目录
一、论文信息
1.1、中文名称
中文题目:ConDSeg:一种通过对比驱动特征增强的通用医学图像分割框架
1.2、论文关键词
医学图像分割、共现现象、对比驱动特征增强、语义信息解耦、尺寸感知解码器
1.3、核心概述
本文提出了一种名为ConDSeg的通用医学图像分割框架,通过对比驱动的特征增强来解决医学图像分割中的“软边界”和共现现象两大挑战。
1.4、源码链接
链接地址:https://github.com/Mengqi-Lei/ConDSeg
二、摘要
2.1、背景
医学图像分割在临床决策、治疗计划和疾病跟踪中发挥着重要作用, 但仍面临两大挑战。
2.2、挑战
一方面,医学图像中前景和背景之间往往存在“软边界”,光照差和对比度低进一步降低了图像内前景和背景的可区分性。 另一方面,共现现象在医学图像中普遍存在,学习这些特征会误导模型的判断。
2.3、提出新方法
为了应对这些挑战,论文提出了一个称为对比度驱动医学图像分割(ConDSeg)的通用框架。
首先,论文开发了一种称为一致性强化(Consistency Reinforcement,CR)的对比训练策略。 它旨在提高编码器在各种照明和对比度场景下的鲁棒性,使模型即使在恶劣环境下也能提取高质量的特征。
其次,论文引入了语义信息解耦模块,该模块能够将编码器中的特征解耦为前景、背景和不确定性区域,逐渐获得在训练过程中减少不确定性的能力。 然后,对比度驱动的特征聚合模块对比前景和背景特征,以指导多级特征融合和关键特征增强,进一步区分要分割的实体。
最后,论文还提出了 Size-Aware 解码器来解决解码器的尺度奇异性。 它准确地定位图像中不同大小的实体,从而避免共现特征的错误学习。
2.4、贡献
对三个场景的五个医学图像数据集进行的广泛实验证明了论文的方法的最先进的性能,证明了其先进性和对各种医学图像分割场景的普遍适用性。
三、引言
3.1、引出背景
医学图像分割是医学成像领域的基石,为临床决策、治疗计划和疾病监测提供不可或缺的支持。近些年来,深度学习在医学图像分割领域已经展现去巨大的潜力,例如U-Net、U-Net++、PraNet、TGANet、CASF-Net等不断地提升分割性能。
3.2、引出挑战
在医学图像领域,不同场景的任务使用不同模态的图像,例如内窥镜图像、皮肤镜图像、数字扫描整体图像、幻灯片图像等。虽然现有的深度学习方法在医学图像分割方面取得了很大的突破,实现了精确分割仍然是一个挑战,主要来自两个方面:边界模糊和共现现象。一方面,与前景和背景之间边界清晰的自然图像相比,在医学图像中, 前景和背景往往是一种模糊的“软边界”。 这种模糊主要是由于病理组织与周围正常组织之间存在过渡区域,使得边界难以界定。 