Hi,大家好,我是半亩花海。图神经网络(GNNs)已经成为处理图数据的重要工具,能够有效捕捉节点之间的依赖关系。在图神经网络中,图注意力网络(Graph Attention Network, GAT)作为一种基于注意力机制的图网络模型,通过引入节点间的注意力权重来动态地加权节点的邻接特征,取得了较好的表现。本实验的目的是通过实现GAT网络中的核心层——GATLayer,并利用多头注意力机制来优化节点特征的表示。最终实现了一个具有多头注意力机制的图卷积层,并通过构建一个简单的图来验证该层的有效性。
目录
一、图注意力网络的含义
为了解决此问题,一种常见的方法是对自连接添加更高的权重,或者为不同连接定义不同的权重,这里就涉及到了另一个重要概念:注意力机制。
注意力机制描述了多个元素的加权平均,这一概念同样适用于图,称为图注意力网络(Graph Attention Networks,GAT),与 GCN 类似,图注意力层使用线性层Linear为每个节点创建消息。对于注意力的计算部分,综合使用来自节点本身的特征以及其它节点的特征。节点从 到
的最终注意力权重
的计算示意图如下所示:
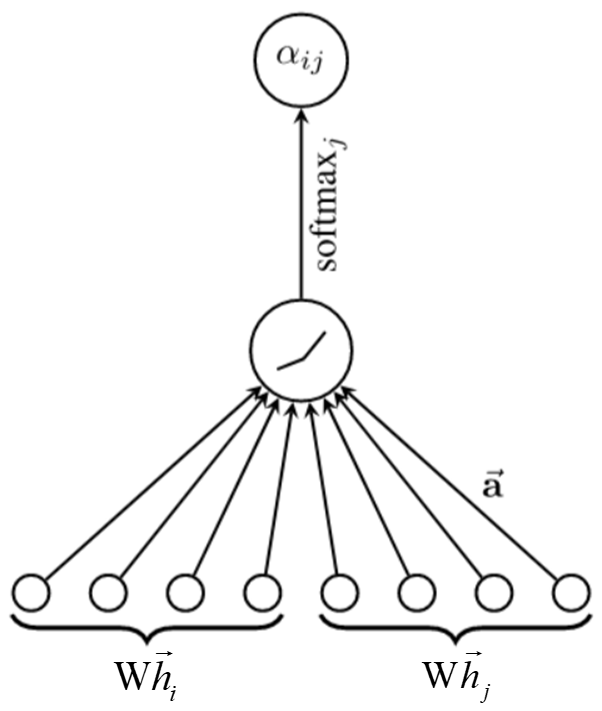
其中, 和
分别是节点
和
的原始特征,用
作为权重矩阵,运算后进行拼接,再经过权重矩阵
的计算,形状为 [1,2×dmessage];接着经由激活函数(例如 LeakyReLU)以及 Softmax 的运算,最后计算而得的
表示节点从
和
的最终注意力权重,计算方法如下:
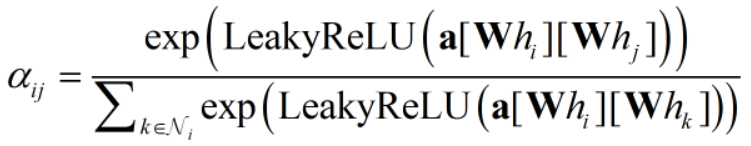
最终的节点特征值 基于所有
以及相应的
进行加权平均而得,
表示激活函数,示意图如下:
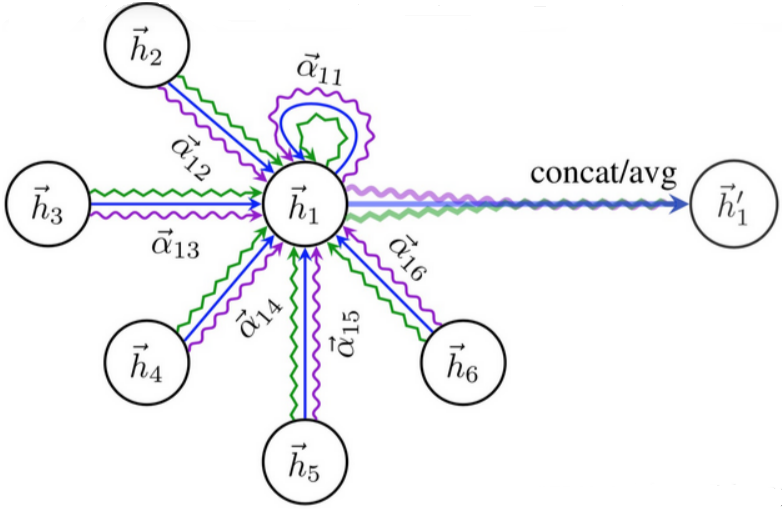
二、实验展示——基于图注意力网络的节点特征计算与表示
为了增加图注意力网络的表征能力,可以将其扩展到多头机制,类似于 Transformer 中的多头注意力模块。在有了对图注意层的基本了解之后,我们可以基于 PyTorch 实现它。
(一)实验环境与依赖
1. 环境配置
- Python版本:Python 3.10
- 深度学习框架:PyTorch 2.1.0
- 其他依赖库:
torch.nn,torch.nn.functional
具体的 pytorch、Python 等环境如何选择,可参考下面的文章:深度学习 | pytorch + torchvision + python 版本对应及环境安装_pytorch对应的python版本-CSDN博客
2. 数据说明
- 节点特征:输入为形状为
(batch_size, num_nodes, c_in)的张量,表示每个节点的特征向量。 - 邻接矩阵:输入为形状为
(num_nodes, num_nodes)的张量,表示节点之间的连接关系。
(二)代码详解
1. 类定义与初始化
首先,我们定义了 GATLayer 类,它继承自 PyTorch 的 nn.Module 类。该类的作用是构建一个包含多头注意力机制的图卷积层。在 __init__ 方法中,我们初始化了网络的关键参数:
class GATLayer(nn.Module):
def __init__(self, c_in, c_out,
num_heads=1, concat_heads=True, alpha=0.2):
"""
初始化GAT层
:param c_in: 输入特征维度
:param c_out: 输出特征维度
:param num_heads: 多头的数量
:param concat_heads: 是否拼接多头计算的结果
:param alpha: LeakyReLU的参数
"""
super().__init__()
self.num_heads = num_heads
self.concat_heads = num_heads
if self.concat_heads:
assert c_out % num_heads == 0, "输出特征数必须是头数的倍数!"
c_out = c_out // num_heads
