论文链接:https://arxiv.org/abs/2502.17157
代码链接:https://aim-uofa.github.io/Diception/
主推一个通用的任务框架
本文介绍了一个名为 DICEPTION 的多任务视觉通用模型,旨在通过有限的计算资源和训练数据,高效地解决多种视觉感知任务。文章的核心动机是探索如何利用预训练的扩散模型(diffusion models)的强大先验知识,来构建一个能够处理多种视觉任务的通用模型,从而避免为每个任务单独训练模型的高成本。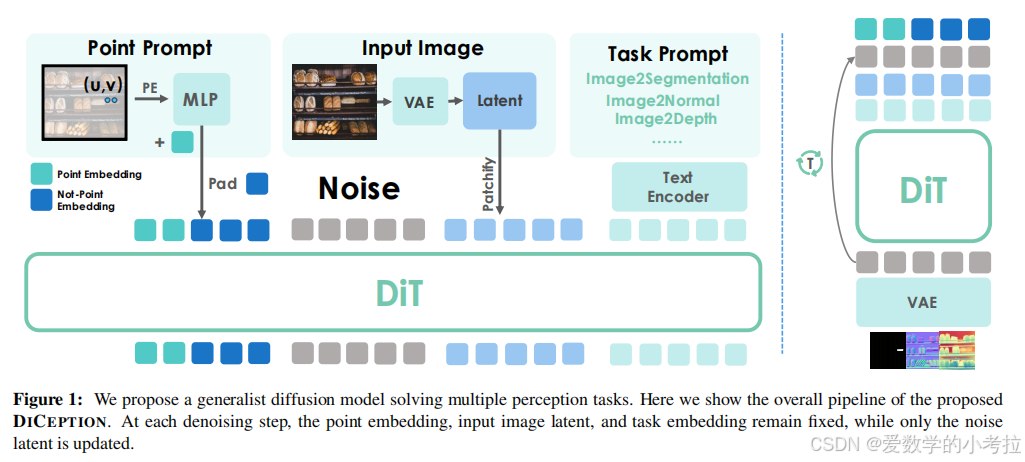
研究动机
-
视觉任务的多样性与挑战:在计算机视觉领域,不同任务(如图像分割、深度估计、姿态估计等)之间的表示差异较大,导致现有的视觉基础模型通常只能专注于单一任务。这种任务专一性限制了模型的通用性和适应性。
-
数据与计算资源的限制:传统的多任务模型通常需要大量的数据和计算资源来训练,这使得它们难以广泛应用。例如,SAM(Segment Anything Model)需要数十亿像素级别的标注数据来实现高质量的分割性能。
-
扩散模型的潜力:扩散模型在图像生成领域取得了巨大成功,但其在多任务视觉感知中的潜力尚未被充分挖掘。作者希望利用扩散模型的强大先验知识,以更高效的方式解决视觉感知任务。
研究方案
-
统一任务表示:DICEPTION 将多种视觉任务的输出统一为 RGB 空间。例如,深度图和分割掩码通过重复通道数据转换为三通道 RGB 格式;对于实例分割,模型通过为每个实例分配随机颜色来区分不同的对象。
-
模型架构:DICEPTION 基于预训练的扩散模型(如 SD3),并引入简单的任务提示(如“image2depth”或“image2segmentation”)来指导模型执行不同任务。对于点提示分割任务,模型通过一个两层的 MLP 处理点提示,以生成与输入图像隐藏状态维度匹配的点嵌入。
-
训练与微调:DICEPTION 在训练时仅使用约 180 万张图像,远少于传统方法所需的海量数据。此外,模型能够通过少量数据(如 50 张图像)和微调极少数参数(不到 1%)快速适应新任务。
核心贡献
-
高效多任务性能:DICEPTION 在多种视觉感知任务(如深度估计、法线估计、点提示分割、语义分割等)上实现了与专用模型相当的性能,但仅使用了极少量的训练数据。例如,与 SAM 相比,DICEPTION 在分割任务上达到了类似的性能,但仅使用了其 0.06% 的数据。
-
快速适应新任务:DICEPTION 能够通过少量样本(如 50 张图像)和微调不到 1% 的参数,快速适应新任务,如肺部分割、肿瘤分割和图像高光增强等。
-
统一框架与实验洞察:文章提出了一个统一的多任务框架,并通过广泛的实验验证了其有效性。此外,作者还探讨了多任务模型中的网络架构、一步扩散技术等关键因素,并为未来研究提供了有价值的见解。
总结
DICEPTION 通过将多种视觉任务统一为条件图像生成问题,并利用预训练扩散模型的强大先验知识,实现了一个高效、通用的视觉感知模型。该模型不仅在多种任务上达到了与专用模型相当的性能,还展示了快速适应新任务的能力。DICEPTION 的提出为构建高效、通用的视觉基础模型提供了新的思路和方法。