点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


一、论文信息

1
论文题目:Vision Transformer with Quadrangle Attention中文题目:具有四边形注意力机制的视觉Transformer论文链接:https://arxiv.org/pdf/2303.15105
所属单位:澳大利亚悉尼大学工程学院计算机科学系
核心速览:本文提出了一种名为“Quadrangle Attention (QA),四边形注意力”的新型视觉变换器注意力机制,旨在通过学习数据驱动的四边形配置来计算局部注意力,从而提高视觉变换器对不同大小、形状和方向物体的适应性。

二、论文概要

Highlight
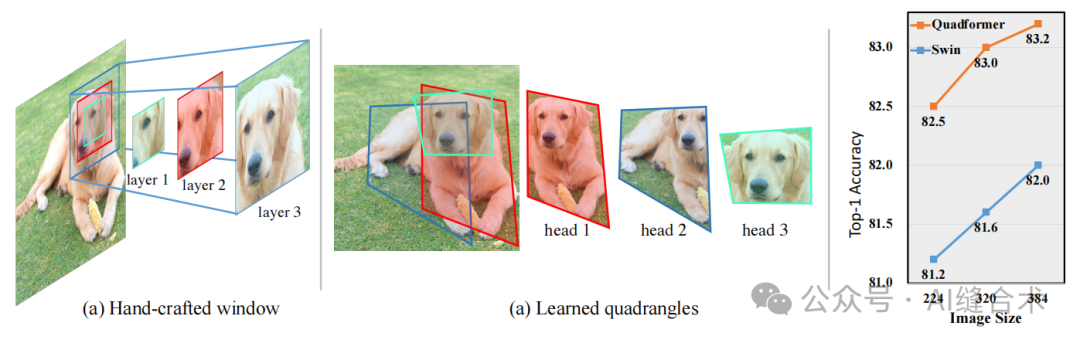
图1:先前手工设计的窗口配置 (a)与所提出的可学习四边形设计(b)的比较,以及它们在ImageNet 验证集上不同输入尺寸设置下的图像分类性能(c)。

图7:QFormerh-T生成的四边形可视化。 该模型在ImageNet上进行了分类训练。

图8:QFormerh-T生成的四边形可视化。该模型在MS COCO上进行物体检测和实例分割的训练。
1. 研究背景:
研究问题:现有的基于窗口的注意力机制虽然在性能、计算复杂度和内存占用方面取得了平衡,但其设计的窗口是手工制作的,无法适应不同大小、形状和方向的物体,限制了变换器捕捉丰富上下文信息的能力。如何设计一种新的注意力机制,以提高视觉变换器对各种目标的适应性,并捕捉丰富的上下文信息?
研究难点:现有的基于窗口的注意力机制由于其固定形状的窗口设计,无法有效处理不同大小、形状和方向的目标,这限制了变换器捕捉长距离依赖关系的能力。此外,如何在不显著增加计算成本的情况下,通过学习机制来适应不同目标的特征表示,也是一个挑战。
文献综述:之前的研究尝试通过扩大窗口大小、设计不同形状的窗口(如Focal attention、cross-shaped window attention和Pale)来改进基于窗口的注意力机制,以增强图像分类性能。然而,这些方法仍然采用固定形状的窗口进行注意力计算,没有充分利用数据驱动的方法来自动学习最优的窗口参数。本文提出了一种数据驱动的解决方案,通过将默认的矩形窗口扩展到四边形,使变换器能够学习更好的特征表示来处理各种不同的物体。
2. 本文贡献:
四边形注意力机制(QA):提出了一种新颖的四边形注意力机制,该机制通过学习数据来确定注意力区域,扩展了基于窗口的注意力到四边形的通用形式。该方法包含一个端到端可学习的四边形回归模块,预测变换矩阵以将默认窗口转换为目标四边形,从而实现对不同形状和方向目标的建模,并捕获丰富的上下文信息。
QFormer架构:将QA集成到平面和分层视觉变换器中,创建了一个名为QFormer的新架构。该架构仅需要对现有代码进行少量修改,并且额外的计算成本可以忽略不计。QFormer在多个视觉任务上均表现出色,包括分类、目标检测、语义分割和姿态估计。
实验验证:在多个公共基准数据集上进行了广泛的实验和消融研究,以验证QA的有效性和QFormer在各种视觉任务上的优越性。实验结果表明,QFormer在各种视觉任务上均优于现有的代表性视觉变换器。

