这是我的第393篇原创文章。
一、引言
今天给大家分享阿里达摩院在语音识别领域开源的大杀器FunASR项目;它支持语音识别、端点检测、标点符合预测、多说话人分离等亮点功能,在中文语音识别方面比OpenAI开源的Whisper模型更小,更准!
FunASR是一个基础的端到端语音识别工具包,旨在架起语音识别学术研究和工业应用之间的桥梁。它支持工业级语音识别模型的训练和微调,方便研究人员和开发者更便捷地进行语音识别模型的研究和生产,促进语音识别生态的发展。其目标是让语音识别变得更有趣(ASR for Fun)!FunASR 提供了语音识别 (ASR)、语音活动检测 (VAD)、标点恢复、语言模型、说话人识别、说话人分段以及多说话人 ASR 等多种功能。并提供方便的脚本和教程,支持预训练模型的推理和微调。
Github仓库:https://github.com/modelscope/FunASR
二、实现过程
2.1 准备音频素材
使用edge-tts命令将一段文字转化为语音并生成.wav语音文件:
edge-tts --voice zh-CN-YunyangNeural --text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。如果非要在这份爱上加上一个期限,我希望是……一万年" --write-media speaker2.wav结果:
![]()
语音文件加载读取:
speaker2_wav = "speaker2.wav"
waveform, sample_rate = torchaudio.load(speaker2_wav)
Audio(waveform, rate=sample_rate, autoplay=True)2.2 利用paraformer-zh-语音文字识别
代码:
model = AutoModel(model="paraformer-zh")
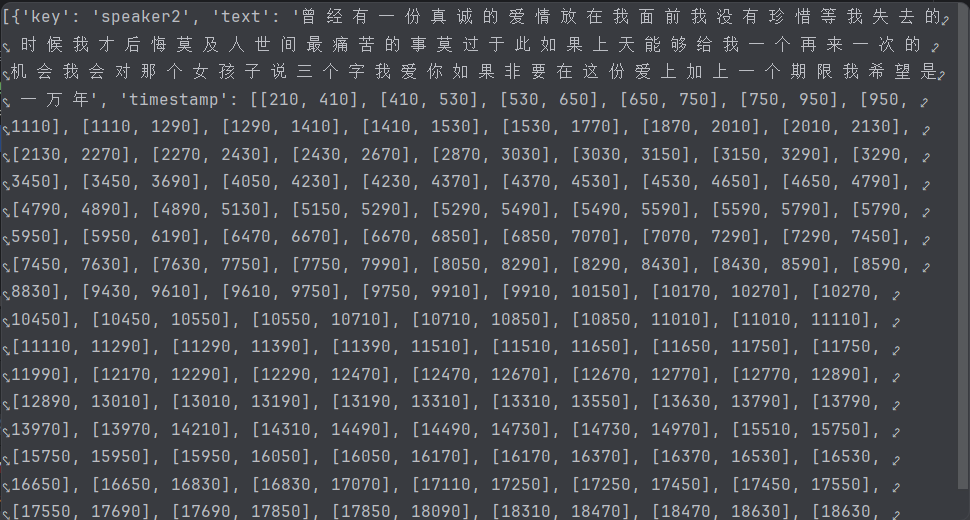
res = model.generate(input=speaker2_wav)
print("识别出的结果:", res[0]['text'])model = AutoModel(model="paraformer-zh")这句代码会在线下载模型,默认路径是C:\User\quwen\.cache\modelscope\hub

