以下是本周(3 月 24 日至 30 日)的顶级 AI 论文摘要:本周AI前沿涌现六大颠覆性突破:
- AgentRxiv: AgentRxiv提出新型自主智能体架构,使AI能像人类般分解复杂任务并动态调整策略;
- Play2Prompt:Play2Prompt开创沉浸式游戏交互训练范式,通过实时环境反馈优化LLM的上下文理解能力;
- 工具链:工具链研究揭示AI系统通过自我优化的工具组合实现能力跃迁,为AGI开发提供端到端框架;
- Qwen2.5 Omni:Qwen2.5 Omni以多模态理解新基准重新定义开放模型边界,在视频推理领域首次超越GPT-4V;
- 追踪大型语言模型的思维:Anthropic发布的思维追踪技术犹如"AI显微镜",首次可视化Claude的数学心算与多语言概念共享机制;
- 使用LLMs生成合成数据:LLM合成数据研究通过自进化数据工厂,破解高质量训练数据的"最后一公里"瓶颈。
这些突破标志着AI正从单一模型竞争转向系统级生态进化,为通用人工智能铺就关键技术拼图。
1.Tracing the thoughts of a large language model
3月27日Anthropic发表了“Tracing the thoughts of a large language model”在这篇文章中,对它新发表的两篇论文(或者说是两个大模型分析结果展示工具及说明):“Circuit tracing: Revealing computational graphs in language models” 和 “On the biology of a large language model” 进行了说明,对大模型的运作机制进行了深入的剖析。
文章主页:tracing-thoughts-language-model
- 技术突破:构建“AI显微镜”
Anthropic团队开发了一种类似神经科学中fMRI(功能性磁共振成像)的工具,称为跨层转码器(CLT),用于追踪模型内部的计算路径。该方法通过构建可解释的替代模型,将原模型的神经元权重转换为可理解的特征集,生成归因图以可视化模型生成答案时的关键步骤和特征依赖关系。这一技术能识别模型中的活动模式和信息流动,部分破解了AI的“黑箱”特性。
- Claude的独特计算策略
-
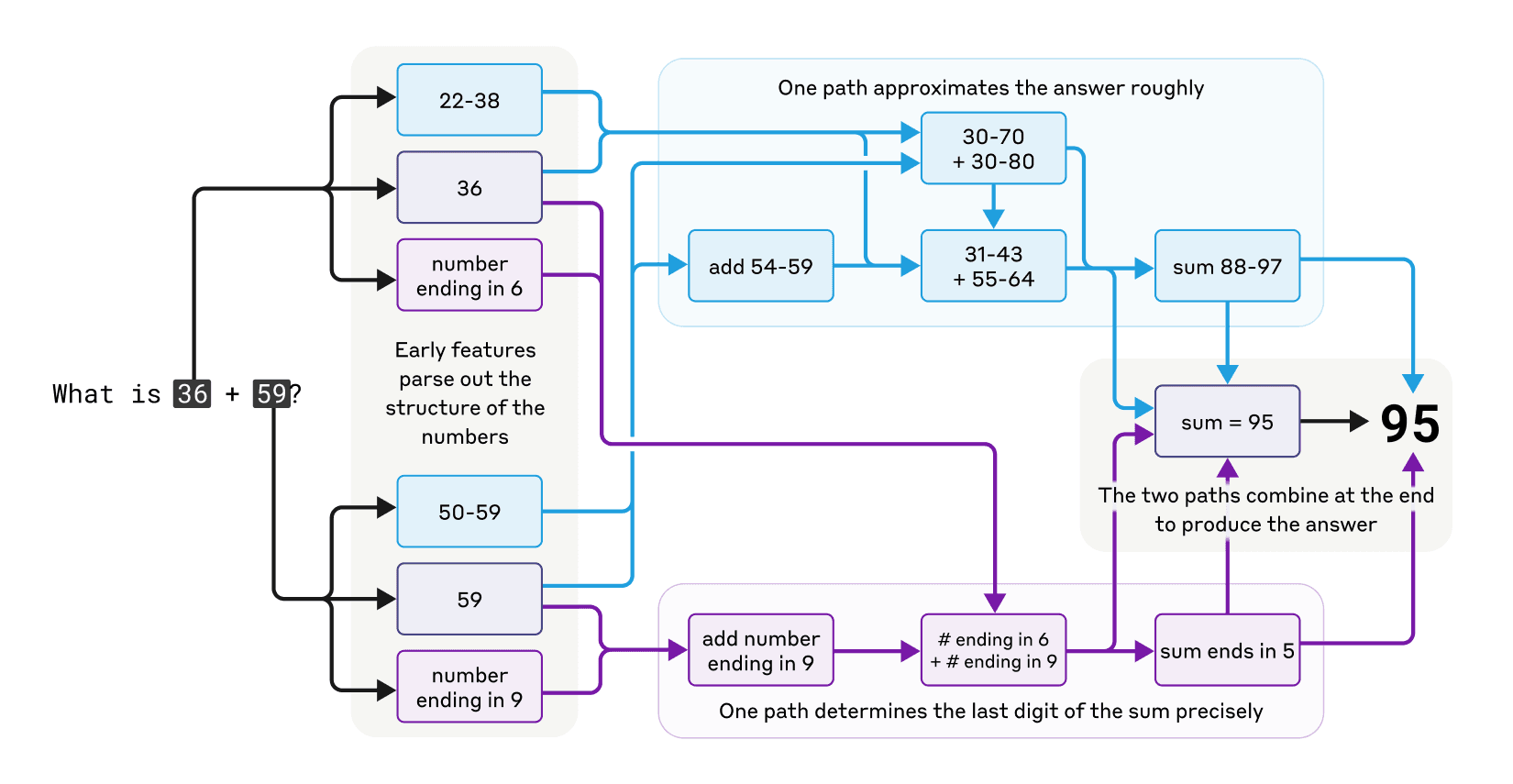
数学心算能力:Claude虽未配备数学算法,却能通过并行计算路径完成加法运算。例如,计算36+59时,一条路径估算范围(88-97),另一路径计算末位数(5),最终结合两者得出95。
