目录
推荐方案一、Insert+xxxMergeTree+optimize
方案二、Insert+xxxMergeTree+argMax
一、问题背景
最近有一个项目需求,需要对日活跃的3万辆车的定位数据进行分析,并支持查询和统计分析结果。每辆车每天产生1条分析结果数据,要求能够查询过去一年内的所有分析结果。因此,每月需要处理约90万条记录,一年大约有1000万条记录。由于数据量庞大,同时还需要考虑数据权限关联,若采用传统关系型数据库进行查询,查询时间可能过长,甚至出现超时的情况。
二、解决方案
针对上述问题,我们选择使用Clickhouse数据库存储分析结果数据。Clickhouse以其高性能的查询能力,可以快速生成BI报表,并支持多维度、多指标的数据分析。由于一辆车每隔10到15秒秒会产生1条定位数据,3万辆车每小时将生成大约700万条数据,因此对这些数据的分析需要频繁更新数据库。然而Clickhouse的更新操作非常耗资源,频繁的更新可能会导致系统崩溃。
为了解决这一问题,我们将频繁更新的操作放入关系型数据库进行处理,并通过定时同步的方式将数据传输到Clickhouse。这样可以大幅降低Clickhouse的更新频率。尽管如此,由于Clickhouse的设计理念并不鼓励频繁更新,更新操作仍然是不可避免的。那么,如何在Clickhouse中实现数据更新,或者实现准实时更新呢?
三、准实时更新
ClickHouse的更新操作本身是低效的,因为它的MergeTree存储引擎一旦生成一个数据分区(Data Part),该分区无法直接修改。任何更新操作都需要删除旧的数据分区并重新写入新的数据分区。因此,从MergeTree的存储引擎设计上看,ClickHouse并不擅长进行数据的更新和删除。
推荐方案一、Insert+xxxMergeTree+optimize
1、Insert + xxxMergeTree
通过结合 Insert 操作和特定的MergeTree引擎(如 ReplacingMergeTree 或 CollapsingMergeTree),可以实现数据更新的效果。此方法适用于那些需要基于某些字段替换或折叠数据的场景,但需要注意的是,更新操作是异步的,刚插入的数据不能马上看到最新的结果,因此无法做到准实时。
例如,使用 ReplacingMergeTree 创建表:
create table gps_result_vehicle_day
(
`belong_time` String comment '数据归属时间,格式yyyy-MM-dd',
`belong_partition` String comment '数据归属分区',
`vehicle_plate` String comment '车牌,车牌号+车牌颜色',
`total_point_num` Int64 DEFAULT 0 comment '总点数',
`qualified_point_num` Int64 DEFAULT 0 comment '合格点数',
`qualified_rate` Decimal(10, 2) DEFAULT 0 comment '数据合格率,单位%',
`create_time` DateTime comment '创建时间',
`update_time` DateTime comment '更新时间'
)
engine = ReplacingMergeTree(update_time)
partition by belong_partition
primary key (belong_time, vehicle_plate)
order by (belong_time, vehicle_plate)
settings index_granularity = 8192使用 ReplacingMergeTree,因为它相比 CollapsingMergeTree 更加简单。CollapsingMergeTree 对数据的要求比较严格,不仅需要反位标记,而且需要保证正负标记号的个数对应。ReplacingMergeTree引擎,可以针对同分区内相同主键的数据进行去重,它能够在合并分区时删除重复的数据。
belong_partition 是分区字段,该字段存储数据归属的月份,表示数据是按月进行分区。
update_time 是版本号字段,每组数据中 update_time 最大的一行表示最新的数据采用。
belong_time+vehicle_plate 是联合主键,是数据去重更新的标识。
2、optimize final
为了确保数据合并的及时性,可以使用 optimize final 强制触发数据合并。ClickHouse的 MergeTree 引擎会自动合并数据,但合并过程的执行时间不确定,可能导致数据更新不完全,甚至可能延迟一天以上。为了解决这个问题,可以在写入数据后,使用 optimize final 强制进行数据合并。
optimize table {tableName} partition {partitionName} final;需要注意的是,optimize 操作会消耗较多资源,执行速度较慢,因此不宜频繁使用。
3、测试验证
3.1、写入 1000万 行测试数据
insert into table gps_result_vehicle_day(belong_time, belong_partition, vehicle_plate,
total_point_num, qualified_point_num, qualified_rate, create_time, update_time)
with(
select [10,20,30,40,50,60,70]
)as dict