此外,在许多情况下,医学图像表现出光线差和对比度低,这进一步模糊了病理组织和正常组织之间的界限,增加了区分边界的难度。 另一方面,共现现象广泛存在于医学图像中。例如,在内窥镜息肉图像中,小息肉往往与大小相似的息肉同时出现。 这使得模型可以轻松学习某些与息肉本身无关的共现特征。而当病理组织单独出现时,模型常常无法准确预测。因此,论文提出了一个称为对比度驱动医学图像分割的通用框架来克服这些挑战。
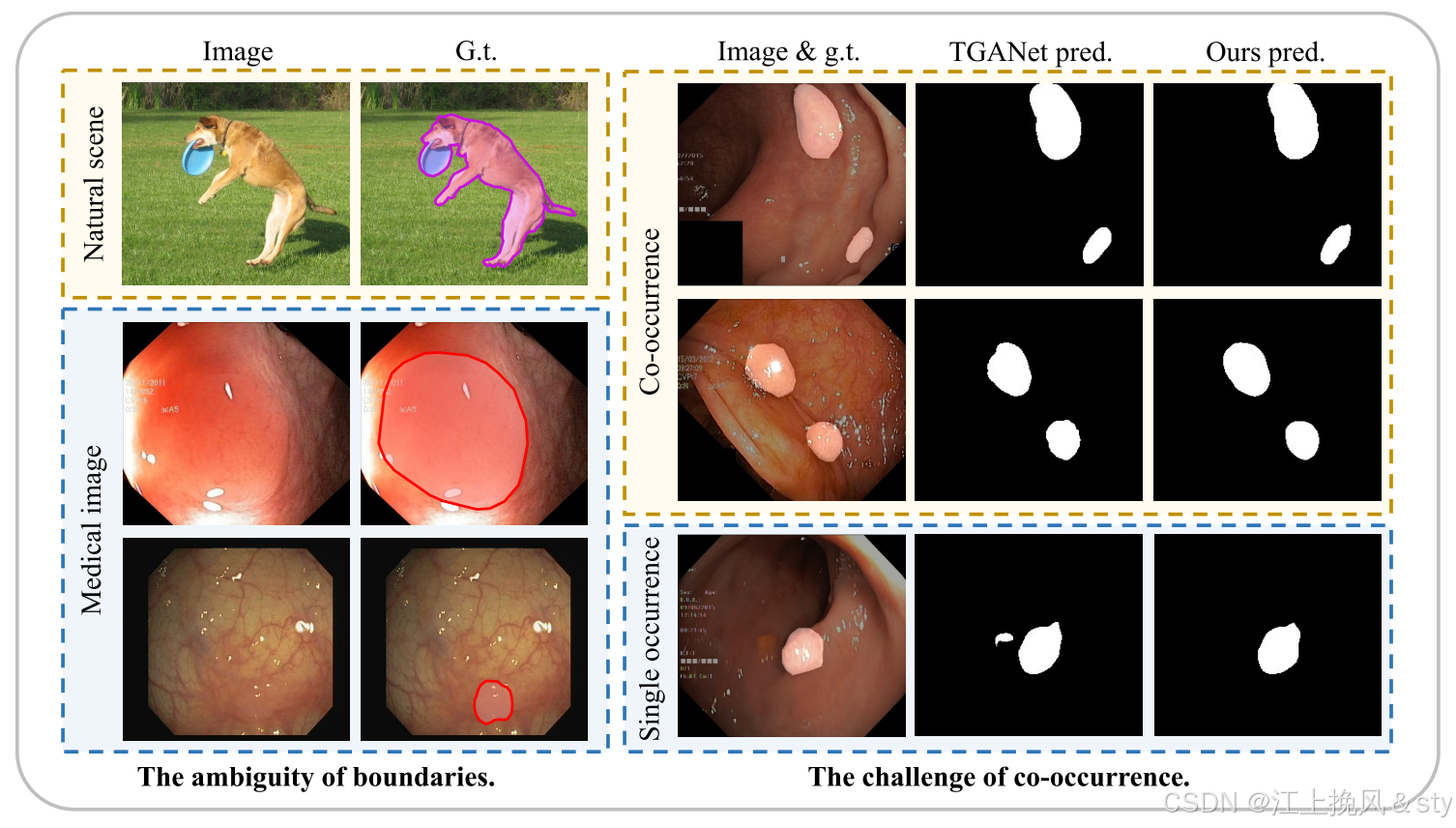
图1:医学图像分割主要挑战
3.3、研究概况
为了解决边界模糊带来的挑战,论文首先引入一种名为一致性强化(CR)的初步训练策略。 具体来说,论文向编码器提供原始图像和强增强图像,并使用编码器的输出分别预测掩模。 通过最大限度地提高这些掩模对之间的一致性,本文增强了编码器对涉及不同光照条件、颜色等的各种场景的鲁棒性,使其即使在不利的环境下也能提取高质量的特征。 随后,本文提出了语义信息解耦(SID)模块,它将特征图从编码器解耦为三个不同的:前景、背景和不确定区域。 在训练阶段,论文通过精心设计的损失函数增强前景和背景掩模的互补性和精度,从而促进不确定性区域的减少。
为了进一步强调前景和背景之间的区别并解决共现现象带来的挑战,论文提出了对比度驱动特征聚合(CDFA)模块。 CDFA从SID接收前景和背景特征,指导多级特征融合并在其对比信息下增强关键特征。 此外,本文提出了 Size-Aware Decoder 来解决预测掩模时解码器的尺度奇异性问题, 负责不同尺寸的SA-Decoder分别接收来自不同级别的特征图来预测不同尺寸的实体,从而促进模型区分同一图像中不同实体的能力,并防止错误学习共现特征。
3.4、贡献总结
-
本文提出的CR初步训练策略可以有效提高编码器对恶劣环境的鲁棒性,从而提取高质量的特征。 另一方面,SID 可以将特征图解耦为前景、背景和不确定性区域,并通过专门设计的损失函数学习减少训练过程中的不确定性。
-
本文提出的 CDFA 通过 SID 提取的对比特征来指导多级特征的融合和增强。 SA-Decoder旨在更好地区分图像中的不同实体,并对不同大小的实体进行单独预测,克服共现特征的干扰。
-
本文对五个医学图像数据集进行了广泛的比较和消融实验,涵盖了三种模式下的任务。 我们的 ConDSeg 在所有数据集上都实现了最先进的性能。
四、相关工作
