这是我的第400篇原创文章。
一、引言
LSTM 是一种特殊的循环神经网络(RNN),设计目的是解决普通 RNN 在长序列中梯度消失或梯度爆炸的问题。Transformer 模型最初用于自然语言处理,但其基于自注意力(Self-Attention)的机制非常适合捕捉长距离依赖,因此近年来也被广泛应用于时间序列预测。在实际应用中,将 LSTM 和 Transformer 融合的做法,充分发挥二者在捕捉局部时序特征(LSTM)和全局依赖关系(Transformer)方面的优势。本文以一个完整的案例讲解两者融合建模的完整流程。
二、实现过程
2.1 数据读取部分
代码:
# 读取数据集
num_total_days = 144
data = pd.read_csv('data.csv')
# 将日期列转换为日期时间类型
data['Month'] = pd.to_datetime(data['Month'])
# 将日期列设置为索引
data.set_index('Month', inplace=True)
print(data)
passengers_data = np.array(data['Passengers'])data:
2.2 数据预处理部分
代码:
# 定义输入和输出窗口长度
input_window = 30# 使用过去 30 天数据作为输入
output_window = 7# 预测未来 7 天乘客
# 划分训练集和测试集,采用 80% 训练、20% 测试
split_ratio = 0.8
dataset = PassengersDataset(passengers_data, input_window, output_window)
train_size = int(len(dataset) * split_ratio)
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
# 创建 DataLoader
batch_size = 12
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)利用滑动窗口方法构造样本,设置过去 30 天作为输入、未来 7 天作为输出,构建了 PyTorch 数据集,并将数据集划分为训练集和测试集。
2.3 模型构建部分
Hybrid Model (LSTM + Transformer):
class PositionalEncoding(nn.Module):
"""
位置编码模块,用于 Transformer 分支
采用正弦和余弦函数构造位置编码,保证模型能够捕捉序列中各个位置的信息
"""
def __init__(self, d_model, dropout=0.1, max_len=500):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 创建位置编码矩阵,形状为 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 根据公式计算位置编码中每个维度的值
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度
pe = pe.unsqueeze(0) # 添加 batch 维度,形状变为 (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
"""
:param x: 输入张量,形状为 (batch, seq_len, d_model)
:return: 加入位置编码后的张量
"""
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
class HybridModel(nn.Module):
"""
混合模型:结合 LSTM 分支和 Transformer 分支进行特征提取,最后通过全连接层预测未来 output_window 天气温
"""
def __init__(self, input_window, output_window, lstm_hidden_dim=64, transformer_dim=64, num_transformer_layers=2):
"""
:param input_window: 输入序列长度
:param output_window: 输出序列长度
:param lstm_hidden_dim: LSTM 隐藏层维度
:param transformer_dim: Transformer 嵌入维度
:param num_transformer_layers: Transformer 编码器层数
"""
super(HybridModel, self).__init__()
# LSTM 分支:输入维度 1,输出隐藏状态维度 lstm_hidden_dim
self.lstm = nn.LSTM(input_size=1, hidden_size=lstm_hidden_dim, num_layers=1, batch_first=True)
# Transformer 分支:首先通过线性层将 1 维输入映射到 transformer_dim 维度
self.transformer_input = nn.Linear(1, transformer_dim)