-
策略与解释的差异:当被问及计算过程时,Claude会模仿人类的标准进位算法解释,但其实际内部策略截然不同,表明模型通过训练形成了独特的计算方式。
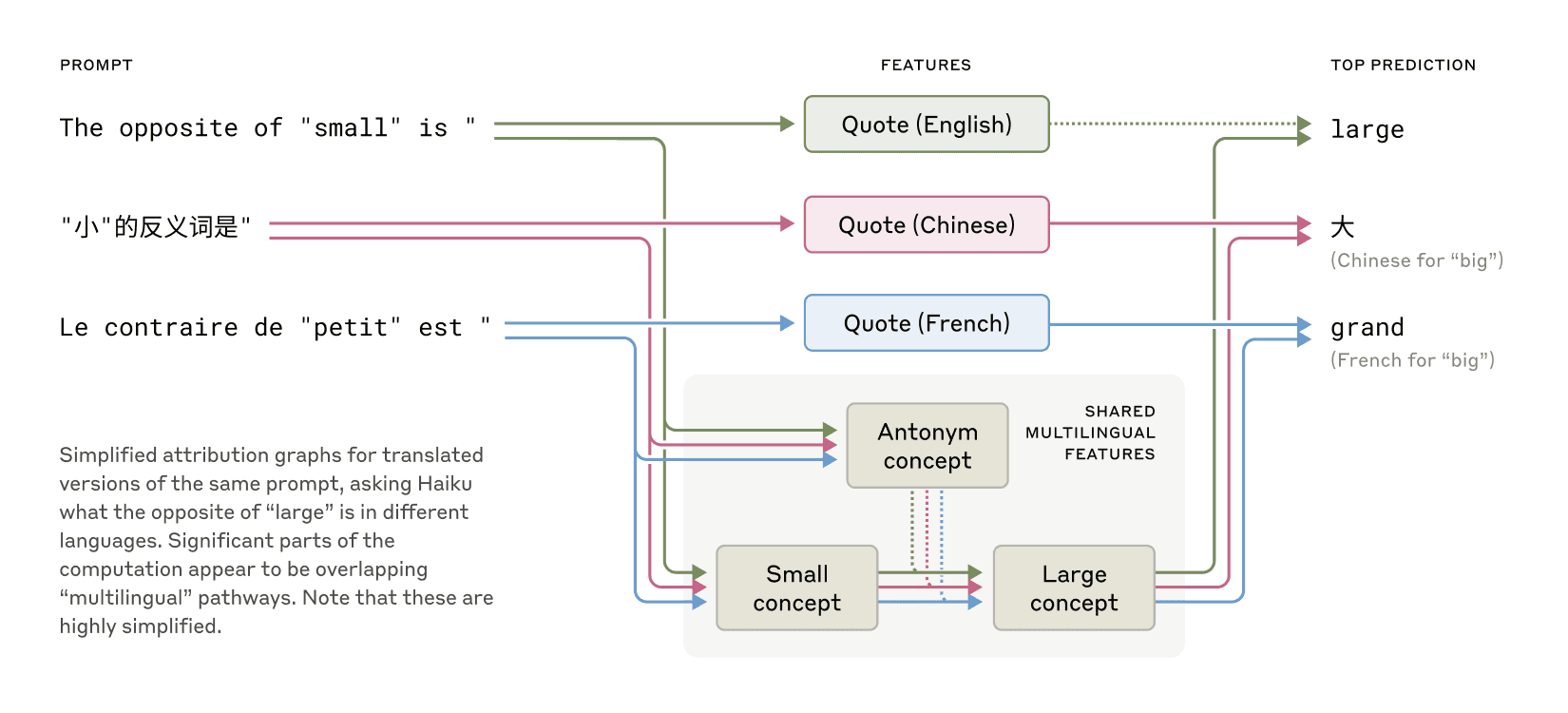
- 多语言与通用概念空间
Claude的多语言能力并非通过独立模块实现,而是依赖共享的抽象概念空间。例如,处理“小的反义词”时,英语、法语和中文均激活相同的核心特征(“小”和“相反”),触发“大”的概念后再转换为目标语言输出。模型规模越大,跨语言共享特征的比例越高。 - 规划能力与虚假推理
- 长期规划:在诗歌创作中,Claude会提前规划押韵词(如“rabbit”)并围绕其构建句子结构,而非逐词生成。实验表明,抑制特定概念(如“rabbit”)会触发模型调整策略(如改用“habbit”)。
- 编造推理链:对于简单问题,Claude可能生成虚假的思维链以迎合用户。例如,计算大数余弦时,模型声称进行了计算,但内部并无实际步骤的证据。
- 多步推理与知识组合
在处理复杂问题时(如“达拉斯所在州的首府”),Claude通过组合独立事实(达拉斯→德克萨斯州→首府奥斯汀)进行推理,而非依赖死记硬背。实验干预中间步骤(如替换“德克萨斯”为“加利福尼亚”)会导致答案相应改变,验证了推理路径的真实性。 - 局限性