select '2025-01-18' as belong_time, '2025-01' as belong_partition, number as vehicle_plate,
dict[number%7+1] as total_point_num, dict[number%7+1] as qualified_point_num,
100 as qualified_rate, now() as create_time, now() as update_time from numbers(10000000)3.2、修改前 100万 行数据
通过新增与前 100万 行主键一致的数据,实现数据的修改
insert into table gps_result_vehicle_day(belong_time, belong_partition, vehicle_plate,
total_point_num, qualified_point_num, qualified_rate, create_time, update_time)
with(
select [100,200,300,400,500,600,700]
)as dict
select '2025-01-18' as belong_time, '2025-01' as belong_partition, number as vehicle_plate,
dict[number%7+1] as total_point_num, dict[number%7+1] as qualified_point_num,
100 as qualified_rate, now() as create_time, now() as update_time from numbers(1000000)3.3、查看数据总数
由于还未触发分区合并,所以会发现有 100 万的重复数据
select count() from gps_result_vehicle_day;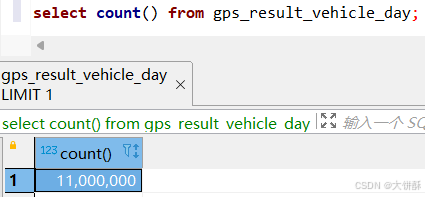
3.4、执行分区合并
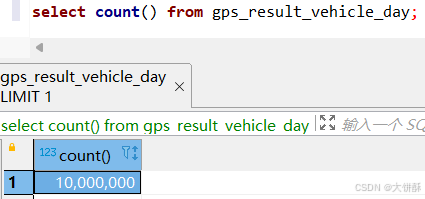
optimize table gps_result_vehicle_day partition '2025-01' final;3.5、再查看数据总数
由于已经执行了分区合并,发现前 100万 行数据已更新,总记录数变为1000万行
4、总结
这种更新方法通过巧妙的设计,能够在ClickHouse中实现准实时的数据更新,虽然更新并非即时完成,但能够有效地平衡性能与数据一致性的需求。
- 异步更新:通过
ReplacingMergeTree或CollapsingMergeTree实现数据的异步更新,虽然更新不是实时的,但可以保证数据一致性。- 数据合并:
optimize final命令可以强制触发数据合并,确保数据及时一致。- 性能考虑:由于
optimize操作代价较高,必须谨慎使用,避免频繁执行。
方案二、Insert+xxxMergeTree+argMax
argMax 函数的参数如下所示,它能够按照 field2 的最大值取 field1 的值。
argMax(field1,field2)当更新数据时,会写入一行新的数据,通过查询最大的 update_time 得到修改后的字段值,例如通过下面的语句可以得到最新的总点数。
argMax(total_point_num, update_time) as total_point_num1、测试验证
1.1、修改vehicle_plate=1的记录
insert into gps_result_vehicle_day(
belong_time, belong_partition, vehicle_plate,
total_point_num, qualified_point_num, qualified_rate,
create_time, update_time)
values ('2025-01-18', '2025-01', '1', 33, 33, 100, now(), now())1.2、查看验证是否被修改
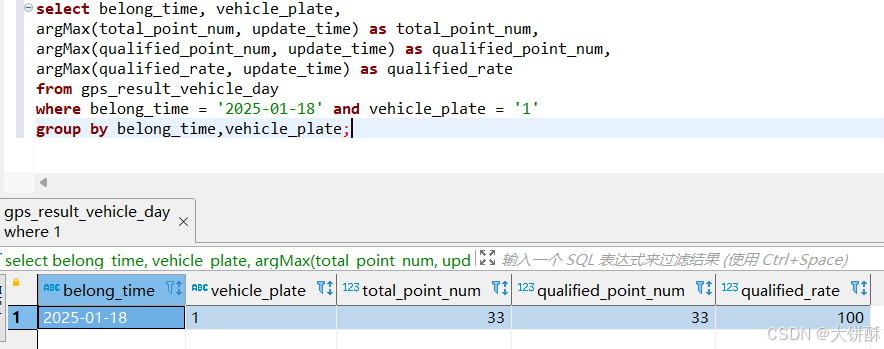
select belong_time, vehicle_plate,
argMax(total_point_num, update_time) as total_point_num,
argMax(qualified_point_num, update_time) as qualified_point_num,
argMax(qualified_rate, update_time) as qualified_rate
from gps_result_vehicle_day
where belong_time = '2025-01-18' and vehicle_plate = '1'
group by belong_time,vehicle_plate;可以发现数据被修改了
2、总结
ClickHouse 的 INSERT + MergeTree + argMax 方案在高吞吐量、实时数据更新场景中非常有效,但需要关注合并带来的性能开销和内存消耗。通过优化查询、表设计和合并策略,可以显著提升系统性能,确保满足实时性要求。
优点:
- 实时性高:每次插入操作都会实时更新数据,查询时能反映最新的数据状态。
- 数据去重与更新:使用
argMax函数可以确保返回某个维度下的最新记录,特别适用于去重和选择最新版本的情况。缺点:
- 查询复杂度高:为了确保数据更新和准确性,查询可能需要复杂的子查询和聚合逻辑,影响可读性与维护性。
- 内存消耗:数据合并和去重过程中需要消耗大量内存,可能影响系统的性能。