一、引言
在机器人技术不断发展的今天,强化学习(RL)作为一种强大的机器学习范式,为机器人的智能决策和自主控制提供了新的途径。ROS2(Robot Operating System 2)作为新一代机器人操作系统,具有更好的实时性、分布式性能和安全性,为强化学习在机器人领域的应用提供了更坚实的基础。本文将通过一个具体案例,深入探讨 ROS2 与强化学习的结合应用,并提供相关代码实现。
二、案例背景
本案例以移动机器人在复杂环境中的导航任务为例。机器人需要在一个包含障碍物的地图中,从起始点移动到目标点,同时避免碰撞障碍物。传统的路径规划方法,如 A * 算法,虽然能够找到一条从起点到目标点的路径,但在动态环境中缺乏适应性。而强化学习可以让机器人通过与环境的交互,不断学习最优的行动策略,以适应不同的环境情况。
三、强化学习基础概念
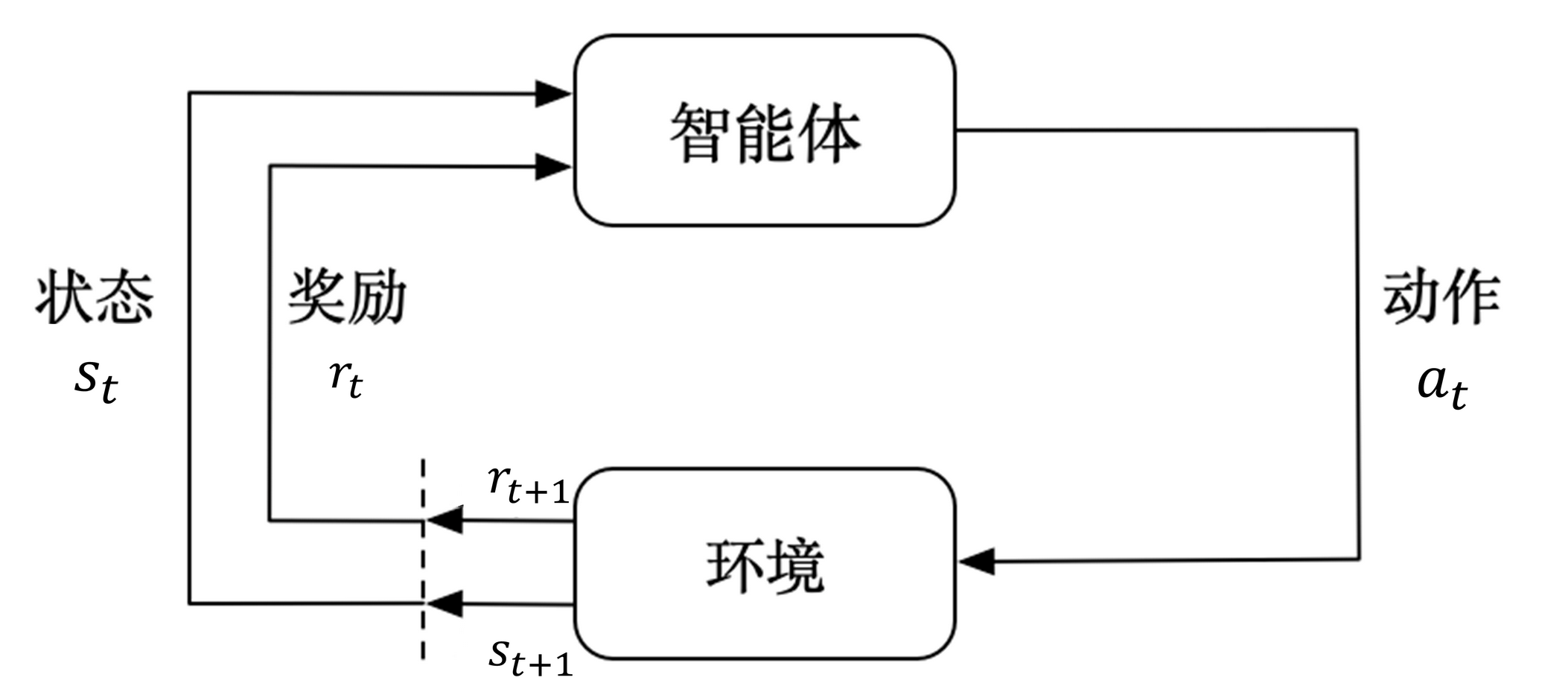
在深入案例之前,先简单回顾一些强化学习的基本概念:
- 智能体(Agent):在本案例中,智能体就是移动机器人,它能够感知环境并执行动作。
- 环境(Environment):包含地图、障碍物、起始点和目标点等信息,智能体在其中进行交互。
- 状态(State):描述智能体当前在环境中的情况,例如机器人的位置、方向等。
- 动作(Action):智能体可以采取的行动,如向前移动、向左转、向右转等。
- 奖励(Reward):环境根据智能体的动作给予的反馈,例如成功到达目标点给予正奖励,碰撞障碍物给予负奖励。
四、ROS2 与强化学习结合的实现
(一)环境搭建
- 安装 ROS2:根据官方文档,在 Ubuntu 系统上安装 ROS2 Foxy 版本。
- 安装强化学习库:使用 pip 安装 stable - baselines3 库,这是一个常用的强化学习算法实现库。
(二)代码实现
- 定义 ROS2 节点
首先,创建一个 ROS2 节点,用于与机器人的运动控制和传感器数据进行交互。以下是一个简单的 Python 代码示例:
import rclpy
from rclpy.node import Node
from geometry_msgs.msg import Twist
from sensor_msgs.msg import LaserScan
class RobotNode(Node):
def __init__(self):
super().__init__('robot_node')
self.publisher_ = self.create_publisher(Twist, 'cmd_vel', 10)
self.subscription = self.create_subscription(
LaserScan,'scan', self.scan_callback, 10)
