简介:本文介绍SillyTavern(酒馆)角色扮演游戏的玩法。并考虑到AI模型服务商API的不稳定性,以及功能限制,本文演示基于本地系统与基于云服务器的AI模型搭建,为SillyTavern的使用提供API接口。文中将介绍SillyTavern的搭建即其原理;介绍AI模型框架,AI模型,并分析优劣与问题,同时推荐相应模型;介绍云服务器的选择并根据需求分析各云服务商和云服务器,以便读者选择;分别在Linux和Windows环境下搭建模型;介绍如何穿透没有购买公网的云服务器并通过转发API配置SillyTavern框架;
考虑到CSDN必须要登录才能阅读或复制全文,对很多读者颇为不便,这里贴出全文doc文档以供下载。这是本人服务器,访问即可下载全文。
![]()

特别通知:经过测评,通过自己搭建的服务器来跑模型,无论质量还是价格,都明显低于网络API.仅做玩票性质,并不实用,性价比甚至仅为网络API的十分之一.
另外如果租用云服务商的显卡,建议事先看好是否提供退款服务,或少量充值,以防后悔.例如AutoDL就不提供退款服务.

一、SillyTavern的搭建与原理
1. SillyTavern的介绍
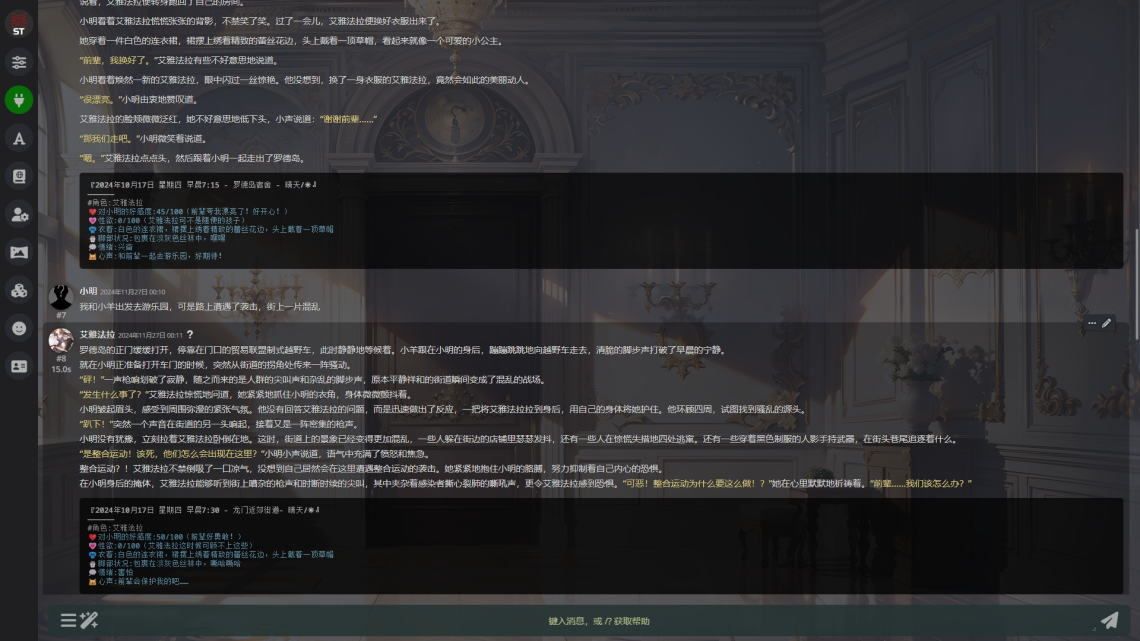
SillyTavern为许多LLM API(KoboldAI/CPP、Horde、NovelAI、Ooba、Tabby、OpenAI、OpenRouter、Claude、Mistral等)提供了一个单一的统一界面,适合移动设备的布局,视觉小说模式,Automatic1111和ComfyUI API图像生成集成,TTS,WorldInfo(传说书),可定制的用户界面,自动翻译,比你想要或需要的更多的提示选项,以及通过第三方扩展带来的无尽增长潜力。
SillyTavern(或简称 ST)是一个本地安装的用户界面,允许您与文本生成 LLM、图像生成引擎和 TTS 语音模型进行交互。
-----来自官方的解释
不过能点开看到这里想必对这类软件已经有了了解,所以就不多解释了。我们直接进入正题。
2. SillyTavern的下载与安装
网上的安装教程很多都是AI写的,所以我们直接跟着GitHub的安装流程走就好了。

如果对GitHub不熟悉的读者,可以阅读这篇文章,云API也可以参考他。
WINNAS轻松搭:SillyTavern(酒馆)从入门到精通 - 梦雨玲音
不过我想能用CSDN的用户,大都知道怎么食用GitHub吧?
