目录
一、引言
2025年的春节,注定是一个被AI深刻标记的节日。DeepSeek以其卓越的性能和低成本优势迅速走红,成为全球科技圈的焦点,不仅让科技圈沸腾,更让普通人看到了AI技术带来的无限可能。
然而,随着其火热程度的攀升,用户激增和恶意攻击问题也随之而来。作为一款备受欢迎的人工智能平台,DeepSeek在高峰时段面临大量用户同时发起请求,导致服务器处理不过来,出现繁忙状态。同时,有观点认为,DeepSeek可能遭受了大规模的恶意网络攻击,如分布式拒绝服务攻击(DDoS),进一步加剧了服务器的负担,影响正常运行。
值得庆幸的是,DeepSeek R1的开源为这一问题提供了解决方案。对于有一定技术能力的用户,可以考虑将DeepSeek模型部署到本地服务器上,以避免网络延迟和服务器负载问题,从而提高响应速度和稳定性。这一举措不仅缓解了服务器压力,也为用户提供了更加高效和可靠的使用体验。本文将详细介绍如何在Docker容器中部署DeepSeek R1镜像,帮助用户快速实现本地化部署,享受更流畅的AI服务。
二、电脑配置要求
为了流畅使用,建议采用推荐配置要求,有条件的可以采用高性能配置
| 配置类型 | CPU | 内存 | 存储 | GPU | 操作系统 | 其他要求 |