self.subscription # prevent unused variable warning
def scan_callback(self, msg):
# 处理激光雷达数据,这里可以提取机器人周围障碍物的信息
pass
def send_velocity_command(self, linear_x, angular_z):
twist = Twist()
twist.linear.x = linear_x
twist.angular.z = angular_z
self.publisher_.publish(twist)- 定义强化学习环境
接下来,定义一个强化学习环境类,继承自 stable - baselines3 中的 gym.Env 类。在这个类中,定义状态空间、动作空间、重置环境和执行动作的方法。
import gym
from gym import spaces
import numpy as np
class RobotEnv(gym.Env):
def __init__(self):
super(RobotEnv, self).__init__()
# 定义状态空间,例如机器人的位置和激光雷达数据
self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(10,), dtype=np.float32)
# 定义动作空间,例如机器人的线速度和角速度
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(2,), dtype=np.float32)
def reset(self):
# 重置环境,返回初始状态
initial_state = np.zeros(10)
return initial_state
def step(self, action):
# 执行动作,返回新的状态、奖励、是否结束和其他信息
new_state = np.zeros(10)
reward = 0
done = False
info = {}
return new_state, reward, done, info- 训练强化学习模型
使用 stable - baselines3 中的 PPO(近端策略优化)算法训练强化学习模型。
from stable_baselines3 import PPO
env = RobotEnv()
model = PPO('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=10000)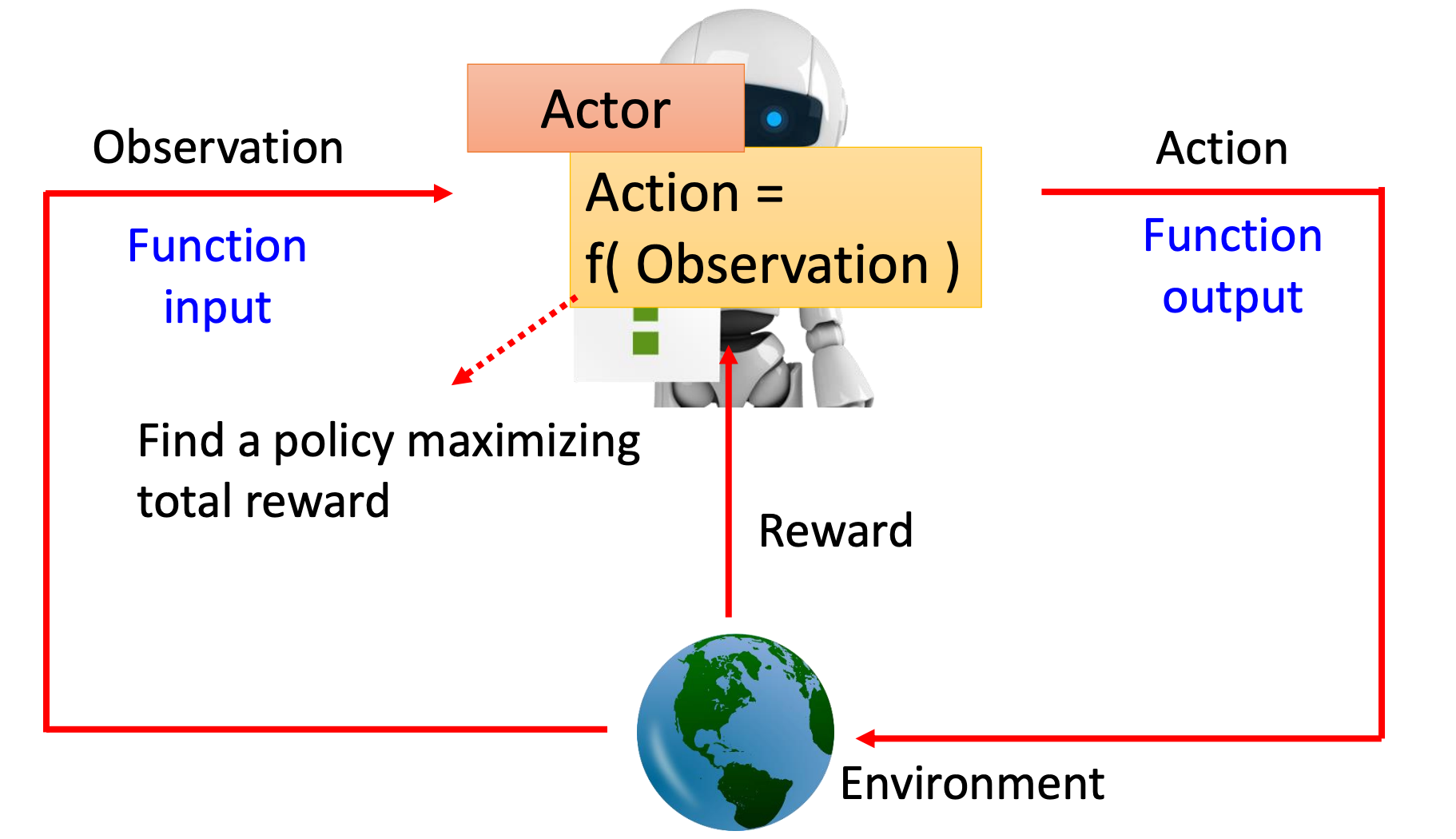
五、强化学习常用算法
点击ROS2 强化学习:案例与代码实战查看全文。