医学图像自动分割一直是医学图像领域的研究热点之一。U-Net基于Encoder-Decoder架构,创新性地利用跳跃连接来组合浅层和深层特征,解决了下采样导致的细粒度信息丢失问题。 在此基础上,U-Net++和ResUNet因其在医学图像分割方面的增强性能而受到广泛认可。 最近的研究主要集中在通过改进 EncoderDecoder 架构中的各个模块或引入辅助监督任务来增强模型性能。 CPFNet通过结合全局金字塔引导模块和尺度感知金字塔融合模块来融合全局/多尺度上下文信息。PraNet通过并行部分解码器和反向注意模块合并边缘特征,逐步扩展对象区域。 TGANet通过引入文本标签的监督来引导模型学习额外的特征表示。 Swin-Unet 、TransUNet 、XBoundFormer 通过使用 Transformer Encoder 的各种变体来增强性能。
在医学图像中,前景(如息肉、腺体、病变等)和背景往往没有清晰的边界,而是有“软边界”。 此外,由于物理限制和内部组织的复杂反射特性,图像中的照明条件和对比度通常受到限制。 近年来,人们采取了许多方法来克服这一挑战。 SFA引入了一个用于边界预测的附加解码器,并采用边界敏感损失函数来利用区域边界关系。 BCNet提出了一种双边边界提取模块,该模块结合了浅层上下文特征、高级位置特征和额外的息肉边界监督来捕获边界。 CFA-Net设计了一个边界预测网络来生成边界感知特征,这些特征使用分层策略合并到分割网络中。 MEGANet提出了一种边缘引导注意模块,该模块使用拉普拉斯算子来强调边界。 虽然这些方法通过明确引入与边界相关的监督来提高模型对边界的关注,但它们并没有从根本上增强模型自发减少模糊区域不确定性的能力。 因此,在恶劣的环境下,这些方法的鲁棒性较弱,对模型的性能提升有限。 此外,共现现象是医学图像分割中一个容易被忽视的挑战。 与自然场景中随机出现的物体不同,医学图像中的器官和组织表现出高度的固定性和规律性,因此共现现象广泛存在。 例如,在结肠镜检查图像中,较小的息肉通常同时出现多个,而较大的息肉经常在其附近伴随有较小的息肉。这导致现有模型在训练过程中可能过度依赖这些上下文关联,而不是息肉本身的特征。 当出现单个息肉时,模型通常倾向于预测多个息肉。 这正是由于模型未能学会准确区分前景和背景以及图像中的不同实体。
五、具体方法
5.1、网络架构
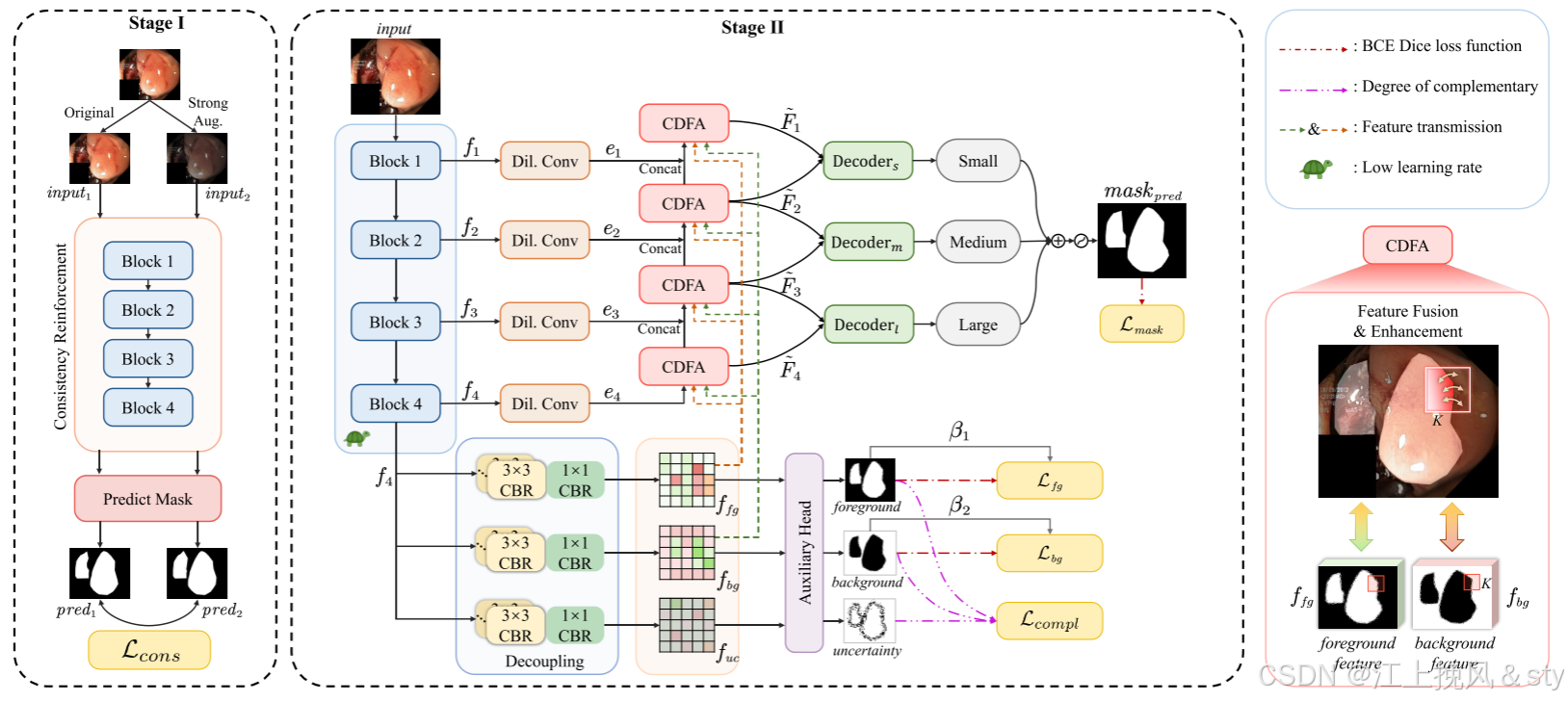
图2:网络架构图
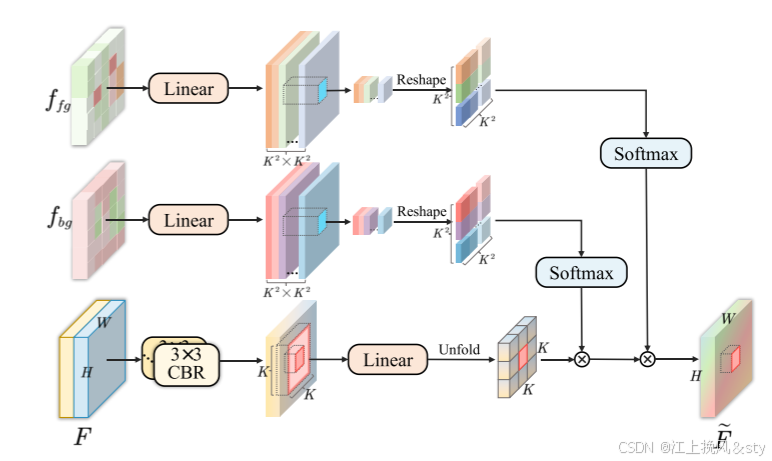
图3:CDFA的结构图
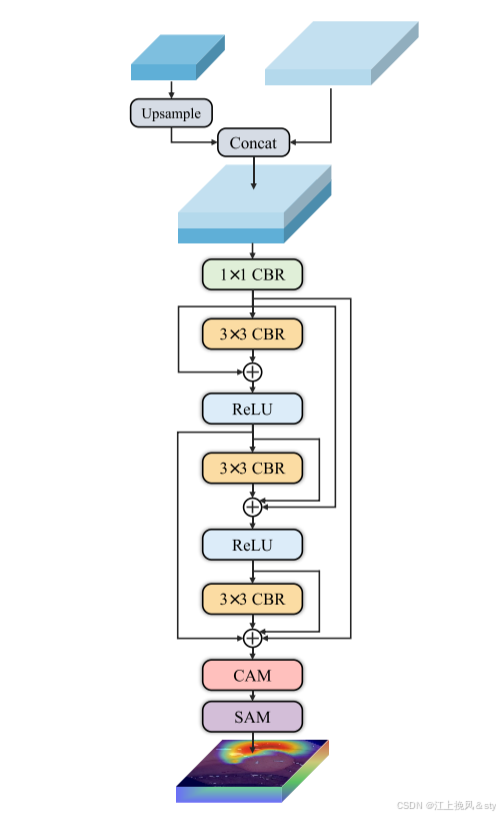
图4:Size-Aware 解码器结构图
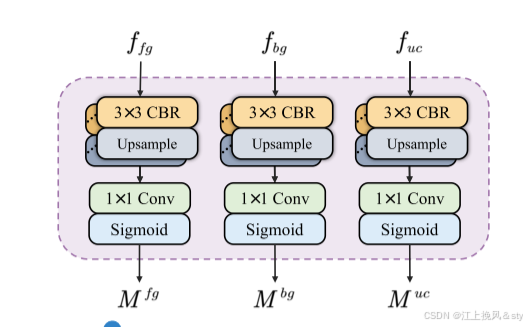
图5:SID辅助头结构图