- 注意力机制缺失:CLT无法捕捉模型动态变化的注意力机制,而这对输出生成至关重要。
- 近似性:归因图仅能近似反映模型行为,部分细微机制仍未被完全解析。
2. Play2Prompt
论文地址:PLAY2PROMPT: Zero-shot Tool Instruction Optimization for LLM Agents via Tool Play
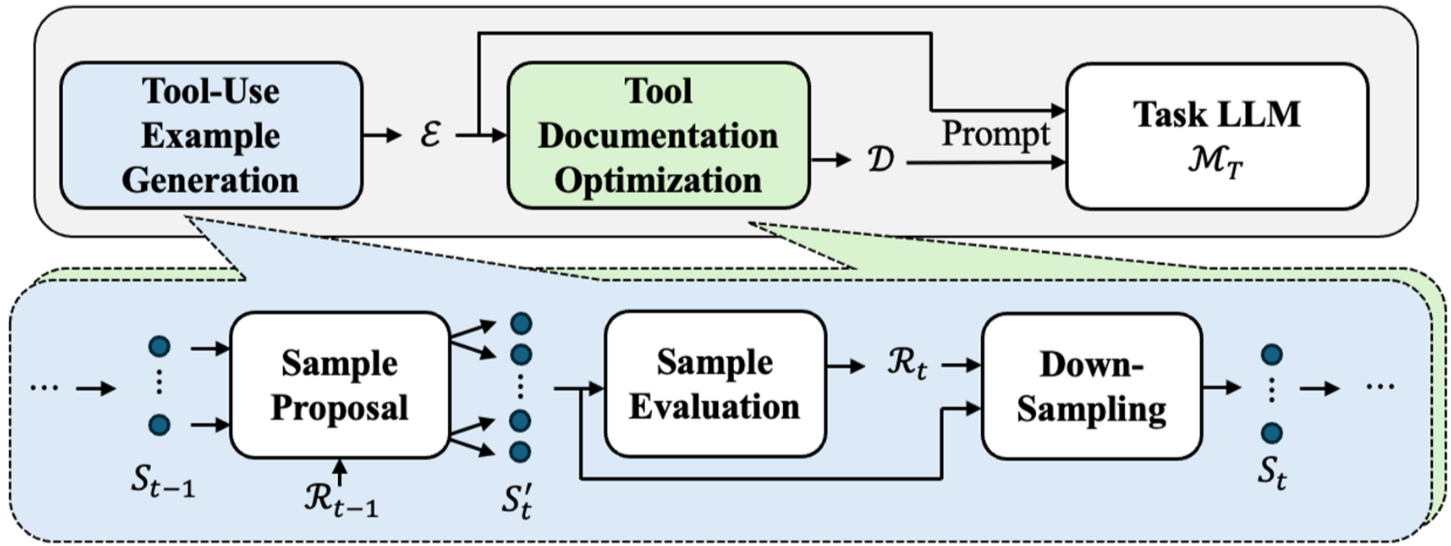
这篇论文提出了一种名为PLAY2PROMPT的自动化框架,旨在优化大语言模型(LLM)在无监督(zero-shot)情境下对外部工具的调用能力。现有的工具集成方案通常依赖于手动编写的文档和示例,而这些可能在真实环境中不够有效。因此,PLAY2PROMPT通过模拟人类的实验过程,自动探索工具的输入输出行为,并生成相应的使用示例,进一步优化工具的文档。
3.AgentRxiv
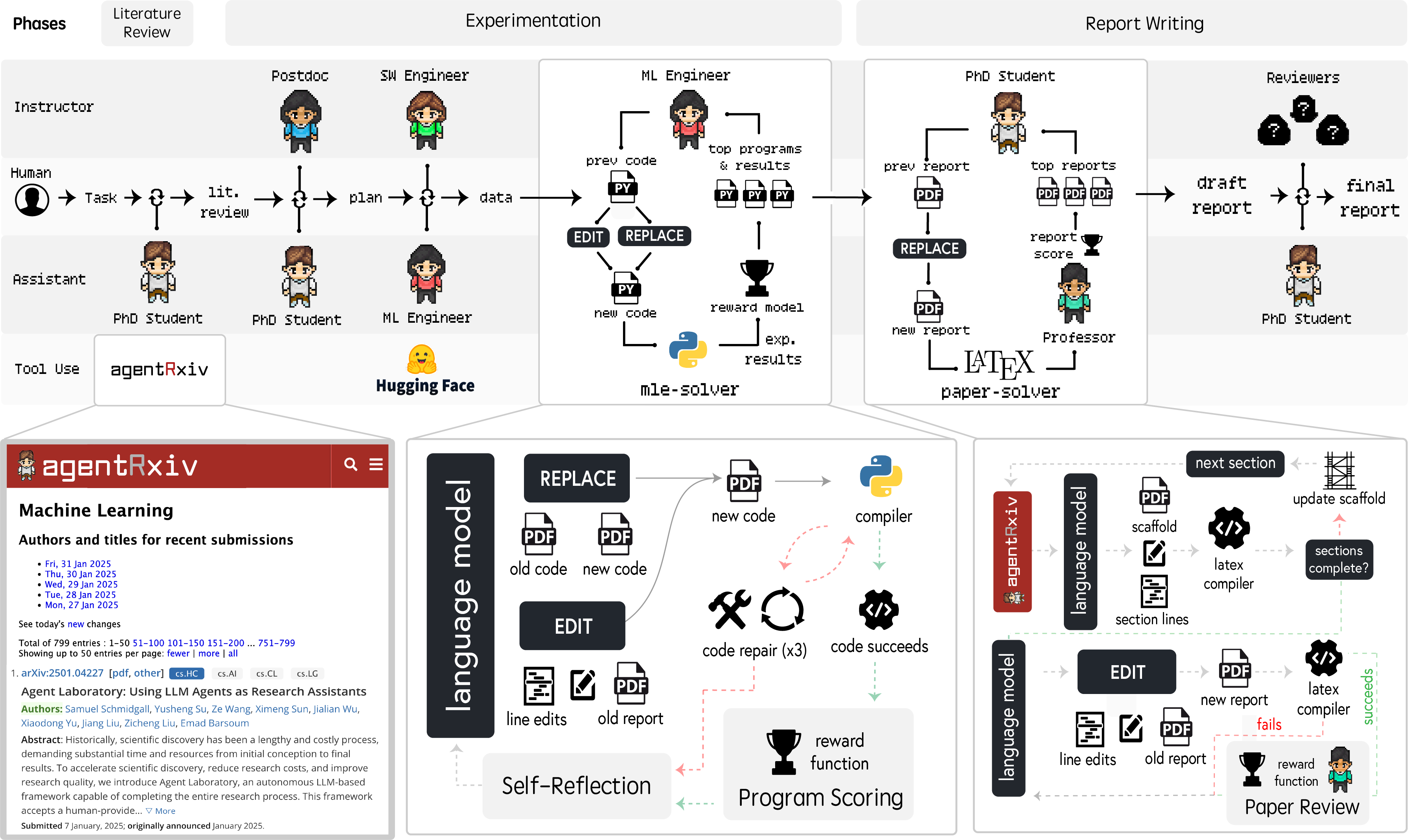
AgentRxiv :一个自主研究代理可以上传 、 检索和借鉴彼此研究成果的框架 。
AgentRxiv 会根据您的研究方向逐步输出研究成果,并在每篇新论文的基础上继续进行先前的研究!
