在实际开发中,我们经常需要从网页内容(content)中提取数据,并将其转换为结构化信息(如 JSON)。Python 提供了强大的工具来实现这一目标,包括 re 模块的正则表达式功能、requests 库获取网页内容,以及 json 模块处理 JSON 数据。本文将详细介绍如何使用这些工具完成数据提取任务。
1. 获取网页内容(content)
在提取数据之前,我们需要先获取网页的内容。通常使用 requests 库来发送 HTTP 请求并获取网页的 HTML 内容。
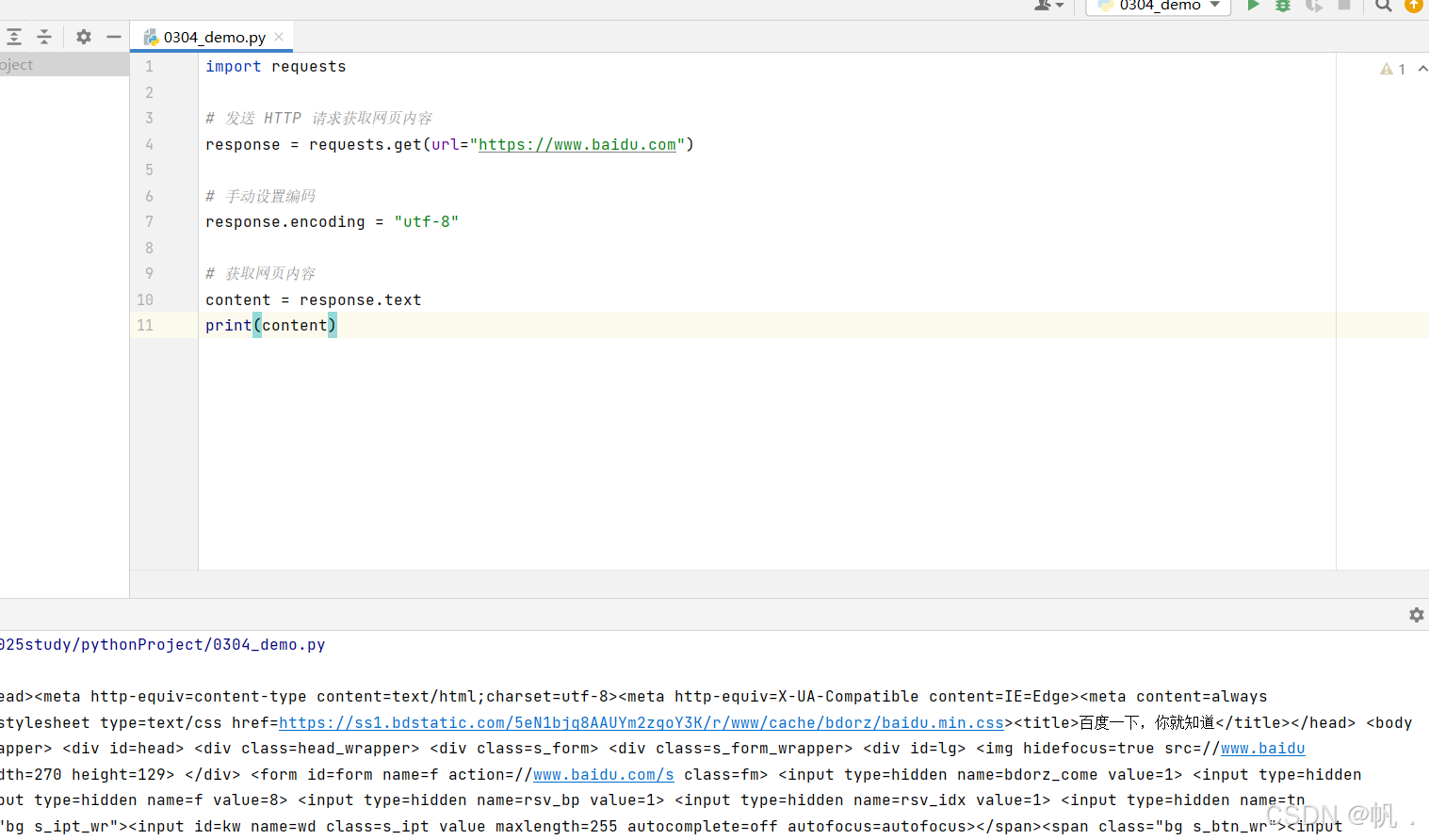
import requests