三、创新方法

1
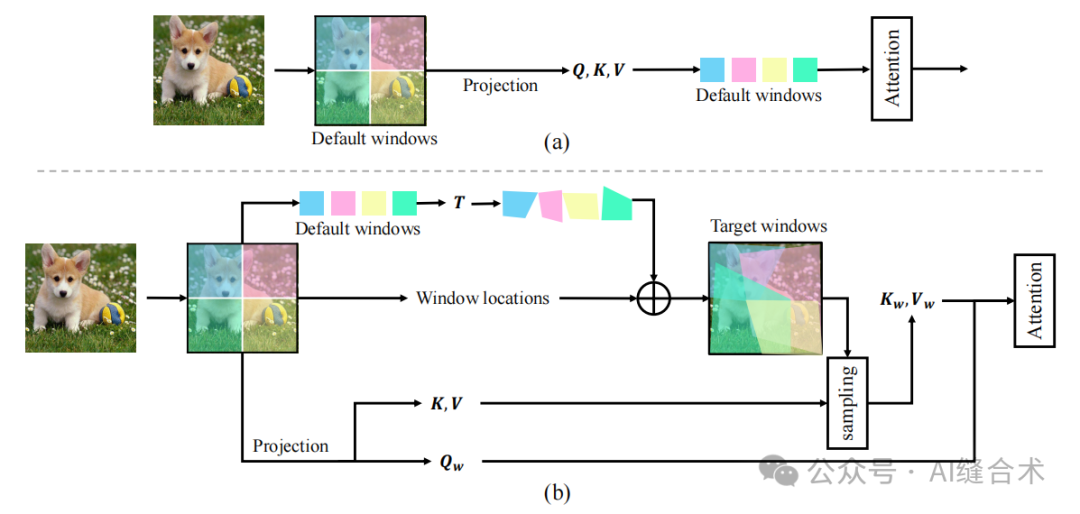
图2:窗口注意力的示意图 (a) 和提出的四边形注意力 (QA) (b)。
I、四边形注意力(Quadrangle Attention,QA)实现过程:
一、基础窗口生成
输入特征图首先被划分为若干个预定义大小为w的窗口,这些窗口被称为基础窗口X。
从每个基础窗口中获取查询(Query)、键(Key)和值(Value)令牌,即Q; K; V = Linear(X)。
对于QA计算,直接使用查询令牌Q,而将键和值令牌重塑为特征图,用于后续的采样步骤。
二、四边形生成