ConDSeg 是一个两级架构。在第一阶段,本文引入一致性强化策略对Encoder进行初步训练,迫使Encoder块增强针对弱光照、低对比度等不利条件的鲁棒性,确保在各种场景下有效提取高质量特征。 在第二阶段,将编码器的学习率设置为较低水平以进行微调。 整个ConDSeg网络可以分为四个步骤:1)ResNet-50编码器提取特征图到
,在不同级别具有不同的语义信息。 2)携带深层语义信息的特征图f4被输入语义信息解耦(SID),以解耦为富含前景、背景和不确定区域信息的特征图
、
、
。 3)特征图
到
被发送到对比度驱动特征聚合(CDFA)模块,促进在
和
引导下的多级特征图的逐步融合,并增强前景和背景特征的表示。 4) 解码器、
和
各自在特定级别接收来自 CDFA 的输出,以按大小定位图像内的多个实体。 每个解码器的输出被融合以产生最终的掩模。
5.2、边界模糊改善
为了克服边界模糊的挑战,提出了一致性强化策略和语义信息解耦模块。
5.2.1、一致性强化
编码器以其特征提取能力和鲁棒性支撑整个模型的性能。 因此,在第一阶段,本文的目标是最大化编码器的特征提取能力及其在弱光照和低对比度场景下的鲁棒性。 为了实现这一点,本文将编码器与整个网络隔离,并为其设计一个预测头。 本文确保该预测头的结构尽可能简单,以避免在编码器块之外提供具有特征提取能力的额外结构,从而尽可能优化编码器性能。 论文将第一阶段的初始训练网络称为 。 对于输入图像X,一方面,直接将其送入
; 另一方面,X被强烈增强以获得X',然后将其送入
。 这些增强方法包括随机改变亮度、对比度、饱和度和色调,随机转换为灰度图像以及添加高斯模糊。 通过这种方式,本文模拟了医学成像中的可变环境,例如弱照明、低对比度和模糊。 这个过程可以表示如下:
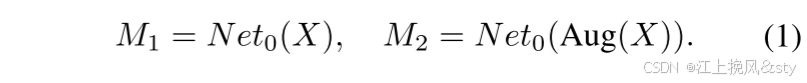
这里,Aug(·)代表强增广操作。 和
分别表示使用原始图像和强增强图像的预测。 对于
和
来说,不仅需要它们逼近ground truth,还需要最大化它们的相似度。 这保证了Encoder在特征提取方面的鲁棒性,即对于相同的内容,预测的mask在任何条件下都应该是一致的,并且不应该受到光照、对比度等变化的影响。
为此,一方面,本文联合使用 Binary CrossEntropy (BCE) Loss 和 Dice Loss 来约束 和
:
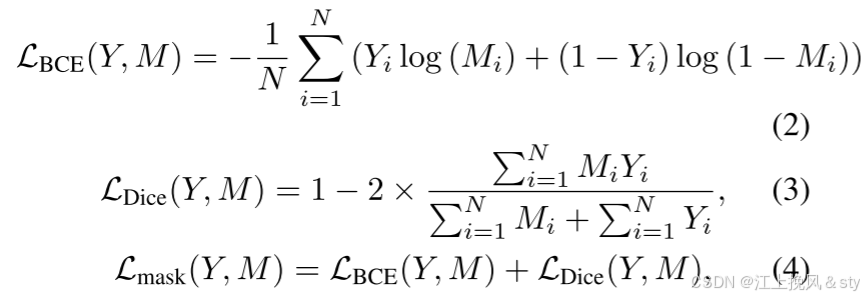
其中i表示所有像素的索引,是预测值,
是真实标签。 N表示像素总数。通过BCE Dice Loss,本文既考虑了像素级的预测精度,又考虑了分割任务中的类不平衡问题。 另一方面,本文设计了一种新颖的一致性损失,以在训练过程中最大化