3. SillyTavern的玩法介绍及其原理
考虑到能阅读CSDN的读者,大部分都是计算机相关的人士。咱们都是理工科的,没必要整那些虚的。所以就直接上这游戏的原理。
等看一遍这游戏的原理,以及角色卡、世界书(mod)的编写。一眼就能看明白这游戏怎么玩,马上就能入手了。
考虑到网上已经有这类视频很好的讲解,没必要听我在这里叭叭,所以我们直接放视频链接。
sillytarven/酒馆 创建角色卡基础0_哔哩哔哩_bilibili
sillytarven/酒馆 创建角色卡基础1 世界书和状态栏_哔哩哔哩_bilibili
sillytarven/酒馆 创建角色卡 平然/常识修改_哔哩哔哩_bilibili
这个是安卓手机上的操作。
考虑到新人可能一时间找不到资源,下面我们再补充一些卡包,这些是我从群里找到的,链接是群里提供的,你们看情况下载就好。
4. SillyTavern的原理及相关社区
qq上搜一下群,或者贴吧。
不过目前由于某些原因,现在类脑和拟人现在关闭了新人入群的渠道,等后面应该会开放。(写文时是2025/2/6)
考虑到一些问题链接都删了。
如果不知道Discord的话,就自己搜一下相关信息,这里不好讲太细。
5. SillyTavern在Linux云服务器上搭建
考虑到本地每次都要点开很麻烦,还好那些服务器云商有新客优惠,比我我这台一年29还是39忘了。似乎是在华为云?反正这些云商现在已经被我薅了个遍。你们挨个看看哪个便宜就行。
另外,不要买大陆的服!不然下载的时候会遇到各种麻烦。推荐港区。
如果实在不想掏这钱的话,就走内网穿透吧。家里找个不要的电脑把SillyTavern跑起来,然后用软件内网穿透。注意Windows要开防火墙。Linux...Linux下面我们会讲。
我用的是debian 11,你们最好买ubuntu22.04以上,垃圾debian 11,apt的nodejs是v12,等会安装会比较麻烦。
总之你们直接从官网git clone。
如果不慎租了大陆的服,那就像我一样,直接给他压缩包下载下来。
![]()
下载下来之后,不管你们是用winscp也好,还是其他什么也好,总之上传上去。
输入unzip文件名,直接解压。
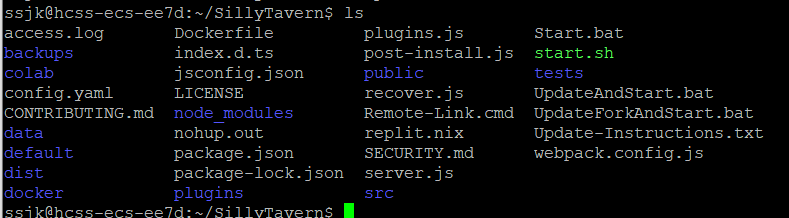
然后可以看到这些。
直接./start.sh运行。
它会自动安装nodejs和npm之类的环境(大陆的服的话,就多试几次,可能就ok了)
你用apt安装如果版本低的话,比如我这儿是12版,那就不行。看要求至少要22版的。
我试过从官网上把nodejs考下来(大陆服就下不下来,我是从本地下载的二进制文件,然后本地上传上去的),whereis查一下,然后挨个放进/usr里。但是nodejs不认。

所以只能让它慢慢下了。
总之你运行通过后,
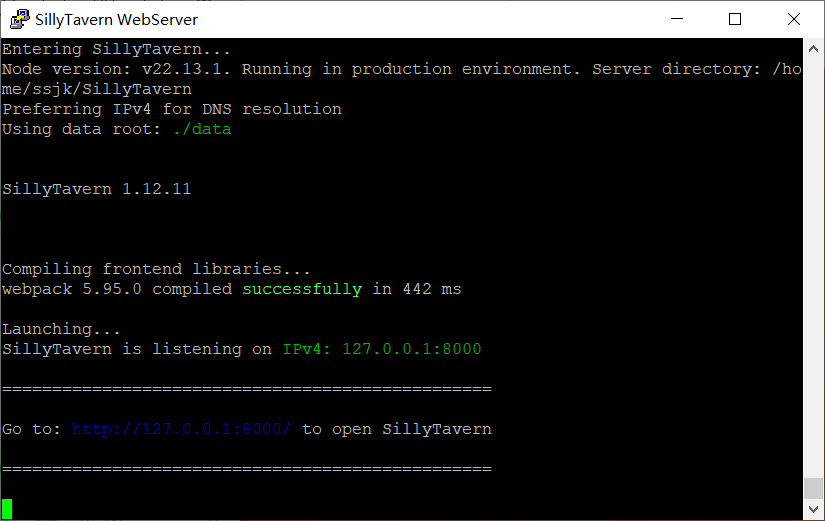
会给出这个页面。
然后你ctrl+c,终止之后,改配置文件。
vim config.yaml
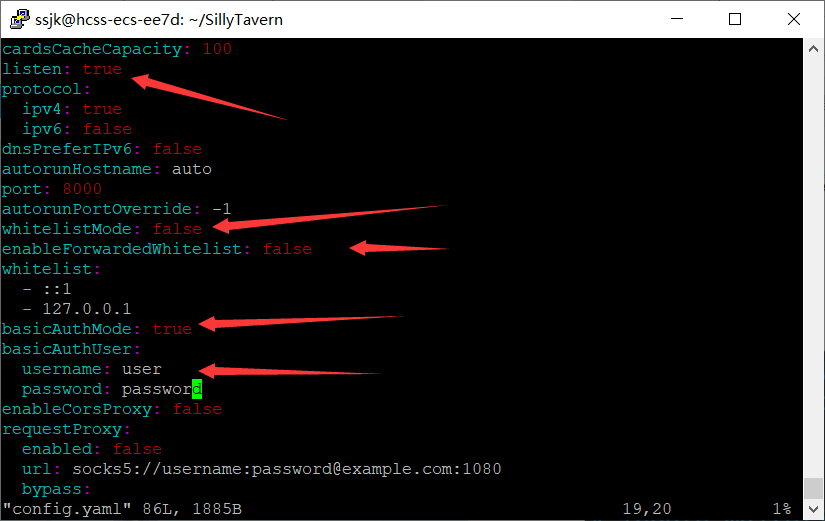
改成我这样的就行。
我用户名和密码是默认的,懒得改了,你要改的话要加双引号!!!