self.positional_encoding = PositionalEncoding(d_model=transformer_dim, dropout=0.1, max_len=input_window)
# 定义 Transformer 编码器层,采用多头注意力(nhead=4)和残差连接
encoder_layer = nn.TransformerEncoderLayer(d_model=transformer_dim, nhead=4, dropout=0.1)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_transformer_layers)
# 全连接层:将 LSTM 和 Transformer 两个分支提取到的特征拼接后映射到 output_window 维度,即未来 7 天预测值
self.fc = nn.Linear(lstm_hidden_dim + transformer_dim, output_window)
def forward(self, x):
"""
:param x: 输入序列,形状 (batch, input_window, 1)
:return: 输出预测,形状 (batch, output_window)
"""
# LSTM 分支:获取最后时刻隐藏状态作为特征
lstm_out, (h_n, c_n) = self.lstm(x) # h_n 形状:(num_layers, batch, lstm_hidden_dim)
lstm_feature = h_n[-1] # 取最后一层隐藏状态,形状:(batch, lstm_hidden_dim)
# Transformer 分支:先将输入映射到 transformer 维度
transformer_input = self.transformer_input(x) # 形状:(batch, input_window, transformer_dim)
transformer_input = self.positional_encoding(transformer_input) # 添加位置编码
# Transformer 编码器要求输入形状为 (seq_len, batch, d_model)
transformer_input = transformer_input.transpose(0, 1) # 形状:(input_window, batch, transformer_dim)
transformer_out = self.transformer_encoder(transformer_input) # 输出形状不变
transformer_out = transformer_out.transpose(0, 1) # 转换回 (batch, input_window, transformer_dim)
# 采用全局平均池化,提取序列的整体信息,得到 transformer 分支特征
transformer_feature = transformer_out.mean(dim=1) # 形状:(batch, transformer_dim)
# 特征级联:拼接 LSTM 与 Transformer 两个分支提取到的特征
combined_feature = torch.cat([lstm_feature, transformer_feature],
dim=1) # 形状:(batch, lstm_hidden_dim+transformer_dim)
# 最后通过全连接层预测未来 output_window 天的
output = self.fc(combined_feature) # 形状:(batch, output_window)
return output模型构建:混合模型由两个分支构成:
LSTM 分支采用单层 LSTM 模型提取输入序列中局部时序特征,通过最后一个隐藏状态作为代表。
Transformer 分支则先利用线性映射将 1 维数据提升到高维空间,接着加入位置编码,再通过 Transformer 编码器提取全局依赖特征,最后采用全局平均池化。
最后,将两个分支得到的特征拼接后经过全连接层输出预测值。
2.4 模型训练
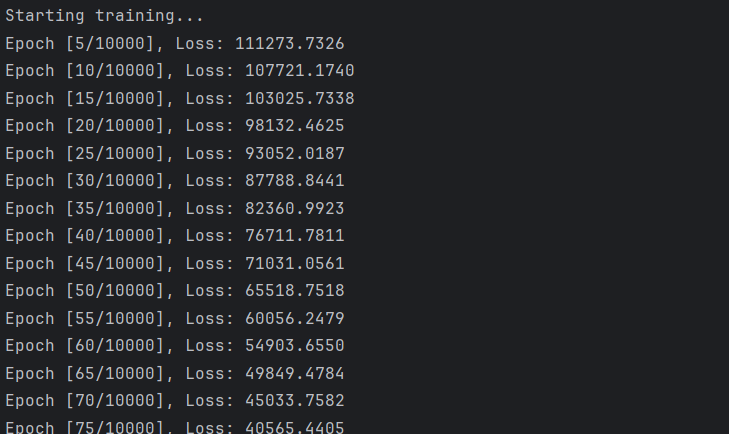
使用均方误差(MSE)作为损失函数,Adam 优化器对模型参数进行更新。训练过程中记录每个 epoch 的损失值,以观察模型是否逐步收敛。
# 定义模型超参数
lstm_hidden_dim = 64
transformer_dim = 64
num_transformer_layers = 2
learning_rate = 0.001
num_epochs = 10000# 为了演示,这里设置 50 轮;实际应用中可调节
# 实例化模型
model = HybridModel(input_window, output_window, lstm_hidden_dim, transformer_dim, num_transformer_layers)
# 若有 GPU 则使用 GPU 训练
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 记录每个 epoch 的训练损失,用于后续绘制训练曲线
train_losses = []
print("Starting training...")