图 4:投影变换流程的示意图。(a) 默认窗口。(b) 计算相对于窗口中心的相对坐标 (x_c, y_c)。(c) 经过对相对坐标进行投影变换后得到目标四边形。(d) 通过加上窗口中心坐标来恢复绝对坐标。
将基础窗口视为参考,利用投影变换将每个基础窗口转换为目标四边形。
投影变换由八个参数的变换矩阵表示,包括缩放、旋转、剪切和平移等。
QA使用四边形预测模块预测基础窗口的投影变换,该模块首先预测替代参数t ∈ R9。
根据输出t,获得基本变换,包括缩放Ts、剪切Th、旋转Tr、平移Tt和投影Tp。
通过顺序乘以所有变换获得最终的变换矩阵T,即T = Ts × Th × Tr × Tt × Tp。
利用标准投影过程,通过变换矩阵获得投影点的位置。
三、相对坐标计算
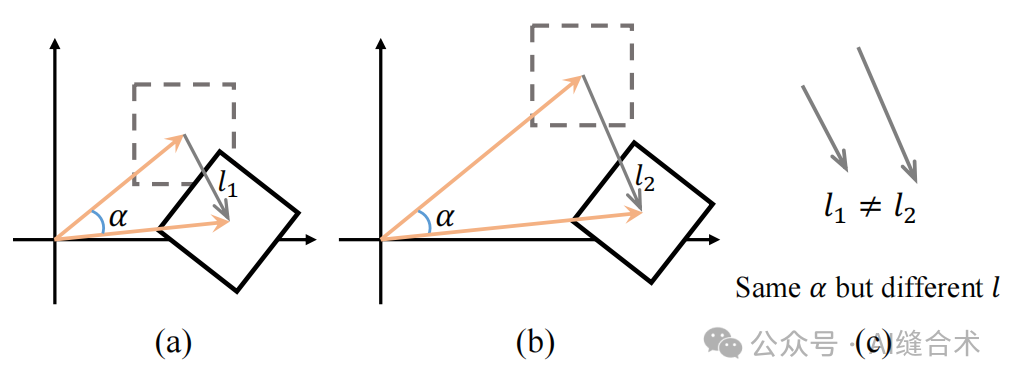
图 5:使用绝对坐标对两个不同位置的窗口进行相同变换的比较。
计算每个窗口内各点相对于窗口中心的相对坐标(xri; yri)。
利用变换矩阵T,将相对坐标转换为目标四边形中的相对坐标(xrq;i; yrq;i)。
通过加上窗口中心坐标(xc; yc),恢复绝对坐标(xq;i; yq;i)。
四、采样策略
使用网格采样函数从K和V中采样目标四边形的键和值令牌Kw;Vw。
