试数据的分组与异常检测
- 场景:在电驱系统或动力电池测试中,通过聚类识别性能相近的组件组,并定位异常数据点(如温度异常、效率偏差)。
- 案例:某厂商对电池充放电循环数据聚类,发现3类电池老化模式,针对性优化BMS策略。
2. 用户行为与需求细分
- 方法:结合用户调研数据(如购车偏好、使用场景)进行二阶聚类,划分“续航敏感型”“性价比导向型”等群体,指导车型设计。
- 实例:四川省新能源汽车研究中,通过聚类将用户分为四类,发现主力人群更关注政策补贴与安全性,直接影响研发优先级。
3. 零部件可靠性分组
- 应用:对高压部件(如充电模块)的测试数据(故障率、温升曲线)聚类,识别高可靠性组与潜在缺陷组,优化供应链选择。
- 技术细节:需对数值型变量(如耐久测试时长)标准化,避免量纲影响;分类变量(如材料类型)需计算汉明距离。
4. 竞品分析与产品定位
- 案例:基于车辆参数(尺寸、动力性能、价格)的K-means聚类,划分市场细分,明确竞品范围。例如,某车企通过聚类发现其电动SUV与特斯拉Model Y、比亚迪唐同属“高端性能组”,针对性调整营销策略。
三、实施步骤与关键技术要点
-
数据预处理:
- 清洗噪声数据(如传感器异常值)。
- 混合数据归一化:数值变量采用Min-Max标准化,分类变量保留原始编码。
-
特征工程:
- 高相关性变量处理(如合并高速/城市工况能耗为综合能效指标)。
- 因子分析降维:提取“动力性能因子”“车身结构因子”等,减少计算复杂度。
-
模型优化:
- 聚类数确定:轮廓系数法评估最佳K值,避免主观预设。
- 结果验证:通过ANOVA分析类间差异显著性(如不同聚类在百公里电耗上的统计差异)。
四、挑战与应对策略
- 高维数据稀疏性:采用基于网格的聚类(如CLIQUE)或特征选择(如递归特征消除)。
- 动态数据流处理:增量聚类算法(如StreamKM++)实时分析车载传感器数据流。
- 业务可解释性:结合决策树或规则提取,将聚类结果转化为工程师可操作的优化建议。
通过上述方法,研发测试工程师可高效挖掘数据价值,优化产品设计、提升测试效率,并精准定位技术改进方向。
五、聚类分析在新能源汽车性能优化中的硬核实践
1、问题背景:新能源汽车性能优化的数据挑战
1.1 性能优化的核心矛盾
新能源汽车的研发测试中,经济性(续航里程、能耗效率)与动力性(加速性能、扭矩响应)常存在以下矛盾:
- 动力性与能耗的权衡:急加速工况下电机峰值功率需求导致电池放电倍率骤增,直接降低续航能力(实测数据显示,0-100km/h加速时间每减少1秒,综合工况续航下降约5-8%)。
- 电池热管理策略的复杂性:低温环境下电池内阻增大,放电性能下降;高温环境则需抑制热失控风险,这对BMS(电池管理系统)的动态调整提出极高要求。
- 用户行为多样性:不同驾驶习惯(如急加速频率、制动能量回收强度)导致车辆性能表现差异显著,传统“一刀切”的标定策略难以满足个性化需求。
1.2 数据特征与工程挑战
| 数据类型 | 典型参数示例 | 数据特征 | 处理难点 |
|---|---|---|---|
| 电机系统 | 转速、扭矩、效率MAP图 | 高采样率(10kHz级) | 实时性要求高,边缘计算资源有限 |
| 电池系统 | SOC、SOH、温度分布 | 多传感器异构数据 | 数据融合与异常值检测 |
| 环境数据 | 温度、坡度、风速 | 时空相关性 | 动态工况建模困难 |
| 用户行为 | 加速踏板开度、充电习惯 | 非结构化文本反馈 | 混合数据类型处理 |
传统方法的局限:
- 基于经验公式的标定策略迭代周期长(通常需3-6个月),难以快速响应市场变化。
- 人工规则库无法覆盖海量工况组合(如城市拥堵+低温+高速巡航的复合场景)。
2、聚类算法核心技术解析
2.1 算法选型与工程适配
2.1.1 算法对比矩阵
| 算法 | 核心原理 | 适用场景 | 参数调优要点 | 工程实现工具链 |
|---|---|---|---|---|
| K-means | 距离最小化迭代 | 数值型数据快速分组 | - 肘部法则确定K值 - 特征标准化(Z-score) - 空簇处理(随机中心重置) |
sklearn.cluster |
| DBSCAN | 密度可达性划分 | 噪声过滤与异常检测 | - ε半径通过k-distance曲线确定 - MinPts根据数据密度动态调整(通常≥维度+1) |
Python: hdbscan包 |
| GMM | 概率分布建模 | 电池健康状态分级 | - 协方差矩阵类型选择(full/tied/diag) - BIC准则评估模型复杂度 |
R: mclust包 |
| OPTICS | 基于可达距离的密度排序 | 多密度层次数据聚类 | - 最小样本数设置 - 提取簇的ξ-steep阈值 |
ELKI框架 |
2.1.2 混合数据类型处理技术
挑战:同时包含数值型(电压、温度)与分类型(故障码、用户评价等级)数据。
解决方案:
-
K-prototype算法:
-
数值变量使用欧氏距离,分类变量使用汉明距离
-
距离计算公式:
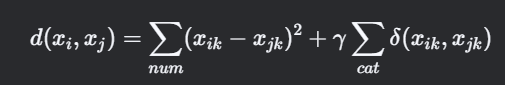
其中γ为分类变量权重系数,通常取数值变量标准差均值。
-
代码示例(R语言):
library(clustMixType) data <- read.csv("mixed_data.csv") kp <- kproto(data, k=3, lambda=0.5, verbose=FALSE)
-
-
Gower距离 + PAM聚类:
-
Gower距离公式:
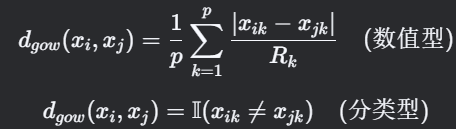
-
实现工具:Python
gower包 +sklearn_extra.cluster.KMedoids
-
2.2 工程化改进策略(新增代码级优化)
2.2.1 动态特征加权
针对关键参数(如SOC、电机温度)进行权重强化:
from sklearn.cluster import KMeans
import numpy as np
class WeightedKMeans(KMeans):
def __init__(self, weights, **kwargs):