例如
username: "woc"
password: "azhe"
改完之后,运行,输入账号密码,上去看看管不管使。(默认用户名和密码就是user password)
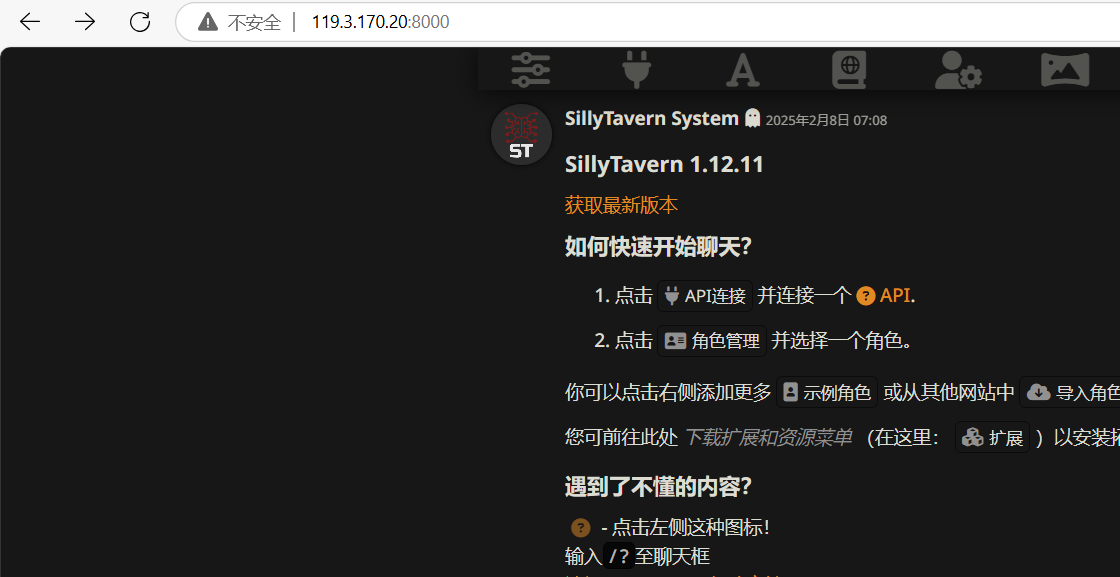
管使了,我们
终止之后。
nohub bash start.sh &
给它调到后台运行,然后就可以exit了。
ps.另外有个怪事,我试图
ctrl+z,给这进程先暂停调到后台。
然后
bg jobspec %1
disown -h %1
先让它在后台运行起来,然后再让它从终端里面滚蛋,挂靠到系统上。
用jobs可以看到它不在jobs里了。
不关终端还能跑,但是一关终端,服务就宕机了,没搞清楚是怎么一回事,等日后有时间了研究一下。不过这套玩意太拉胯了,你们要用的话,建议还是用tmux吧。。。
二、AI模型框架和AI模型的选择与本地搭建与云服务器的选择
1. AI模型常识与推荐
原本我想仔细写写,但是想了想还是算了,直接放个看过的文章。这比我再嚼一遍喂给读者会保留更多原有信息。
【极简+全面+网盘】windows快速部署角色扮演大模型 - 哔哩哔哩
具体我也不好写太细,后面你跟着这些模型慢慢找相关信息就ok了。
这是我的这几天搜索的比较有趣的模型(很多我也没试过,想玩玩的可以试一下)