和
之间的相似性。 在量化模型输出的一致性时,KL散度、JS散度等传统方法通常从概率分布的角度来衡量相似性。 这些方法在理论上具有明显的统计意义,但在实际应用中可能会遇到数值不稳定的情况,特别是当预测概率接近 0 或 1 时。这些极值处的对数函数可能会导致数值问题,这在处理大量数据时尤其重要。 数据。 相比之下,本文提出的一致性损失
是基于像素级分类精度设计的,使用简单的二值化操作和二元交叉熵(BCE)损失计算,直接比较预测掩模
和
之间的像素级差异。 这使得计算更简单并避免数值不稳定,使其对于大规模数据更加鲁棒。 具体来说,本文交替二值化
和
之一作为参考,并用另一个计算BCE Loss。 首先,定义二值化操作的阈值t,二值化函数B(M,t)定义为:
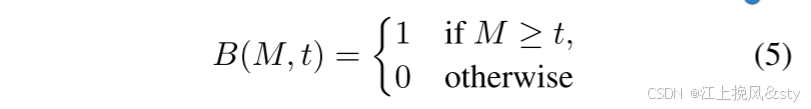
一致性损失由以下公式给出,计算以
为参考的
的BCE Loss和以
为参考的
的BCE Loss的平均值:
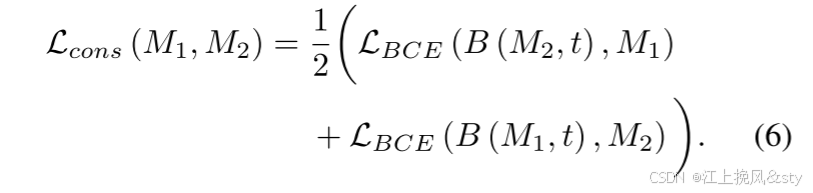
最后,第一阶段的总损失如下:
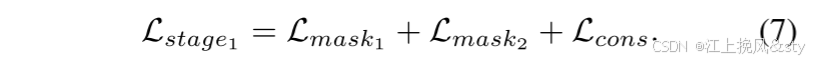
5.2.2、语义信息解耦
语义信息解耦(SID)模块旨在将编码器输出的高级特征图解耦为三个特征图,分别富含前景、背景和不确定区域的信息。 通过损失函数的约束,鼓励 SID 学习减少不确定性,从而精确区分前景和背景。
SID 以三个并行分支开始,每个分支由多个 CBR 块组成。 来自Encoder的特征图f4被输入到这三个分支中,得到三个具有不同语义信息的特征图、
、
,分别用前景、背景和不确定区域特征进行丰富。 然后,辅助头对这三个特征图进行预测,以生成前景 (
)、背景 (
) 和不确定区域 (
) 的掩模。 理想情况下,这三个掩模的每个像素的值应该是明确的0或1,表明该像素所属的类别是确定的。 此外,三个特征图应表现出互补关系,即对于任何像素索引 i,三个掩模
、
和
应满足:
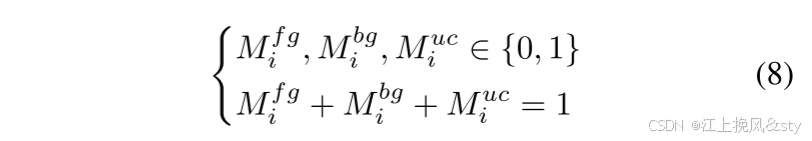
因此,本文的优化目标是 和
分别逼近真实值 Y 及其否定值 (1 − Y)。 同时,
、
和
应大致满足前述互补性。
一方面,我们使用 BCE Dice 损失(表示为 和
)针对真实标签优化
和
。 此外,考虑到小尺寸实体占用的像素很少,因此其预测精度对整体损失影响较小,我们设计了一对动态惩罚项
、
:
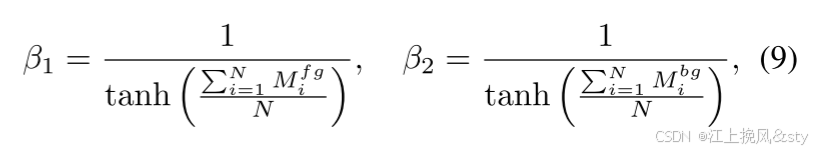
其中N表示像素总数,i是所有像素的索引,范围从1到N。本质上,和
