利用大模型的API时,我们可以配置一些参数来改进大模型的生成效果。比如temperature、top_p、max_tokens、stop、frequency_penalty、presence_penalty等。那么这些参数究竟具有什么意义呢?
今天我们仔细研究一下temperature这个参数的含义。
stream = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
messages=[
{
"role": "system", "content": "你是一个知识渊博的医生,有丰富的医学知识,请根据用户的问题给出答案"},
{
"role": "user", "content": "如何预防新冠肺炎?"}
],
temperature=0.7,
max_tokens=1024,
top_p=0.95,
frequency_penalty=0,
presence_penalty=0,
stream=False,
stop=["", "<|endofturn|>"]
)
以下是大型语言模型核心参数temperature的详细解析及具体示例,帮助理解它们如何影响生成结果:
Temperature参数用于调整语言模型生成文本的随机性。在生成结果时,模型并不是直接计算出生成的词,而是会计算出每个可能的下一个词的概率分布。如下图所示:
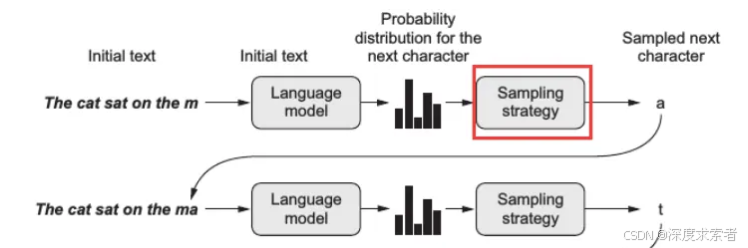
当你给模型输入一堆文本后,模型输出的是下一个token的输出概率,然后经过一个采样策略来确定最终要输出的东西。Temperature参数实际上是在抽样策略阶段,对这些概率进行调整,以控制生成文本的多样性和可预测性。Temperature参数通常为一个从0到2的值。
高temperature:增加生成文本的随机性,使得不太可能的词汇有更高的出现概率。这会导致生成的文本更加多样化和创造性,但同时也可能产生无意义或不连贯的文本。
低temperature:减少随机性,使得更可能的token出现概率更高。这样生成的文本更加可预测和连贯,但可能缺乏创造性和多样性。
- 创意写作:在需要创意和新颖性的写作任务中,如诗歌、故事创作等,可以使用较高的Temperature值来激发模型的创造性。
- 正式文档:在需要正式和准确信息的场合,如新闻报道、学术论文等,可以使用较低的Temperature值来确保生成文本的准确性和连贯性。
在技术实现上,Temperature参数通过对模型输出的概率分布进行缩放来起作用。具体来说,对于每个可能的下一个token,模型计算出一个原始概率分布,然后使用以下公式进行调整:

在这个公式中,Temperature代表Temperature参数,P(wi)是模型计算出的原始概率,log表示对数函数,exp表示指数函数。通过这种方式,Temperature值改变了原始概率分布的"平滑度"。
这里我们举个例子:
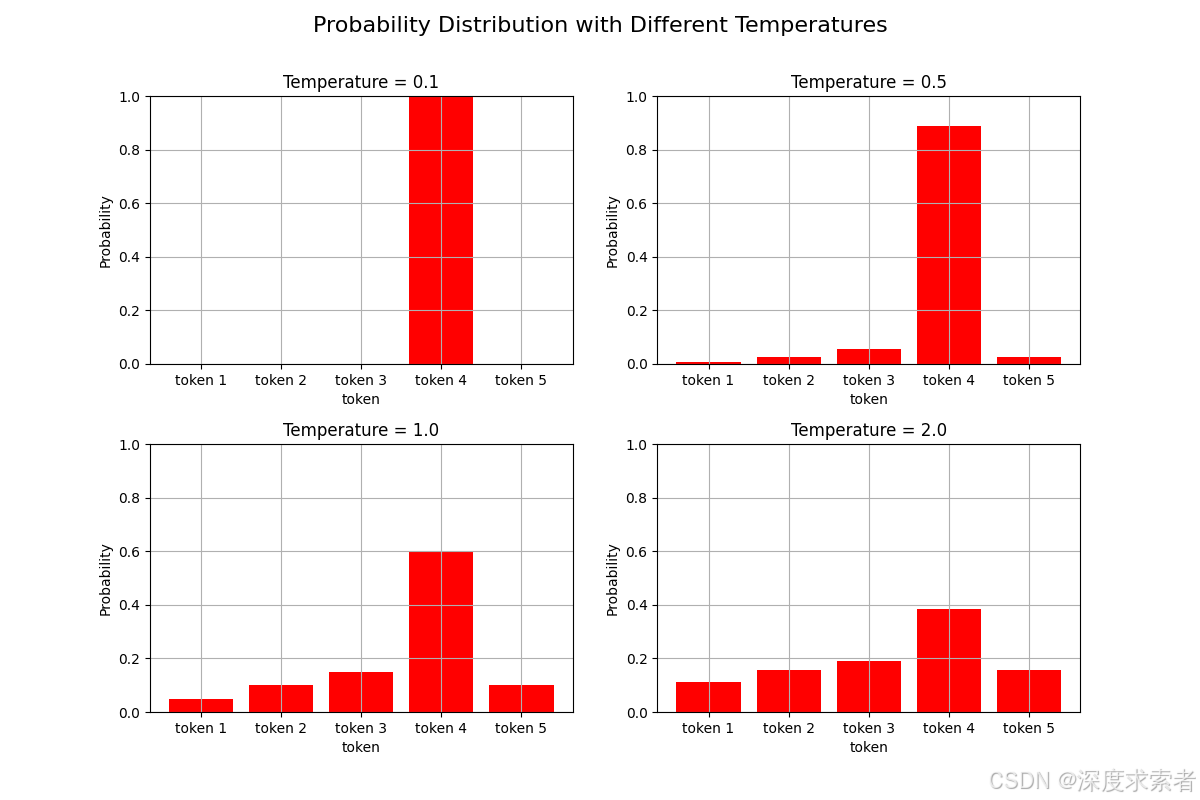
假设我们有5个token,分别为token1-token5,上图代表了这五个token在不同的Temperature参数下的输出概率。Temperature参数越小,那么概率值越集中,或者说它放大了具有较大概率值的token的概率,Temperature参数越大,概率值越平滑,或者说不同token之间的概率值差别越小。
因此,temperature 的值越小,模型返回的结果越确定,模型会返回具有最大概率的词。如果调高该参数值,大语言模型可能会返回更随机的结果。因为加大Temperature参数相当于加大其他可能的token的权重。
通过灵活调整这些参数,可以精细控制生成文本的多样性、准确性和流畅度。