# 参数
self.projection = nn.Linear(c_in, c_out * num_heads) # 将输入映射到高维空间
self.a = nn.Parameter(torch.Tensor(num_heads, 2 * c_out)) # 注意力参数
self.leakrelu = nn.LeakyReLU(alpha) # 激活函数
# 参数初始化
nn.init.xavier_uniform_(self.projection.weight.data, gain=1.414)
nn.init.xavier_uniform_(self.a.data, gain=1.414)(1)输入参数
c_in:输入特征的维度。c_out:输出特征的维度。num_heads:多头注意力机制的头数。concat_heads:是否将多头计算结果拼接在一起。如果为True,则输出特征维度为c_out * num_heads;否则为c_out。alpha:LeakyReLU激活函数的负斜率参数。
(2)核心组件
self.projection:线性变换层,用于将输入特征映射到高维空间。self.a:可学习的注意力参数,用于计算节点对之间的注意力分数(此参数的维度为[num_heads, 2 * c_out],即每个头的注意力权重对应两个输入节点的拼接特征)。self.leakyrelu:LeakyReLU激活函数,用于非线性变换。
(3)参数初始化
- Xavier初始化:对线性层和注意力参数进行初始化,以加速训练过程并提高模型性能。
2. 前向传播
在 forward 方法中,我们定义了前向传播的步骤。具体步骤如下:
def forward(self, node_feats, adj_matrix, print_attn_probs=False):
batch_size, num_nodes = node_feats.size(0), node_feats.size(1)
# 将节点初始输入进行权重运算
node_feats = self.projection(node_feats)
# 扩展出多头数量的维度
node_feats = node_feats.view(batch_size, num_nodes, self.num_heads, -1)
# 获取所有顶点对拼接而成的特征向量 a_input
edges = adj_matrix.nonzero(as_tuple=False) # 返回所有邻接矩阵中值不为 0 的 index,即所有连接的边对应的两个顶点
node_feats_flat = node_feats.view(batch_size * num_nodes, self.num_heads, -1) # 将所有 batch_size 的节点拼接
edge_indices_row = edges[:, 0] * batch_size + edges[:, 1] # 获取边对应的第一个顶点 index
edge_indices_col = edges[:, 0] * batch_size + edges[:, 2] # 获取边对应的第二个顶点 index
a_input = torch.cat([
torch.index_select(input=node_feats_flat, index=edge_indices_row, dim=0), # 基于边对应的第一个顶点的 index 获取其特征值
torch.index_select(input=node_feats_flat, index=edge_indices_col, dim=0) # 基于边对应的第二个顶点的 index 获取其特征值
], dim=-1) # 两者拼接
# 基于权重 a 进行注意力计算
attn_logits = torch.einsum('bhc,hc->bh', a_input, self.a)
# LeakyReLU 计算
attn_logits = self.leakrelu(attn_logits)