import requests # 发送 HTTP 请求获取网页内容 response = requests.get(url="https://www.baidu.com") # 手动设置编码 response.encoding = "utf-8" # 获取网页内容 content = response.text print(content)
注意点: Python 在打印内容时,默认使用了 gbk 编码,而网页内容中可能包含 gbk 编码无法处理的字符(例如 UTF-8 编码的非 ASCII 字符),会报错:UnicodeEncodeError: 'gbk' codec can't encode character '\xe7' in position 318: illegal multibyte sequence
在上面代码中直接手动设置编码
2. 使用 re.findall 提取数据
获取网页内容后,我们可以使用 re.findall 从 HTML 中提取所需的数据。re.findall 是正则表达式的核心函数之一,用于查找所有匹配的子串。
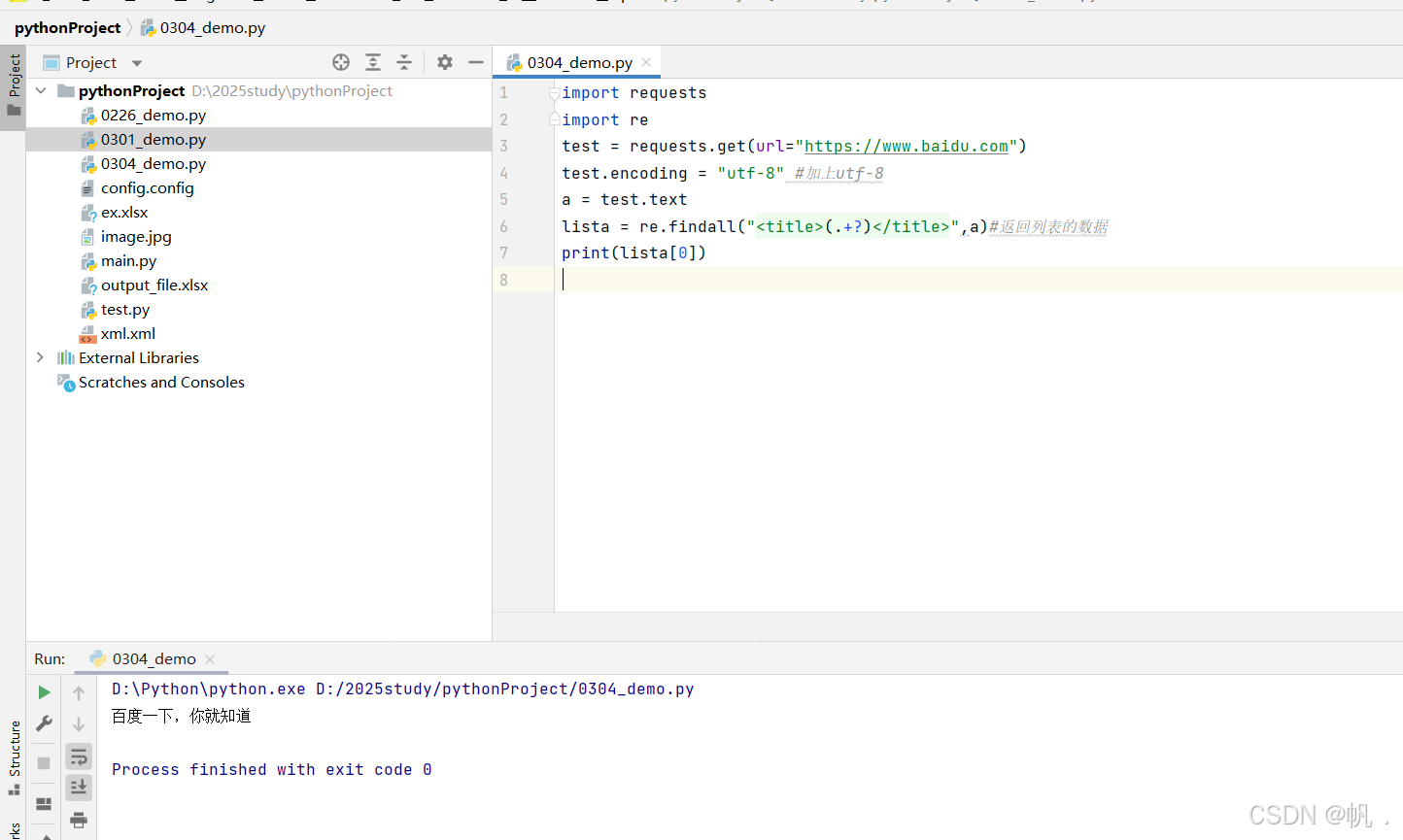
2.1 单个正常表达式提取
import requests
import re
test = requests.get(url="https://www.baidu.com")
test.encoding = "utf-8" #加上utf-8
a = test.text
