群雄逐鹿的 AI 时代,你不进步,就是在后退。
因为,总有人比你更 “卷”。
最近,OpenAI 可谓动作频频。
从最先发布的 GPT-4.5,目前最大参数模型(具体参数量未知),拥有最多的世界级知识,同时也是 OpenAI 最后一个 “非思考” 通用型模型。
到近期开放的 o1-pro 模型 API,o1 系列的高算力版本,也是 OpenAI 当前最强的推理模型,没有之一。
再到前天 OpenAI 重磅推出的基于 GPT-4o 的原生生图功能,相信开通了 ChatGPT 会员的小可爱已经玩 “疯” 了。
它打破了 传统 AI 画图工具的各个限制,无限放大了各种创意实现的可能性。
比如,它可以直接召集 “不同朝代的历史人物开个会”。

也可以轻松让 “哆啦A梦和樱桃小丸子合个影”。

然而,OpenAI 的好模型有一个 “通病”。
那就是 太贵。
GPT-4.5 和 o1-pro 皆是如此。
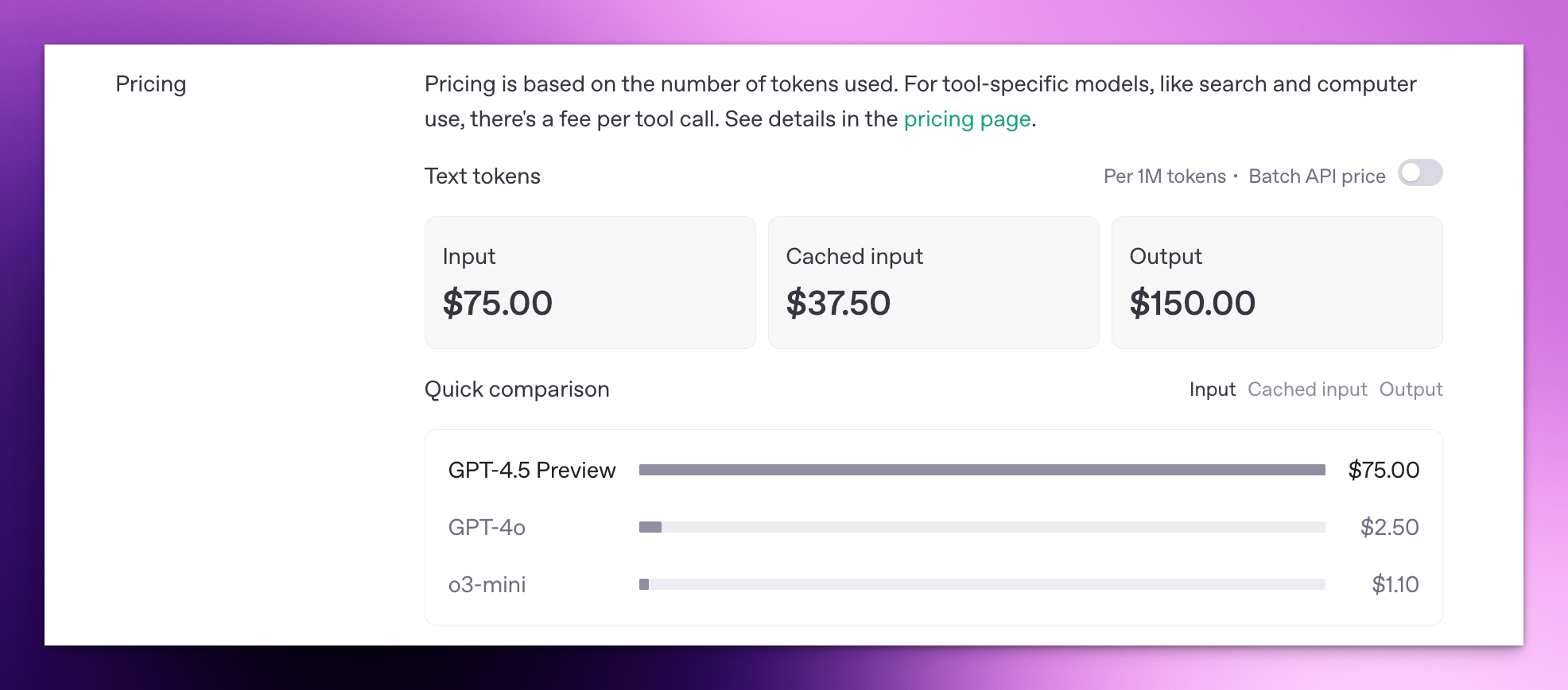
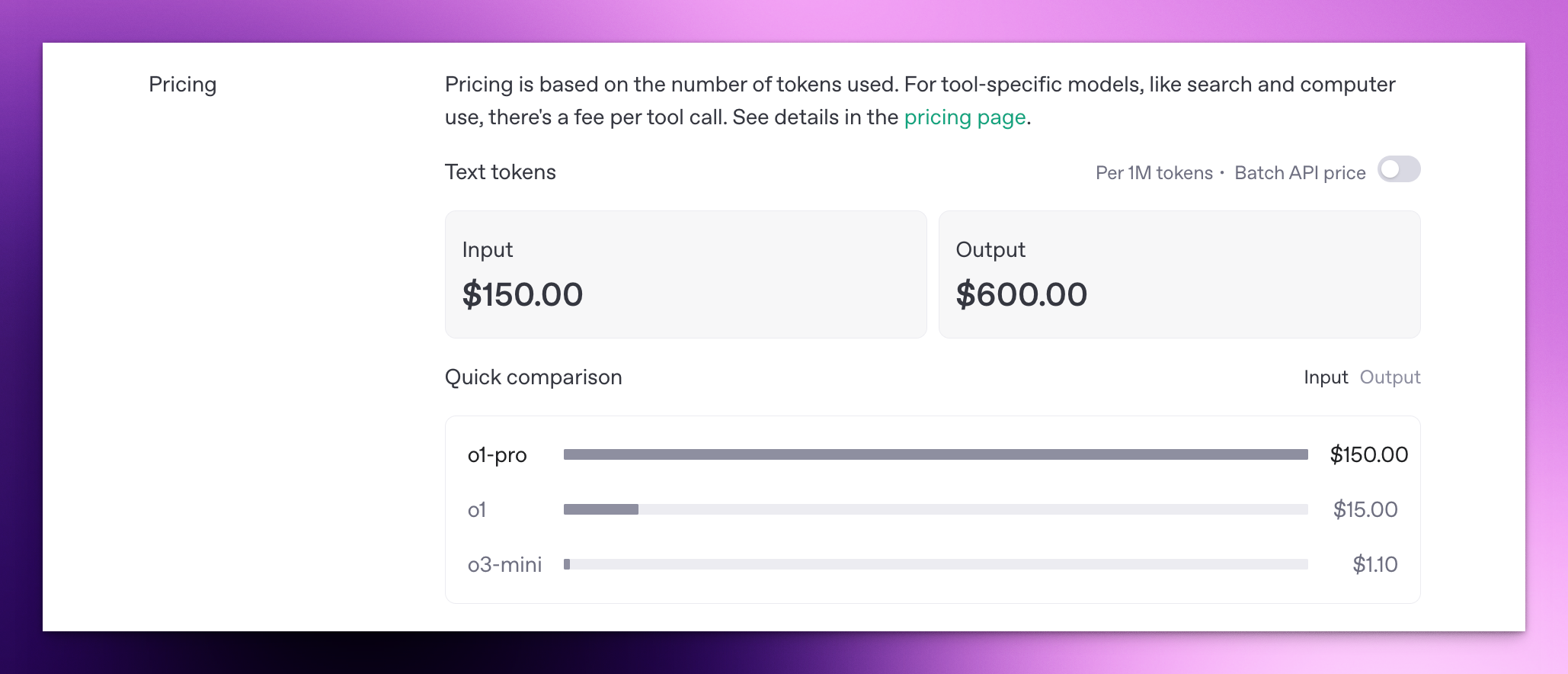
GPT-4.5 模型每百万输入、输出 tokens 成本分别为 75、150 美元。o1-pro 的成本更是高达每百万输入、输出 tokens 150、600 美元。
以我个人的一次实际体验为例。我只是随便问了 GPT-4.5 一个很普通的问题,它哐哐哐一通输出。OpenAI 就提醒我 “余额不足,该充值了”。