# 将注意力权转换为矩阵的形式
attn_matrix = attn_logits.new_zeros(adj_matrix.shape + (self.num_heads,)).fill_(-9e15)
attn_matrix[adj_matrix[..., None].repeat(1, 1, 1, self.num_heads) == 1] = attn_logits.reshape(-1)
# Softmax 计算转换为概率
attn_probs = F.softmax(attn_matrix, dim=2)
if print_attn_probs:
print("注意力权重:\n", attn_probs.permute(0, 3, 1, 2))
# 对每个节点进行注意力加权相加的计算
node_feats = torch.einsum('bijh,bjhc->bihc', attn_probs, node_feats)
# 根据是否将多头的计算结果拼接与否进行不同操作
if self.concat_heads: # 拼接
node_feats = node_feats.reshape(batch_size, num_nodes, -1)
else: # 平均
node_feats = node_feats.mean(dim=2)
return node_feats
(1)节点特征投影
- 使用
self.projection将输入特征映射到高维空间,并扩展出多头维度。
(2)构造注意力输入
- 通过
adj_matrix.nonzero()获取所有边对应的节点索引。 - 将节点特征展平,并根据边索引提取对应节点的特征向量,拼接成注意力输入
a_input。
(3)计算注意力分数
- 使用
torch.einsum计算节点对之间的注意力分数。 - 应用LeakyReLU激活函数,增加非线性能力。
(4)构造注意力矩阵
- 初始化一个全零矩阵
attn_matrix,并将有效边对应的注意力分数填充到相应位置。
(5)Softmax归一化
- 对注意力矩阵进行Softmax归一化,得到注意力权重。
(6)加权求和
- 使用注意力权重对邻居节点特征进行加权求和,更新节点特征。
(7)多头处理
- 如果
concat_heads为True,将多头结果拼接;否则取平均。
(三)实验结果与分析
1. 输入数据
layer = GATLayer(2, 2, num_heads=2)
layer.projection.weight.data = torch.Tensor([[1., 0.], [0., 1.]])
layer.projection.bias.data = torch.Tensor([0., 0.])
layer.a.data = torch.Tensor([[-0.2, 0.3], [0.1, -0.1]])
node_feats = torch.arange(8, dtype=torch.float32).view(1, 4, 2)
adj_matrix = torch.Tensor([[[1, 1, 0, 0],
[1, 1, 1, 1],
[0, 1, 1, 1],
[0, 1, 1, 1]]])(1)节点特征:node_feats是一个形状为(1, 4, 2)的张量,表示4个节点,每个节点有2维特征。
(2)邻接矩阵:adj_matrix是一个形状为(4, 4)的张量,表示节点之间的连接关系。
2. 输出结果
with torch.no_grad():
out_feats = layer(node_feats, adj_matrix, print_attn_probs=True)
print("节点特征:\n", node_feats)
print("添加自连接的邻接矩阵:\n", adj_matrix)
print("节点输出特征:\n", out_feats)(1)注意力权重:打印出的注意力权重矩阵展示了每个节点对其邻居的注意力分布。
(2)节点输出特征:输出特征反映了经过GAT层处理后的节点表示。
通过运行上述代码,我们得到以下输出:
注意力权重: tensor([[[[0.3543, 0.6457, 0.0000, 0.0000], [0.1096, 0.1450, 0.2642, 0.4813], [0.0000, 0.1858, 0.2885, 0.5257], [0.0000, 0.2391, 0.2696, 0.4913]], [[0.5100, 0.4900, 0.0000, 0.0000], [0.2975, 0.2436, 0.2340, 0.2249], [0.0000, 0.3838, 0.3142, 0.3019], [0.0000, 0.4018, 0.3289, 0.2693]]]]) 节点特征: tensor([[[0., 1.], [2., 3.], [4., 5.], [6., 7.]]]) 添加自连接的邻接矩阵: tensor([[[1., 1., 0., 0.], [1., 1., 1., 1.], [0., 1., 1., 1.], [0., 1., 1., 1.]]]) 节点输出特征: tensor([[[1.2913, 1.9800], [4.2344, 3.7725], [4.6798, 4.8362], [4.5043, 4.7351]]])
- 节点特征:输入的节点特征为
node_feats,每个节点有两个特征。- 邻接矩阵:定义了节点之间的连接关系,表示为
adj_matrix。- 输出特征:通过多头注意力机制加权求和后的输出特征,展示了节点间通过注意力加权得到的新表示。
(四)实验小结
本实验实现了GAT层的核心逻辑,并通过具体输入数据验证了其功能。通过对代码的逐步解析,我们深入理解了GAT的工作原理及其在图结构数据上的应用。经实现并验证 GATLayer,我们可以得出以下结论:
- 多头注意力机制:该机制有效地增强了节点间的相互关系建模,通过多个头对不同邻居的关注进行加权平均或拼接,提高了模型的表达能力。
- 可扩展性:GATLayer 可以通过调整
num_heads参数和concat_heads的选择来控制多头注意力的数量和方式,灵活性强。 - 实验验证:实验结果表明,GATLayer 能够成功地基于输入特征和邻接矩阵计算出新的节点特征。
未来,我们可以进一步扩展实验,例如在真实数据集上测试模型性能,或与其他图神经网络模型进行对比分析。
三、总结
GNN对属性向量优化的方法叫做消息传递机制。比如最原始的GNN是SUM求和传递机制;到后面发展成图卷积网络(GCN)就考虑到了节点的度,度越大,权重越小,使用了加权的SUM;再到后面发展为图注意力网络GAT,在消息传递过程中引入了注意力机制;目前的SOTA模型研究也都专注在了消息传递机制的研究。
三种不同的图神经网络模型的消息传递机制差异如下图所示。
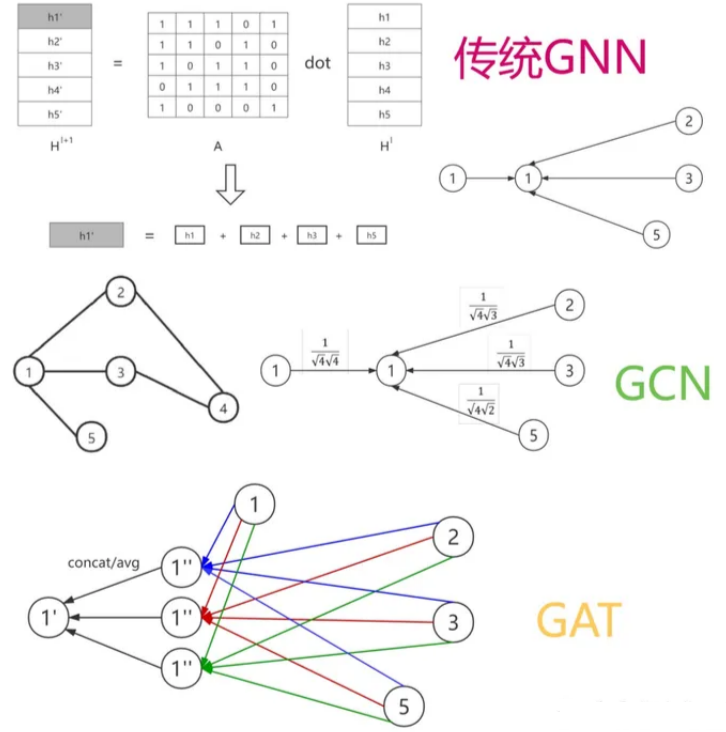
不同GNN的本质差别就在于它们如何进行节点之间的信息传递和计算,即它们的消息传递机制不同。
四、完整代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
@Project : GNN/GAT
@File : gat1.py
@IDE : PyCharm
@Author : 半亩花海
@Date : 2025/03/05 10:10
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class GATLayer(nn.Module):
def __init__(self, c_in, c_out,
num_heads=1, concat_heads=True, alpha=0.2):
"""
:param c_in: 输入特征维度
:param c_out: 输出特征维度
:param num_heads: 多头的数量
:param concat_heads: 是否拼接多头计算的结果
:param alpha: LeakyReLU的参数
:return:
"""
super().__init__()
self.num_heads = num_heads
self.concat_heads = num_heads
if self.concat_heads:
assert c_out % num_heads == 0, "输出特征数必须是头数的倍数!"
