目录
思路
一个好的prompt应该始终以 response是否符合任务要求 为标准,由于LLM的回答具有黑盒性质,所以prompt工程需要人来不断试错找到一个相对靠谱的prompt,但这种优化的时间成本过高,因此本文抛砖引玉,提供一种用LLM来优化prompt的思路,评估流程如下:
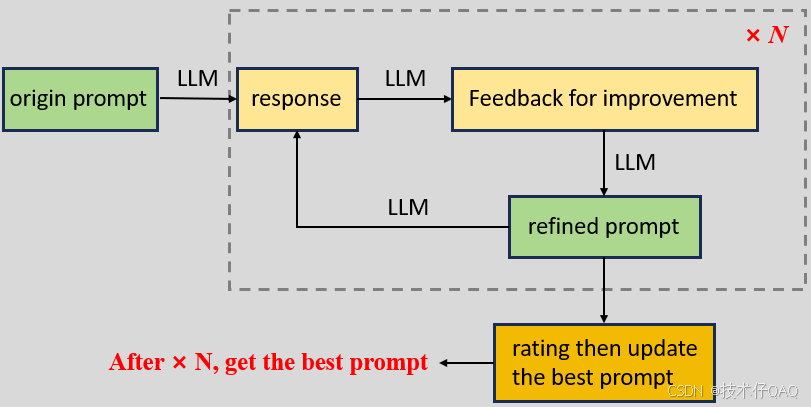
输入原始prompt — LLM生成response — 根据response提出反馈建议 — 根据建议修改prompt — 对修改后的prompt打分并记录分数最高的prompt
代码
打分函数
定义三个指标来对LLM生成的response打分,通过分数来评估prompt的效果。
criteria = ["clarity", "informativeness", "engagement"]
def evaluate_response(response, criteria):
"""Evaluate the quality of a response based on given criteria.
Args:
response (str): The generated response.
criteria (list): List of criteria to evaluate.
Returns:
float: The average score across all criteria.
"""
scores = []
for criterion in criteria:
print(f"Evaluating response based on {criterion}...")
# prompt = f"On a scale of 1-10, rate the following response on {criterion}. Start your response with the numeric score:\n\n{response}"
prompt = (
f'''Rate the following response on: {criterion}.
The response is: \n\n{response} \nStart your rating, On a scale of 1-10.'''
)
response = generate_response(prompt)
# show 50 characters of the response
# Use regex to find the first number in the response
score_match = re.search(r'\d+', response)
if score_match:
score = int(score_match.group())
scores.append(min(score, 10)) # Ensure score is not greater than 10
else:
print(f"Warning: Could not extract numeric score for {criterion}. Using default score of 5.")
scores.append(5) # Default score if no number is found
return np.mean(scores)反馈和修改函数
让LLM对response生成修改建议,然后根据生成建议修改prompt。
def refine_prompt(initial_prompt, topic, iterations=3):
"""Refine a prompt through multiple iterations.
Args:
initial_prompt (PromptTemplate): The starting prompt template.
topic (str): The topic to explain.
iterations (int): Number of refinement iterations.
Returns:
PromptTemplate: The final refined prompt template.
"""
current_prompt = initial_prompt
best_score = -1
best_template = current_prompt.template
for i in range(iterations):
try:
response = generate_response(current_prompt.format(topic=topic))
except KeyError as e:
print(f"Error in iteration {i+1}: Missing key {e}. Adjusting prompt...")
# Remove the problematic placeholder
current_prompt.template = current_prompt.template.replace(f"{
{
{e.args[0]}}}", "relevant example")
response = generate_response(current_prompt.format(topic=topic))
# Generate feedback and suggestions for improvement
feedback_prompt = f"Analyze the following explanation of {topic} and suggest improvements to the prompt that generated it:\n\n{response}"
feedback = generate_response(feedback_prompt)
# Use the feedback to refine the prompt
refine_prompt = f"Based on this feedback: '{feedback}', improve the following prompt template. Ensure to only use the variable {
{topic}} in your template:\n\n{current_prompt.template}"
refined_template = generate_response(refine_prompt)
current_prompt = PromptTemplate(
input_variables=["topic"],
template=refined_template
)
# Evaluate the refined template
refined_response = generate_response(current_prompt.format(topic=topic))
refined_score = evaluate_response(refined_response, ["clarity", "informativeness", "engagement"])
if refined_score > best_score:
best_score = refined_score
best_template = current_prompt.template
print(f"Iteration {i+1} prompt: {current_prompt.template}")
print(f"Iteration {i+1} score: {refined_score:.2f}")
print(best_template)
return PromptTemplate(input_variables=["topic"], template=best_template)
示例演示
from langchain.prompts import PromptTemplate
# 设置origin prompt
prompt_a = PromptTemplate(
input_variables=["topic"],
template="Explain {topic}."
