今天,AI 领域再次上演了后浪拍前浪的一幕——英伟达开源推出 Llama Nemotron Ultra 253B 模型,将 Meta 刚发布三天的 Llama 4 踢下了神坛。
【图片来源于网络,侵删】
Nemotron Ultra 从 Llama 3.1 405B 中微调出来,可在多 GPU 数据中心服务器上实现最大的代理准确性。这款2530亿参数推理新王,不仅在数学推理、科学问答等硬核任务中刷新纪录,更以超大吞吐量,将行业天花板推向了新的高度。
而背后的核心技术,是英伟达祭出的测试时 Scaling 杀手锏。这是一种在推理时间内应用更多计算资源进行思考和推理的技术,能改善模型的响应质量,并提升模型在关键下游任务上的性能。
Nemotron 选择在推理阶段二次加码——通过动态分配计算资源,让模型像人类团队一样集思广益:先由多个子模块生成候选方案,再综合反馈迭代优化,最终输出高质量响应。
这种边推理边学习的模式,使得它在处理开放式复杂任务如科研创意、软件架构设计时,展现出接近人类协作的灵活性。
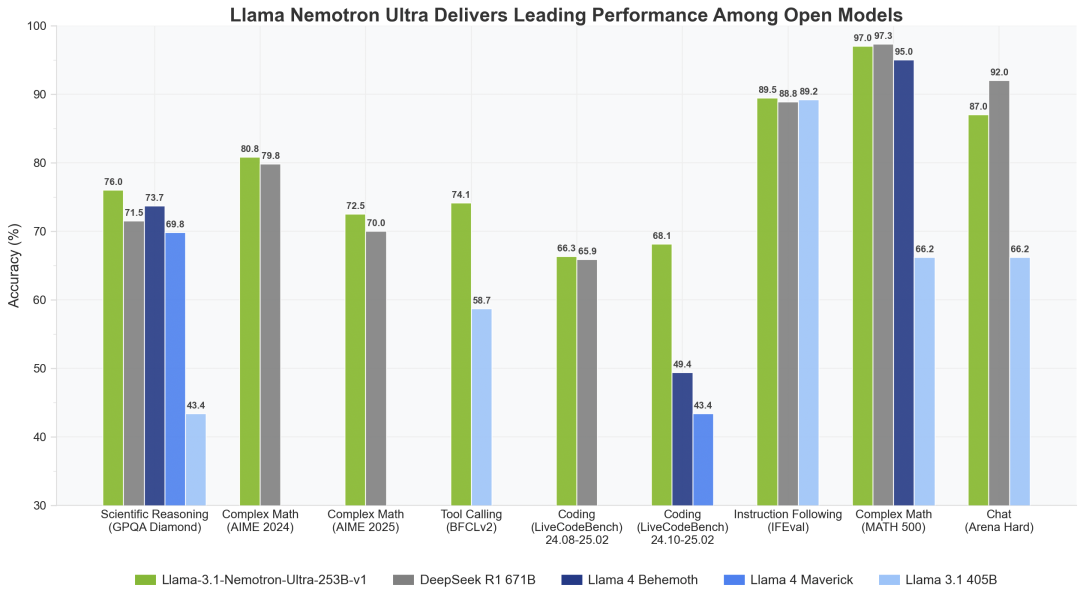
在性能方面,Llama Nemotron Ultra 在科学推理基准 GPQA 中以76分碾压了 Llama 4 的 71.5 分;并且仅用了 2530 亿参数,在多项基准测试中性能直逼 DeepSeek R1 这个 6710 亿参数巨兽。
【图片来源于网络,侵删】
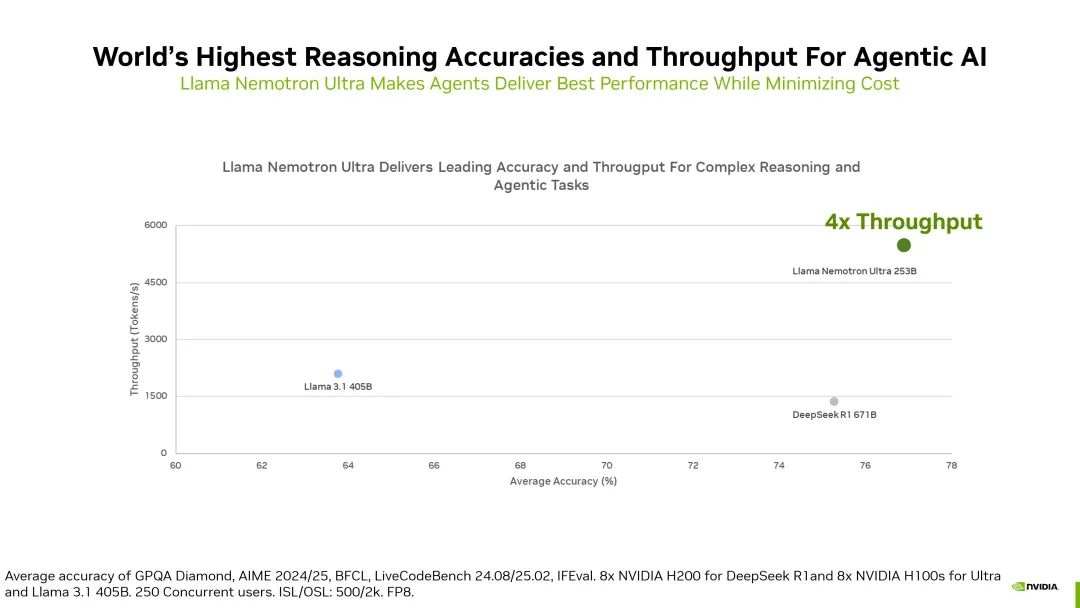
相比 DeepSeek R1 671B,它的推理吞吐量提升了 4 倍。
【图片来源于网络,侵删】
不过,DeepSeek-R1 仍在数学题 MATH500 和 Arena Hard 基准测试中守住了阵地,略占优势。
Llama Nemotron 系列共有三种尺寸:Nano、Super 和 Ultra,它们共同组成了模型全家桶,分别用于不同场景和计算资源需求。
Nano 版(8B)专为边缘设备打造,让家用PC也能流畅运行智能客服;Super 版(49B)则可以优化数据中心吞吐量,成为企业级RAG应用的性价比之选;Ultra 版(253B)则在药物研发、自动驾驶等场景中协调多智能体攻克复杂任务。
英伟达的软硬协同战略
值得一提的是,该模型的代码已在 Hugging Face 平台上公开,包含开放的权重和训练后数据。英伟达此次将模型全家桶开源商用,无异于向行业投下一枚生态核弹。

这意味着开发者可自由切换推理模式与常规模式,仅凭一行提示词便能让同一模型在严谨的数学推导与开放的创意生成间无缝切换。这种双模态设计,既降低了企业部署成本,又为学术研究提供了绝佳试验场。
而结合下半年即将量产的 Blackwell Ultra 芯片,英伟达的软硬协同战略已清晰浮现:用开源模型圈地生态,凭自研硬件收割算力红利。
当然,由于模型对 H100/B100 芯片的强依赖,中小开发者可能会被挡在门外。但无论如何,Nemotron的横空出世,已为推理技术写下新注脚:未来的AI竞赛,不再是参数的军备之战,而是效率、协同与生态的全面较量。算家云—AI算力服务平台
大家怎么看?欢迎在评论区留言分享你的感受~