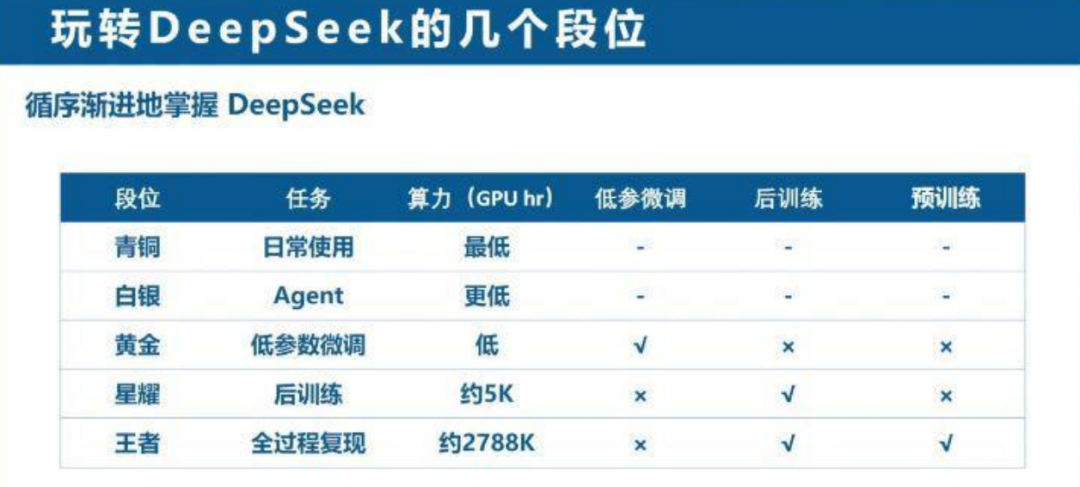
DeepSeek使用段位划分来了~~~
青铜段位主要通过问答和提示工程掌握基础应用;
白银段位将LLM作为Agent,与其他系统连接扩展功能;
星耀段位进入后训练阶段,提升模型的泛化能力和执行效率;
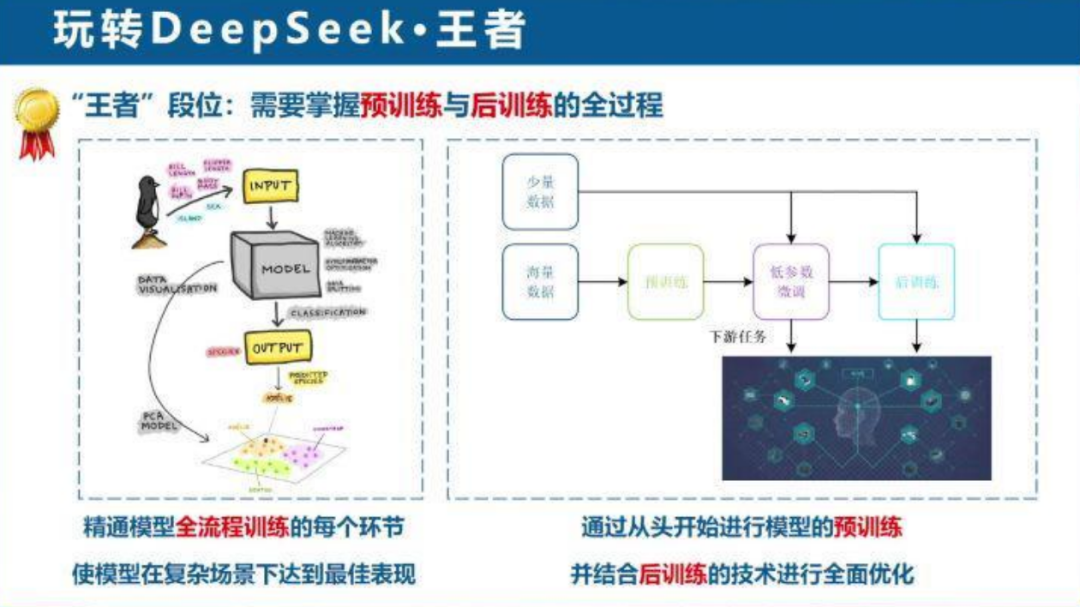
王者段位则需要掌握预训练与后训练的全过程,使模型在复杂场景下达到最佳表现。
你现在属于哪个段位呢?
