这是我的第375篇原创文章。
一、引言
dify工作流或者对话助手中编排里的代码执行节点是走sandbox,但是sandbox中环境中的第三方包有限,安装多了会导致包版本冲突,我们可以曲线救国,利用dify本身环境自带的第三方包开发一个工具,然后在工作流中调用这个工具。本文将结合一个具体的案例来实现。
二、实现过程
2.1 准备工具供应商 yaml
这个 yaml 将包含工具供应商的信息,包括供应商名称、图标、作者等详细信息,以帮助前端灵活展示。我们需要在 core/tools/provider/builtin下创建一个smb模块(文件夹),并创建smb.yaml,名称必须与模块名称一致。后续,我们关于这个工具的所有操作都将在这个smb模块(文件夹)下进行。
k-means这样的工具,就不需要填写凭据字段,可以参考这里:api/core/tools/provider/builtin/wikipedia/wikipedia.yaml。最终smb.yaml文件如下:
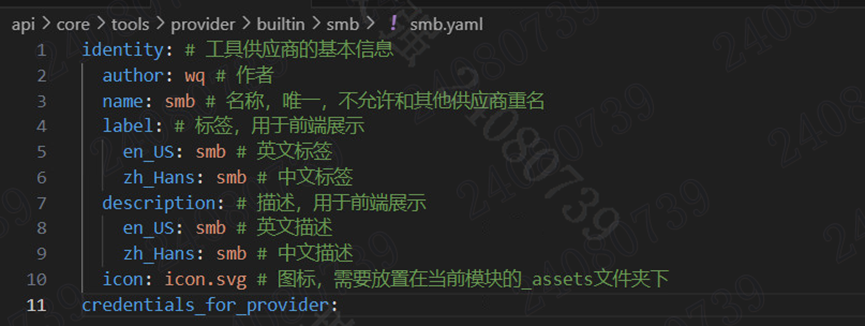
图标需要放置在当前模块的_assets文件夹下,参考这里:api/core/tools/provider/builtin/google/_assets/icon.svg。
2.2 准备工具 yaml
一个供应商底下可以有多个工具,每个工具都需要一个 yaml 文件来描述,这个文件包含了工具的基本信息、参数、输出等。仍然以 KmeansCluster 为例,我们需要在smb模块下创建一个tools模块,并创建tools/ kmeans_cluster.yaml,内容如下。