lista = re.findall("<title>(.+?)</title>",a)#返回列表的数据
print(lista[0])
2.2 多个正则表达式提取
2.2.1 将今日的博客云的新闻标题全部提取
2.2.2 打开在线正则表达式测试,将python输入的结果复制,粘贴到在线正则表式上
2.2.3 找到第一个和第二个新闻的标签,复制到记事本上,发现规律,id不一样,将id和标题内容替换为正则表达式,在2.2.2的正则表达式上粘贴,点击匹配
2.2.4 发现30个,在python中写一个循环,取全部的数据
import requests import re test = requests.get(url="https://news.cnblogs.com/") lista = re.findall('<a href="/n/(.+?)/" target="_blank">(.+?)</a>',test.text) for i in range(29): #30个数据,返回的是列表,变化的只有第一个 print(lista[i][1])
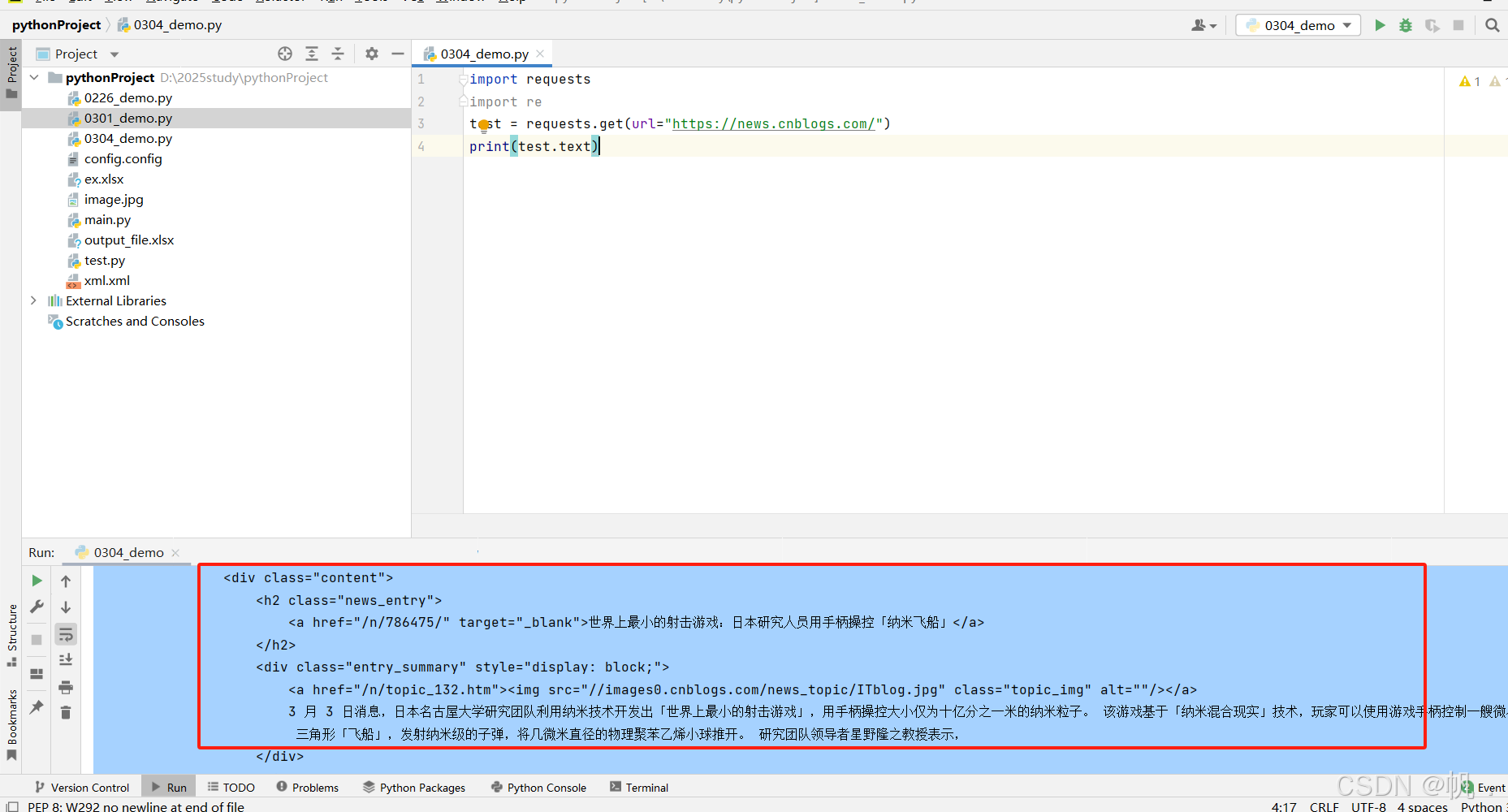
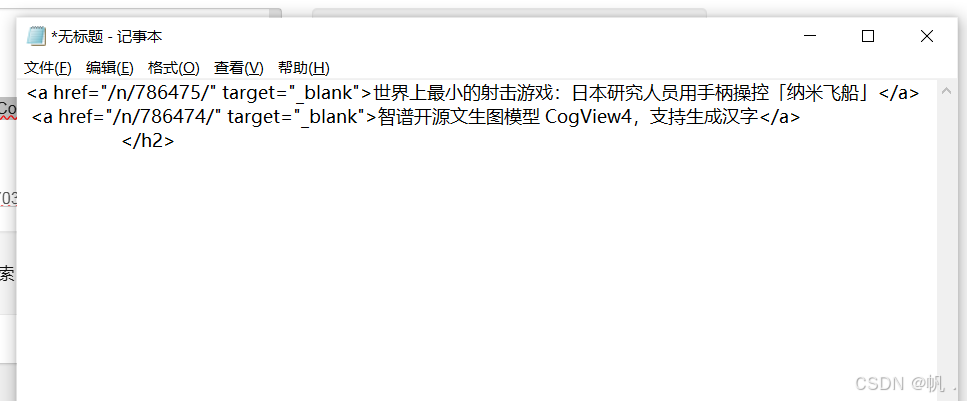
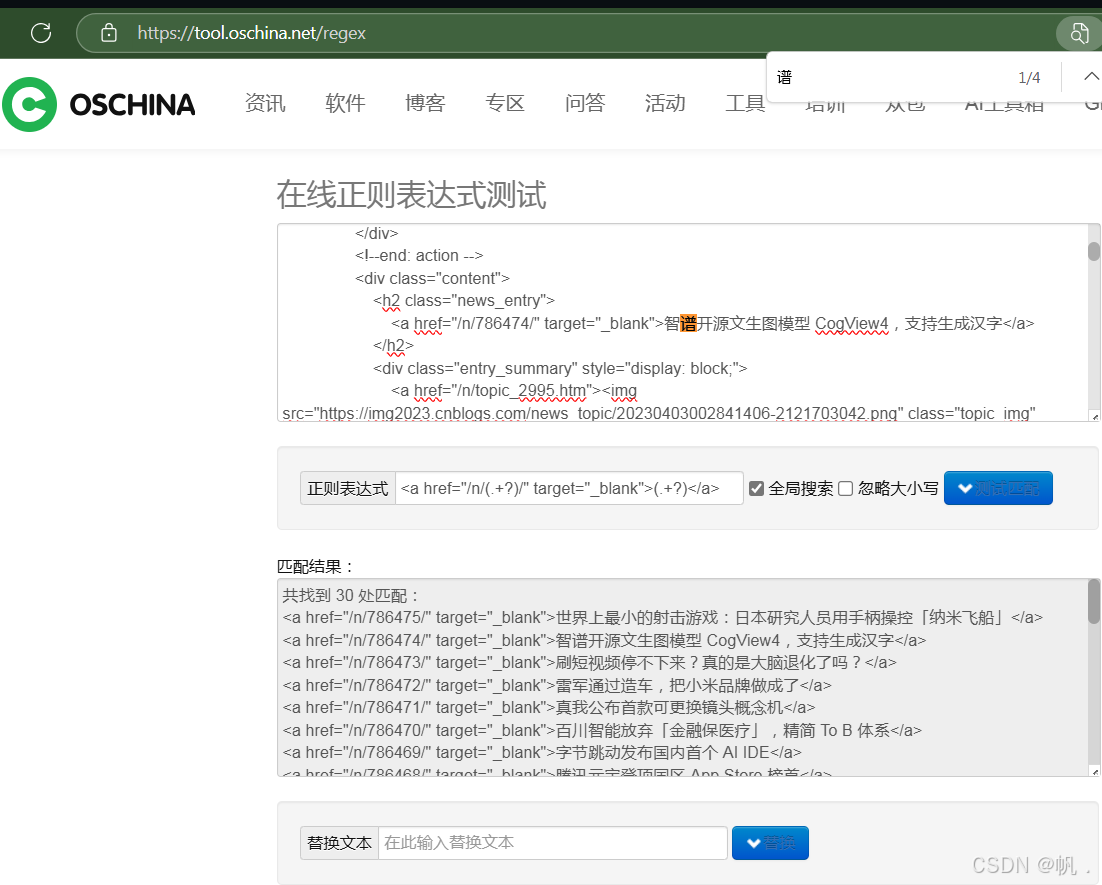
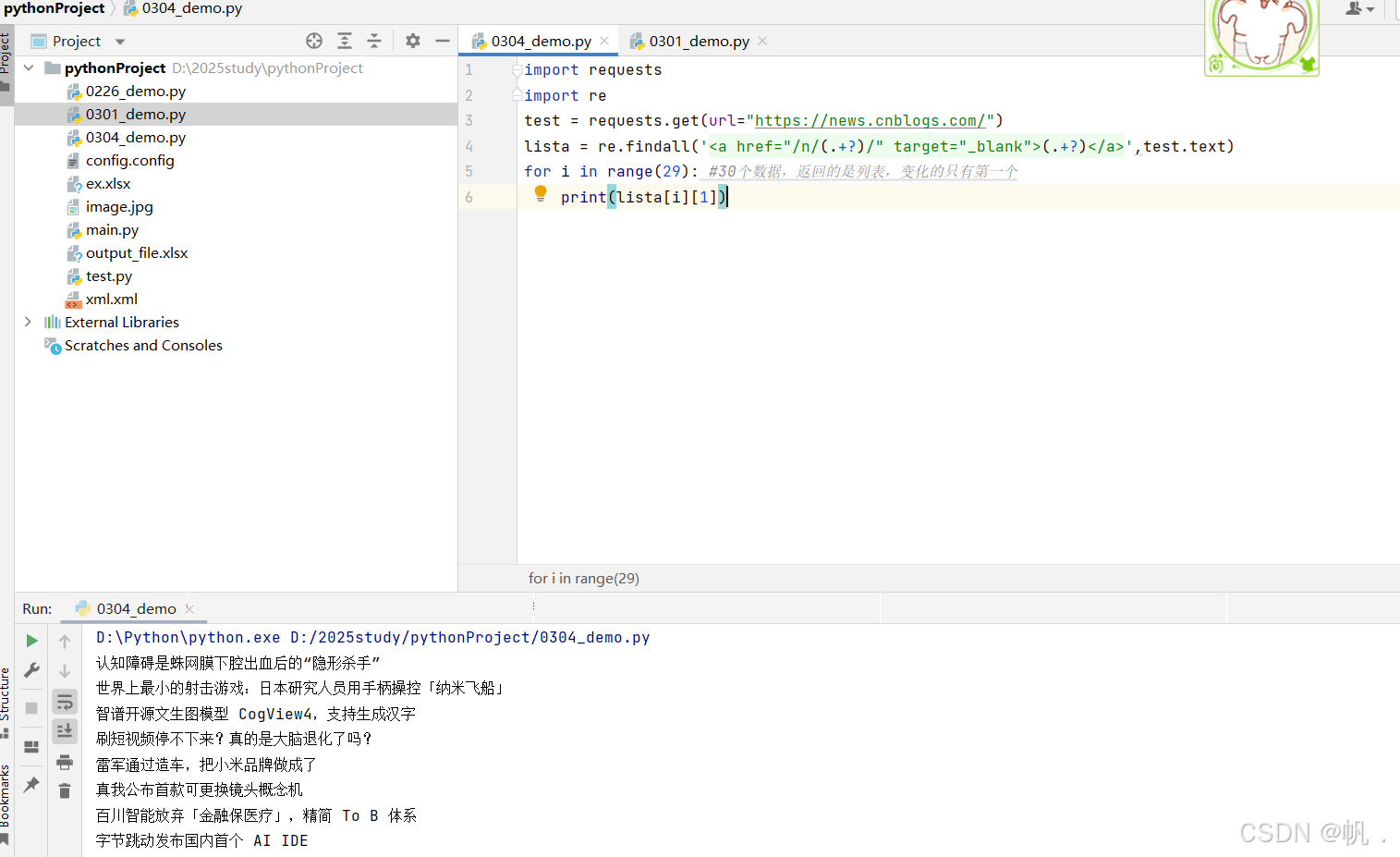