为了解决可能生成覆盖特征图外部区域的四边形问题,提出了一种简单的采样策略:a. 对于特征图内的采样坐标,使用双线性插值采样值;b. 对于特征图外的坐标,使用零向量作为采样值。
五、自注意力计算
使用采样得到的Kw;Vw和原始的Qw进行自注意力计算,计算公式为:
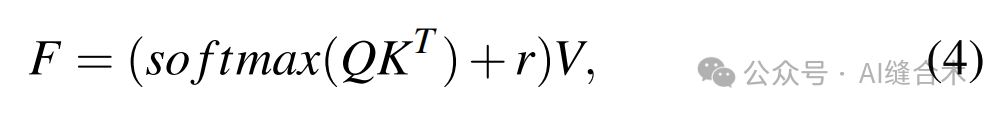
其中 r 是相对位置嵌入用来编码空间信息,在训练过程中是可学习的。
总结:四边形注意力通过数据驱动的方式动态确定每个窗口的位置、大小、方向和形状,从而允许模型更好地捕捉不同大小、方向和形状的对象,并捕获丰富的上下文信息。
II、四边形注意力(Quadrangle Attention,QA)的应用位置:
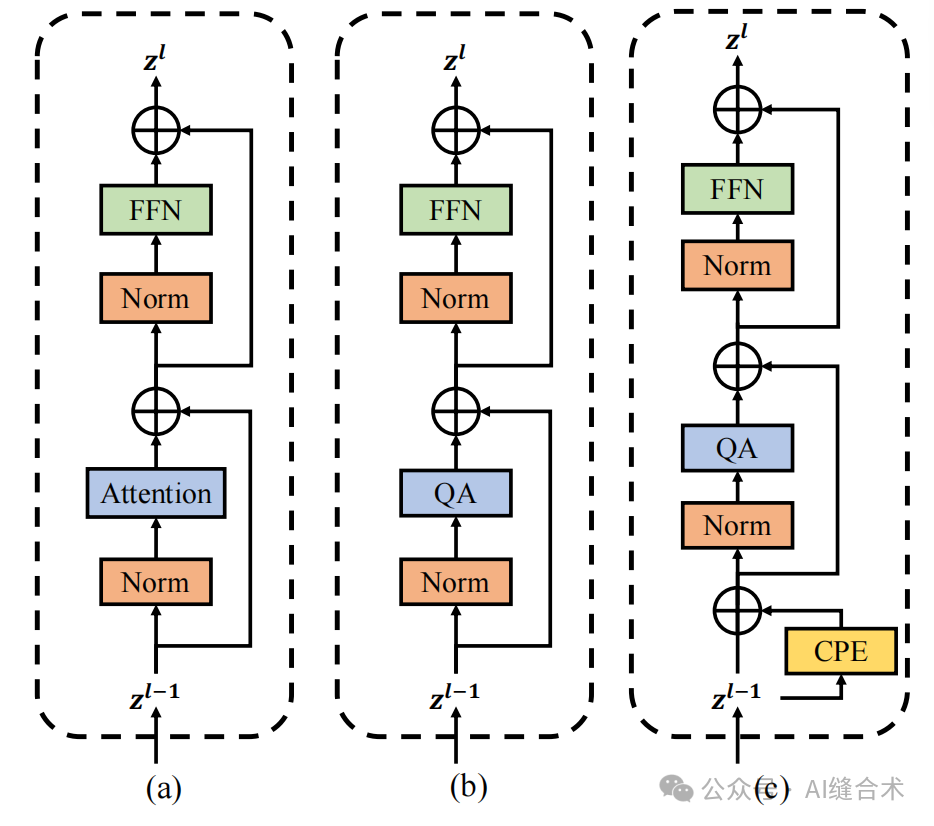
图3:传统窗口注意力块(a),提出的纯ViT中的QA(b),以及分层ViT(c)。
III、基于四边形注意力设计的QFormer:
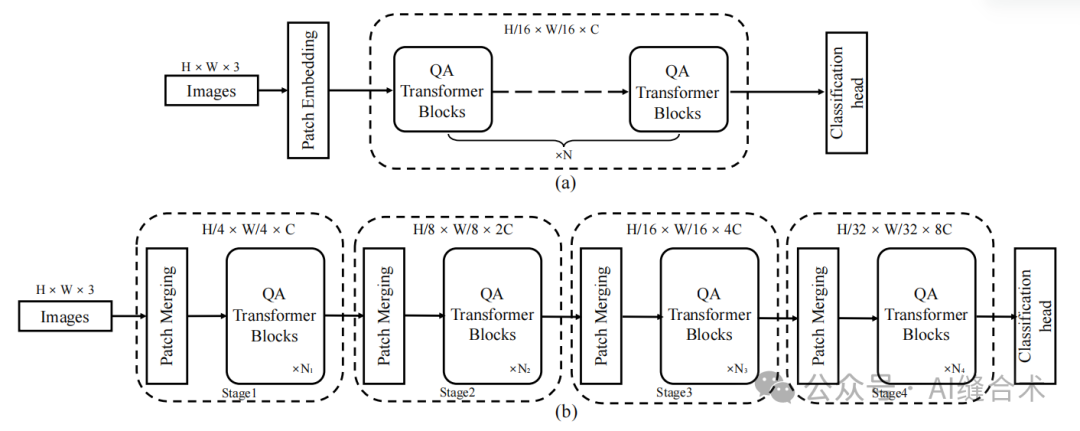
图6:窗口注意力的流程图(a),提出的四边形注意力(QA) (b),以及带有提出的四边形注意力的变换器块QFormer的细节。