https://huggingface.co/cgxjdzz/Qwen-2.5-7B-Instruct-novel-lora
saiga_nemo_12b
https://huggingface.co/mradermacher/Dans-PersonalityEngine-V1.1.0-12b-GGUF/tree/main
Cydonia-v1.3-Magnum-v4-22B
本地大模型推荐
magnum-32b和magnum-72b v2
注意推荐v2版本,v4版本则是想象力丰富但智商降低
这个系列模型基于阿里巴巴的qwen,中文很不错
是比较万金油的模型,非常适合404
vathene-v1.2.i1-IQ4_XS
turbcat-instruct-72b
中文不错,更拟人的模型,适合扮演具体的,性格鲜明的角色进行对话,但不适合系统类,世界类等npc较多,逻辑需求交给的场景,也不是很擅长写旁白剧情
hf-mirror.com/Sao10K/72B-Qwen2.5-Kunou-v1
hf-mirror.com/sophosympatheia/Evathene-v1.3
hf-mirror.com/blockblockblock/turbcat-instruct-72b-bpw4.6-exl2
据说中文任务量和英文一样多。
hf-mirror.com/Doctor-Shotgun/L3.3-70B-Magnum-v4-SE
据说角色扮演优化。
hf-mirror.com/Sao10K/L3.3-70B-Euryale-v2.3
hf-mirror.com/mistralai/Mistral-Nemo-Instruct-2407
网上说12b可当70b使,我不太信。
hf-mirror.com/MarinaraSpaghetti/NemoMix-Unleashed-12B
https://hf-mirror.com/ValueFX9507/Tifa-Deepsex-14b-CoT-GGUF-Q4
国产cosplay小模型,日后可以试试。
https://hf-mirror.com/Tifa-RP/Tifa-7B-Qwen2-v0.1-GGUF
国产小模型
最近找到了专门讨论AI模型的社区,社区中有大佬对市面上的模型进行测评,比我一小白详细的多了。
下面我就直接放大佬的测评链接。
(已删除)
再后面教程中我推荐的模型不必理会,那都是几天前的我,几天前的我还是个菜。
3. 两种AI模型框架ollama与lm studio的比较