for epoch in range(num_epochs):
model.train()
epoch_loss = 0.0
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device) # 输入形状:(batch, input_window, 1)
batch_y = batch_y.to(device) # 目标形状:(batch, output_window)
optimizer.zero_grad()
outputs = model(batch_x) # 输出形状:(batch, output_window)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
epoch_loss += loss.item() * batch_x.size(0)
epoch_loss /= len(train_loader.dataset)
train_losses.append(epoch_loss)
if (epoch + 1) % 5 == 0:
print("Epoch [{}/{}], Loss: {:.4f}".format(epoch + 1, num_epochs, epoch_loss))
print("Training finished.")结果:
2.5 模型测试
在测试集上进行预测后,我们选取了测试集中的一个样本,绘制了真实值与预测值的对比曲线,同时计算了预测误差,并绘制误差直方图。通过真实值与预测值的对比,可以直观评估模型在短期预测上的表现,而误差直方图则展示了预测偏差的分布情况。
model.eval()
predictions = []
true_values = []
with torch.no_grad():
for batch_x, batch_y in test_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
outputs = model(batch_x)
predictions.append(outputs.cpu().numpy())
true_values.append(batch_y.cpu().numpy())
predictions = np.concatenate(predictions, axis=0) # 形状:(num_samples, output_window)
true_values = np.concatenate(true_values, axis=0) # 形状:(num_samples, output_window)