四、实验分析

1. 数据集与评估指标:在ImageNet-1k、ADE20k和MS COCO等知名公共数据集上进行实验,评估指标包括Top-1和Top-5准确率、平均精度均值(mAP)和交并比(IoU)。
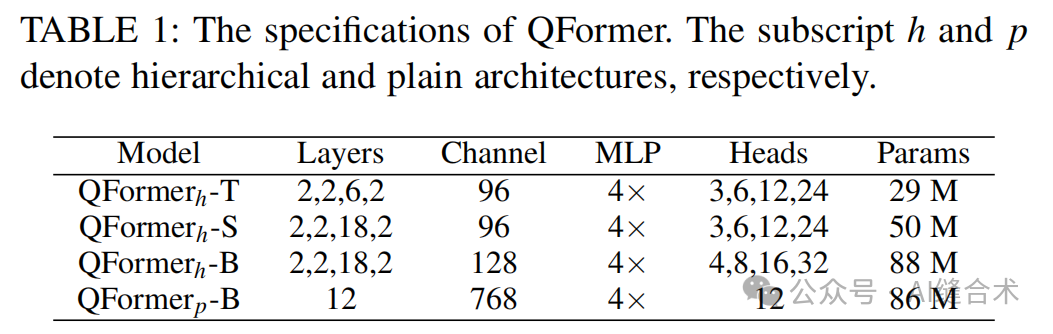
2. 模型规格:QFormer模型包括不同层数和通道数的变体,例如QFormer h-T、QFormer h-S和QFormer h-B,以及对应的plain架构QFormerp-B。这些模型在不同任务上表现出色,具有不同的参数和计算复杂度。
3. 训练细节:使用AdamW优化器和不同的学习率调度策略进行训练,训练过程包括预训练和微调阶段。对于不同的下游任务,使用ImageNet-1k预训练权重进行初始化。
4. 实验结果:
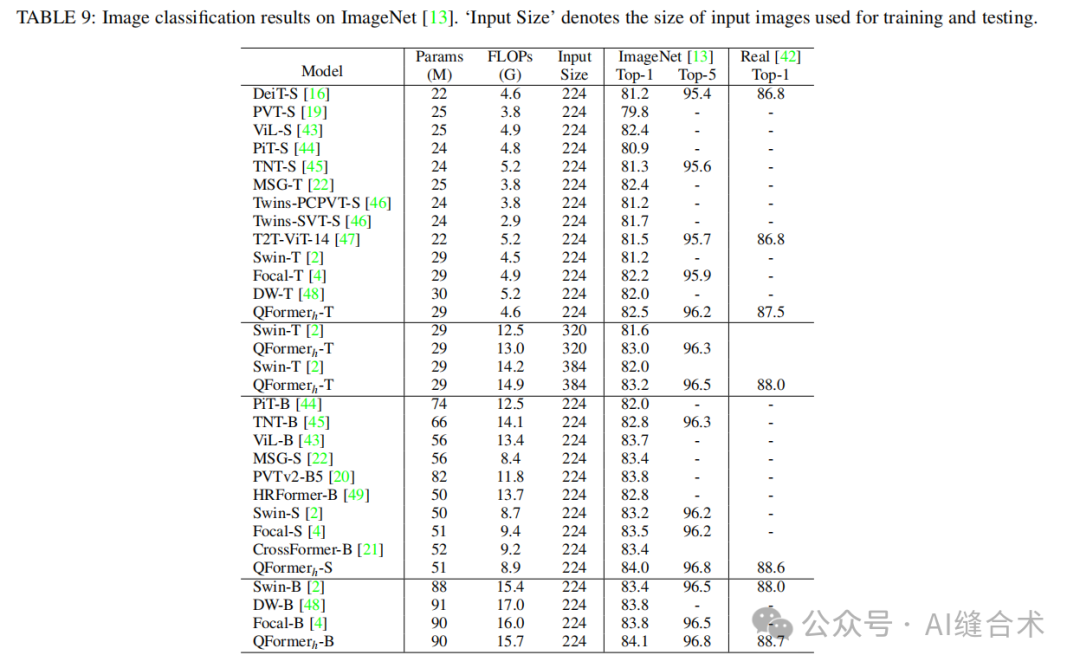
图像分类:QFormer在ImageNet-1k数据集上的分类任务中表现出色,特别是在处理不同大小和形状的目标时。例如,QFormer h-T在224×224输入尺寸下达到了82.5%的Top-1准确率,比Swin-T高出1.3%。
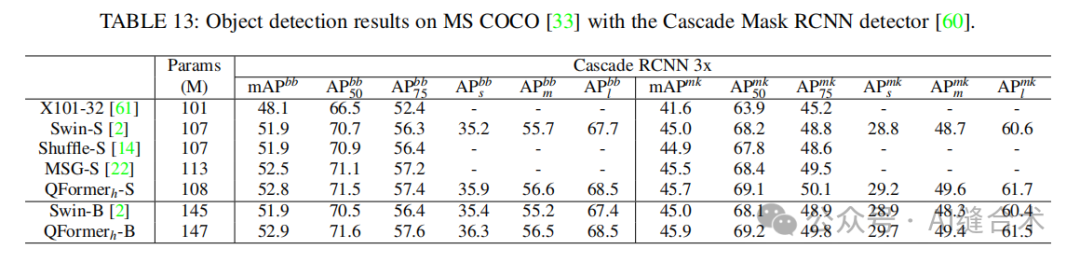
目标检测与实例分割:在MS COCO数据集上,QFormer在目标检测和实例分割任务中均优于基线方法Swin-T。例如,QFormer h-T在使用Mask RCNN检测器时,相较于Swin-T在1×训练计划下提高了2.2 mAPbb和1.7 mAPmk。
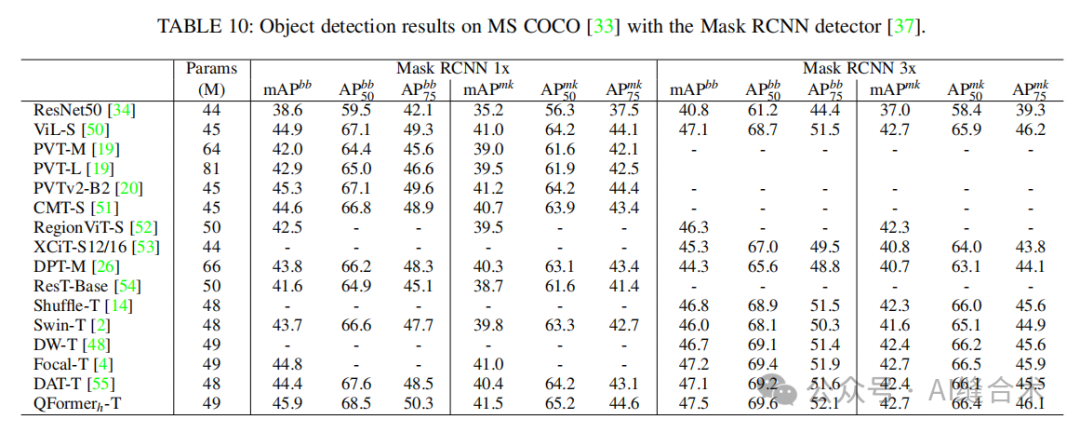
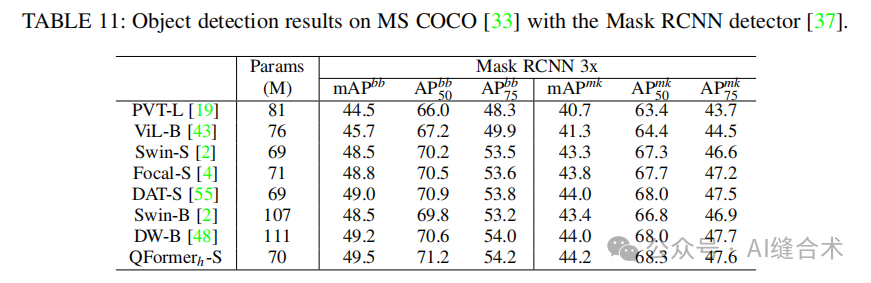

