这是我的第388篇原创文章。
一、引言
在语音识别和音频处理领域,我们经常需要对音频文件格式进行转换,例如将 M4A 格式转为更常见的 WAV 格式。本文将基于pydub这个库批量实现m4a到wav语音格式的转化。
pydub 是一个用 Python 编写的音频处理库,可以方便地处理许多音频文件,诸如分割、合并、格式转换、音量调节等。它具有以下特点:
-
主要使用 ffmpeg 和 libav 模块来实现音频的读取、处理和输出。
-
支持的音频格式非常广泛,包括 MP3、WAV、FLAC、MP4 等。
-
API 简单易用,可以方便地进行常用的音频处理操作。
注意事项
-
安装依赖:
pydub需要通过
pip install pydub安装。-
转换音频文件需要支持的解码工具,例如 FFmpeg 或 libav。可以通过安装 FFmpeg 来确保
pydub正常工作。
-
FFmpeg 配置:
-
确保系统已安装 FFmpeg,并配置好环境变量。
-
或者将 FFmpeg 的路径手动传递给
pydub(如果默认路径不可用)。
-
二、实现过程
pydub 需要 FFmpeg 来处理音频文件格式。如果你的系统未安装 FFmpeg,请按以下步骤操作:前往 FFmpeg 官方网站https://www.gyan.dev/ffmpeg/builds/#release-builds 下载 Windows 二进制文件。
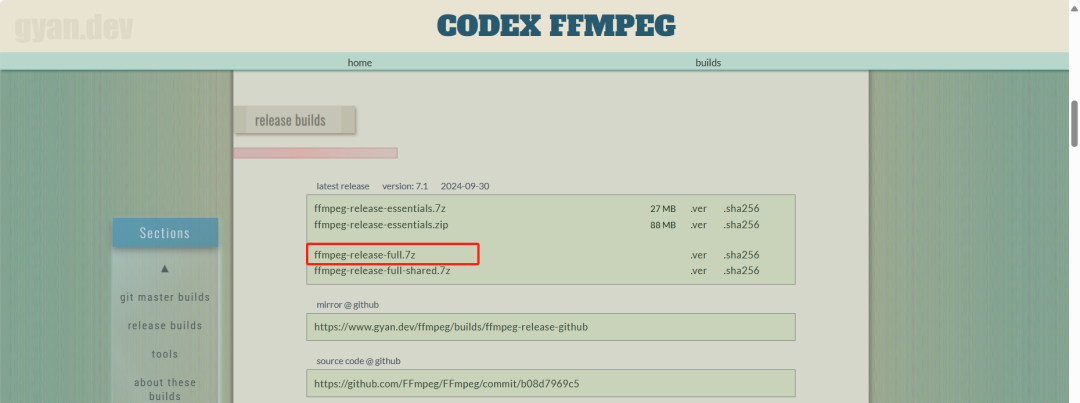
解压后将 bin 文件夹路径添加到系统环境变量:
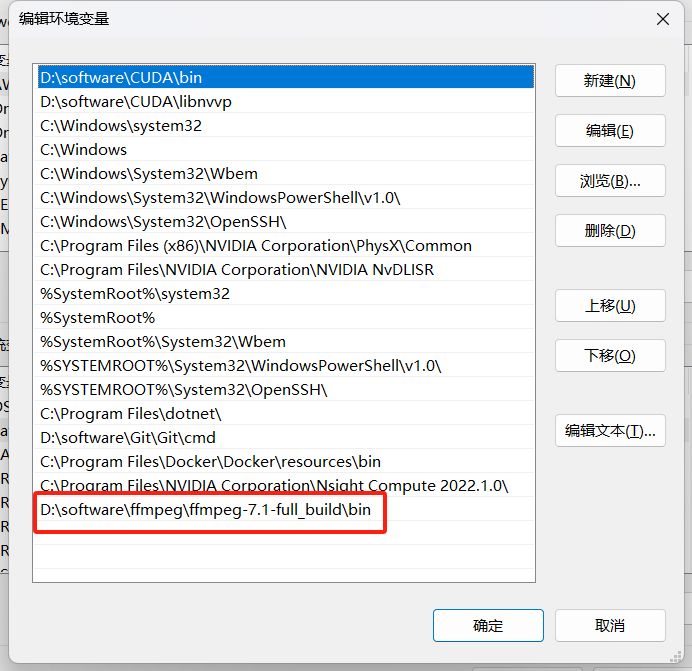
在终端输入以下命令看是否成功配置:
ffmpeg -i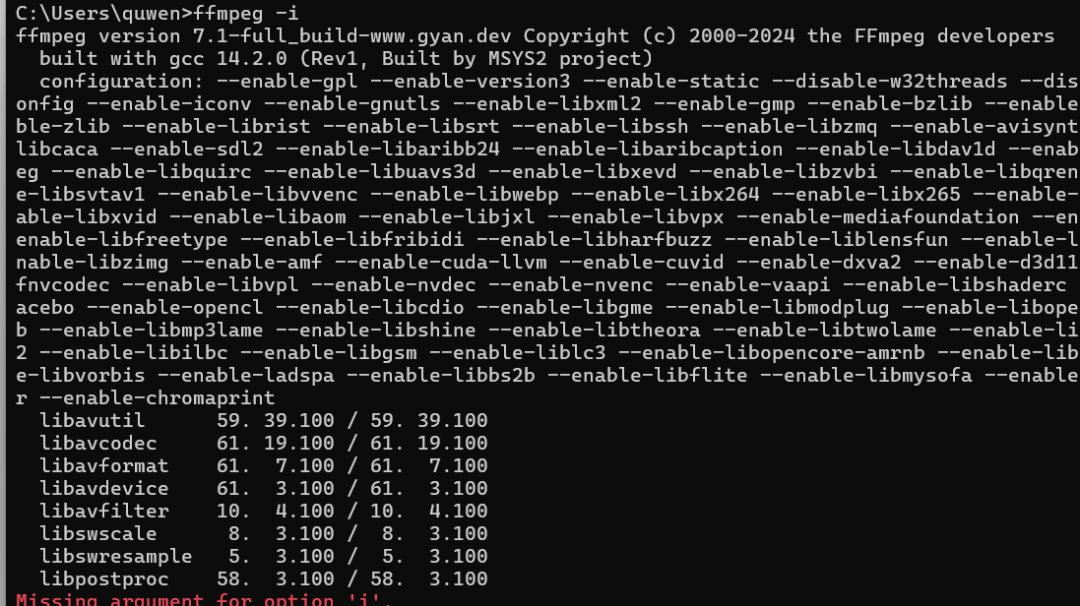
编写代码:从指定的输入文件夹中批量查找 .m4a 文件。将每个 .m4a 文件转换为 .wav 文件。将转换后的 .wav 文件保存到目标文件夹中。
import os
from pydub import AudioSegment
# 文件夹路径
input_folder = "D:\\quwen\Documents\录音-副本"
wav_folder = "D:\\quwen\Documents\录音-副本-wav"
os.makedirs(wav_folder, exist_ok=True)
# 批量处理 M4A 文件
for file_name in os.listdir(input_folder):
if file_name.endswith(".m4a"):
print(file_name)
input_path = os.path.join(input_folder, file_name)
print(input_path)
wav_path = os.path.join(wav_folder, os.path.splitext(file_name)[0] + ".wav")
# M4A 转 WAV
song = AudioSegment.from_file(input_path, format="m4a")
song.export(wav_path, format="wav")
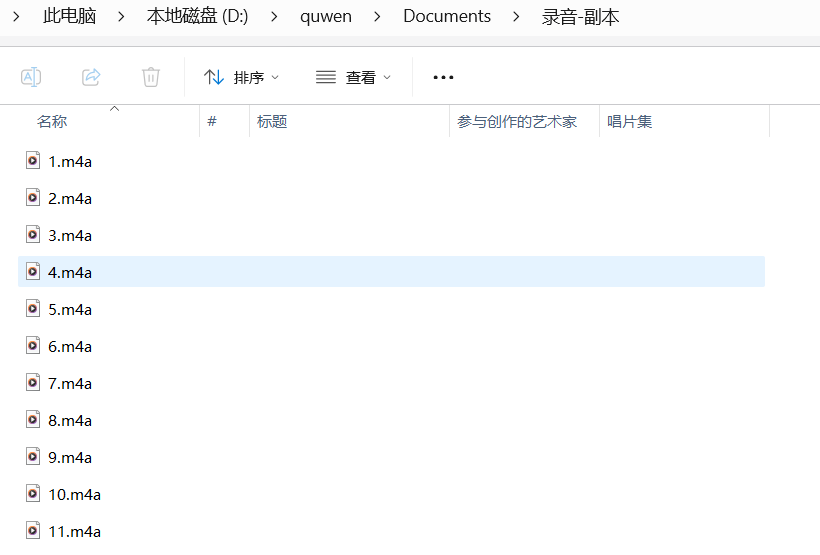
print(f"转换完成:{wav_path}")执行过程:
最终结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。