# 为便于绘图,这里选取测试集中的第一个样本进行预测与真实值对比
sample_idx = 0
sample_pred = predictions[sample_idx] # 长度为 output_window
sample_true = true_values[sample_idx]
# 计算预测误差
errors = sample_pred - sample_true2.6 数据分析与可视化
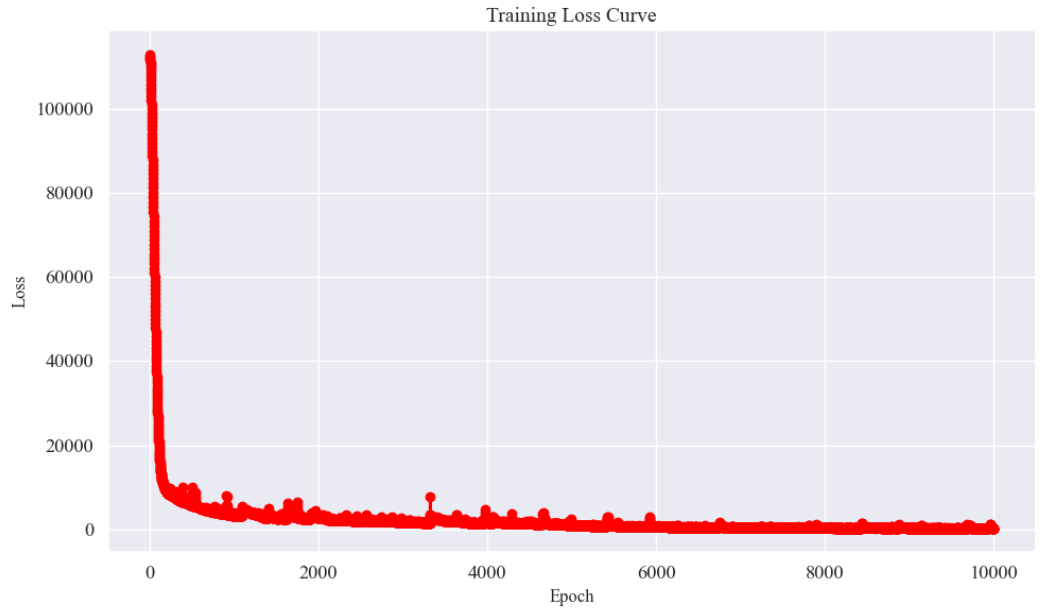
展示模型训练损失随 epoch 的变化,帮助判断模型收敛性。
plt.figure(figsize=(10, 6))
plt.plot(range(1, num_epochs + 1), train_losses, marker='o', color='red', linewidth=2)
plt.xlabel("Epoch", fontsize=12) # 英文标签
plt.ylabel("Loss", fontsize=12) # 英文标签
plt.title("Training Loss Curve", fontsize=14) # 英文标题
plt.grid(True)
plt.tight_layout()
plt.show()结果:
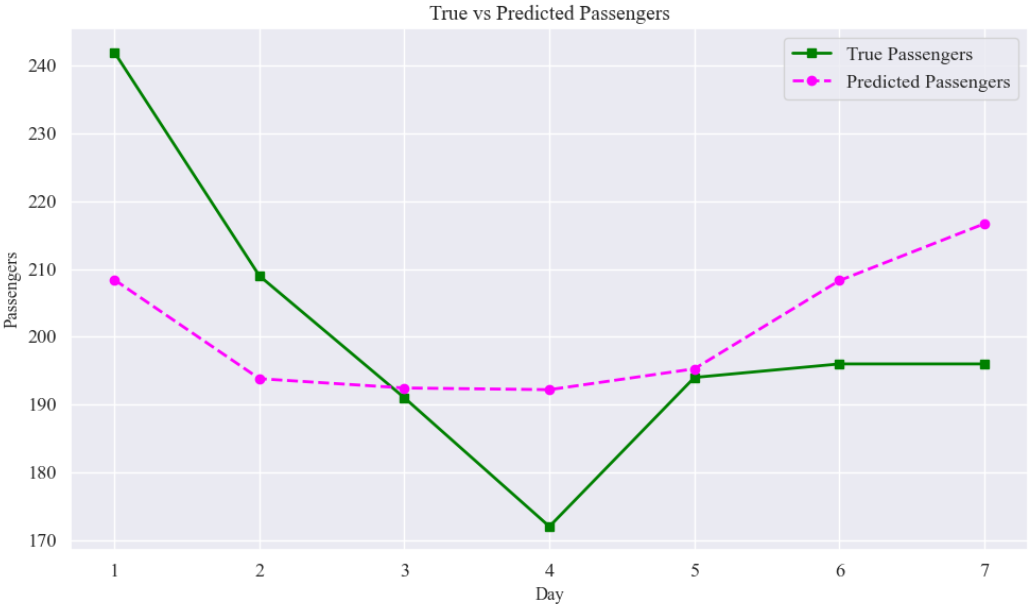
直观对比测试样本中真实与预测的气温变化情况。
plt.figure(figsize=(10, 6))
days = np.arange(1, output_window + 1)
plt.plot(days, sample_true, marker='s', linestyle='-', color='green', linewidth=2, label="True Passengers")
plt.plot(days, sample_pred, marker='o', linestyle='--', color='magenta', linewidth=2, label="Predicted Passengers")
plt.xlabel("Day", fontsize=12)
plt.ylabel("Passengers", fontsize=12)
plt.title("True vs Predicted Passengers", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()结果:
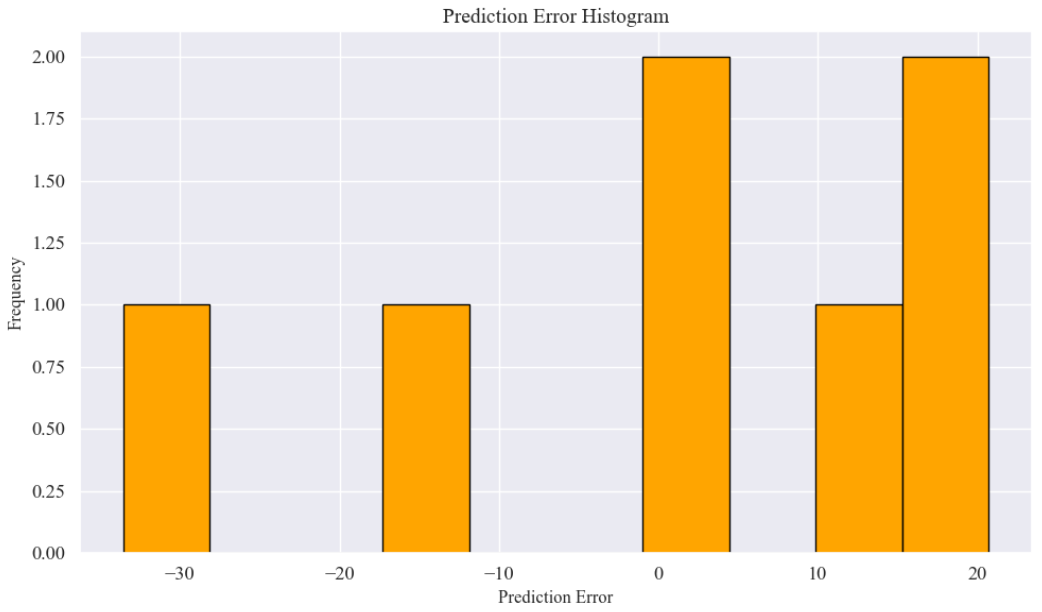
展示预测误差的分布,有助于判断误差是否呈现正态分布及其离散情况。
plt.figure(figsize=(10, 6))