ollama下载模型方便一点,直接换镜像网址就ok了。ollama对Linux的支持非常好,没有图形界面也能用。例如你从云服务器哪儿租了个显卡,而对方只提供给你个终端CLI,至少你不用倒腾装图形界面vnc之类的东西。
lm studio的话,你要替换文件,比较麻烦,或者你到huggingface上下载下来模型,然后本地导入进去。对Linux的服务器非常不友好,因为这玩意的运行必须要有图形界面。大多数云服务商不提供,你要手动安装图形界面,然后用vnc连过去。
后面这两种我都会介绍到,你们看需求选用就好。
4. huggingface的介绍与镜像
简单来将,你可以把他当一个模型共享网站就行,想要什么模型,有人共享出来,你就能下载下来跑。当然官网在国外,考虑到下载速度,一般我们用国内的镜像站HF-Mirror。
简单来说,如果有人分享模型,你直接在上面搜名字就好。
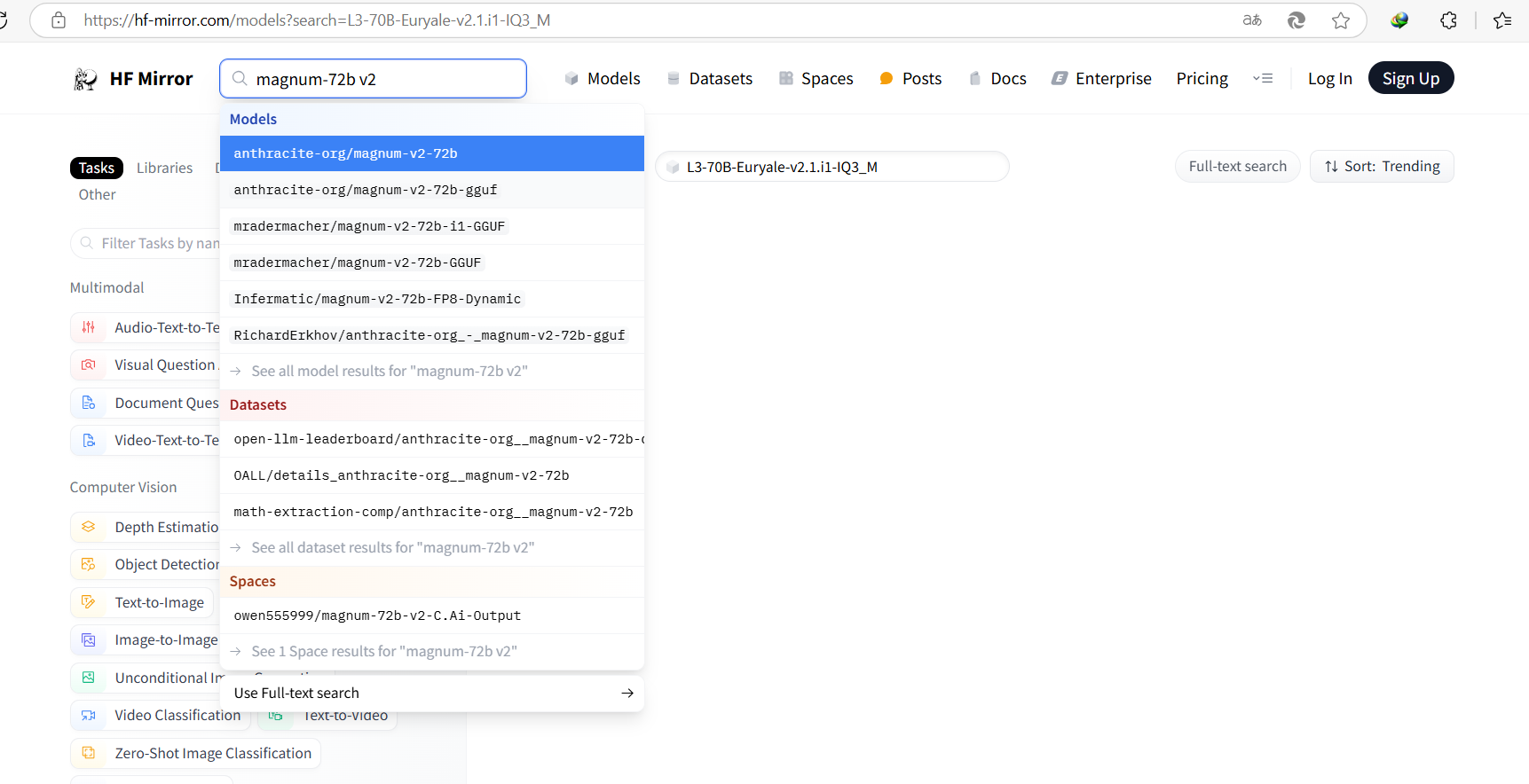
点进去就能看到模型简介。
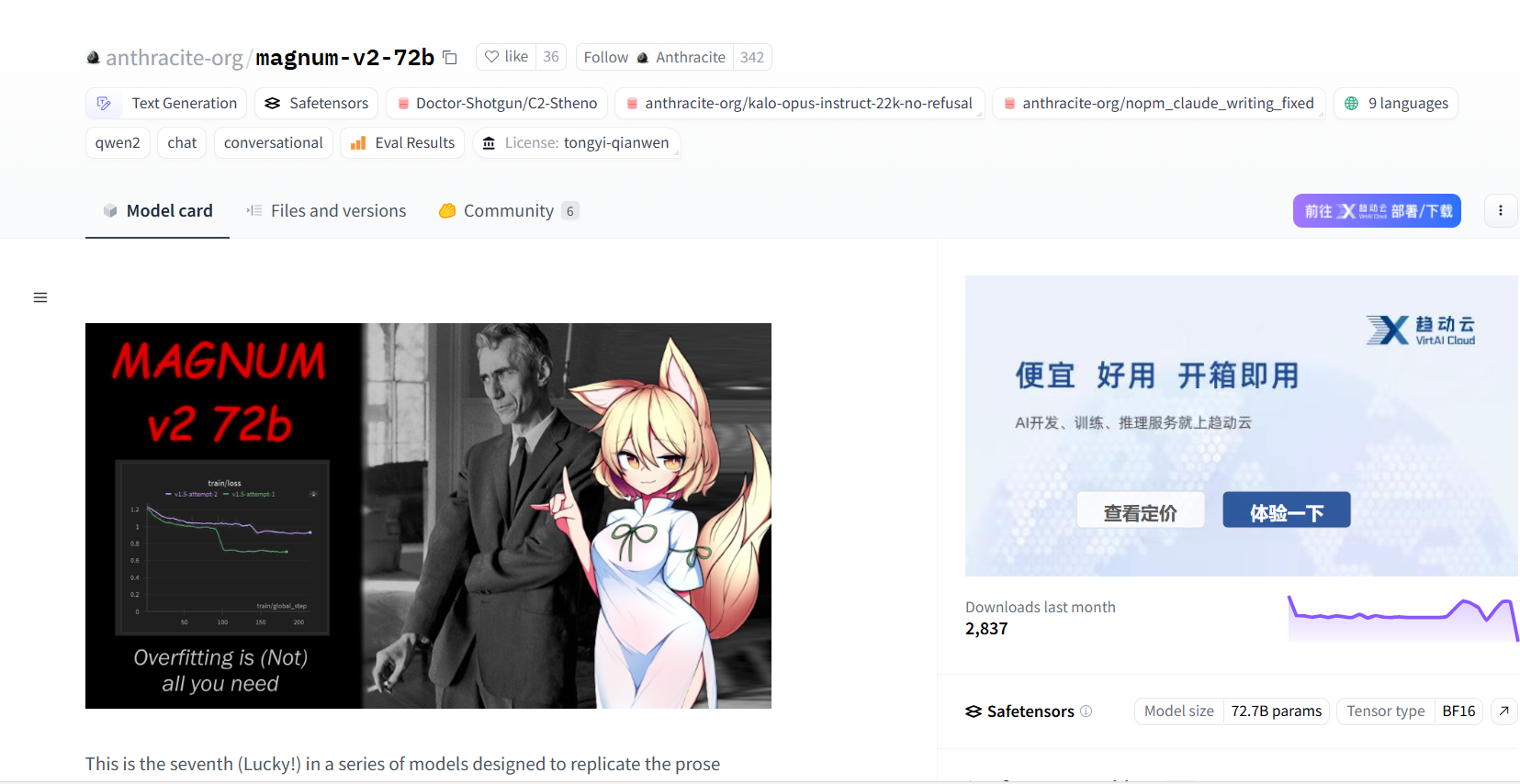
这儿可以找到他发布的相关模型。
这儿可以找到量化对应的模型,相信看了前面链接里的教程,你应该知道量化是啥。(如果提供的话)
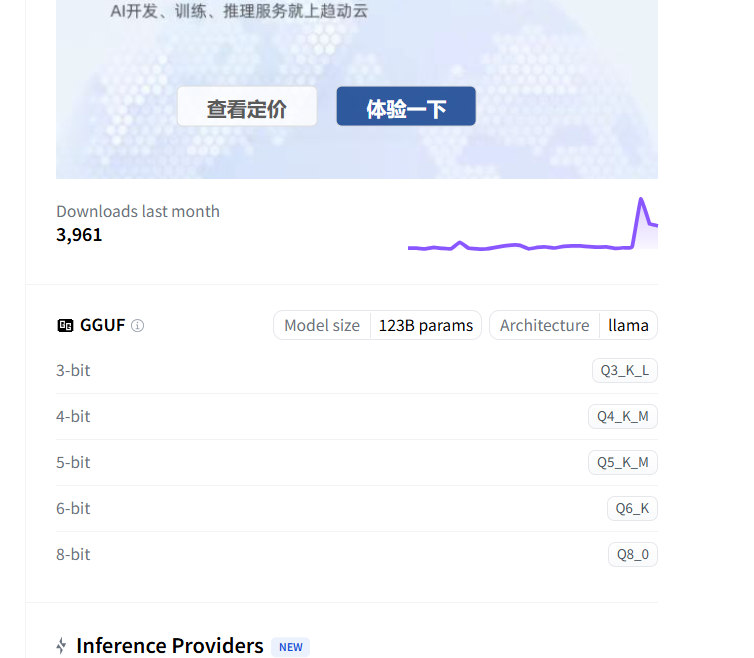
点击之后,例如点击Q4_K_M进去之后,可以直接把模型下载到本地(看到那个Download没?