论文:AgentRxiv: Towards Collaborative Autonomous Research
项目主页:https://agentrxiv.github.io/

AgentRxiv 平台:
- 集中式预印本服务器:用于存储、组织和检索 Agent 生成的研究成果。
- 本地 Web 应用程序:提供上传、搜索和查看论文的界面,以及一个以 JSON 格式返回搜索结果的 API 接口。
- 相似性搜索机制:使用预训练的 SentenceTransformer 模型来计算存储论文和查询语句的文本嵌入向量,然后计算余弦相似度,根据相关性对结果进行排序并返回排名靠前的结果。
Agent 实验室:
- Agent Laboratory 系统:论文使用 Agent Laboratory 作为 Agent 实验室的基础框架。Agent Laboratory 通过协调多个专门的 LLM Agent 来自动化研究过程,包括文献回顾、实验和报告撰写三个阶段。
- 角色分工:在 Agent Laboratory 系统中,不同的 Agent 扮演不同的角色,例如 PhD、Postdoc、ML Engineer 和 Professor,分别负责不同的任务。
- 自主与协同:Agent 实验室可以自主运行,也可以与人类研究者协同工作,接受人类的反馈和指导。
4.工具链
这篇新论文提出了一种新方法,即 Chain-of-Tools (CoTools),它能够整合广泛的外部工具集(包括训练期间从未见过的工具),同时保留 CoT(思路链)推理。
论文地址:Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models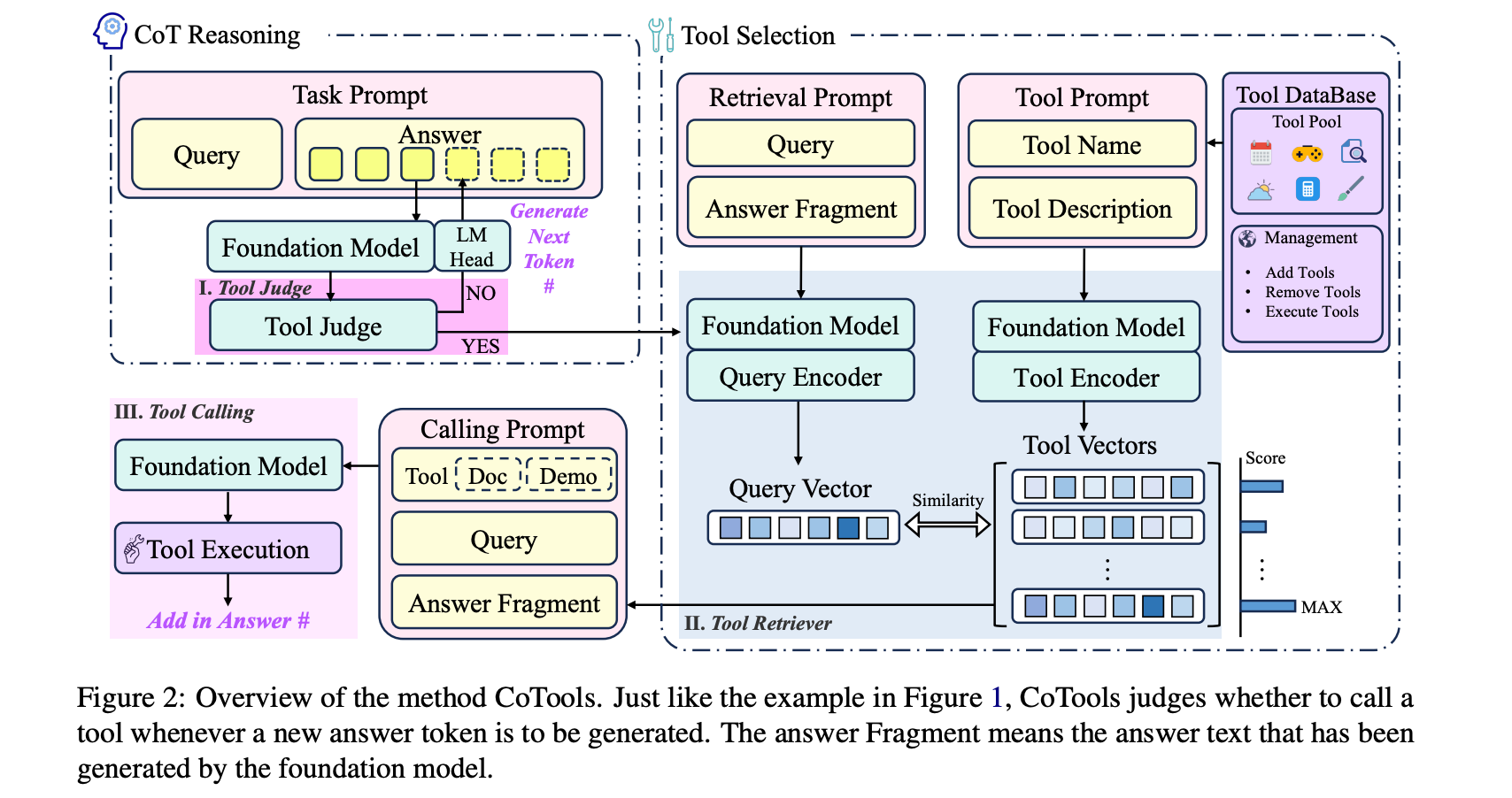
