一、为什么需要分布式训练?
- 模型规模爆炸:现代大模型(如GPT-3、LLaMA等)参数量达千亿级别,单卡GPU无法存储完整模型。
- 计算资源需求:训练大模型需要海量计算(如GPT-3需数万GPU小时),分布式训练可加速训练过程。
- 内存瓶颈:单卡显存不足以容纳大模型参数、梯度及优化器状态。
二、分布式训练的并行策略
1、数据并行(Data Parallelism)
原理:将数据划分为多个批次,分发到不同设备,每个设备拥有完整的模型副本。
同步方式:通过All-Reduce操作同步梯度(如PyTorch的DistributedDataParallel)。
挑战:通信开销大,显存占用高(需存储完整模型参数和优化器状态)。
2、模型并行(Model Parallelism)
原理:将模型切分到不同设备(如按层或张量分片)。
类型:
横向并行(层拆分):将模型的层分配到不同设备。
纵向并行(张量拆分):如Megatron-LM将矩阵乘法分片。
挑战:设备间通信频繁,负载均衡需精细设计。
3、流水线并行(Pipeline Parallelism)
原理:将模型按层划分为多个阶段(stage),数据分块后按流水线执行。
优化:微批次(Micro-batching)减少流水线气泡(Bubble)。
挑战:需平衡阶段划分,避免资源闲置。
4、混合并行(3D并行)
组合策略:结合数据并行、模型并行、流水线并行,典型应用如训练千亿
级模型。
案例:微软Turing-NLG、Meta的LLaMA-2。
三、DeepSpeed框架介绍
1、基本概念
DeepSpeed 是由微软开发的开源深度学习优化库,专为大规模模型训练设计,其核心技术通过显存优化、计算加速、通信优化三个维度突破传统分布式训练的局限。
核心目标:降低大模型训练成本,提升显存和计算效率。
集成生态:与PyTorch无缝兼容,支持Hugging FaceTransformers库。
2、核心技术
(1)ZeRO(Zero Redundancy Optimizer)
原理:通过分片优化器状态、梯度、参数,消除数据并行中的显存冗余。
阶段划分:
ZeRO-1:优化器状态分片。
ZeRO-2:梯度分片 + 优化器状态分片。
ZeRO-3:参数分片 + 梯度分片 + 优化器状态分片。
优势:显存占用随设备数线性下降,支持训练更大模型。
(2)显存优化技术
CPU Offloading:将优化器状态和梯度卸载到CPU内存。
混合精度训练:FP16/BP16与动态损失缩放(Loss Scaling)。
其他特性
大规模推理支持:模型并行推理(如ZeRO-Inference)。
自适应通信优化:自动选择最佳通信策略(如All-Reduce vs. All-Gather)。
(3)优势与特点
显存效率高:ZeRO-3可将显存占用降低至1/设备数。
易用性强:通过少量代码修改即可应用(如DeepSpeed配置JSON文件)。
扩展性优秀:支持千卡级集群训练。
开源社区支持:持续更新,与Hugging Face等生态深度集成。
(4) 使用场景
训练百亿/千亿参数模型(如GPT-3、Turing-NLG)。
资源受限环境:单机多卡训练时通过Offloading扩展模型规模。
快速实验:通过ZeRO-2加速中等规模模型训练。
四、LLaMA Factory 分布式微调训练
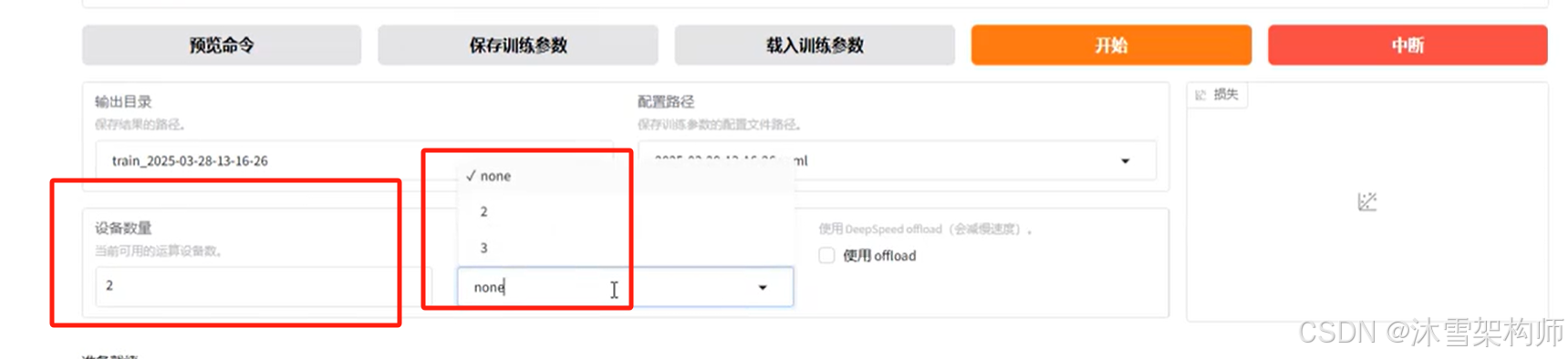
LLaMA-Factory 支持单机多卡和多机多卡分布式训练。同时也支持 DDP , DeepSpeed 和 FSDP 三种分布式引擎。
官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/advanced/distributed.html
服务器要有多个显卡,LLaMA Factory会自动读取服务器的所有显卡。
1、环境安装deeseed
pip install deepseed2、参数配置