模型文件如下:
结果:
2.3 利用fsmn_vad_zh来-语音结束点识别
代码:
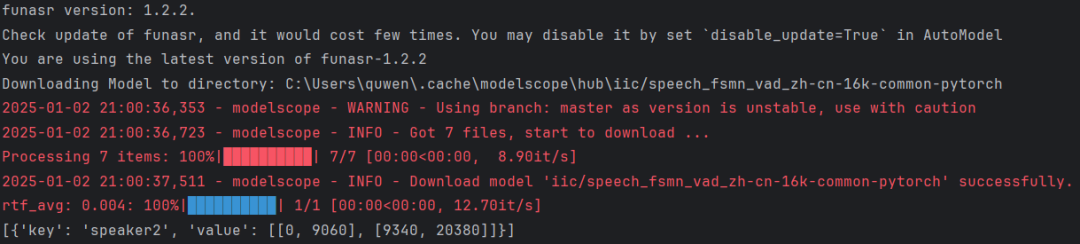
model=AutoModel(model="fsmn-vad")
res=model.generate(input=speaker2_wav)
print(res)model = AutoModel(model="fsmn-vad")这句代码会在线下载模型,默认路径是C:\User\quwen\.cache\modelscope\hub
模型文件如下:
2.4 利用ct-punc-对语音识别文本进行标点符号预测
代码:
model = AutoModel(model="ct-punc")
res = model.generate(input="曾 经 有 一 份 真 诚 的 爱 情 放 在 我 面 前 我 没 有 珍 惜 等 我 失 去 的 时 候 我 才 后 悔 莫 及 人 世 间 最 痛 苦 的 是 莫 过 于 此 如 果 上 天 能 够 给 我 一 个 再 来 一 次 的 机 会 我 会 对 那 个 女 孩 子 说 三 个 字 我 爱 你 如 果 非 要 在 这 份 爱 上 加 上 一 个 期 限 我 希 望 是 一 万 年")
print(res)model = AutoModel(model="ct-punc")这句代码会在线下载模型,默认路径是C:\User\quwen\.cache\modelscope\hub
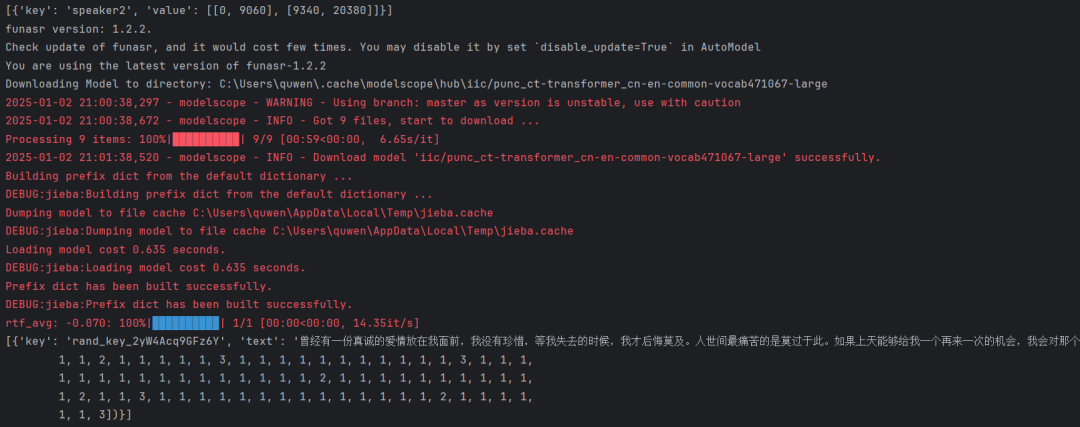
模型文件如下:
2.5 利用cam++对语音中说话人身份识别
代码:
model = AutoModel(model="cam++")
res = model.generate(input=speaker2_wav)
print(res)model = AutoModel(model="cam++")这句代码会在线下载模型,默认路径是C:\User\quwen\.cache\modelscope\hub
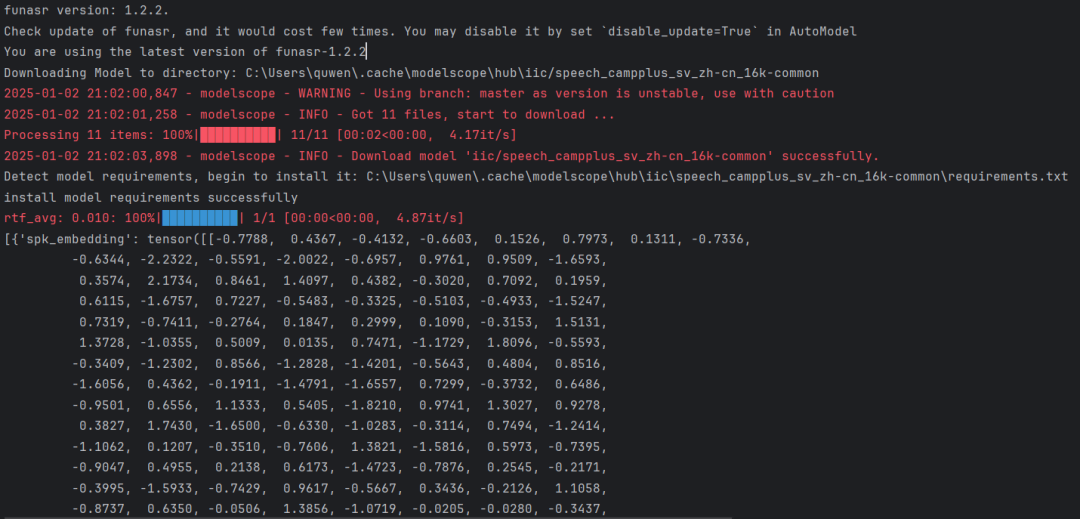
模型文件如下:
2.6 对多说话人进行语音识别
代码:
speaker1_wav = ("E:\data\\a2.wav")
waveform, sample_rate = torchaudio.load(speaker1_wav)
Audio(waveform, rate=sample_rate, autoplay=True)
funasr_model = AutoModel(model="C:\\Users\quwen\.cache\modelscope\hub\iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
vad_model="C:\\Users\quwen\.cache\modelscope\hub\iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="C:\\Users\quwen\.cache\modelscope\hub\iic\punc_ct-transformer_cn-en-common-vocab471067-large",
spk_model="C:\\Users\quwen\.cache\modelscope\hub\iic/speech_campplus_sv_zh-cn_16k-common", )
res = funasr_model.generate(input=speaker1_wav, batch_size_s=300)
print(res)
print(type(res))
conv = ''
sentence_info = res[0]['sentence_info']
for sentence in sentence_info:
conv = conv + f"spk {sentence['spk']} : {sentence['text']}\n"
print(conv)结果:

2.7 热词功能
代码:
speaker1_wav = ("E:\data\\a2.wav")
waveform, sample_rate = torchaudio.load(speaker1_wav)
Audio(waveform, rate=sample_rate, autoplay=True)
funasr_model = AutoModel(model="C:\\Users\quwen\.cache\modelscope\hub\iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
vad_model="C:\\Users\quwen\.cache\modelscope\hub\iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="C:\\Users\quwen\.cache\modelscope\hub\iic\punc_ct-transformer_cn-en-common-vocab471067-large",
spk_model="C:\\Users\quwen\.cache\modelscope\hub\iic/speech_campplus_sv_zh-cn_16k-common", )
res = funasr_model.generate(input=speaker1_wav,
batch_size_s=300,
hotword='苏珊银行')
print(res)
print(type(res))
conv = ''
sentence_info = res[0]['sentence_info']
for sentence in sentence_info:
conv = conv + f"spk {sentence['spk']} : {sentence['text']}\n"
print(conv)结果:

作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。