)
topic = "machine learning"
refined_prompt = refine_prompt(prompt_a, "machine learning")
print("\nFinal refined prompt:")
print(refined_prompt.template)输出结果:
prompt_a:Explain {topic}.(解释一下{topic})
*************************************************************************************
final_refined_prompt:Explain {topic} by providing a brief definition of artificial intelligence to establish context and clarity. Illustrate {topic} with real-world examples to showcase its practical applications in various industries. Discuss potential challenges and limitations of {topic}, such as data biases and ethical considerations, to offer a more balanced perspective. Emphasize the importance of data quality and preprocessing in {topic} to underscore the crucial role of data in ML algorithms. Lastly, provide suggestions for further reading or resources to help readers deepen their understanding of {topic}.(通过提供人工智能的简要定义来解释{topic},以建立上下文和清晰度。用现实世界的例子来说明{topic},以展示其在各个行业的实际应用。讨论{topic}的潜在挑战和限制,例如数据偏差和道德考虑,以提供更平衡的观点。强调{topic}中数据质量和预处理的重要性,强调数据在ML算法中的关键作用。最后,提供进一步阅读的建议或资源,以帮助读者加深对{topic}的理解。)
Evaluating response based on clarity...
Evaluating response based on informativeness...
Evaluating response based on engagement...
Iteration 1 prompt: Explain {topic} by providing a brief definition of artificial intelligence to establish context and clarity. Illustrate {topic} with real-world examples to showcase its practical applications in various industries. Discuss potential challenges and limitations of {topic}, such as data biases and ethical considerations, to offer a more balanced perspective. Emphasize the importance of data quality and preprocessing in {topic} to underscore the crucial role of data in ML algorithms. Lastly, provide suggestions for further reading or resources to help readers deepen their understanding of {topic}.(通过提供人工智能的简要定义来解释{主题},以建立上下文和清晰度。用现实世界的例子来说明{topic},以展示其在各个行业的实际应用。讨论{topic}的潜在挑战和限制,例如数据偏差和道德考虑,以提供更平衡的观点。强调{topic}中数据质量和预处理的重要性,强调数据在ML算法中的关键作用。最后,提供进一步阅读的建议或资源,以帮助读者加深对{topic}的理解。)
Iteration 1 score: 9.33
Evaluating response based on clarity...
Evaluating response based on informativeness...
Evaluating response based on engagement...
Iteration 2 prompt: Explain {topic} by providing a brief definition of artificial intelligence to establish context and clarity. Clarify the target audience by specifying whether the explanation is intended for beginners, intermediate, or advanced users in the field of AI and machine learning. Illustrate {topic} with real-world case studies to showcase its practical applications in various industries. Discuss potential challenges and limitations of {topic}, such as data biases and ethical considerations, to offer a more balanced perspective. Emphasize the importance of data quality and preprocessing in {topic} to underscore the crucial role of data in ML algorithms. Include references and citations to reputable sources, research papers, or industry publications to support the information provided and allow readers to delve deeper into specific topics within {topic}. Lastly, provide suggestions for further reading or resources to help readers deepen their understanding of {topic}.(通过提供人工智能的简要定义来解释{主题},以建立上下文和清晰度。通过指定解释是针对人工智能和机器学习领域的初学者、中级用户还是高级用户来澄清目标受众。用现实世界的案例研究来说明{topic},以展示其在各个行业的实际应用。讨论{topic}的潜在挑战和限制,例如数据偏差和道德考虑,以提供更平衡的观点。强调{topic}中数据质量和预处理的重要性,强调数据在ML算法中的关键作用。包括参考文献和引用有信誉的来源,研究论文,或行业出版物,以支持所提供的信息,并允许读者深入研究{topic}中的特定主题。最后,提供进一步阅读的建议或资源,以帮助读者加深对{topic}的理解。)
Iteration 2 score: 6.33
Evaluating response based on clarity...
Evaluating response based on informativeness...
Evaluating response based on engagement...