|---|---|---|---|---|---|---|
| 最低配置 | 4核处理器 | 8GB RAM | 20GB 可用空间 | 无要求(仅CPU运行) | Linux (Ubuntu 18.04+) 或 Windows 10/11 | Python 3.8+ |
| 推荐配置 | 8核处理器 | 16GB RAM | 50GB 可用空间 | NVIDIA GTX 1080 或更高 | Linux (Ubuntu 18.04+) 或 Windows 10/11 | Python 3.8+, CUDA 11.0+(如需GPU加速) |
| 高性能配置 | 12核或更多 | 32GB RAM | 100GB 可用空间 | NVIDIA RTX 2080 Ti 或更高 | Linux (Ubuntu 18.04+) 或 Windows 10/11 | Python 3.8+, CUDA 11.0+(如需GPU加速) |
三、安装Docker及可视化工具
为了简化安装过程并确保环境一致性,推荐使用 Docker 来本地部署 DeepSeek R1。这不仅能够快速启动服务,还能有效解决不同操作系统之间的兼容性问题,采用隔离环境的方式,避免了因环境差异导致的问题。
- Windows环境安装Docker可参考:WSL2中安装Docker—部署Docker Engine方案
四、在WSL2上使用CUDA
借助 NVIDIA CUDA 对 WSL 2 的支持,开发人员可以通过 WSL 在 Windows 上利用 NVIDIA GPU 加速计算技术进行数据科学、机器学习和推理。GPU 加速还可以降低在 WSL 类环境中运行应用程序的性能开销,使其接近原生环境,因为它能够在更少的 CPU 干预下在 GPU 上执行更多并行工作。
1、安装NVIDIA驱动程序
为兼容使用GeForce或NVIDIA RTX/Quadro显卡,需在Windows系统上安装NVIDIA GeForce Game Ready或NVIDIA RTX Quadro Windows 11显示驱动程序,驱动程序可从 NVIDIA驱动程序 下载。
注意:这是您需要安装的唯一驱动程序。请勿在 WSL2 中安装任何 Linux 显示驱动程序。
验证NVIDIA驱动是否正常,Windows运行如下命令
nvidia-smi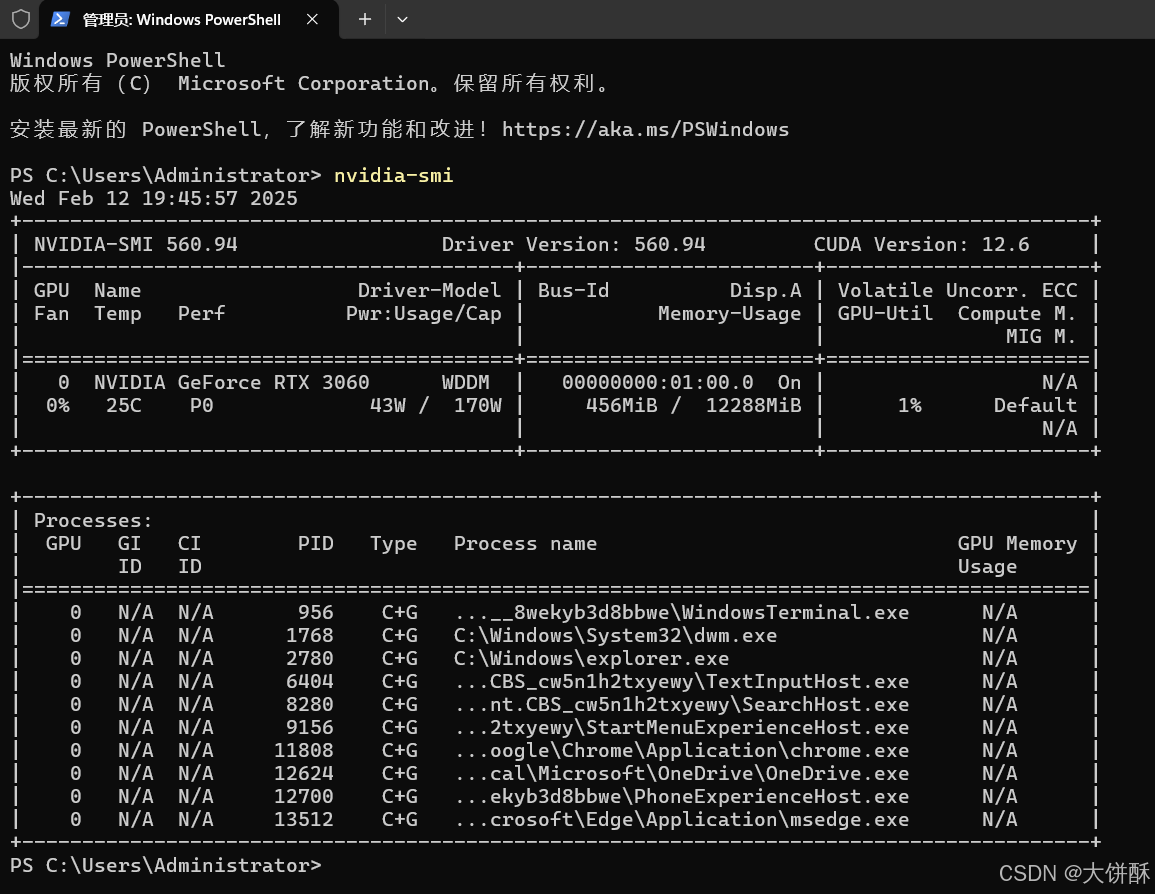