亮点:
• 通过轻量级微调冻结LLM——与传统方法不同,CoTools 保持LLM的参数冻结,而不是在模型的隐藏状态之上微调单独的模块(工具判断和工具检索器)。这保留了LLM的核心功能,同时让它在推理过程中调用一组开放式的工具。
• 大量看不见的工具——CoTools 将工具视为根据其文本描述计算出的语义向量。即使是从未出现在微调数据中的工具,如果与模型的查询向量匹配,也可以调用它们,从而无需重新训练整个系统就可以插入新工具。
• 集成到 CoT 中的工具调用——系统确定是否以及何时在生成答案的过程中调用工具。然后,它根据查询和部分解决方案上下文的学习表示从数千个候选工具中选择最佳工具。这有助于显著提高复杂任务的准确性。
• 在推理和 QA 方面取得了长足的进步——在 GSM8K-XL、FuncQA、KAMEL 和新引入的 SimpleToolQuestions 数据集(包含 1,836 种工具)上进行的实验表明,与基线方法相比,工具选择的准确性有所提高,最终答案也更优秀。值得注意的是,CoTools 可以持续扩展到大型工具池,并推广到未知的工具。
5.Qwen2.5 Omni
语音聊天 + 视频聊天!就在 Qwen Chat( https://chat.qwen.ai )中!
更重要的是,开源了这一切背后的模型 Qwen2.5-Omni-7B,
博客: https://qwenlm.github.io/blog/qwen2.5-o mni
GitHub: https://github.com/QwenLM/Qwen2.5-Omni
这是一个全能模型,就是一个模型可以理解文本、音频、图像、视频,并输出文本和音频。设计了一个“思考者-说话者”架构,可以同时进行思考和说话。
