2025年3月13日,由何凯明和Yann LeCun领衔的论文Transformers without Normalization挂载Arxiv上,大佬论文必须读一下。本文就该论文进行一个简单总结。

1.论文解读
这份研究论文挑战了深度神经网络中标准化层(如 Layer Norm)的必要性。作者提出了一种名为 Dynamic Tanh (DyT) 的简单元素操作,可以有效地替代 Transformer 架构中的标准化层,并取得与标准化模型相当甚至更好的性能。
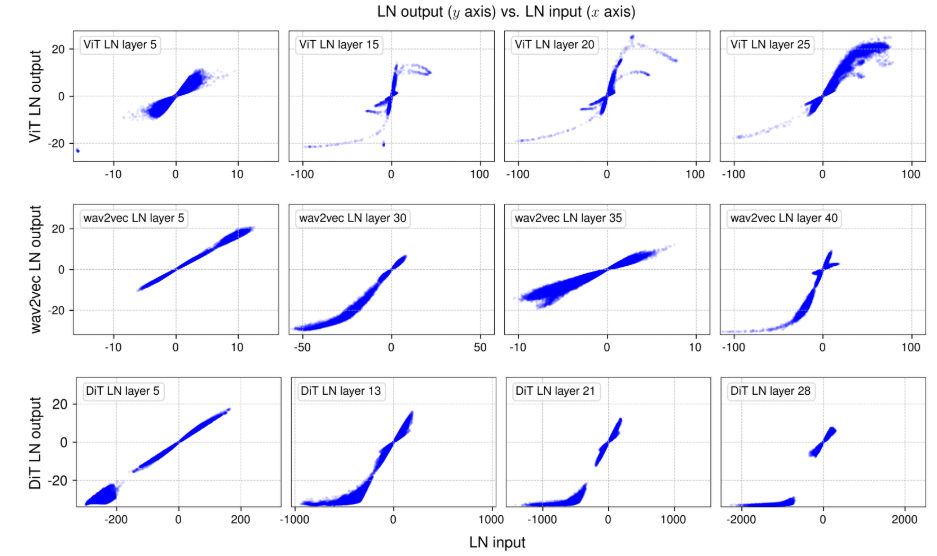
作者通过分析发现,标准化层(如 Layer Norm)的输出与 tanh 函数的 S 形曲线相似,即对输入进行缩放并压缩极端值。论文中的图2说明标准化层并非简单的线性变换,而是会对输入数据进行非线性压缩,特别是对极端值进行压缩。这种非线性压缩效果可能是标准化层对深度神经网络训练至关重要的原因之一。在模型的前几层 LN 层,输入输出关系接近直线,这是因为输入数据的范围较小,经过 LN 层处理后,变化幅度也较小。随着模型层数的增加,输入数据的范围变大,经过 LN 层处理后,极端值被压缩,使得输入输出关系更接近 S 形曲线。
作者提出的操作定义为 : D y T ( x ) = γ ∗ t a n h ( α x ) + β \mathrm{DyT}(x)=\gamma*\mathrm{tanh}(\alpha x)+\beta DyT(x)=γ∗tanh(αx)+β
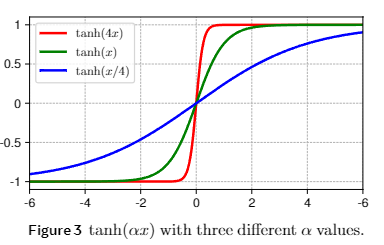
其中 α \alpha α 是一个可学习标量参数, γ \gamma γ和 β \beta β是同维度的矢量。 D y T \mathrm{DyT} DyT 通过学习合适的缩放因子 α \alpha α 来模拟标准化层的缩放效果,并通过 t a n h \mathrm{tanh} tanh 函数压缩极端值。不同 α \alpha α取值的函数图像如图3:
作者在多个任务和架构上进行了实验,包括视觉识别、语言模型、自监督学习等,结果表明 D y T \mathrm{DyT} DyT可以有效地替代标准化层,并取得与标准化模型相当甚至更好的性能。
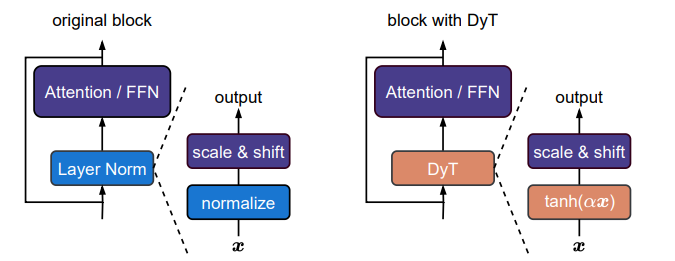
替换方式在论文图1中直接给出,比较直观。
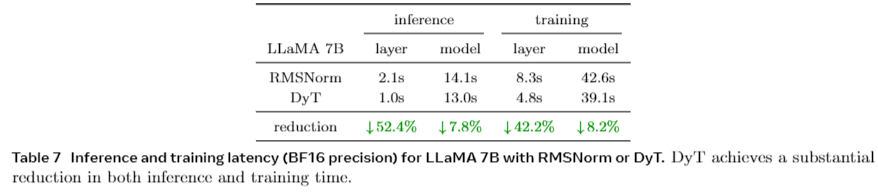
由论文中的表7,可以看出这种替换的最大优势是与标准化层相比,**在性能近似或更好的情况下, D y T \mathrm{DyT} DyT 的计算效率更高,可以加快训练和推理速度。**这也是作者提出这一改进的最大用途。
在论文第6部分,作者进行了消融分析,分析了如下三方面的情况:
- DyT 的效率: 通过对 LLaMA 7B 模型的基准测试,发现 DyT 层相比 RMSNorm 层可以显著减少计算时间,在推理和训练过程中都更加高效。
- **tanh 函数和$ \alpha 参数的作用 ∗ ∗ : t a n h 函数在防止训练发散和提高模型性能方面的重要性。同时, 参数的作用**: tanh 函数在防止训练发散和提高模型性能方面的重要性。同时, 参数的作用∗∗:tanh函数在防止训练发散和提高模型性能方面的重要性。同时, \alpha$ 参数的可学习性对于模型性能至关重要,去除$ \alpha$ 参数会导致性能下降。
- **$ \alpha 参数的值 ∗ ∗ :从 参数的值**: 从 参数的值∗∗:从 \alpha 参数在训练过程中的变化趋势,发现 参数在训练过程中的变化趋势,发现 参数在训练过程中的变化趋势,发现 \alpha$ 参数与输入激活值的标准差密切相关,$ \alpha$ 参数可以起到部分归一化的作用。此外,在训练完成后,$ \alpha$ 参数的值与输入激活值的标准差也呈现正相关关系。
在论文第7部分,作者给出了$ \alpha$的初始值建议:
- 非大型语言模型 (LLM) 对 α \alpha α的初始化不敏感: 在非 LLM 任务中, α \alpha α 的初始值对模型性能影响较小, α \alpha α 的取值范围较广,通常在 0.5 到 1.2 之间都能取得良好的结果。 α \alpha α的初始值设置为 0.5 通常可以获得良好的性能和训练稳定性。
