这是我的第392篇原创文章。
一、引言
XGBoost 是一种高效的梯度提升树(Gradient Boosting Decision Tree, GBDT)算法。尽管 XGBoost 主要用于监督学习任务(如分类和回归),但通过适当的数据预处理,它也可以用于时间序列预测(Time Series Forecasting)。本文通过一个具体的案例逐步讲解XGBoost模型用于单变量时序数据预测。
二、实现过程
2.1 读取时间序列数据
代码:
data = pd.read_csv('data.csv')
data['Month'] = pd.to_datetime(data['Month'])
df = data
sns.set(font_scale=1.2)
plt.rc('font', family=['Times New Roman', 'SimSun'], size=12)
plt.figure()
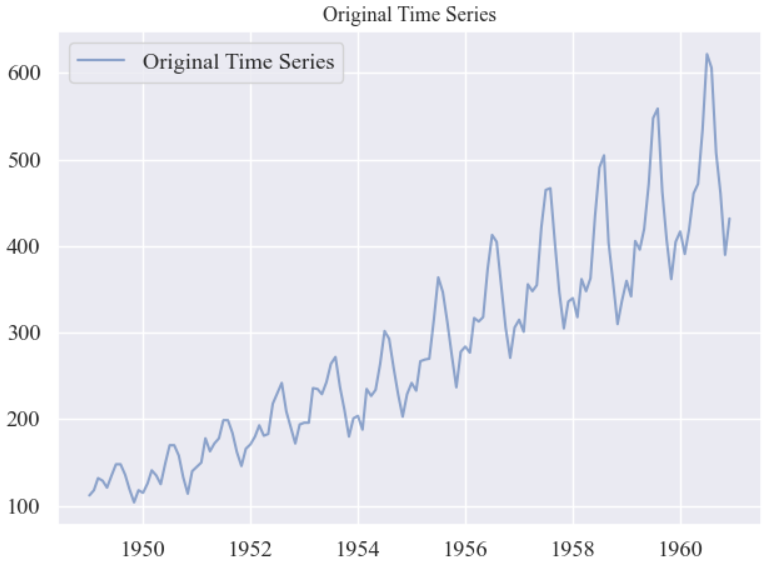
plt.plot(df['Month'], df['Passengers'], color='b', alpha=0.6, label='Original Time Series')
plt.title('Original Time Series', fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()结果:
2.2 数据格式转换
滑动窗口法转换为监督学习格式,代码 :
df_lagged = create_lag_features(df, lags=10)
X = df_lagged.drop(columns=['Passengers'])
y = df_lagged['Passengers']2.3 数据集划分
代码:
# 3. 数据集拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)结果:
![]()
2.4 模型训练
代码:
model = XGBRegressor(objective='reg:squarederror', n_estimators=200, learning_rate=0.1, max_depth=5)
model.fit(X_train, y_train)2.5 模型预测
代码:
y_pred = model.predict(X_test)2.6 模型评估
代码
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.4f}')结果::
![]()
可视化:
