RAG从入门到放弃
前言
想象一下,你有一个非常聪明但是有点“健忘”的朋友——大型语言模型(LLM),比如 GPT 系列。它能写诗、能编程、能跟你聊天,听起来很厉害吧?但是,它所知道的知识都来自于训练它的海量数据,这些数据是有时间范围的,而且不包含你个人或者特定领域最新的、私有的信息。
当你问它一些关于最近发生的事情,或者你公司内部的知识时,它可能会胡编乱造(我们称之为“AI幻觉”),或者干脆说不知道。这可就尴尬了。
这个时候,RAG 就派上用场了!它的核心思想很简单:在 LLM 生成答案之前,先去外部的知识库里检索相关的信息,然后把这些信息“喂”给 LLM,让它基于检索到的信息来生成更准确、更可靠的答案。
你可以把 RAG 想象成给你的“健忘”朋友配备了一个“搜索引擎”和一个“记忆助手”。当它需要回答问题时,先去“搜索引擎”里查阅相关的资料,然后结合自己的“记忆”来给出答案。

RAG是什么
RAG(Retrieval Augmented Generation,检索增强生成)是一种将大型语言模型(LLM) 与外部数据源(例如私有数据或最新数据)连接的通用方法。它允许大型语言模型(LLM)使用外部数据来生成其输出。
RAG 的流程大致
1.构建知识库 (Knowledge Base)
- 首先,你需要准备好你的知识来源,这可以是各种各样的文档、网页、数据库等等。
- 然后,你需要将这些原始数据转换成 LLM 可以理解和处理的格式。一个常见的做法是将文本分割成小的“chunk”(块),并为每个 chunk 生成对应的向量嵌入(embedding)。向量嵌入是一种将文本信息映射到高维空间的技术,语义上相似的文本在向量空间中的距离也会比较近。
- 最后,你需要将这些向量嵌入存储在一个专门的向量数据库中,以便后续的快速检索。常见的向量数据库有 ChromaDB、Pinecone、FAISS 等。
2.检索 (Retrieval)
- 当用户提出一个问题时,首先需要将这个问题也转换成对应的向量嵌入。
- 然后,利用这个问题的向量嵌入在向量数据库中进行相似性搜索,找到与问题最相关的若干个知识块。这个过程就像在图书馆里通过关键词找到相关的书籍或文章。
3.增强生成 (Augmented Generation)
- 将检索到的相关知识块和用户的问题一起作为上下文(context)输入给 LLM。
- LLM 基于这些检索到的信息,结合自身的知识和理解能力,生成最终的答案。
RAG的架构
那么 rag 究竟是什么呢,我想,通过一些架构图来理解是最简单直观的,但架构图也需要一定的挑选,这里我选取两张比较容易看懂容易理解的图,来辅助理解。