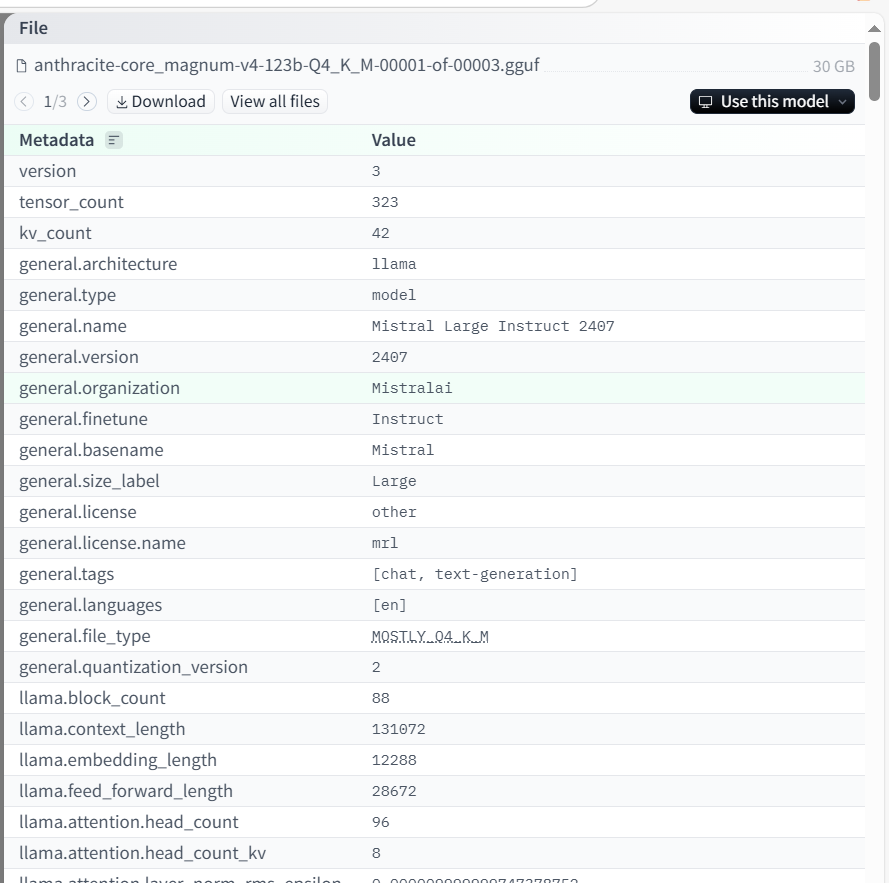
gguf是指gguf格式。
你也可以中这里下载。
如果直接下载的话,我推荐用IDM,至少下载的快一点。
5. ollama搭建与运行模型
访问ollama的官网,直接下载,安装就行。
ollama的安装和下载非常傻瓜化,windows上就是下载之后,下一部下一步,Linux就是执行他提供的那条命令就行。
如果实在看不懂的话,可以看他的文档。
【极简+全面+网盘】windows快速部署角色扮演大模型 - 哔哩哔哩
安装完之后,打开cmd,直接输入ollama,如果出现提示就说明安装成功了。
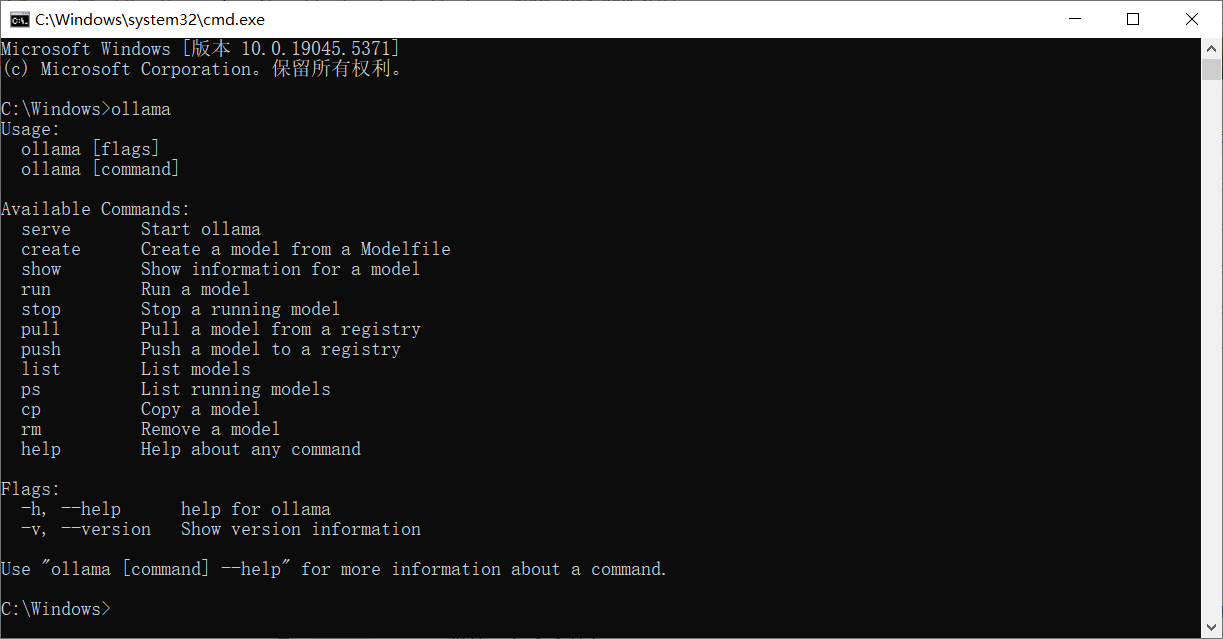
如果提示没有运行,你就输入 ollama serve 运行就行了。
用ollama下载模型的话,你首先知道要下载的模型叫什么。
ollama推荐了一些常见的模型(不过那些模型不适合我们玩),所以,你拿到别人推荐的模型名后。到huggingface的官网上,查他的名字。
例如别人推荐了个叫Dans-PersonalityEngine-V1.1.0-12b-GGUF的模型。
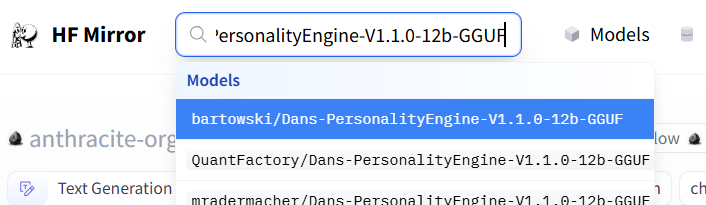