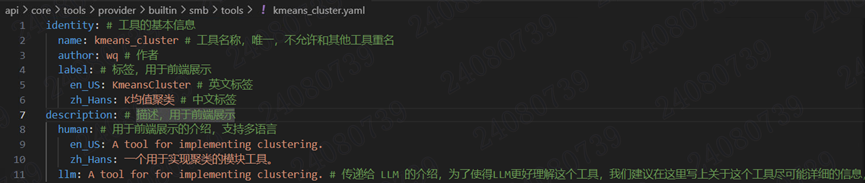
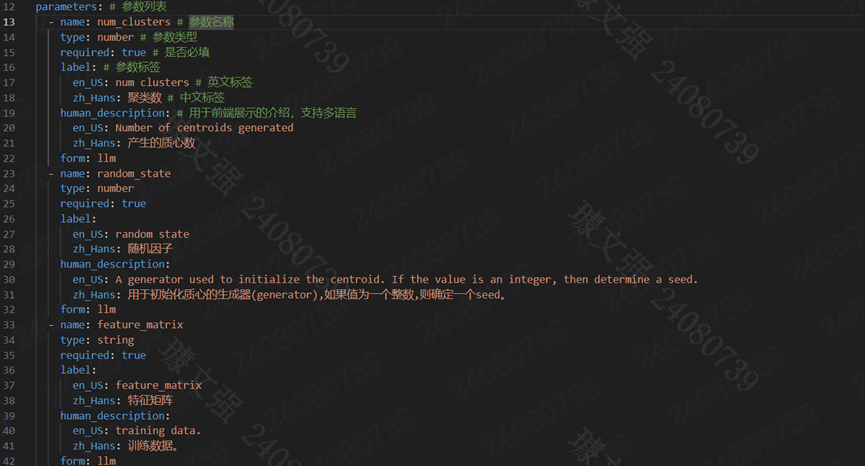
说明:
-
identity 字段是必须的,它包含了工具的基本信息,包括名称、作者、标签、描述等
-
parameters 参数列表
-
name 参数名称,唯一,不允许和其他参数重名
-
type 参数类型,目前支持string、number、boolean、select 四种类型,分别对应字符串、数字、布尔值、下拉框
-
required 是否必填
-
在llm模式下,如果参数为必填,则会要求 Agent 必须要推理出这个参数
-
在form模式下,如果参数为必填,则会要求用户在对话开始前在前端填写这个参数
-
-
options 参数选项
-
在llm模式下,Dify 会将所有选项传递给 LLM,LLM 可以根据这些选项进行推理
-
在form模式下,type为select时,前端会展示这些选项
-
-
default 默认值
-
label 参数标签,用于前端展示
-
human_description 用于前端展示的介绍,支持多语言
-
llm_description 传递给 LLM 的介绍,为了使得 LLM 更好理解这个参数,我们建议在这里写上关于这个参数尽可能详细的信息,让 LLM 能够理解这个参数
-
form 表单类型,目前支持llm、form两种类型,分别对应 Agent 自行推理和前端填写