来自 PAI-RAG 地址:https://github.com/aigc-apps/PAI-RAG
整个图的中心是大语言模型 LLM,RAG 的目标就是通过外部检索到的信息来增强 LLM 的生成能力,最终给出问题回答。整个流程可以分为构建知识库、检索相关信息和增强生成答案三个主要阶段。
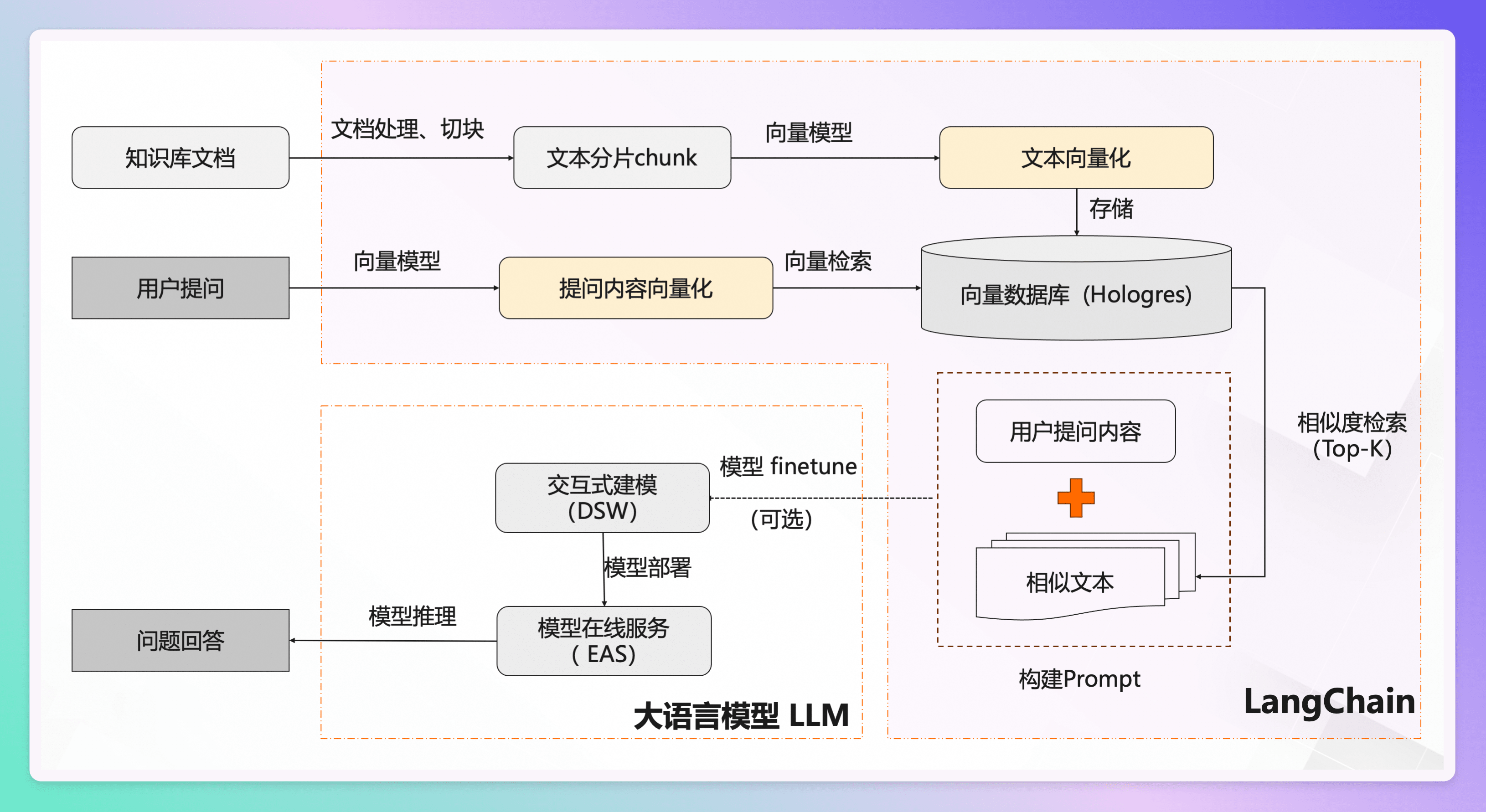
这张图清晰地展示了 RAG 的核心流程:
首先,将知识库中的文档转化为向量并存储。
然后,当用户提问时,也将其转化为向量,并在向量数据库中检索出最相关的知识片段。
最后,将用户的提问和检索到的知识片段一起作为上下文输入给大语言模型,让模型基于这些信息生成更准确、更相关的答案。
RAG应用场景
理论上,RAG 在开放域问答、智能客服、专业文档查询等领域有着巨大应用潜力。包括但不限于以下应用:
**1.智能问答系统:**例如企业内部知识库问答、专业领域问答、教育和研究等
**2.内容创作与增强:**例如辅助写作、新闻报道和内容生成、产品描述和营销文案生成等
**3.智能助手与聊天机器人:**客服机器人、个人知识助手、会议助手等
**4.信息检索与知识管理:**企业知识管理平台、搜索引擎优化
**5.代码生成与解释:**代码辅助生成、代码解释等。
6.多模态:图像、视频、音频检索增强生成: 未来 RAG 不仅限于文本,还可以扩展到处理图像、视频、音频等多种模态的数据,例如,用户可以提问关于一张图片的内容,RAG 系统可以检索相关的文本描述和背景信息进行回答。
如何利用RAG搭建个人知识库
RAG 的挑战
当你按照开源社区一些框架给的教程,做出了一个 rag 的 demo 之后,你会发现,所呈现的效果,可能只有真正理想的效果 50%都不到。
那么是什么问题,产生了这一不确定性呢?
检索质量的瓶颈: 如果检索到的信息与用户的问题相关性不高或者质量不高,那么即使 LLM 再强大,也无法生成高质量的答案。
上下文长度的限制: LLM 的输入上下文长度是有限制的,如果检索到的相关文档过多,可能会超出这个限制,需要进行有效的上下文压缩或选择。
知识库的维护成本: 构建和维护一个高质量的知识库需要持续的投入,包括数据的收集、清洗、更新等。
如何处理不相关或冗余的检索结果: 有时候检索到的信息可能包含噪声或者与问题关联不大,如何有效地过滤和利用这些信息是一个挑战。
复杂的推理问题: 对于需要复杂推理的问题,仅仅依靠检索到的片段信息可能不够,还需要 LLM 具备更强的推理能力。
RAG 是一种强大的技术,但在实际应用中需要仔细考虑其固有的缺点和挑战,并采取相应的策略来缓解这些问题,以构建更有效、更可靠的知识增强型 LLM 应用。