说明已成功安装NVIDIA驱动程序
2、WSL2中安装CUDA工具包
在系统上安装了 Windows NVIDIA GPU 驱动程序后,CUDA 便可在 WSL2 中使用。安装在 Windows 主机上的 CUDA 驱动程序将在 WSL2 中存根为 libcuda.so,因此用户不得在 WSL2 中安装任何 NVIDIA GPU Linux 驱动程序。
但是要编译新的 CUDA 应用程序,需要安装 CUDA 工具包。这里有一点必须注意,默认的 CUDA 工具包附带一个驱动程序,并且很容易用默认安装覆盖 WSL 2 NVIDIA 驱动程序。因此我们建议开发人员使用 CUDA 工具包 下载页面提供的单独的 WSL 2(Ubuntu)CUDA 工具包来避免这种覆盖。
2.1、首先删除旧的 GPG 密钥
sudo apt-key del 7fa2af802.2、安装 CUDA 工具包
由于网络问题,在线安装很容易出错,所以我们使用离线安装的方法。根据实际的CUDA版本,下载对应的CUDA工具包,访问 nvidia 官网驱动下载地址:CUDA工具包下载

通过挂载目录复制下载的CUDA工具包到WSL2中
# 根据实际情况修改
sudo cp /mnt/d/cuda_12.6.0_560.28.03_linux.run /data复制完成以后,就可以安装CUDA工具包。
cd /data
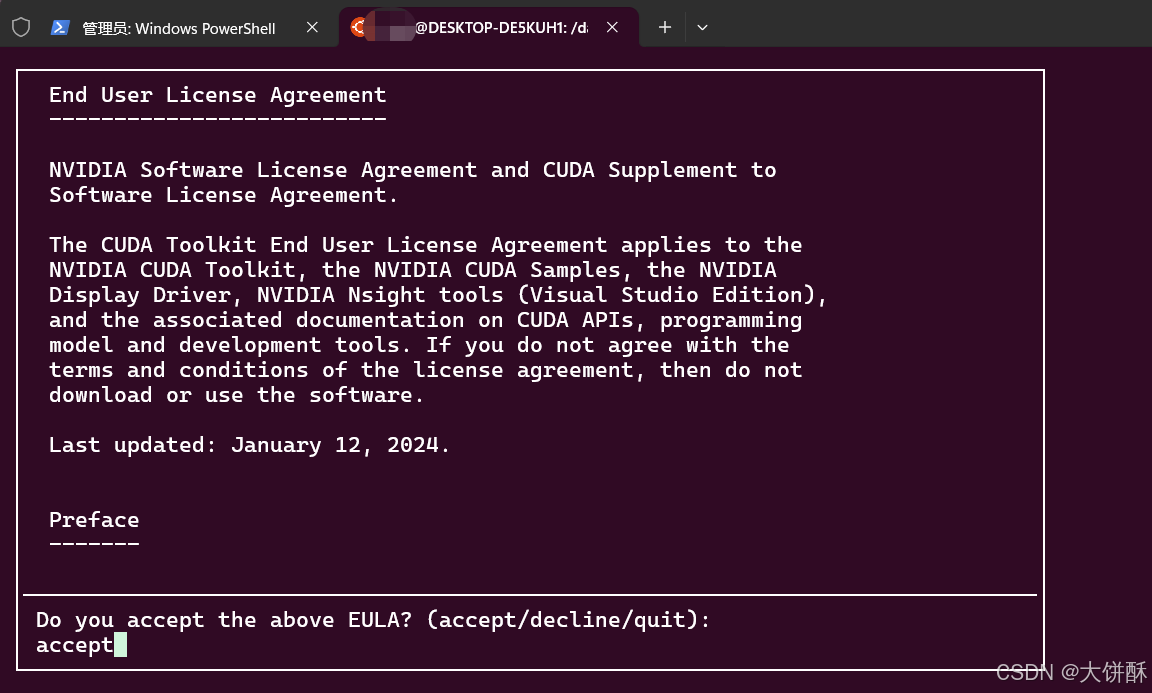
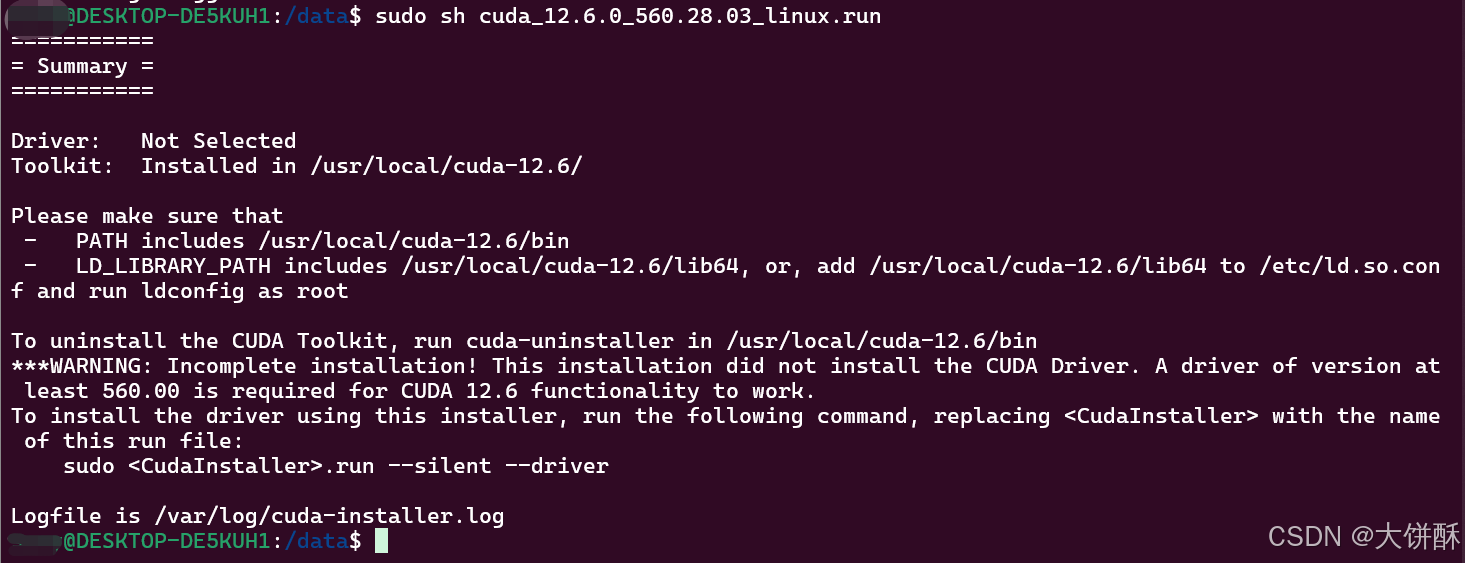
sudo sh cuda_12.6.0_560.28.03_linux.run
说明需要安装 gcc
sudo apt-get install gcc
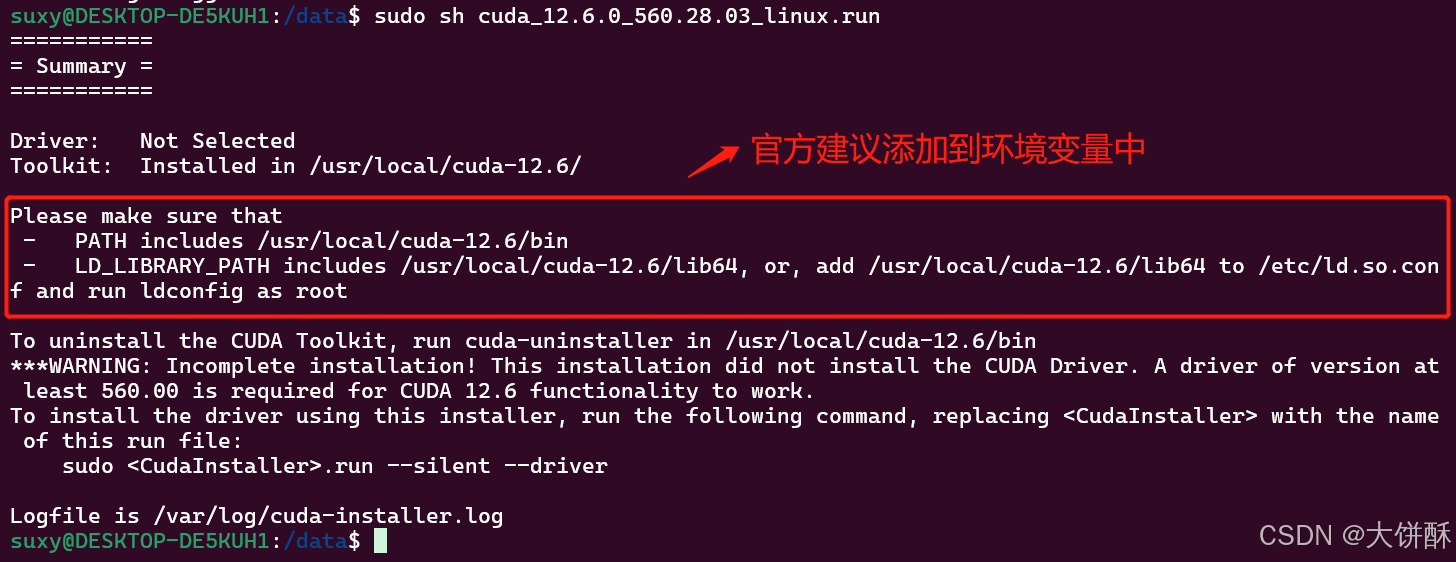
然后重新执行上面的安装驱动的命令
2.3、配置环境变量
编辑 WSL2 的 ~/.bashrc 添加环境变量
我们使用 vi 命令编辑 .bashrc 文件,末尾写入环境变量如下:
export PATH=/usr/local/cuda-12.6/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH
激活环境变量:
source ~/.bashrc2.4、验证是否安装成功
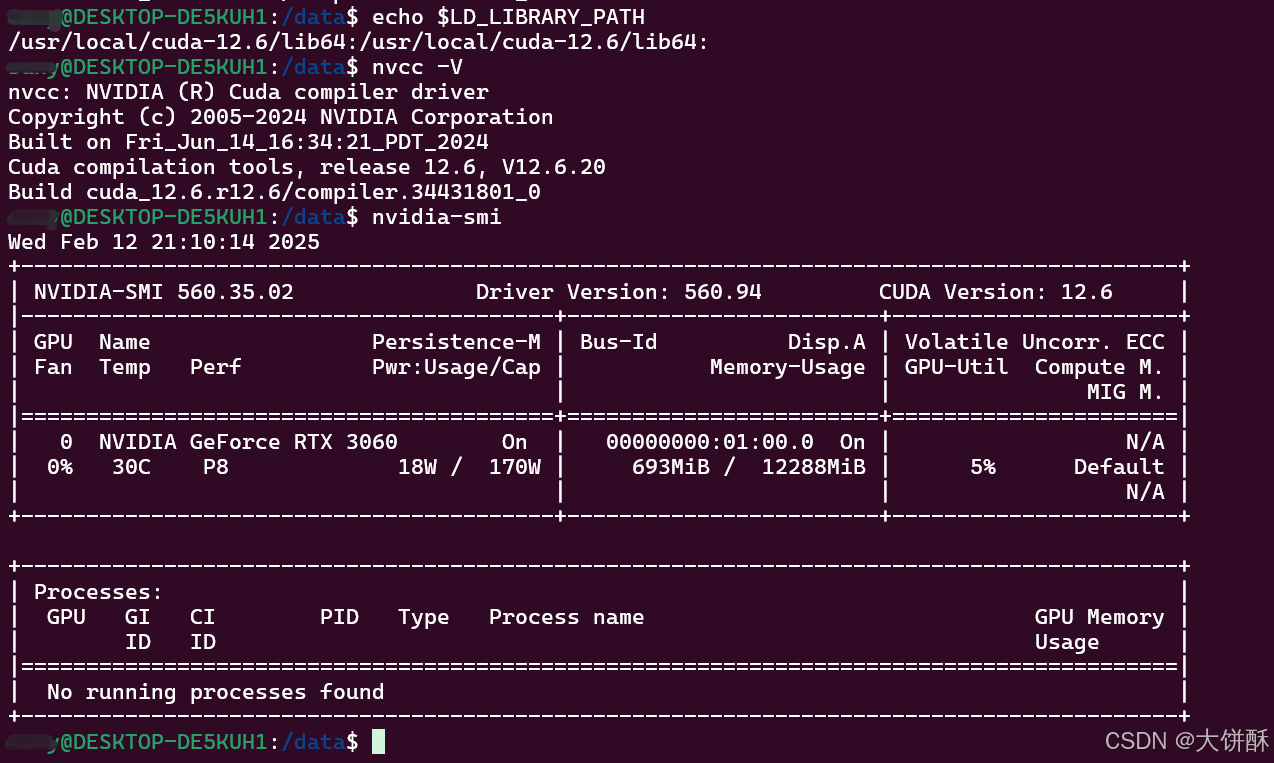