今天为大家分享《西北工业大学DeepSeek核心技术白话解读》,让所有人都能读懂DeepSeek核心技术,从青铜到王者。

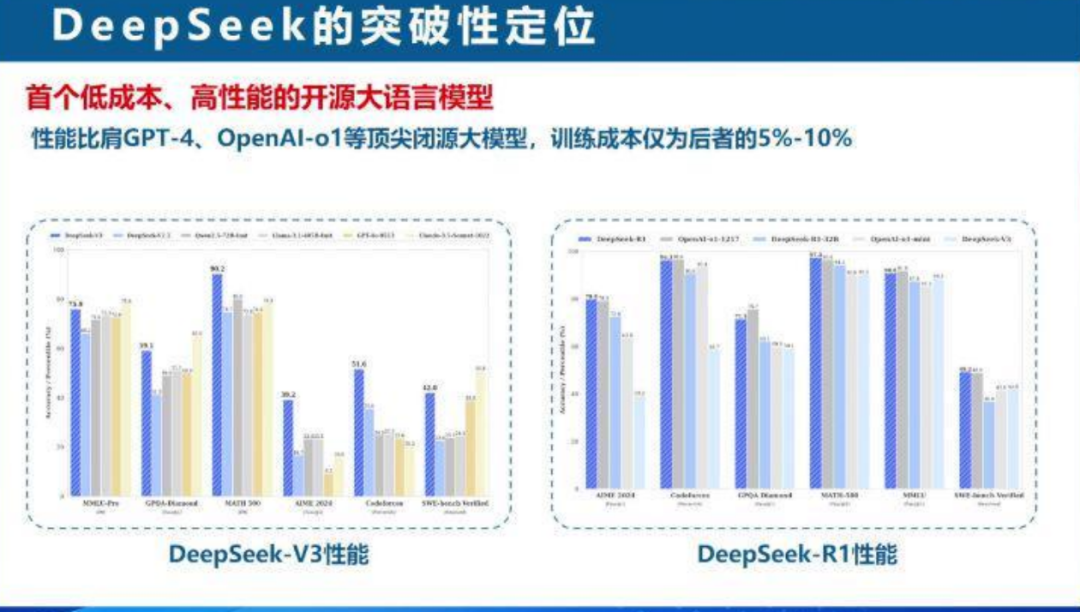
西北工业大学计算机学院教授王鹏介绍了DeepSeek的突破性定位以及核心逻辑创新,性能与GPT-4、OpenAI等顶尖闭源大模型相当。
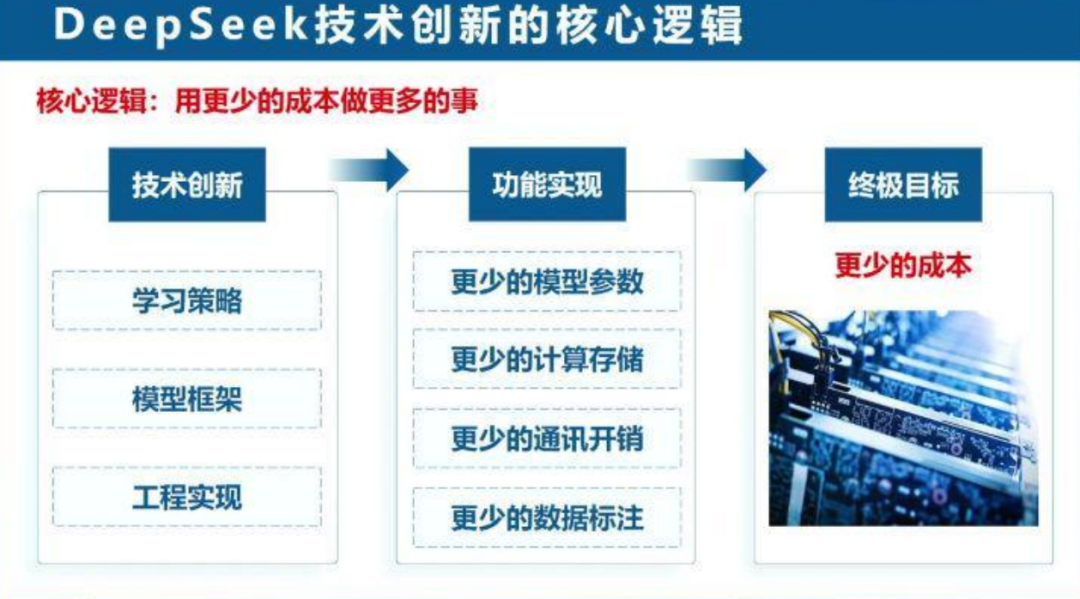
DeepSeek涵盖多个版本,通过不同的技术手段实现性能与效率的平衡;核心逻辑是用更少的成本做更多的事,包括学习策略、模型框架和工程实现。
1、 学习策略
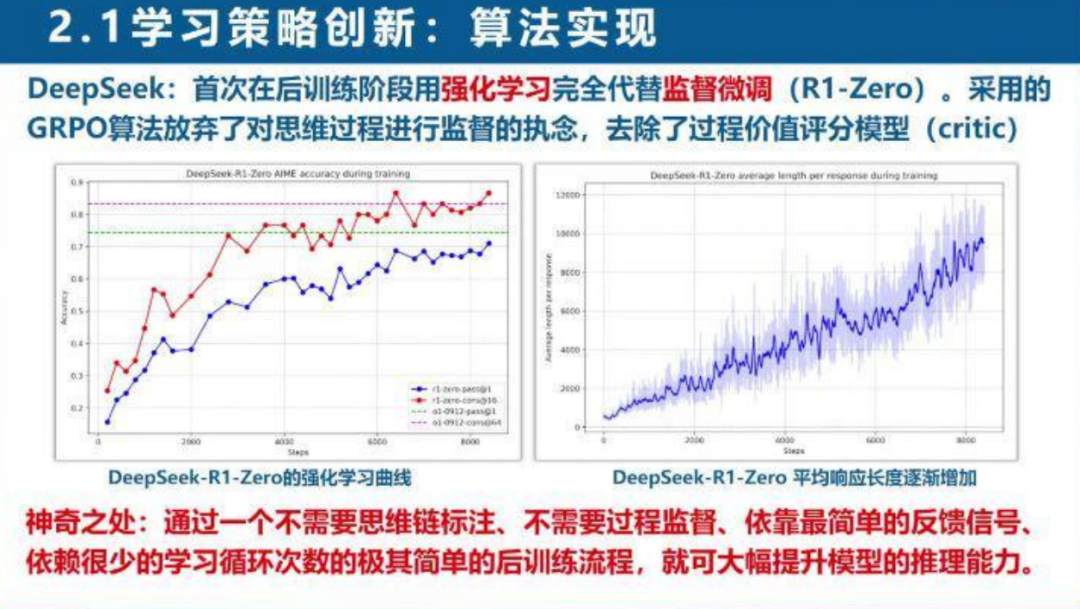