- LLM 对 α \alpha α的初始化敏感: 在 LLM 训练中,调整 α \alpha α的初始值可以显著提高模型性能。较大的模型需要更小的 α \alpha α 初始值,并且在注意力模块中使用较大的 α \alpha α初始值可以提高性能。
- 模型宽度对 α \alpha α初始值的影响: 模型宽度对 α \alpha α初始值的选择影响较大,模型宽度越大,需要的 α \alpha α初始值越小。模型深度对 α \alpha α初始值的影响较小。
在论文最后,作者提到DyT 可能无法直接替代 Batch Normalization (BN)。初步实验表明,DyT 在直接替代经典卷积神经网络(如 ResNet)中的 BN 层时,会导致性能下降。因此未来的研究方向是研究 DyT 是否可以有效地替代其他类型的标准化层,例如 Instance Normalization 和 Group Normalization以及探索更复杂的 DyT 设计,使其能够更好地适应不同类型的网络和任务。
2.DyT代码实现
class DynamicTanh(nn.Module):
# 初始化函数,定义模块参数和可学习参数
def __init__(self, normalized_shape, channels_last, alpha_init_value=0.5):
super().__init__()
# 保存输入张量的目标规范化形状(如通道数C)
self.normalized_shape = normalized_shape
# 保存alpha参数的初始值,用于控制Tanh的缩放程度
self.alpha_init_value = alpha_init_value
# 布尔值标记是否通道维度在最后(如NHWC格式时为True)
self.channels_last = channels_last
# 定义可学习的缩放参数alpha,初始化为指定值的标量(通过torch.ones(1)创建)
# 论文中建议非LLM设置为0.5
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value)
# 定义可学习的权重参数,论文中的gamma,形状与规范化形状一致(如通道数C),初始化为全1
self.weight = nn.Parameter(torch.ones(normalized_shape))
# 定义可学习的偏置参数,形状与规范化形状一致(如通道数C),初始化为全0
self.bias = nn.Parameter(torch.zeros(normalized_shape))
# 前向传播函数,定义数据处理流程
def forward(self, x):
# 对输入x进行缩放后应用Tanh激活:alpha*x -> tanh(alpha*x)
x = torch.tanh(self.alpha * x)
# 根据通道顺序标记选择不同的维度处理方式
if self.channels_last:
# 当通道在最后时(如NHWC),直接进行逐通道的缩放和偏置
x = x * self.weight + self.bias
else:
# 当通道在中间时(如NCHW),通过增加两个维度适配空间维度(H,W)
# 使用[:, None, None]将权重从(C,)扩展为(C,1,1)以匹配输入维度
# 广播实现按通道(C维度)的逐元素乘法,保持H/W维度不变
x = x * self.weight[:, None, None] + self.bias[:, None, None]
return x # 返回处理后的张量
# 打印模块信息时显示额外参数的函数
def extra_repr(self):
# 返回包含关键参数的格式化字符串,用于模块信息展示
return f"normalized_shape={
self.normalized_shape}, alpha_init_value={
self.alpha_init_value}, channels_last={
self.channels_last}"