# 1.打印配置的环境变量地址
echo LD_LIBRARY_PATH
# 2.输出显卡的相关信息
nvidia-smi
# 3.输出 nvidia cuda 驱动相关信息
nvcc -V上面三个过程都验证一下,避免出现其它问题
3、安装NVIDIA Container Toolkit
NVIDIA Container Toolkit 是 NVIDIA 为 Docker 提供的一个插件,使 Docker 容器能够访问宿主机的 GPU 资源,用于在 Docker 容器中支持 GPU 加速计算,而无需在容器内安装 NVIDIA 驱动。
WSL2中按步骤执行以下命令
# 1.添加 NVIDIA Container Toolkit 的仓库密钥和源列表
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 2.更新包列表并安装 NVIDIA Container Toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# 3.重启 Docker 服务以使更改生效
sudo systemctl restart docker
# 4.验证 NVIDIA Container Toolkit 是否正确安装
nvidia-container-cli --version
# 5.确认 Docker 是否能够访问 GPU
sudo docker run --rm --gpus all nvidia/cuda:12.0-base nvidia-smi
安装完NVIDIA Container Toolkit后,能够使用 --gpus all选项运行Docker容器,以使容器可以访问宿主机的GPU。
4、Docker中验证CUDA
Docker运行CUDA实例镜像
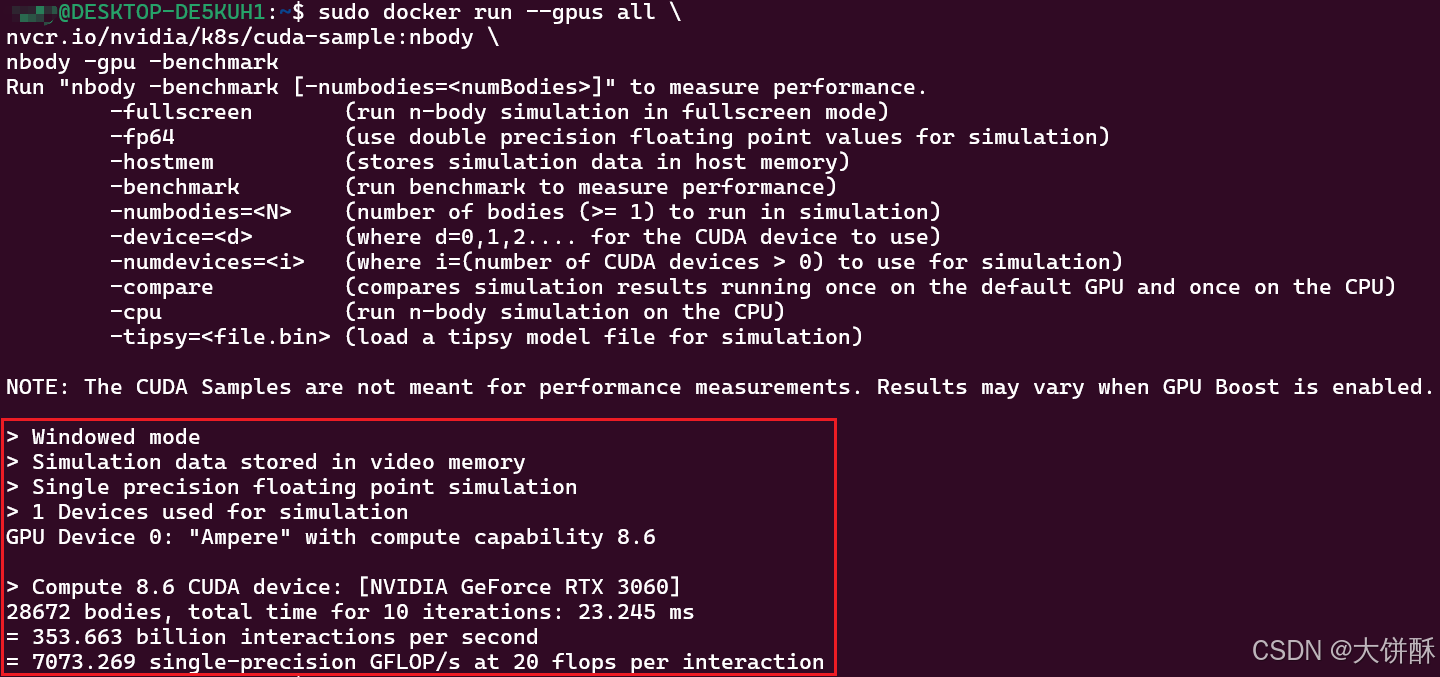
sudo docker run --gpus all \
nvcr.io/nvidia/k8s/cuda-sample:nbody \
nbody -gpu -benchmark日志中包括 CUDA 的相关内容,足够证明 docker 镜像中能使用 CUDA,也就是能使用GPU。
五、安装open-webui+ollama镜像
这里我们不分别安装两次了,我们使用官方提供了的方法,一个镜像包括了 open webui 与 ollama3,更加方便。
1、创建挂载目录