plt.hist(errors, bins=10, color='orange', edgecolor='black')
plt.xlabel("Prediction Error", fontsize=12)
plt.ylabel("Frequency", fontsize=12)
plt.title("Prediction Error Histogram", fontsize=14)
plt.tight_layout()
plt.show()结果:
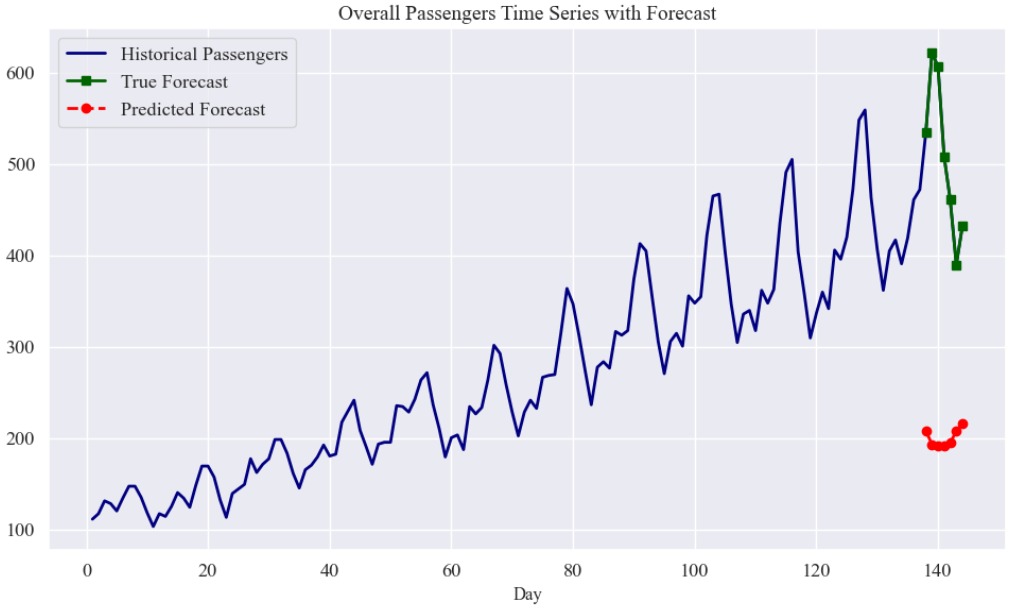
将历史气温数据与预测未来气温叠加展示,帮助理解模型预测在整体趋势中的位置。
plt.figure(figsize=(10, 6))
all_days = np.arange(1, num_total_days + 1)
plt.plot(all_days, passengers_data, color='navy', linewidth=2, label="Historical Passengers")
# 假设最后一段数据为测试集最后一个样本,取出最后 input_window + output_window 的数据作为示例
forecast_start = num_total_days - (input_window + output_window)
forecast_days = np.arange(forecast_start + 1, num_total_days + 1)
# 真实未来气温(测试集真实值)
true_forecast = passengers_data[forecast_start + input_window: forecast_start + input_window + output_window]
# 用模型预测未来气温,注意这里只是演示,所以取测试集中最后一个样本预测结果
plt.plot(forecast_days[input_window:], true_forecast, marker='s', linestyle='-', color='darkgreen', linewidth=2,
label="True Forecast")
plt.plot(forecast_days[input_window:], sample_pred, marker='o', linestyle='--', color='red', linewidth=2,
label="Predicted Forecast")
plt.xlabel("Day", fontsize=12)
plt.ylabel("Temperature", fontsize=12)