Iteration 3 prompt: Explain {topic} by providing a more concise and clear definition of machine learning at the beginning of the explanation to set the context for readers. Clarify the target audience by specifying whether the explanation is intended for beginners, intermediate, or advanced users in the field of AI and machine learning. Include examples of popular machine learning algorithms, such as decision trees, support vector machines, or neural networks, to give readers a more comprehensive understanding of the topic. Expand on the challenges faced by machine learning, such as overfitting, underfitting, or the curse of dimensionality, to provide a more well-rounded view of the field. Include more real-world case studies across different industries to showcase the diverse applications of machine learning. Incorporate information on the tools and programming languages commonly used in machine learning, such as Python, TensorFlow, or Scikit-learn, to help beginners get started in the field. Include a brief overview of the history of machine learning and how it has evolved over the years to give readers a better understanding of its origins and development. Add information on the current trends and future prospects of machine learning, such as deep learning, explainable AI, or autonomous systems, to highlight the advancements in the field.(解释{topic},在解释开始时提供一个更简洁清晰的机器学习定义,为读者设置上下文。通过指定解释是针对人工智能和机器学习领域的初学者、中级用户还是高级用户来澄清目标受众。包括流行的机器学习算法的例子,如决策树、支持向量机或神经网络,让读者更全面地了解这个主题。扩展机器学习面临的挑战,例如过拟合,欠拟合或维度诅咒,以提供更全面的领域视图。包括更多不同行业的真实案例研究,以展示机器学习的各种应用。结合机器学习中常用的工具和编程语言的信息,如Python、TensorFlow或Scikit-learn,以帮助初学者开始该领域的学习。包括对机器学习历史的简要概述以及多年来它是如何演变的,以便读者更好地了解它的起源和发展。添加有关机器学习的当前趋势和未来前景的信息,例如深度学习,可解释的人工智能或自主系统,以突出该领域的进展。)
Iteration 3 score: 8.67
Final refined prompt:
Explain {topic} by providing a brief definition of artificial intelligence to establish context and clarity. Illustrate {topic} with real-world examples to showcase its practical applications in various industries. Discuss potential challenges and limitations of {topic}, such as data biases and ethical considerations, to offer a more balanced perspective. Emphasize the importance of data quality and preprocessing in {topic} to underscore the crucial role of data in ML algorithms. Lastly, provide suggestions for further reading or resources to help readers deepen their understanding of {topic}.前后比较,输入给LLM进行回答:
prompt_a:机器学习是人工智能的一个子集,涉及算法和统计模型的开发,允许计算机系统在没有明确编程的情况下从经验中学习和改进。它使用数据来识别模式,做出预测,并优化决策过程。机器学习算法可以分为三大类:监督学习、无监督学习和强化学习。在监督学习中,算法在带有输入输出对的标记数据上进行训练,以根据新数据做出预测。在无监督学习中,算法在未标记的数据上进行训练,以识别数据中的模式和关系。强化学习包括使用奖励和惩罚来训练算法,使其基于试验和错误做出决策。总的来说,机器学习被广泛应用于图像和语音识别、预测分析、推荐系统和自动驾驶汽车等领域。它继续发展,在推动技术进步和解决各行业的复杂问题方面发挥着至关重要的作用。
*************************************************************************************
refined_prompt:人工智能(AI)是一种能够完成通常需要人类智能才能完成的任务的机器,比如视觉感知、语音识别、决策和语言翻译。机器学习是人工智能的一个子集,涉及可以从数据中学习并根据数据做出预测或决策的算法。机器学习算法用于各种行业,用于自动化和优化流程,提供来自大型数据集的见解,并实现预测分析。例如,在医疗保健领域,机器学习用于预测患者结果、协助诊断和个性化治疗计划。在金融领域,机器学习算法被用于欺诈检测、风险评估和算法交易。在市场营销中,机器学习可以帮助企业通过个性化推荐和优化广告活动来瞄准合适的受众。然而,机器学习也面临着挑战和限制。数据偏差可能导致不公平的结果,例如有偏见的招聘做法或歧视性的贷款决定。必须解决隐私问题和问责制等道德问题,以确保负责任地使用机器学习系统。数据质量和预处理在机器学习中至关重要,因为机器学习算法的性能在很大程度上依赖于用于训练的数据的质量和相关性。数据预处理包括清理、转换和准备数据,使其适合训练机器学习模型。要进一步阅读,Aurelien Geron的“动手机器学习与Scikit-Learn, Keras和TensorFlow”是一本流行的书,提供了机器学习的实用介绍。Coursera和Udemy等在线资源为初学者和高级学习者提供机器学习课程。此外,像Kaggle这样的平台提供数据集和竞赛,帮助从业者磨练他们的机器学习技能。
总结
用LLM评估自己的response显然比人工更有效,因为:1. LLM效率更高;2. LLM更了解自己输出的不足。
将这套prompt optimization范式应用到具体场景时,可以根据任务的不同修改打分指标。
可以进一步优化的部分:1. 指标 2. feedback的prompt可以加入更具体约束,加速收敛。