Python基于WordCloud词云图的数据可视化分析 词云图的基本使用 政府工作报告分析
文章目录
1、词云图简介
词云图,也叫文字云,是对文本数据中出现频率较高的“关键词”在视觉上予以突出,形成“关键词的渲染”,类似于云一样的彩色图片,会过滤掉大量的低频低质的文本信息,使人一眼就可以看出文本数据的主要表达意思。
2、wordcloud库的安装
首先在命令行中使用 pip install wordcloud看是否能安装成功
如果使用命令行的方式安装失败,则可以使用以下的方式安装
- 首先打开网站
https://www.lfd.uci.edu/~gohlke/pythonlibs/
-
ctrl+f查找包名
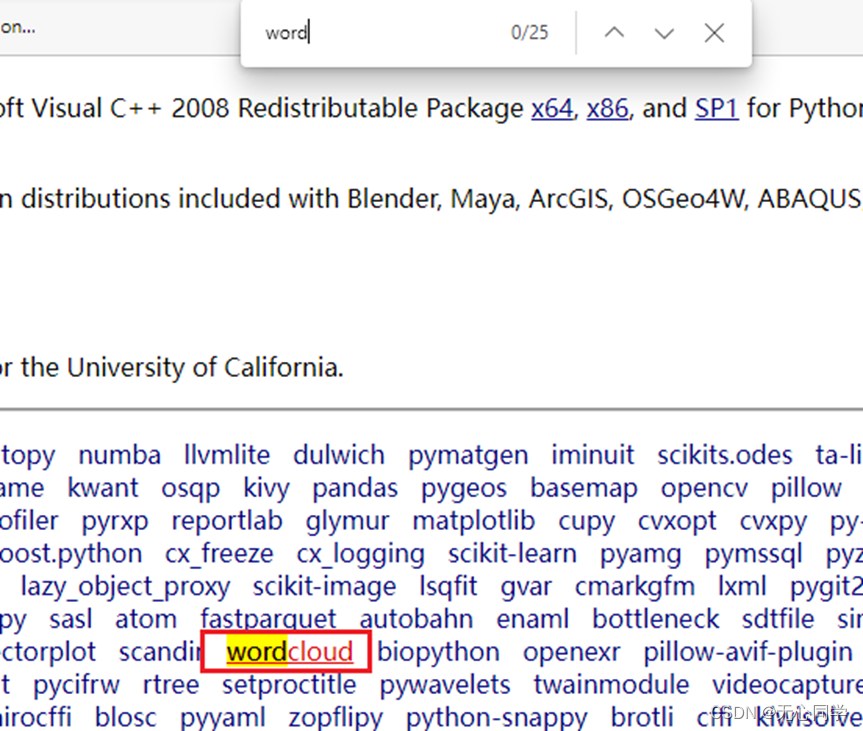
-
下载对应的python版本的文件

-
在对应目录下,输入命令pip install 下载的包文件名
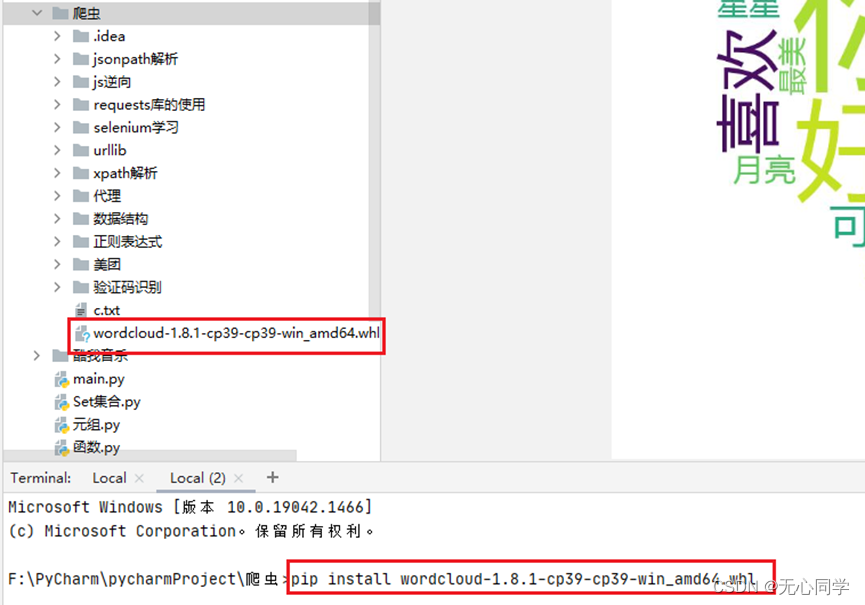
这样就安装成功了!
3、WordCloud的主要参数说明
| 参数名 | 解释 |
|---|---|
| background_color | 输出的背景颜色 |
| mask | array形式的轮廓图片,如果参数为空,则使用二维遮罩绘制词云 |
| font_path | 字体路径 |
| max_words | 词云图的最大词语数量 |
| stopwords | 停用词列表 |
| font_step | 字体字号的步进间隔,默认是1 |
4、绘制词云图
接下来,我们对这个政府工作报告做一个词云图分析

1、获取并处理文本信息
from matplotlib import pyplot as plt
import jieba
import wordcloud as wc
from PIL import Image
import numpy as np
# 获取文本内容
word = open('../first_work/assets/aaa.txt', 'r', encoding='utf-8').read()
# 用结巴分词后,用空格隔开,因为词云以空格为分隔符
word = ' '.join(jieba.cut(word,cut_all=False))
2、将白底的轮廓图片转换成array形式
# 注意图片得是白底的
img_arr = np.array(Image.open('LOVE.jpg')) # 将图片转换成数组形式

3、生成词云并保存成文件
cloud = wc.WordCloud(
background_color='white', # 输出白色背景
mask=img_arr, # 数组格式的img,定义轮廓
font_path='../first_work/assets/微软雅黑.ttf',
width=800,
height=800,
max_words=200, # 词云图的最大词语数量
stopwords=[], # 被排除词的列表
font_step=1 # 字体字号的步进间隔,默认是1
)
# 根据字符串文本,使用generate方法生成词云
cloud.generate(word)
# 通过matplotlib将词云展示出来
plt.imshow(cloud.to_image())
plt.axis('off') # 去除坐标轴
# plt.savefig('wordcloud.jpg') # 必须在show方法执行前调用!!!
plt.show()
# 将词云保存成jpg格式文件
cloud.to_file('wordcloud.jpg')
最终效果图如下:

以上就是本次代码分享,觉得不错的朋友可以点个赞关注一下!