3. 使用 json 模块处理结构化数据
提取的数据通常需要进一步处理,转换为结构化格式(如 JSON)。json 模块提供了将字符串解析为 Python 对象(如字典、列表)的功能。
3.1安装jsonpath
pip install josnpath
3.2 json字符串转换成 json对象 == jsonpath
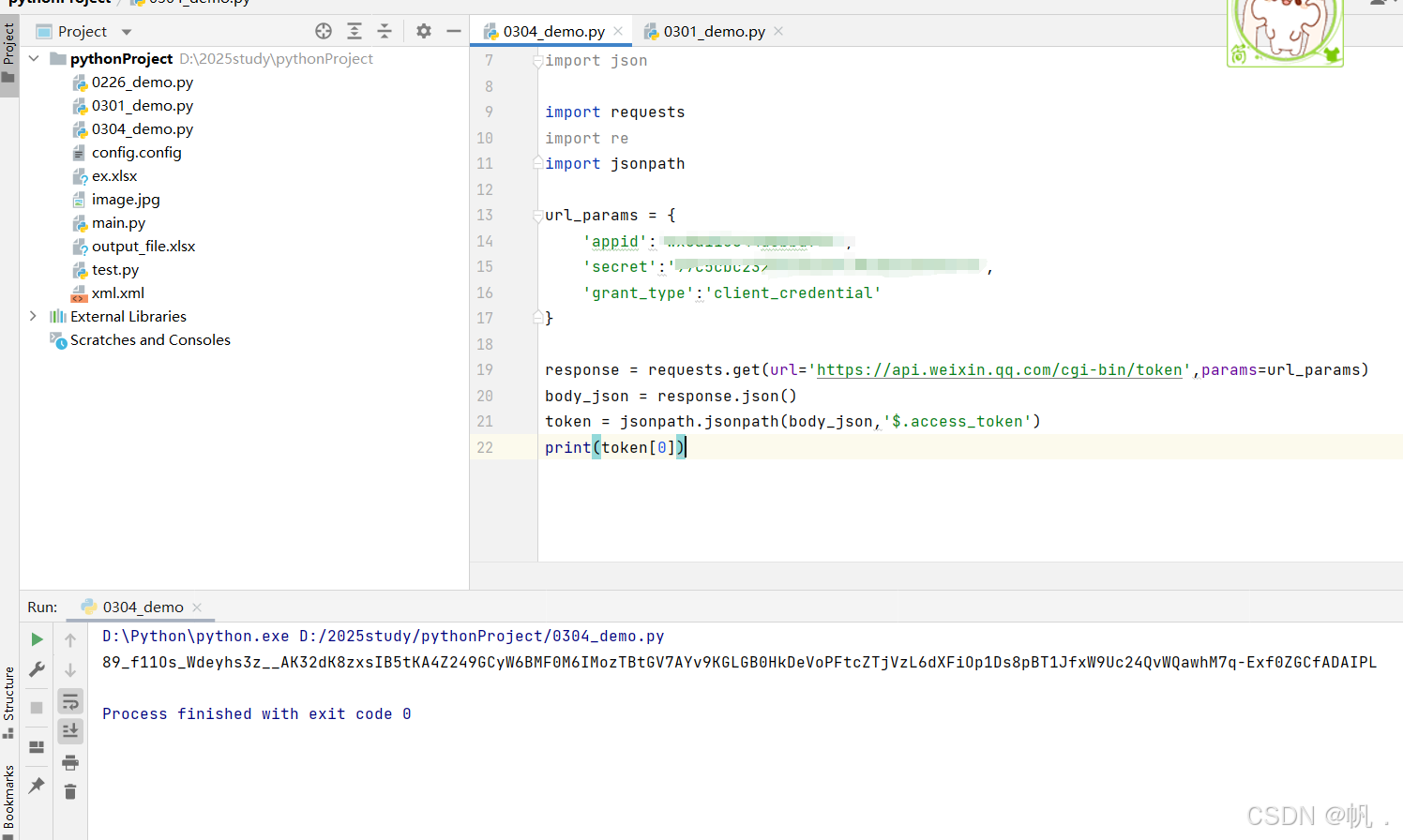
import json import requests import re import jsonpath url_params = { 'appid':'微信公众号id', 'secret':'微信公众号secret', 