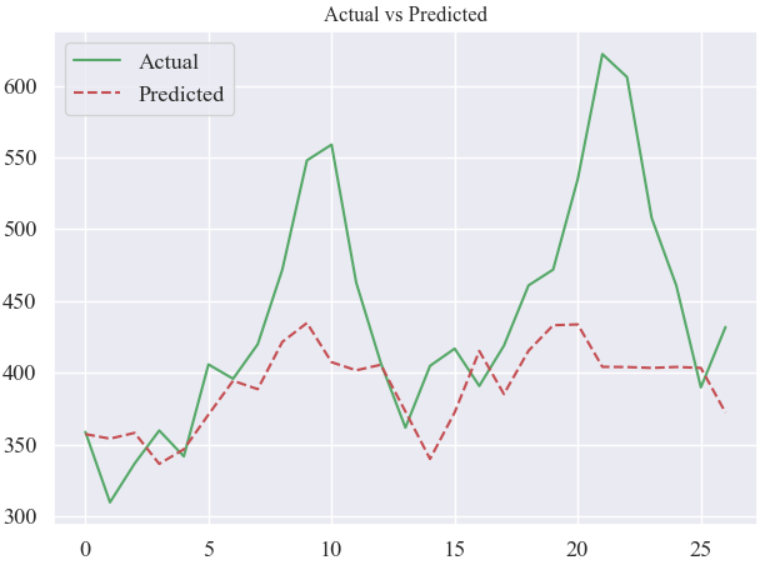
plt.figure()
plt.plot(y_test.values, label='Actual', color='g')
plt.plot(y_pred, label='Predicted', color='r', linestyle='dashed')
plt.title('Actual vs Predicted', fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()结果:
查看预测误差的分布情况:
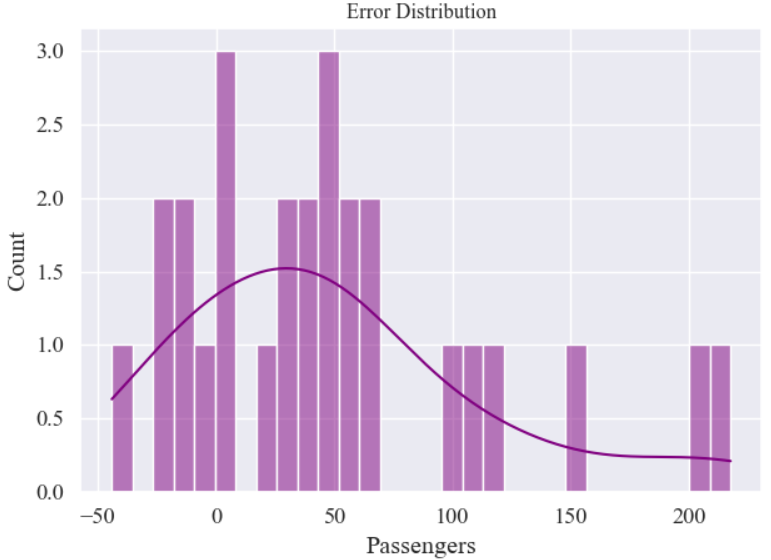
plt.figure()
sns.histplot(y_test - y_pred, bins=30, kde=True, color='purple')
plt.title('Error Distribution', fontsize=12)
plt.tight_layout()
plt.show()结果:
2.7 特征重要性分析
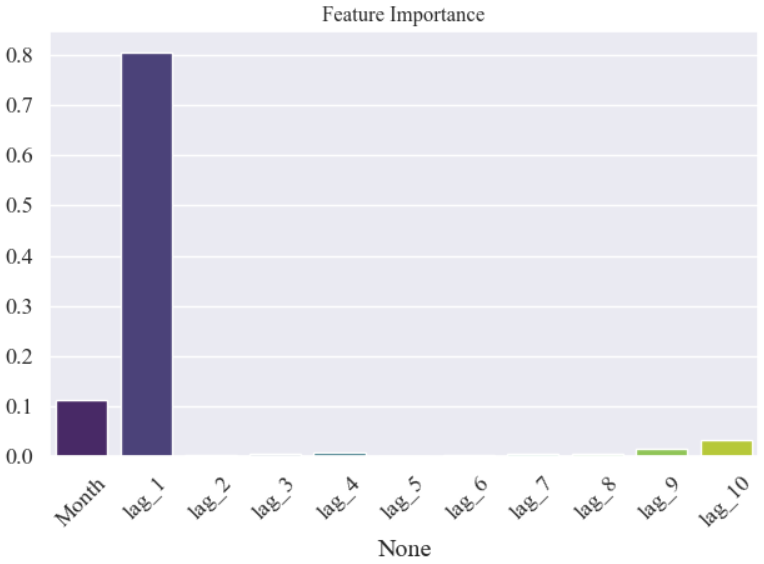
分析哪些滞后变量对预测最重要,代码:
plt.figure()
feature_importance = model.feature_importances_
sns.barplot(x=X.columns, y=feature_importance, palette='viridis')
plt.title('Feature Importance', fontsize=12)
plt.xticks(X.columns, rotation=45)
plt.tight_layout()
plt.show()结果:
2.8 参数调优
代码:
grid_params = {
'n_estimators': [100, 200, 500],
'max_depth': [3, 5, 7],
'learning_rate': [0.01, 0.1, 0.2]
}
grid_search = GridSearchCV(XGBRegressor(objective='reg:squarederror'), grid_params, cv=3, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
print(f'Best Parameters: {grid_search.best_params_}')结果:
![]()
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。