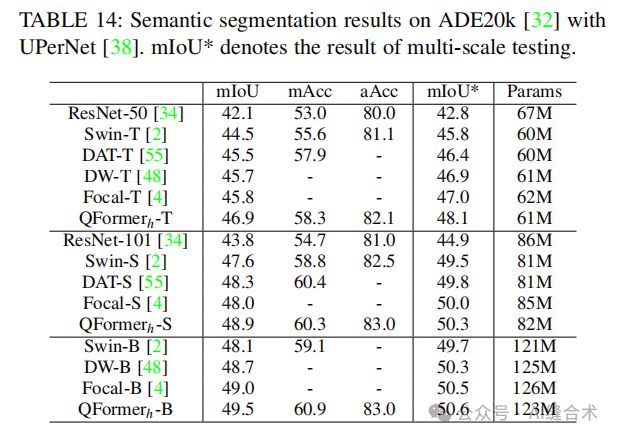
语义分割:在ADE20k数据集上,QFormer在语义分割任务中也取得了优异的成绩。例如,QFormer h-T在512×512图像上达到了43.6 mIoU,比使用固定窗口注意力的ViT-B模型高出2.0 mIoU。
姿态估计:在MS COCO数据集上,QFormer在姿态估计任务中同样表现出色。例如,QFormer h-T在使用Mask RCNN检测器时,相较于Swin-T在1×训练计划下提高了0.6 APbbs、0.9 APblb和1.6 APmlk。

五、结论

1
1. 研究发现:提出的四边形注意力机制(QA)能够有效地从数据中学习注意力区域,显著提升了视觉变换器处理不同大小、形状和方向目标的能力。通过将QA集成到视觉变换器中,创建了QFormer架构,该架构在多个视觉任务上均表现出色,包括分类、目标检测、语义分割和姿态估计。
2. 解释与分析:QFormer通过学习适应性窗口配置,能够更好地建模长距离依赖关系,并促进跨窗口信息交换,从而学习到更好的特征表示。实验结果表明,QFormer在各种视觉任务上均优于现有的代表性视觉变换器,证明了QA的有效性和QFormer架构的优越性。
3. 意外发现:尽管QFormer在性能上有所提升,但其在推理速度上仅比Swin Transformer慢约13%,这表明QA在实现速度和准确性之间的更好权衡方面具有巨大潜力。此外,QFormer在处理不同尺度对象时表现出色,这表明其学习到的四边形能够适应各种形状和方向的目标。

六、代码与运行结果

1
 温馨提示:对于所有推文中出现的代码,如果您在微信中复制的代码排版错乱,请复制该篇推文的链接,在任意浏览器中打开,再复制相应代码,即可成功在开发环境中运行!或者进入官方github仓库找到对应代码进行复制!
温馨提示:对于所有推文中出现的代码,如果您在微信中复制的代码排版错乱,请复制该篇推文的链接,在任意浏览器中打开,再复制相应代码,即可成功在开发环境中运行!或者进入官方github仓库找到对应代码进行复制!
运行结果



七、附录
1
便捷下载
https://github.com/AIFengheshu/Plug-play-modules下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~