而反观最近的 “当红炸子鸡” DeepSeek 和谷歌,它们分别推出了各自的新模型 DeepSeek-V3-0324 和 Gemini 2.5 Pro。
然而,这俩模型,一个几乎接近免费,一个是真正的免费。
这让 OpenAI 怎么玩?是我我也急。
于是,OpenAI 出手了。
3 月 28 日凌晨,OpenAI 官宣对 ChatGPT 的基座模型 GPT-4o 进行了升级优化。
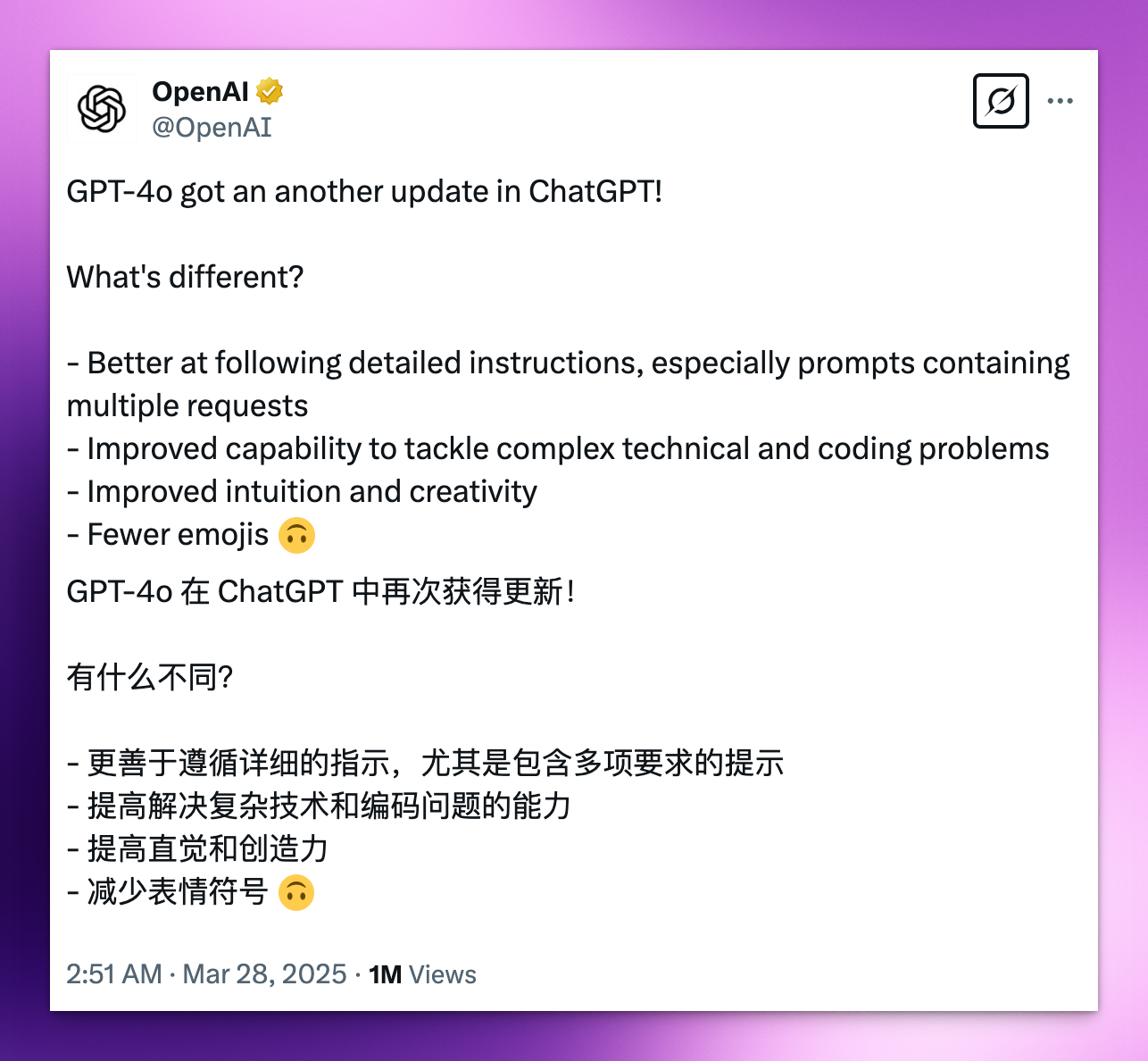
总结一下,这次的更新主要包括:
-
更精准的指令遵循。指令遵循其实是
GPT-4o的一大强项,从它超强的原生生图能力就能看出来。另外,从这里也能体现出 提示词 的重要性。尤其是复杂任务,你的提示词越精准,AI 回答的质量必然也就越高。 -
更强的推理和编程能力。这一点和
DeepSeek-V3-0324非常像,后者的这次更新也是在 推理和编程能力 显著提高。换句话说,GPT-4o变得更聪明了。 -
提高直觉和创造力。模型的直觉指的是 “快速抓住问题的关键”,以及对于 模糊问题准确的推断和响应。这一点其实是很关键的。因为多数用户在使用 ChatGPT 不会去精心构思提示词。
-
更少的表情符号。你感受到
GPT-4o这几个月以来在回答中加的表情符号变多了吗?这是去年年底 OpenAI 的更新。这次更新给改回去了。
更新后的 GPT-4o 怎么用?
遗憾的是,目前只有 ChatGPT 付费用户可用。免费用户需要再等几周才能体验。
付费用户,如 ChatGPT Plus 和 Pro,在 ChatGPT 里选择 ChatGPT 4o,就能体验到这个新模型了。
那么问题来了,更新后的 GPT-4o 值得用吗?
答案是:很值得。
相较于每周50次使用限制得 GPT-4.5,GPT-4o 的性价比几乎是拉满。
并且,在 LMSYS 大模型排行榜,这个最新的 GPT-4o 0326 已经超越 GPT-4.5 冲到了全榜单的第二名。“风格控制 Style Control” 模式下,综合评分 1359 分,仅次于谷歌的最新推理模型 Gemini 2.5 Pro。要知道,GPT-4o 0326 是一个不会思考的通用模型!

尺有所长,寸有所短。
虽然 OpenAI 官方宣传 GPT-4o 0326 在编程方面有提高,但实测下来,前端页面的设计和代码编写体验还是不如 DeepSeek-V3-0324,更不用说 Claude 3.7 Sonnet。
最后,附上这个我的实测。依旧是经典的 “天气卡片” 编程问题。
相同的提示词,GPT-4o 0326 仅输出了约 200 行代码,并且实际效果远比不上那篇文章里 DeepSeek-V3-0324 的表现。

我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。