super().__init__(**kwargs)
self.weights = weights
def _transform(self, X):
return X * np.sqrt(self.weights)
# 使用示例
weights = [0.2, 0.5, 0.3] # 对应各特征的权重
model = WeightedKMeans(weights, n_clusters=3)
model.fit(X)
2.2.2 增量式聚类(车载实时处理)
使用MiniBatch K-means处理高速数据流:
from sklearn.cluster import MiniBatchKMeans
import numpy as np
# 初始化模型
mbk = MiniBatchKMeans(n_clusters=3, batch_size=1000, reassignment_ratio=0.1)
# 模拟数据流处理
for i in range(0, len(data), 1000):
batch = data[i:i+1000]
mbk.partial_fit(batch)
current_centers = mbk.cluster_centers_
# 实时更新控制策略
update_control_policy(current_centers)
3、经济性优化:全链路数据驱动方案
3.1 用户能耗行为分析
步骤1:数据采集与清洗
import pandas as pd
from sklearn.impute import KNNImputer
# 读取原始OBD数据
raw_data = pd.read_csv("obd_log.csv")
# 缺失值处理(KNN插补)
imputer = KNNImputer(n_neighbors=5)
data_imputed = imputer.fit_transform(raw_data)
# 异常值过滤(IQR法则)
Q1 = np.percentile(data_imputed, 25, axis=0)
Q3 = np.percentile(data_imputed, 75, axis=0)
IQR = Q3 - Q1
filter_mask = ~((data_imputed < (Q1 - 1.5 * IQR)) | (data_imputed > (Q3 + 1.5 * IQR))).any(axis=1)
clean_data = data_imputed[filter_mask]
步骤2:特征工程
# 构造衍生特征
df['急加速指数'] = df['加速踏板变化率'] * df['电机扭矩梯度']
df['动能回收效率'] = df['制动能量回收量'] / (df['车速']**2)
# 标准化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df)
步骤3:聚类建模与评估
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 确定最佳K值
silhouette_scores = []
for k in range(2, 6):
kmeans = KMeans(n_clusters=k)
labels = kmeans.fit_predict(scaled_data)
silhouette_scores.append(silhouette_score(scaled_data, labels))
# 选择K=3进行聚类
final_model = KMeans(n_clusters=3)
clusters = final_model.fit_predict(scaled_data)
# 可视化(TSNE降维)
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2)
vis_data = tsne.fit_transform(scaled_data)
plt.scatter(vis_data[:,0], vis_data[:,1], c=clusters)
步骤4:业务策略生成
# 群体特征分析
cluster_profile = df.groupby(clusters).agg({
'急加速指数': 'mean',
'平均车速': 'median',
'空调使用率': lambda x: (x > 0.5).mean()
})
# 优化策略映射
strategies = {
0: "推送平稳驾驶提示+优化空调预冷策略",
1: "解锁高功率充电模式+电池主动冷却",
2: "限制电机峰值功率+增强动能回收"
}
4、动力性提升:从部件到系统的协同优化
4.1 电机-电池-电控协同聚类
数据融合架构
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 电机系统 │ │ 电池系统 │ │ 环境数据 │
│ - 效率MAP │◄─────►│ - SOC曲线 │◄─────►│ - 温度 │
│ - 扭矩响应 │ │ - 内阻分布 │ │ - 坡度 │
└──────────────┘ └──────────────┘ └──────────────┘
▼ ▼ ▼
┌───────────────────────────────────────────────────┐
│ 联合特征矩阵 (100+维度) │
└───────────────────────────────────────────────────┘
▼
┌───────────────┐
│ 分层聚类 │
│ (Ward方法) │
└───────────────┘
▼
┌─────────────────────────┐
│ 最优工作区间划分 │
│ - 高功率模式 │
│ - 经济巡航模式 │
└─────────────────────────┘
工程实现代码(MATLAB/Simulink示例)
% 导入电机效率MAP数据
motorData = readmatrix('motor_map.csv');
% 电池放电曲线拟合
batterySOC = 0:0.1:1;
batteryPower = 150 - 50*(1 - batterySOC).^2;