-
2.3 准备工具代码
当完成工具的配置以后,我们就可以开始编写工具代码了,主要用于实现工具的逻辑。在smb/tools模块下创建google_search.py,内容如下
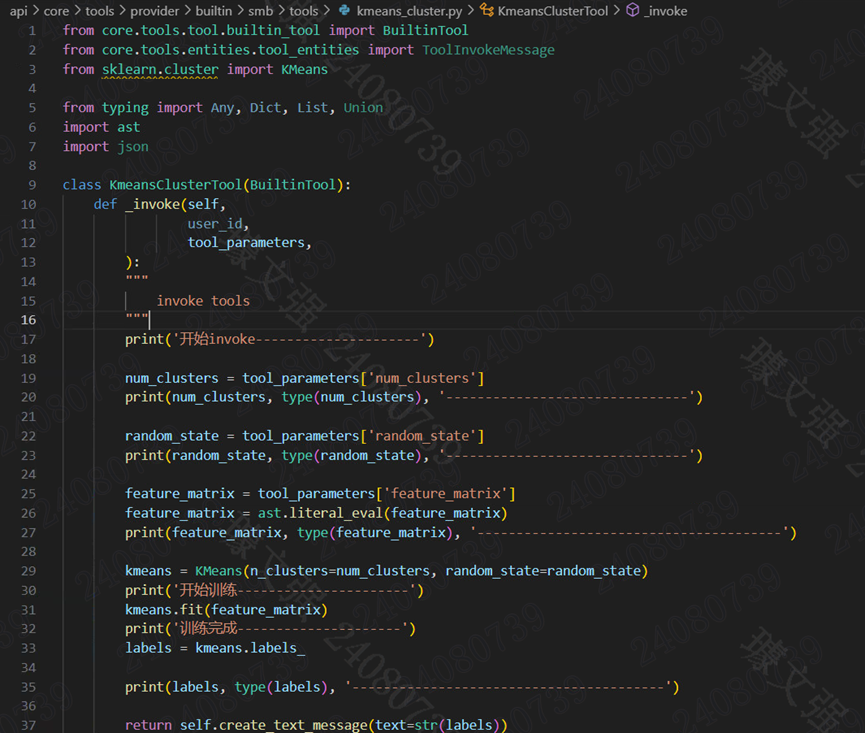
参数:工具的整体逻辑都在_invoke方法中,这个方法接收两个参数:user_id和tool_Parameters,分别表示用户 ID 和工具参数
返回数据:在工具返回时,你可以选择返回一个消息或者多个消息,这里我们返回一个消息,使用create_text_message和create_link_message可以创建一个文本消息或者一个链接消息。
2.4 准备供应商代码
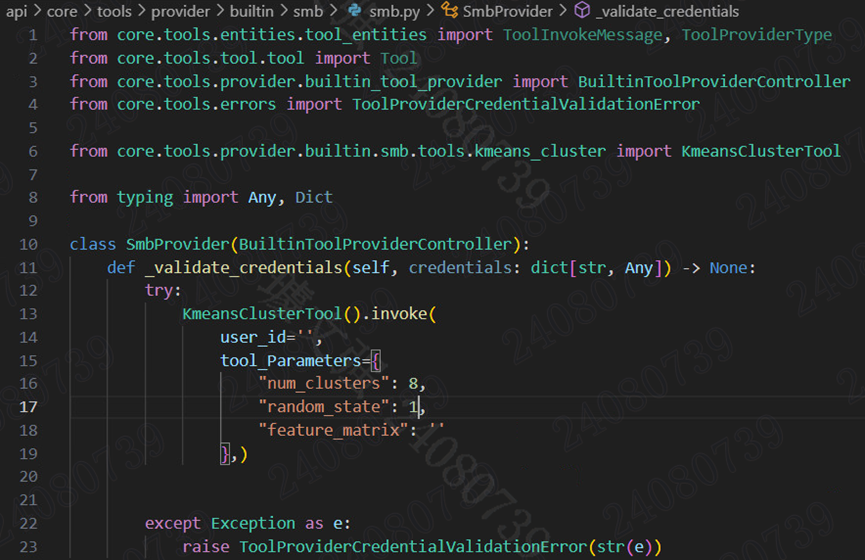
最后,我们需要在供应商模块下创建一个供应商类,用于实现供应商的凭据验证逻辑,如果凭据验证失败,将会抛出ToolProviderCredentialValidationError异常。在google模块下创建google.py,内容如下。
三、结果
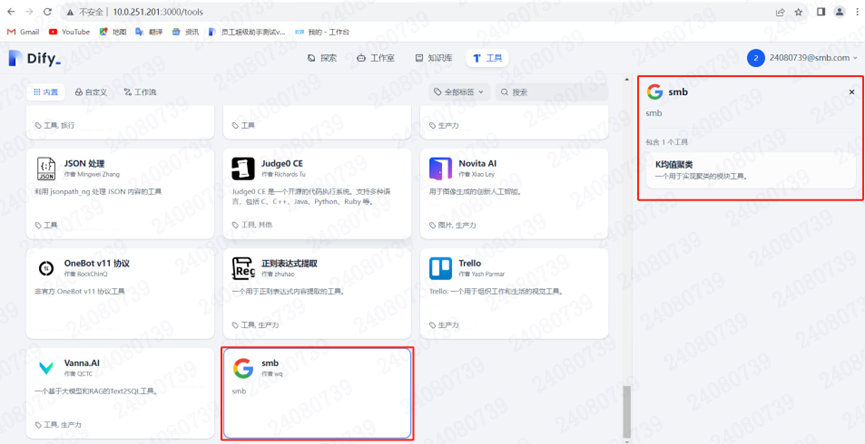
当上述步骤完成以后,我们就可以在前端看到这个工具了:
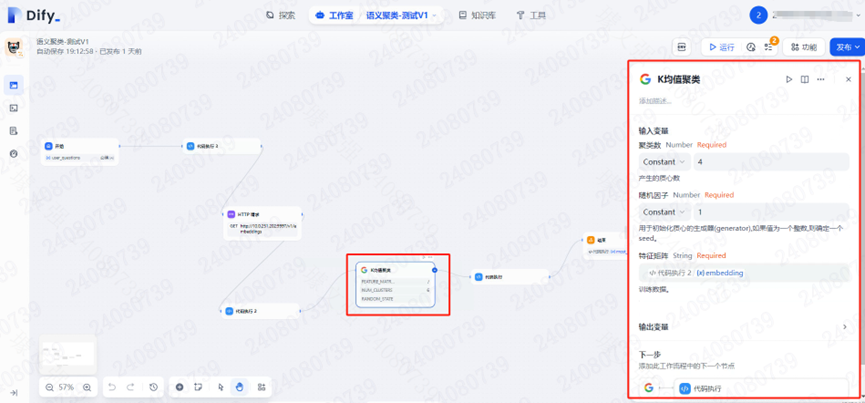
并且可以在 Agent 或工作流中使用这个工具:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。