plt.title("Overall Passengers Time Series with Forecast", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()结果:
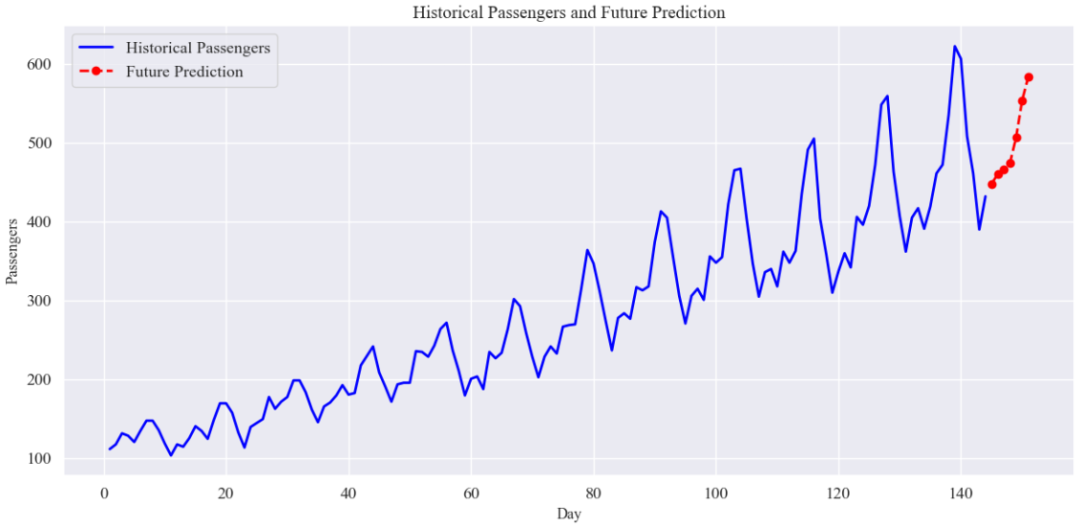
2.7 模型预测未来一周乘客的实际案例
为了演示模型预测未来一周乘客变化的效果,我们选择数据集最后一段作为预测对象:
last_input = passengers_data[-input_window:]
# 将输入数据转换为 tensor,形状:(1, input_window, 1)
last_input_tensor = torch.tensor(last_input, dtype=torch.float32).unsqueeze(0).unsqueeze(-1).to(device)
model.eval()
with torch.no_grad():
future_pred = model(last_input_tensor).cpu().numpy().flatten()
# 打印预测结果
print("Predicted Passengers for the next 7 days:")
print(future_pred)结果:

绘制未来预测结果与历史数据对比图:
plt.figure(figsize=(12, 6))
# 历史数据绘制
plt.plot(np.arange(1, num_total_days + 1), passengers_data, color='blue', linewidth=2, label="Historical Passengers")
# 未来预测数据:将预测值接在历史数据之后
future_days = np.arange(num_total_days + 1, num_total_days + output_window + 1)
plt.plot(future_days, future_pred, marker='o', linestyle='--', color='red', linewidth=2, label="Future Prediction")
plt.xlabel("Day", fontsize=12)
plt.ylabel("Passengers", fontsize=12)
plt.title("Historical Passengers and Future Prediction", fontsize=14)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。