RAG 检索通常与向量数据库密切结合,也催生了基于 ChatGPT + Vector Database + Prompt 的 RAG 解决方案,简称为 CVP 技术栈。这一解决方案依赖于向量数据库高效检索相关信息以增强大型语言模型(LLMs),通过将 LLMs 生成的查询转换为向量,使得 RAG 系统能在向量数据库中迅速定位到相应的知识条目。这种检索机制使 LLMs 在面对具体问题时,能够利用存储在向量数据库中的最新信息,有效解决 LLMs 固有的知识更新延迟和幻觉的问题。
向量数据库在高效地存储和检索大量嵌入向量方面的出色能力
在 RAG 系统中,检索的任务是快速且精确地找出与输入查询语义上最匹配的信息,而向量数据库正因其在处理高维向量数据和进行快速相似性搜索方面的显著优势而脱颖而出。
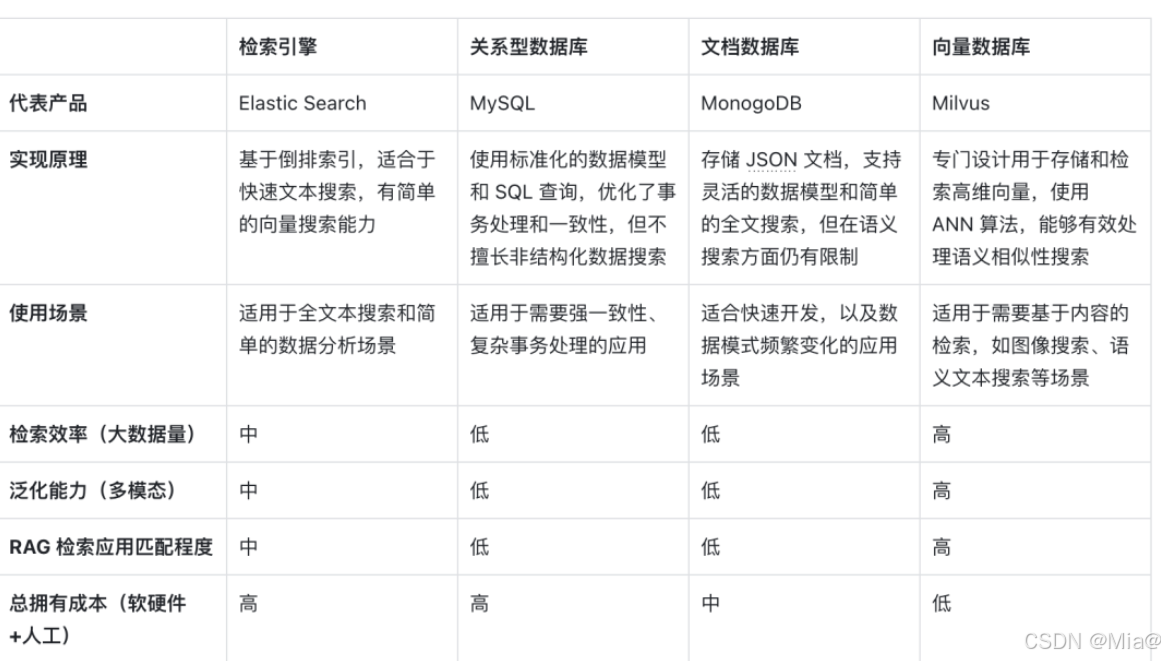
由于信息可以表示成高维向量,针对向量加上特殊的索引优化和量化方法,可以极大提升检索效率并压缩存储成本,随着数据量的增长,向量数据库能够水平扩展,保持查询的响应时间,这对于需要处理海量数据的 RAG 系统至关重要,因此向量数据库更擅长处理超大规模的非结构化数据。
传统的搜索引擎、关系型或文档数据库大都只能处理文本,泛化和扩展的能力差,向量数据库不仅限于文本数据,还可以处理图像、音频和其他非结构化数据类型的嵌入向量,这使得 RAG 系统可以更加灵活和多功能。
向量检索正凭借其对于语义的理解能力、高效的检索