c_out = c_out // num_heads
# 参数
self.projection = nn.Linear(c_in, c_out * num_heads) # 有几个头,就需要将c_out扩充几倍
self.a = nn.Parameter(torch.Tensor(num_heads, 2 * c_out)) # 用于计算注意力的参数,由于对两节点拼接后的向量进行操作,所以2*c_out
self.leakrelu = nn.LeakyReLU(alpha) # 激活层
# 参数初始化
nn.init.xavier_uniform_(self.projection.weight.data, gain=1.414)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
def forward(self, node_feats, adj_matrix, print_attn_probs=False):
"""
输入:
:param node_feats: 节点的特征表示
:param adj_matrix: 邻接矩阵
:param print_attn_probs: 是否打印注意力
:return:
"""
batch_size, num_nodes = node_feats.size(0), node_feats.size(1)
# 将节点初始输入进行权重运算
node_feats = self.projection(node_feats)
# 扩展出多头数量的维度
node_feats = node_feats.view(batch_size, num_nodes, self.num_heads, -1)
# 获取所有顶点对拼接而成的特征向量 a_input
edges = adj_matrix.nonzero(as_tuple=False) # 返回所有邻接矩阵中值不为 0 的 index,即所有连接的边对应的两个顶点
node_feats_flat = node_feats.view(batch_size * num_nodes, self.num_heads, -1) # 将所有 batch_size 的节点拼接
edge_indices_row = edges[:, 0] * batch_size + edges[:, 1] # 获取边对应的第一个顶点 index
edge_indices_col = edges[:, 0] * batch_size + edges[:, 2] # 获取边对应的第二个顶点 index
a_input = torch.cat([
torch.index_select(input=node_feats_flat, index=edge_indices_row, dim=0), # 基于边对应的第一个顶点的 index 获取其特征值
torch.index_select(input=node_feats_flat, index=edge_indices_col, dim=0) # 基于边对应的第二个顶点的 index 获取其特征值
], dim=-1) # 两者拼接
# 基于权重 a 进行注意力计算
attn_logits = torch.einsum('bhc,hc->bh', a_input, self.a)
# LeakyReLU 计算
attn_logits = self.leakrelu(attn_logits)
# 将注意力权转换为矩阵的形式
attn_matrix = attn_logits.new_zeros(adj_matrix.shape + (self.num_heads,)).fill_(-9e15)
attn_matrix[adj_matrix[..., None].repeat(1, 1, 1, self.num_heads) == 1] = attn_logits.reshape(-1)
# Softmax 计算转换为概率
attn_probs = F.softmax(attn_matrix, dim=2)
if print_attn_probs:
print("注意力权重:\n", attn_probs.permute(0, 3, 1, 2))
# 对每个节点进行注意力加权相加的计算
node_feats = torch.einsum('bijh,bjhc->bihc', attn_probs, node_feats)
# 根据是否将多头的计算结果拼接与否进行不同操作
if self.concat_heads: # 拼接
node_feats = node_feats.reshape(batch_size, num_nodes, -1)
else: # 平均
node_feats = node_feats.mean(dim=2)
return node_feats
layer = GATLayer(2, 2, num_heads=2)
layer.projection.weight.data = torch.Tensor([[1., 0.], [0., 1.]])
layer.projection.bias.data = torch.Tensor([0., 0.])
layer.a.data = torch.Tensor([[-0.2, 0.3], [0.1, -0.1]])
node_feats = torch.arange(8, dtype=torch.float32).view(1, 4, 2)
adj_matrix = torch.Tensor([[[1, 1, 0, 0],
[1, 1, 1, 1],
[0, 1, 1, 1],
[0, 1, 1, 1]]])
with torch.no_grad():
out_feats = layer(node_feats, adj_matrix, print_attn_probs=True)
print("节点特征:\n", node_feats)
print("添加自连接的邻接矩阵:\n", adj_matrix)
print("节点输出特征:\n", out_feats)
参考文章
[1] 实战-----基于 PyTorch 的 GNN 搭建_pytorch gnn-CSDN博客
[2] 图神经网络简单理解 — — 附带案例_图神经网络实例-CSDN博客
[3] 一文快速预览经典深度学习模型(二)——迁移学习、半监督学习、图神经网络(GNN)、联邦学习_迁移学习 图神经网络-CSDN博客
[4] 深度学习 | pytorch + torchvision + python 版本对应及环境安装_pytorch对应的python版本-CSDN博客