是根据预测结果的面积比计算的惩罚项,旨在更多地关注具有以下特征的实体: 损失函数中的区域更小,从而提高了损失函数的稳定性。 因此,加入惩罚项后,
和
转化为
和
。
另一方面,考虑到辅助头的输出、
和
实际上是概率分布,我们设计了一个简单而有效的损失函数来量化它们的互补程度:
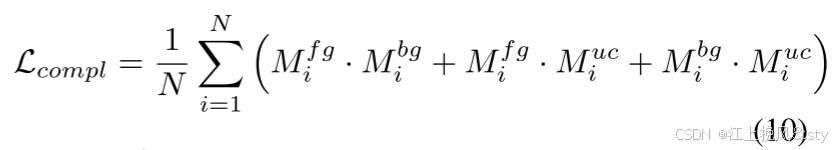
这里, 、
和
分别表示第i个像素被预测为前景、背景和不确定区域的概率。 这一表述为 SID 的预测提供了直接有效的约束。 通过用像素总数对损失进行归一化,使损失函数的尺度与输入图像大小无关,使其值始终保持在[0, 1]范围内,从而充分保证了训练的稳定性。
总体而言,增强了三个分支的预测结果的互补性,确保每个像素都被分类为仅属于前景、背景或不确定区域之一。 此外,
和
用于约束前景和背景分支的准确性。在训练过程中通过这些约束,模型逐渐减少不确定性区域,并增强特征图
和
中前景和背景的突出程度。
5.3、克服共现现象
共现现象在医学成像中广泛存在,这通常会导致模型学习错误的模式,从而降低其性能。 图 6 显示了 TGANet与本文的方法在 Kvasir-SEG 数据集的几个示例上的直观比较。 对于这两者,我们利用 Grad-CAM 来可视化输出层附近的卷积层,直观地展示模型的焦点。 对于同时发生的息肉,两种模型都能实现准确定位。 然而,当息肉单独出现时,TGANet 往往会错误地预测多个息肉。 相反,本文的方法避免了共现现象的误导性影响。 当单个息肉出现时,它仍然能够准确识别和分割。 在本文的框架中,通过专门设计的对比度驱动特征聚合模块和大小感知解码器克服了共现现象。
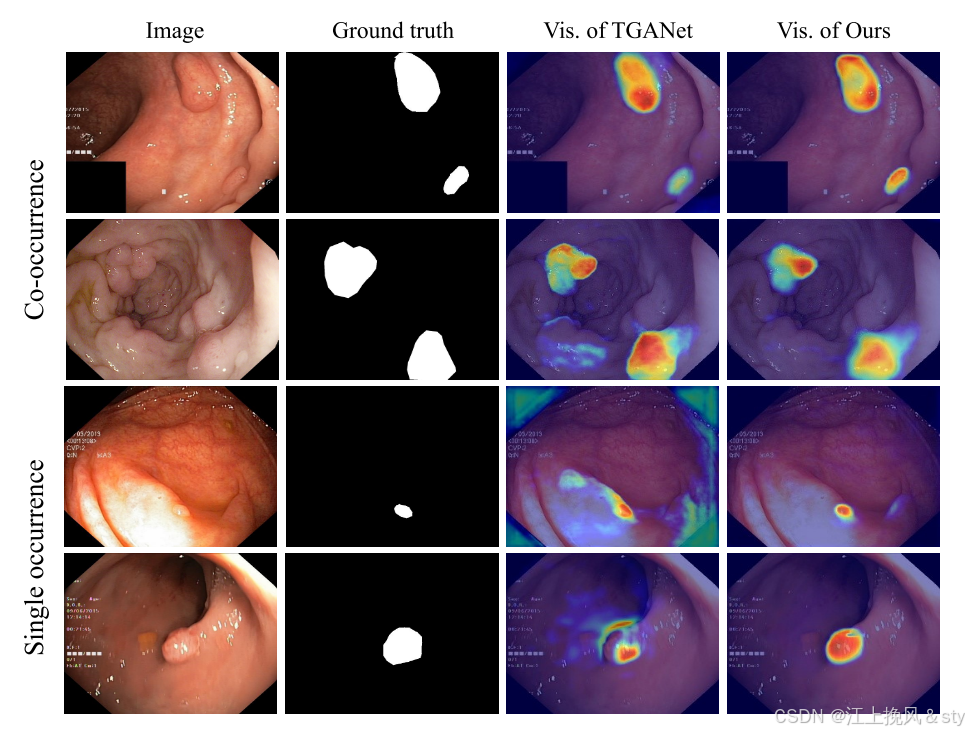
图6:不同方法的 Grad-CAM 可视化
5.3.1、对比驱动的特征聚合
对比度驱动特征聚合(CDFA)模块旨在利用SID解耦的前景和背景的对比特征来指导多级特征融合。 此外,它有助于模型更好地区分待分割的实体和复杂的背景环境。 具体来说,从Encoder块输出的到
首先通过一组扩张卷积层进行预增强以获得
到
。 随后,CDFA 在对比特征(
、
)的指导下实现多级特征融合。
一方面,上一级的输出和横向特征图(即 , i = 1, 2, 3, 4)沿通道方向连接形成 F 。 然后将F输入CDFA(
除外,它直接输入CDFA)。 另一方面,在输入 CDFA 之前,通过卷积层和双线性上采样调整
和
以匹配 F 的维度。
图3显示了CDFA的结构。 和