'grant_type':'client_credential' } response = requests.get(url='https://api.weixin.qq.com/cgi-bin/token',params=url_params) body_str =response.text print(body_str) body_json = json.loads(body_str) #将字符串转换对象 token = jsonpath.jsonpath(body_json,'$.access_token') print(token[0])
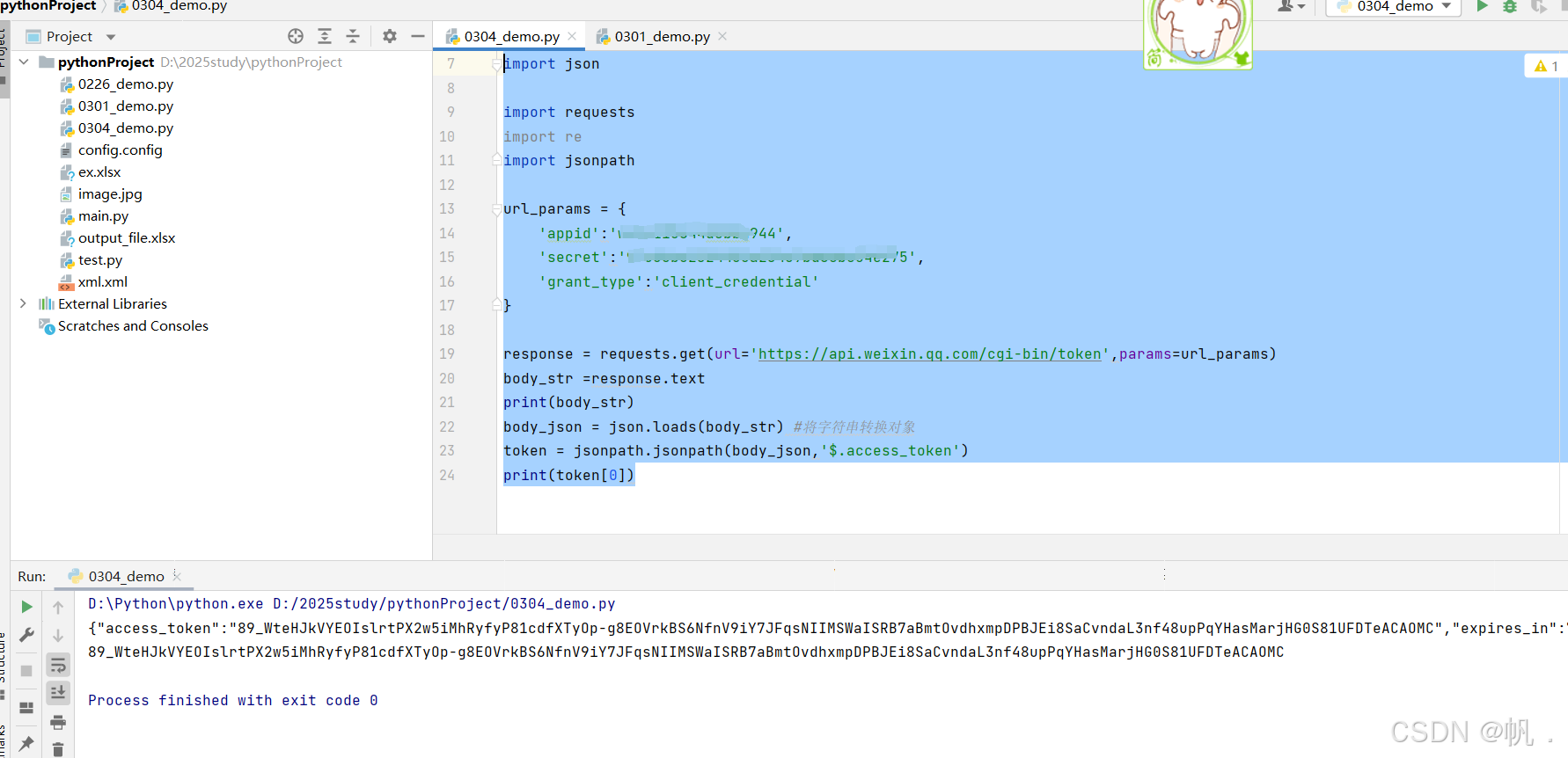
3.3 响应正文直接转换json对象返回
import requests import re import jsonpath url_params = { 'appid':'微信公众号id', 'secret':'微信公众号secret', 'grant_type':'client_credential' } response = requests.get(url='https://api.weixin.qq.com/cgi-bin/token',params=url_params) body_json = response.json() token = jsonpath.jsonpath(body_json,'$.access_token') print(token[0])