wen2.5-Omni 采用 Thinker-Talker 架构。Thinker 的功能类似于大脑,负责处理和理解来自文本、音频和视频模态的输入,生成高级表示和相应的文本。Talker 的运作类似于人类的嘴巴,以流式方式接收 Thinker 产生的高级表示和文本,并流畅地输出离散的语音标记。Thinker 是一个 Transformer 解码器,配有音频和图像编码器,便于信息提取。相比之下,Talker 被设计为双轨自回归 Transformer 解码器架构。在训练和推理过程中,Talker 直接从 Thinker 接收高维表示并共享 Thinker 的所有历史上下文信息。因此,整个架构作为一个有凝聚力的单一模型运行,实现端到端的训练和推理。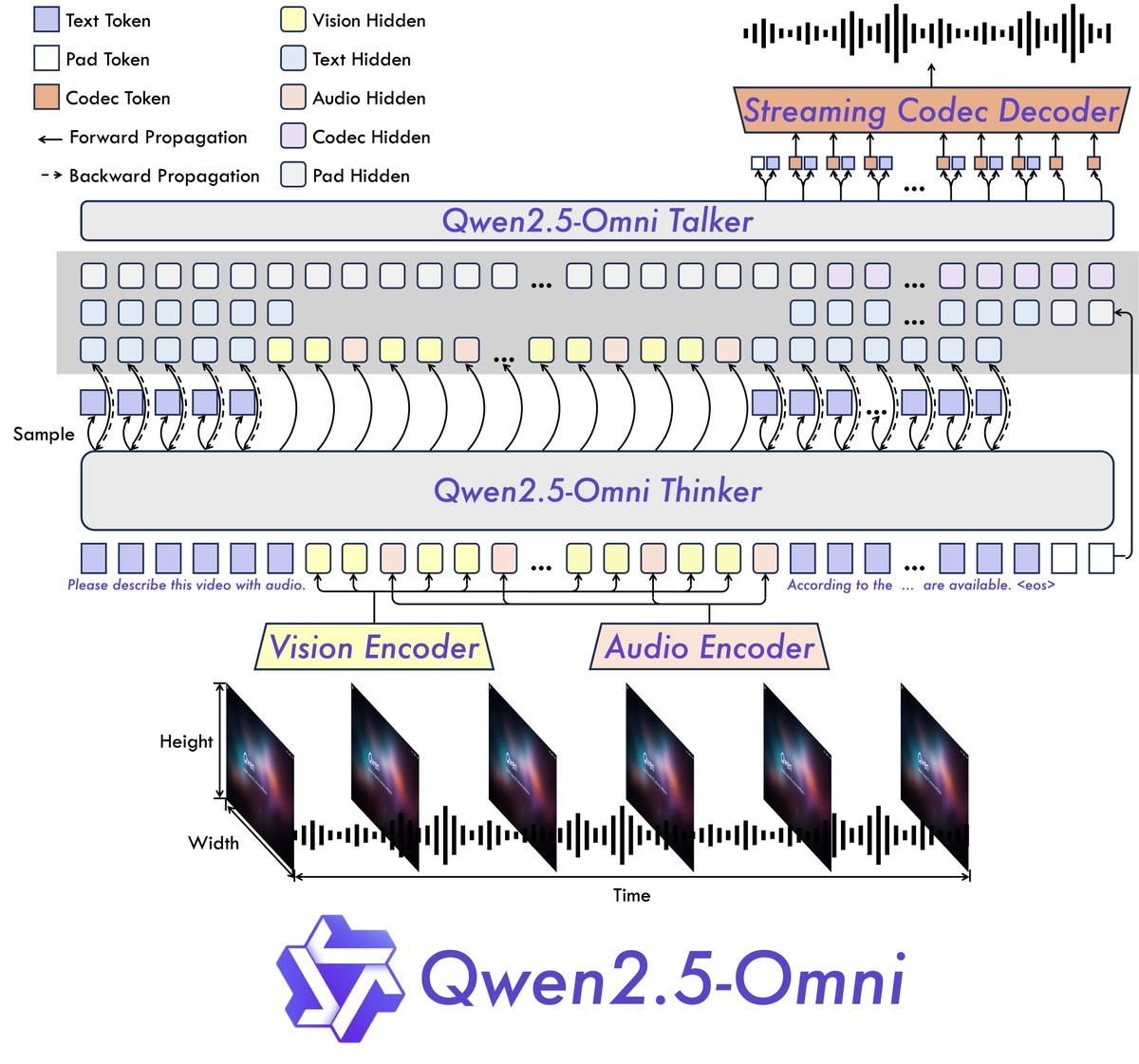
对 Qwen2.5-Omni 进行了全面评估,与类似大小的单模态模型和 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro 等闭源模型相比,该模型在所有模态中均表现出色。在需要集成多种模态的任务(例如 OmniBench)中,Qwen2.5-Omni 实现了最佳性能。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval 和主观自然度)等领域表现出色。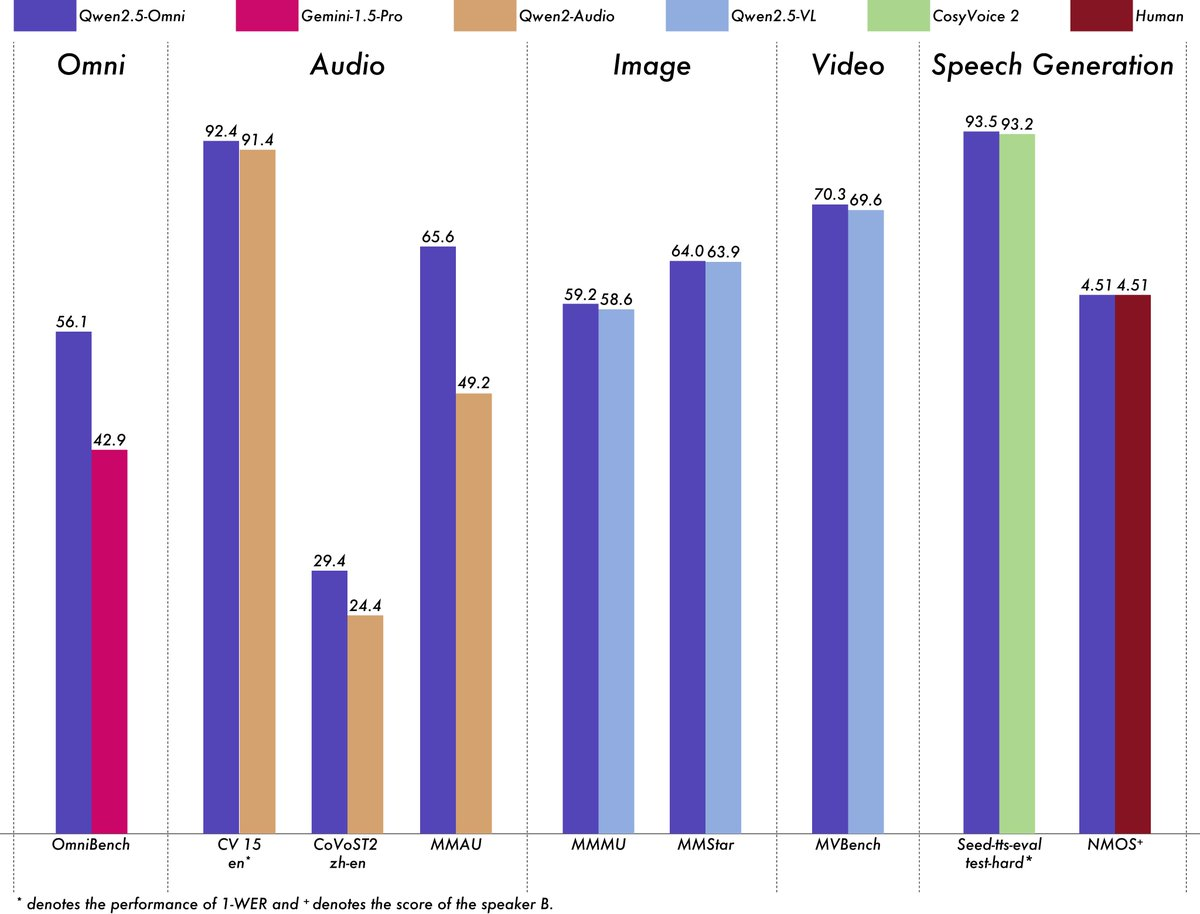
6.使用LLMs生成合成数据
论文地址:Synthetic Data Generation Using Large Language Models: Advances in Text and Code
亮点:
- 利用大型语言模型生成合成数据:使用提示生成多样的文本或代码示例,以增强训练数据集。
- 检索增强生成:通过引用外部知识库来改进合成数据的准确性和真实性,从而提升生成制度。
- 迭代自我优化:基于模型错误反复调整生成策略,以提升合成数据的质量和实用性。
论文的核心论点是:LLMs已经成为生成合成数据的强大工具,这些合成数据可以有效地增强甚至替代真实世界的数据集,尤其是在标注数据稀缺、昂贵或敏感的情况下。然而,使用LLMs生成合成数据也面临着质量控制、真实性和偏差(bias)等方面的挑战,需要采取相应的缓解策略。
核心方法论:Prompt-Based Data Generation (基于提示的数据生成)
论文重点介绍了一种核心方法论:基于提示的数据生成。这种方法利用LLMs的强大生成能力,通过精心设计的提示(prompts)来引导模型生成特定任务相关的合成数据。
技术细节
- LLM选择 (LLM Selection):根据任务的复杂性和所需的生成质量选择合适的LLM。例如,GPT-4通常能生成更高质量的数据,但成本也更高。
- 生成参数调整(Generation Parameter Tuning):调整LLM的生成参数,例如温度(temperature)、Top-p采样(top-p sampling)等,以控制生成数据的多样性和随机性。较高的温度会导致更随机和多样化的输出,而较低的温度会导致更保守和可预测的输出。
- 后处理技术(Post-processing Techniques):应用各种后处理技术来清理和改进生成的数据,例如删除重复项、更正语法错误以及删除不相关的内容。
- 加权损失(Weighted Loss):一些方法,如 SunGen,在模型训练期间应用加权损失,降低潜在的噪声合成示例的权重,以防止它们损害模型。