均源自深层特征的解耦,其中每个空间位置的特征都具有足够的代表性,足以生成用于局部聚合相邻特征的注意力权重。 在每个空间位置 (i, j),CDFA 通过合并前景和背景的细节来计算以 (i, j) 为中心的 K×K 窗口内的注意力权重。 具体来说,给定输入特征图
,首先通过多个 CBR 块进行初步融合。 随后,这个C维特征向量通过线性层权重
映射到值向量
。 然后将值向量 V 展开在每个局部窗口上,准备聚合每个位置的邻域信息。 设
表示以 (i, j) 为中心的局部窗口内的所有值,定义为:
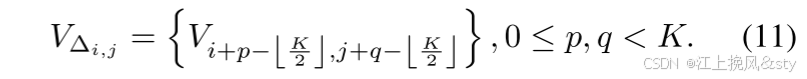
然后通过两个不同的线性层处理前景和背景特征图(和
),以生成相应的注意力权重
和
。 注意力权重的计算可以表示为:
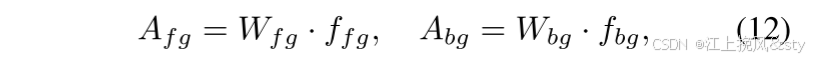
其中 和
分别是前景和背景特征图的线性变换权重矩阵。 随后,位置(i,j)处的前景和背景注意力权重被重塑为
和
,并且它们都由 Softmax 函数激活。 然后,展开的值向量
分两步加权:
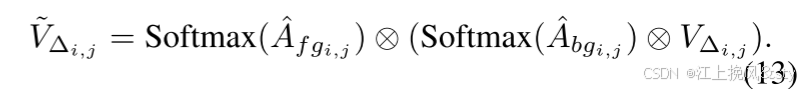
这里,⊗表示矩阵乘法。 最后,将加权值表示进行密集聚合以获得最终输出特征图。 具体来说,位置 (i, j) 处的聚合特征为:
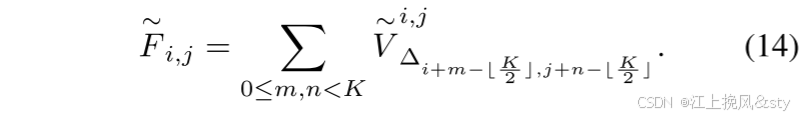
5.3.2、尺寸感知解码器
本文设计了一个简单但有效的大小感知解码器(SA-Decoder),其结构在图4有详细介绍。 SA-Decoder通过将不同大小的实体分布在不同的层中来实现单独的预测。 在多个CDFA输出的特征中,浅层特征图包含更细粒度的信息,使其适合预测较小尺寸的实体。 随着层数的加深,特征图包含了越来越多的全局信息和更高层次的语义,使它们更适合预测更大尺寸的实体。
因此,我们针对小、中、大尺寸建立了三个解码器:、
和
,每个解码器分别接收来自两个相邻CDFA的特征,即
和
、
和
、
和
。 然后,三个解码器的输出沿着通道维度连接并融合。 然后通过 Sigmoid 函数生成预测掩模。 通过多个并行SA解码器的协同工作,ConDSeg能够准确地区分不同体型的个体。 该模型既能够精确分割大实体,又能够精确定位小实体。
5.3.3、整体优化及训练流程
ConDSeg 的培训分为两个阶段。 第一阶段的重点是增强编码器的特征提取能力及其对不利条件的鲁棒性。 第二阶段,将Encoder的学习率设置在较低的水平,并对整个模型进行优化。 形式上,如下:
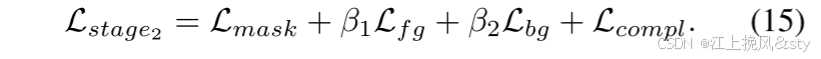
六、实验过程
6.1、实验装置
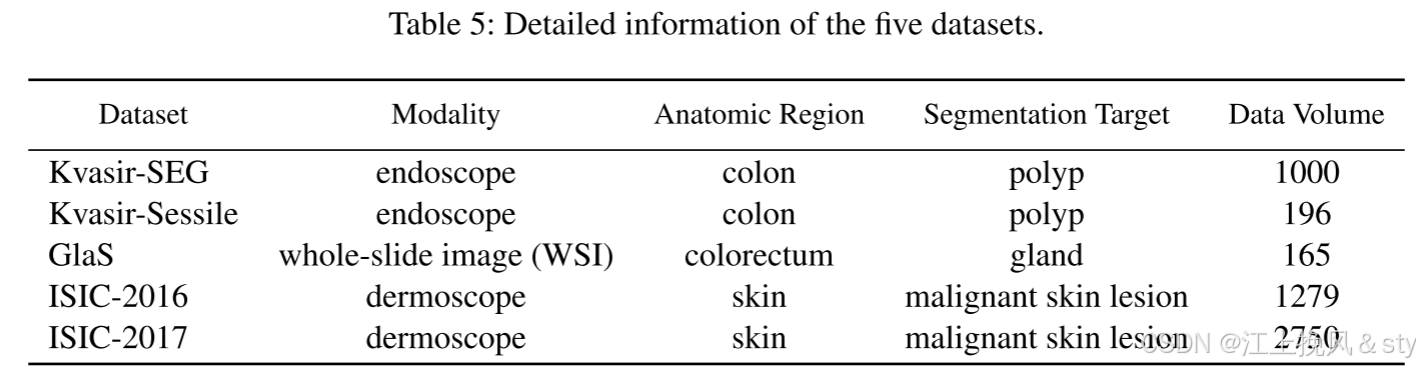