# 创建宿主机挂载目录
sudo mkdir -p /data/docker/ollama-webui2、命令运行镜像
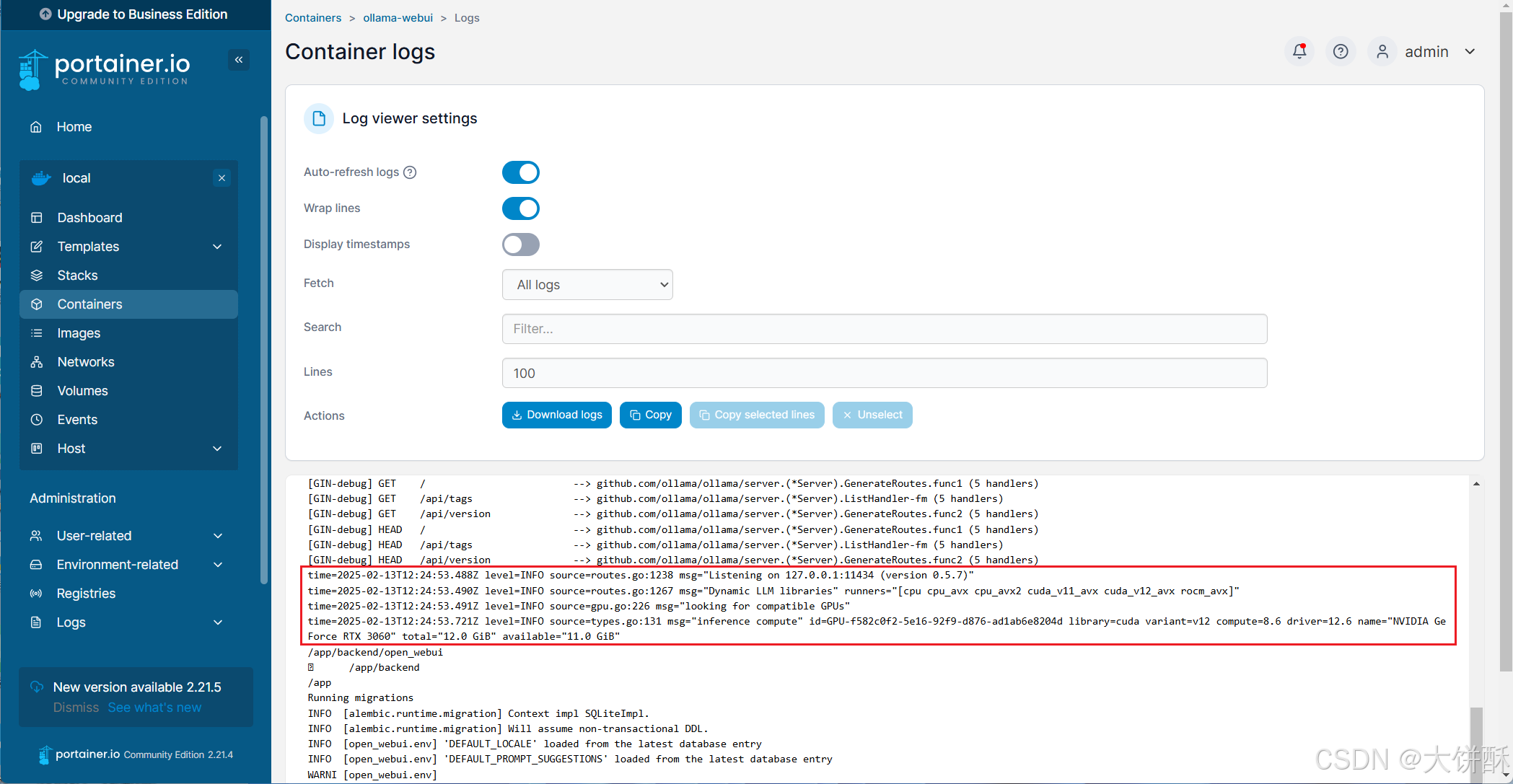
sudo docker run -d -p 3010:8080 --gpus=all \
--name ollama-webui --restart always \
-v /data/docker/ollama-webui/ollama:/root/.ollama \
-v /data/docker/ollama-webui/open-webui:/app/backend/data \
ghcr.io/open-webui/open-webui:ollamaDocker 日志中提示 CUDA 可用,说明一切正常,安装成功
3、部署DeepSeek R1大模型
浏览器访问open-webui,地址: http://127.0.0.1:3010
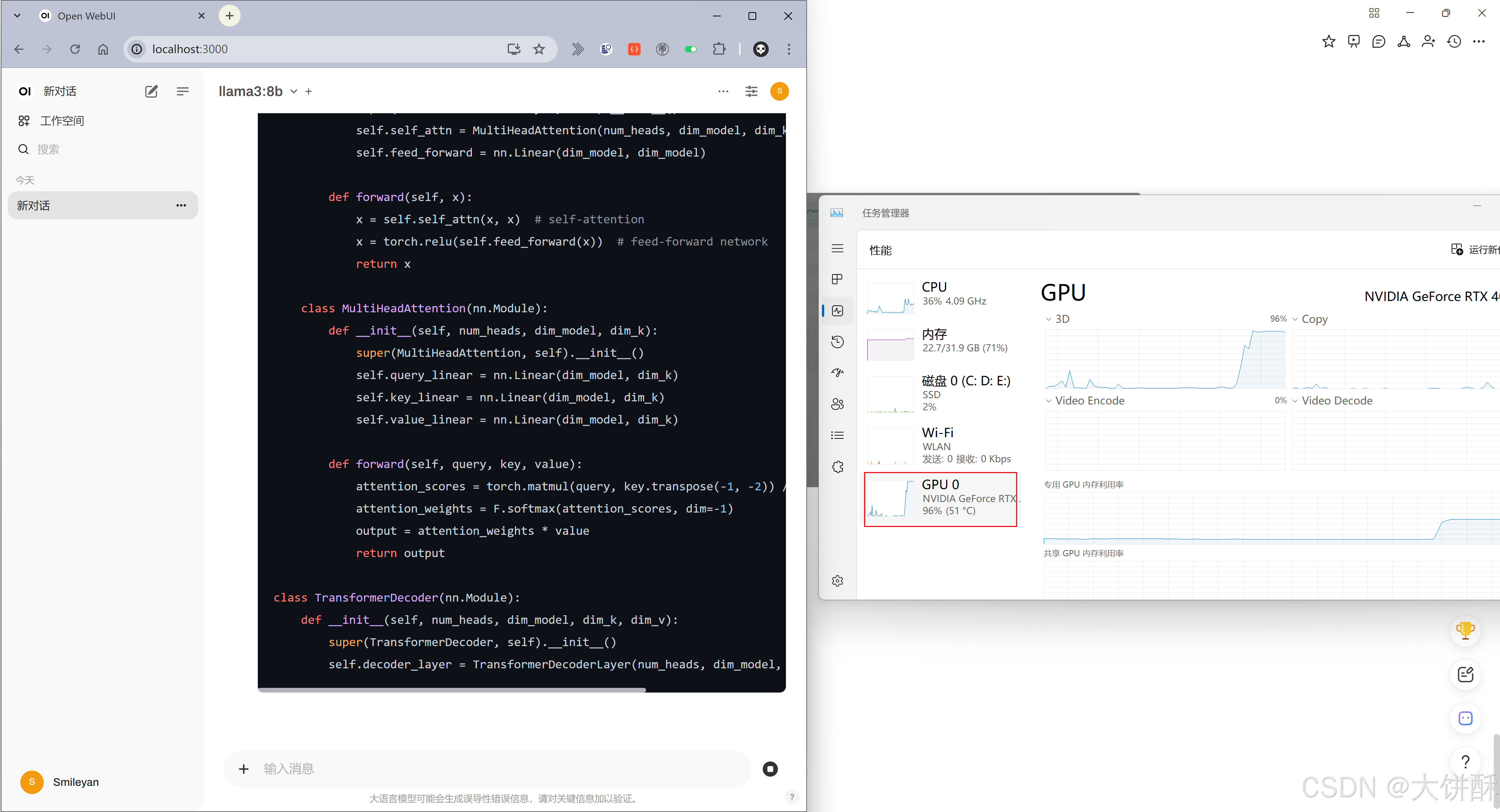
4、验证大模型推理是否使用GPU
在 open webui 中输入一个相对复杂的对话,让大模型推断时间久一些,然后同时观察 任务管理器窗口中 GPU 的变化情况。