在后训练阶段用强化学习完全代替监督微调,采用的GRPO算法去除了过程价值评分模型,通过简单的反馈信号即可大幅提升模型的推理能力。
这种策略不仅降低了数据标注成本,还开启了LLM推理能力的自我进化之门,让模型能够自己悟出更好的解题思路。
2、 模型结构
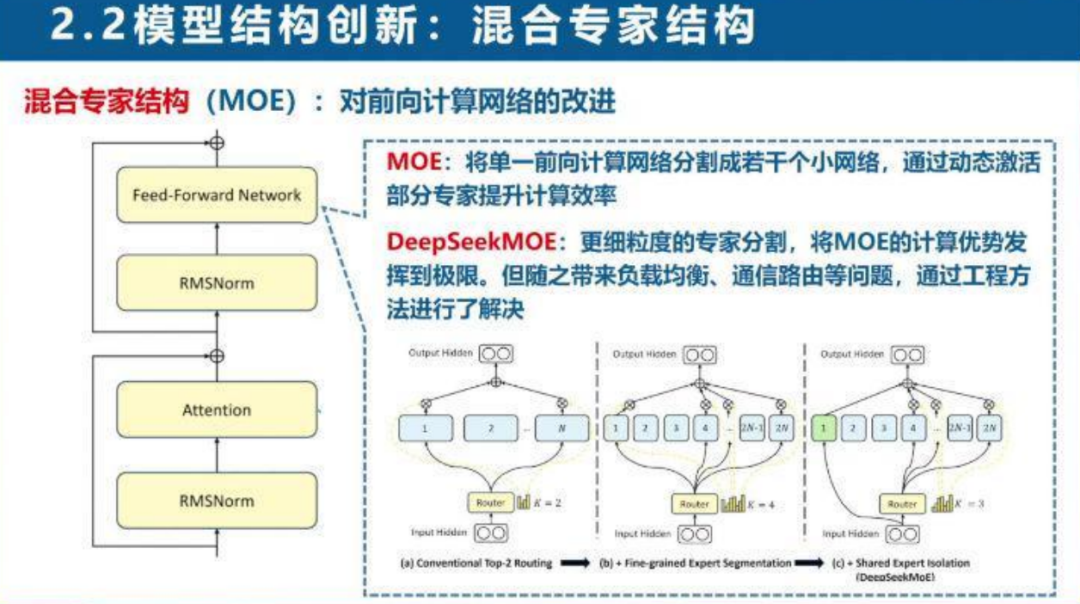
DeepSeek对Transformer结构进行了改进,采用混合专家结构(MOE),将单一前向计算网络分割成若干个小网络,通过动态激活部分专家提升计算效率。
这种结构创新不仅解决了传统Transformer在长文本条件下的计算存储瓶颈,还通过工程方法解决了负载均衡和通信路由等问题,进一步提升了模型的性能。
3、 工程实现
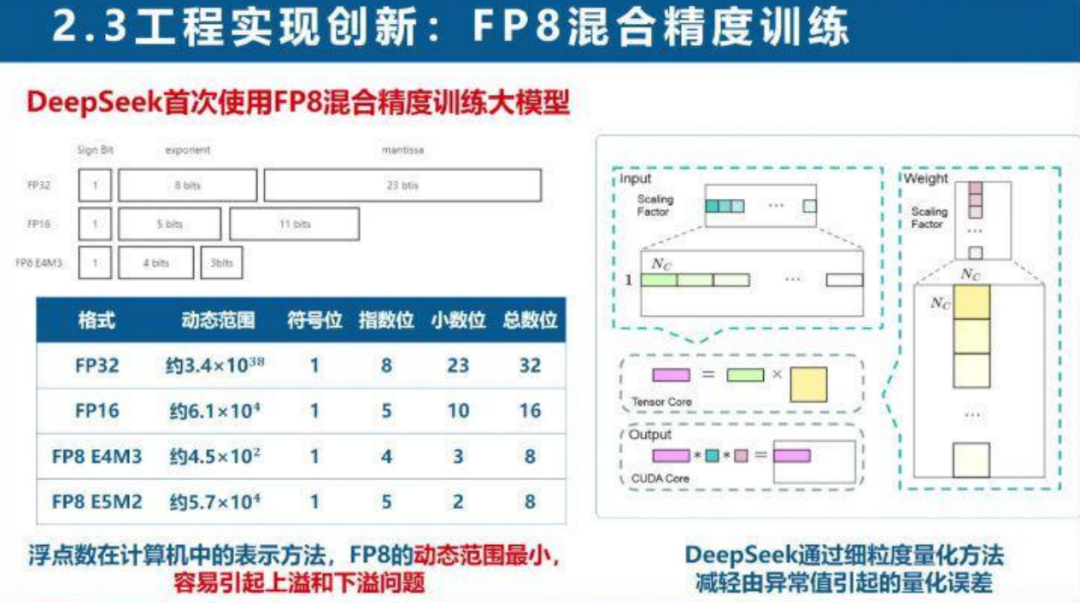
DeepSeek在工程实现上进行了大量创新,以实现极致性价比。采用FP8混合精度训练,通过细粒度量化方法减轻量化误差,提升了训练速度。
采用4D并行策略和通信计算重叠技术,将万亿Token训练时间压缩至3.7天。还实现了推理部署分离策略,提升了在线服务的吞吐量和响应速度。
最后
王鹏教授对DeepSeek的部署热潮进行了反思,指出大多数用户停留在基础段位,高校科研应专注于更高效的模型训练和任务优化。也讨论了现有问题,如幻觉消除和模型压缩,提出包括多模态大模型与具身智能的发展方向,强调智慧将跨越文本领域,催生新的跨模态应用。
以下是文档部分内容,全文36页


现在这份资料已经打包好了,话不多说,长按 vx 扫码发送 410 即可获取。

获取这份PDF:长按扫码发送「 410 」获取