数据集:Kvasir-SEG、Kvasir-Sessile、GlaS、ISIC-2016、ISIC-2017
实验器材:
| GPU | NVIDIA GeForce RTX 4090 GPU |
| 图像大小 | 256 × 256 |
| 数据增强 | 随机旋转、垂直翻转、水平翻转 |
| batch_size | 4 |
| 优化器 | Adam |
| Encoder | ResNet-50 |
| 第一阶段learning_rate | 1e-4 |
| 第二阶段learning_rate | 1e-5 |
| 其余阶段learning_rate | 1e-4 |
| CDFA 的窗口大小 | 3 |
医学图像分割指标:平均交并集 (mIoU)、平均 Sørensen-Dice 系数 (mDSC)、召回率和精度。
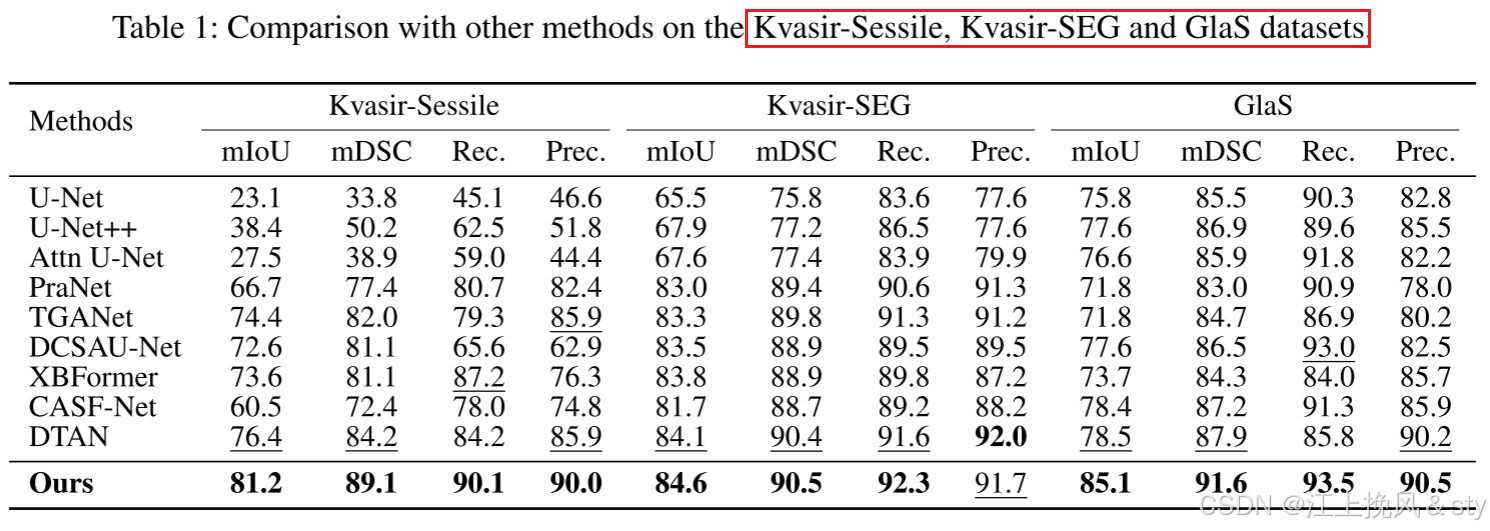
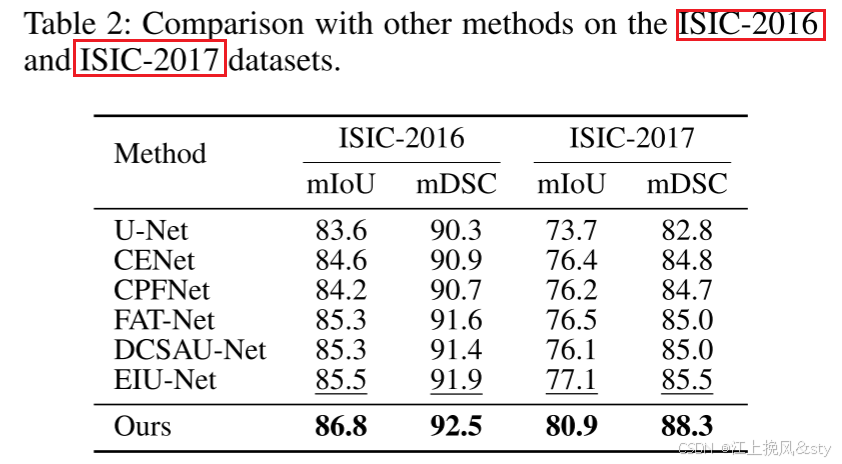
6.2、SOTA对比
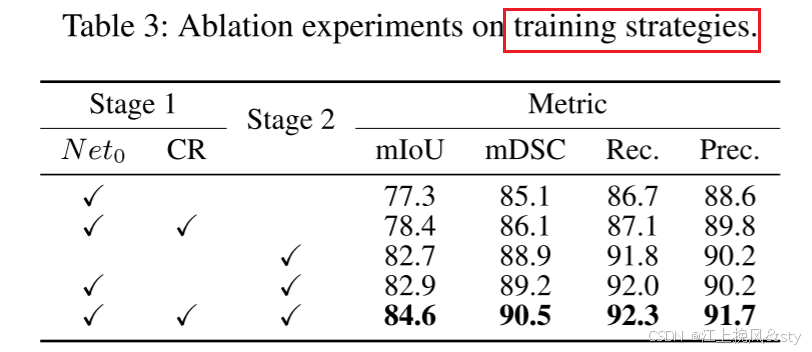
6.3、消融实验
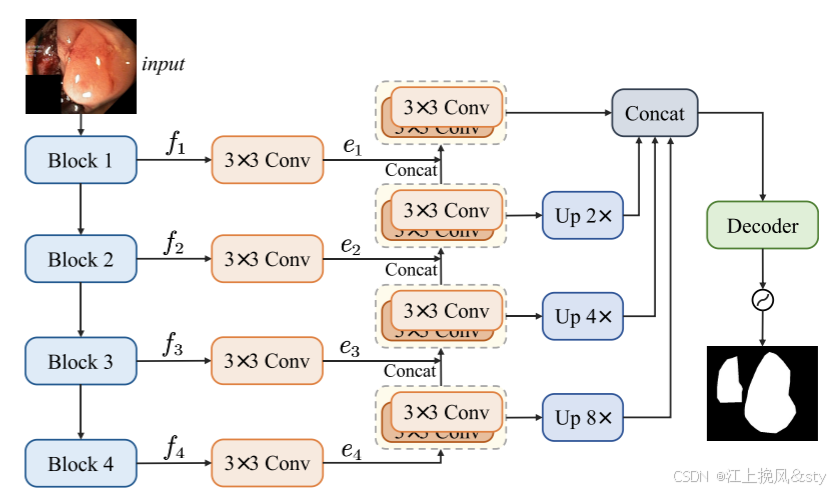
图7:消融实验基线结构图

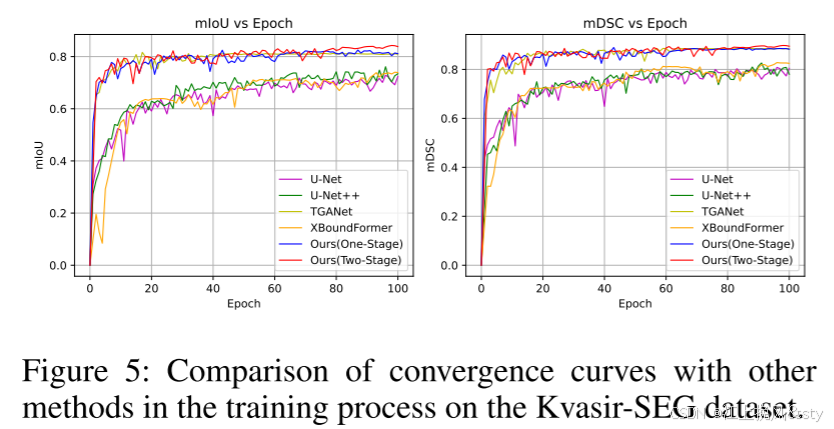
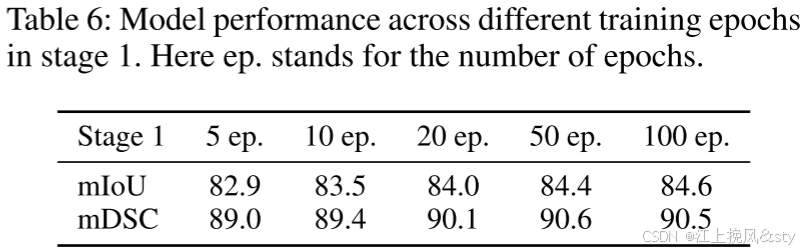
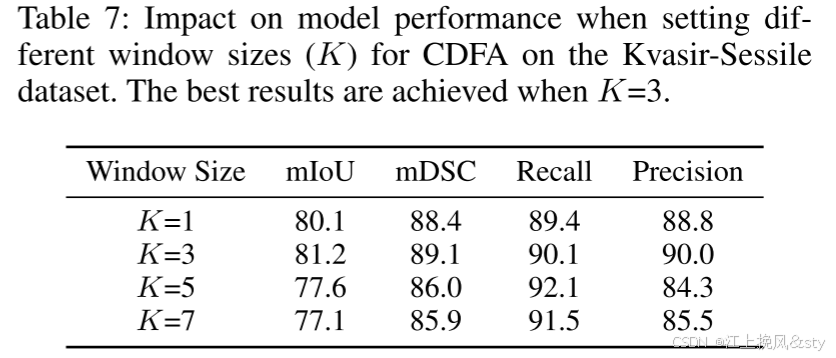

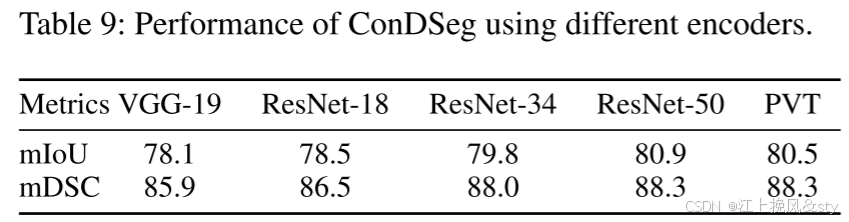
6.4、实验效果
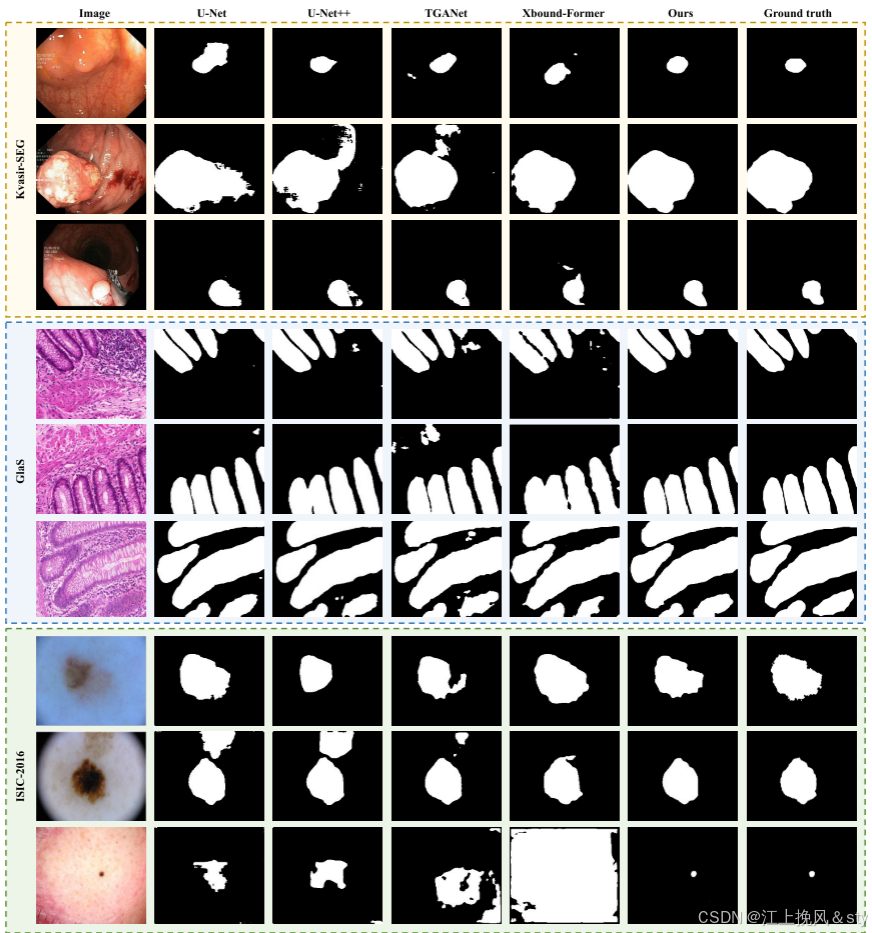
图4:可视化展示图
七、总结
本文提出了一种通用的医学图像分割框架 ConDSeg,它减轻了医学成像中广泛存在的软边界和共现现象所带来的挑战。 对于与边界模糊、光照差和对比度低相关的问题,本文的初步训练策略“一致性强化”专门旨在增强编码器对不利条件的鲁棒性。 此外,本文设计了语义信息解耦模块,将编码器中的特征解耦为前景、背景和不确定性区域三个部分,逐渐获得在训练过程中减少不确定性的能力。 为了解决共现的挑战,对比驱动特征聚合模块使用前景和背景信息来指导多级特征图的融合并增强关键特征,有利于模型进一步区分前景和背景。 此外,本文引入了尺寸感知解码器来实现图像中不同尺寸的多个实体的精确定位。 在五个广泛使用的各种模式的医学图像分割数据集中,本文的 ConDSeg 实现了最先进的性能,验证了我们框架的先进性和通用性。