p = polyfit(batterySOC, batteryPower, 3);
% 联合聚类分析
combinedData = [motorData(:,2:3), batteryPower'];
Z = linkage(combinedData, 'ward', 'euclidean');
dendrogram(Z);
clusterIDs = cluster(Z, 'maxclust', 3);
% 控制策略生成
if clusterID == 1
set_param('VehicleModel/MotorControl', 'PeakTorque', '400');
elseif clusterID == 2
set_param('VehicleModel/MotorControl', 'PeakTorque', '300');
end
4.2 实时动态调校系统设计
边缘计算架构
车载传感器数据流
▼
[数据采集模块] → 10ms时间窗 → 标准化处理 → 特征提取 → 增量聚类 → 控制指令生成
▲ ▼ ▼
└───── 历史聚类中心反馈 ────────┘ └──→ [VCU执行器]
嵌入式C++实现核心逻辑
#include <vector>
#include <Eigen/Dense>
using namespace Eigen;
class RealTimeCluster {
public:
RealTimeCluster(int k, int dim) :
k(k), dim(dim),
centers(MatrixXd::Zero(k, dim)),
counts(VectorXi::Zero(k)) {
}
void update(const VectorXd& sample) {
// 寻找最近聚类中心
int nearest = findNearest(sample);
// 更新中心(指数衰减)
double eta = 1.0 / (++counts[nearest]);
centers.row(nearest) = (1 - eta) * centers.row(nearest) + eta * sample;
}
private:
int findNearest(const VectorXd& x) {
VectorXd distances(k);
for (int i=0; i<k; ++i) {
distances[i] = (x - centers.row(i)).norm();
}
return std::min_element(distances.begin(), distances.end()) - distances.begin();
}
MatrixXd centers;
VectorXi counts;
int k, dim;
};
五、工程挑战与解决方案(扩展实战技巧)
5.1 高维数据降维实战
问题:电机电磁场仿真数据(800+维度)导致聚类失效
解决方案:
-
前置特征选择:
- 使用随机森林评估特征重要性
from sklearn.ensemble import RandomForestRegressor rf = RandomForestRegressor() rf.fit(X, y) importance = rf.feature_importances_ selected_features = X[:, importance > 0.01] -
t-SNE参数调优:
tsne = TSNE( n_components=3, perplexity=30, # 根据数据量调整(通常5-50) early_exaggeration=12, learning_rate=200 ) -
密度聚类优化:
dbscan = DBSCAN( eps=0.5, min_samples=5, metric='euclidean', algorithm='ball_tree' )
5.2 模型可解释性增强
策略:聚类结果与决策树融合
from sklearn.tree import DecisionTreeClassifier
# 使用聚类标签作为决策树目标
tree = DecisionTreeClassifier(max_depth=3)
tree.fit(X, cluster_labels)
# 可视化决策规则
from sklearn.tree import plot_tree
plot_tree(tree, feature_names=feature_names)
输出示例:
if 电机温度 > 85℃ and SOC < 20%:
归为"高风险组" → 触发功率限制
elif 加速踏板变化率 > 50%/s:
归为"激进驾驶组" → 优化扭矩响应曲线
六、工业级工具链与协作流程(新增团队协作指南)
6.1 研发团队协作框架
数据工程师
│ ▲
▼ │
[数据湖] ←─────────────┐
│ │
▼ │
算法工程师 → [特征仓库] → 聚类模型训练
│ ▲
▼ │
测试工程师 → [验证平台] → 模型部署
│
▼
整车集成 → 实车标定
6.2 工具链集成示例
七、未来趋势与研发建议(扩展技术前瞻)
7.1 联邦学习在跨车企数据协同中的应用
-
技术架构:
各车企本地数据 → 加密特征提取 → 全局聚类模型更新 ← 参数聚合服务器 -
优势:
- 保护数据隐私的同时利用行业级数据优化模型
- 解决单一车企数据量不足的问题
7.2 数字孪生驱动的闭环优化系统
实车传感器 → 数字孪生体 → 虚拟聚类分析 → 优化策略 → OTA更新 → 实车
7.3 量子计算加速
- Grover算法:将聚类中心的搜索复杂度从O(N)降至O(√N)
- 量子主成分分析(QPCA):加速高维数据降维过程
结语(增强版):
聚类分析正在重塑新能源汽车研发的每个环节——从电池分选到用户画像,从实时控制到长期可靠性管理。作为测试工程师,需掌握三大核心能力:
- 数据敏感度:从海量测试数据中提取关键特征
- 算法工程化能力:将理论模型转化为嵌入式代码
- 系统思维:理解聚类结果与整车系统的关联影响
文末互动:
“在实际项目中,你是如何处理高维车辆数据的?欢迎在评论区分享你的实战经验!”