你查到之后点进去。
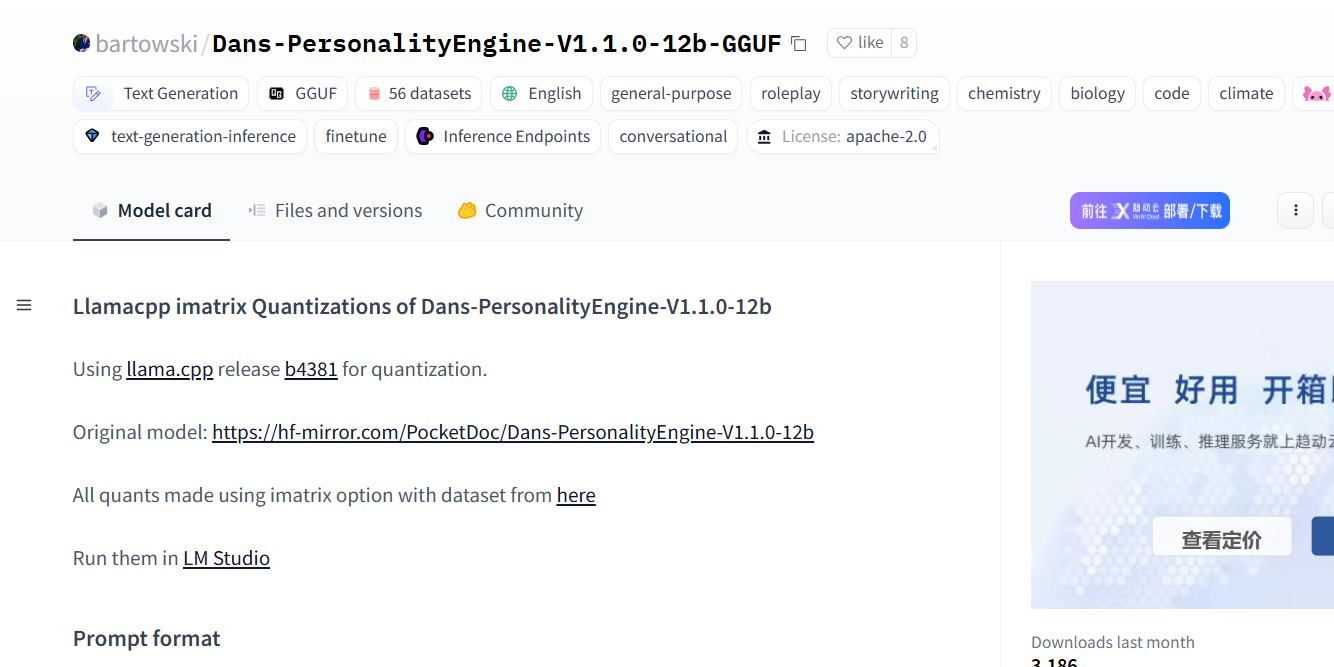
可以看看他的介绍(如果想看的话)
然后直接复制这些
再看下面的量化参数,选一个你想要的参数,例如我打算下个最小的IQ2_S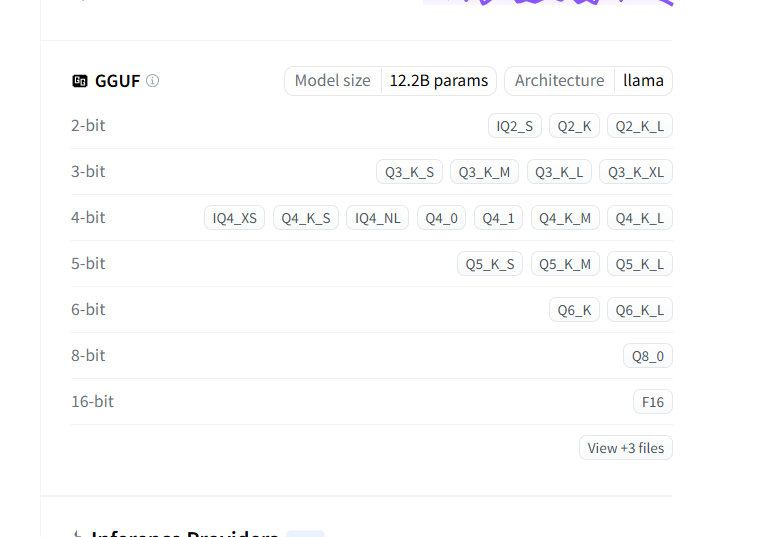
然后就在cmd里写,注意IQ2_S前面要用冒号。当然如果不带参数的话就会下载推荐的默认模型。
有时候模型没有给你提供量化的选择,你就直接写网站,下载默认的就行。

如果成功的话,你可以看到他正在下载。
下载完成后,输入ollama list可以查看下载到本地的模型。(我就不下了,占空间)

可以看到我这儿下载了两个模型,一个llama3.2一个就是之前说的那个。
你想运行的话,就输入ollama run [模型名]就好
退出的话,就输入/bye就行。
当然这只是退出对话,你想终止模型运行的话,就输入ollama stop,如果不知道运行有哪些模型的话,就ollama ps查看,删除模型的话就ollama rm。
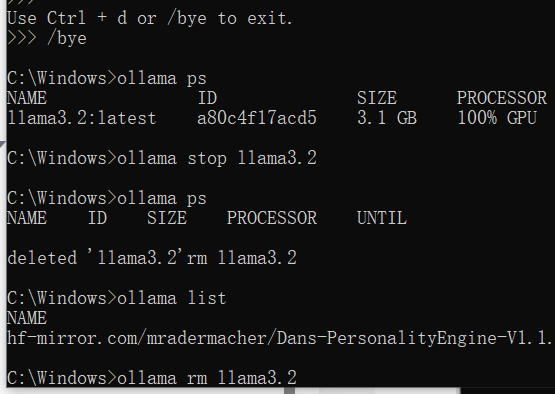
(之前卡了一下删除命令没有截到,不过看看就好)
如果你忘了这些命令的话,直接输入ollama执行就能查看有什么命令。
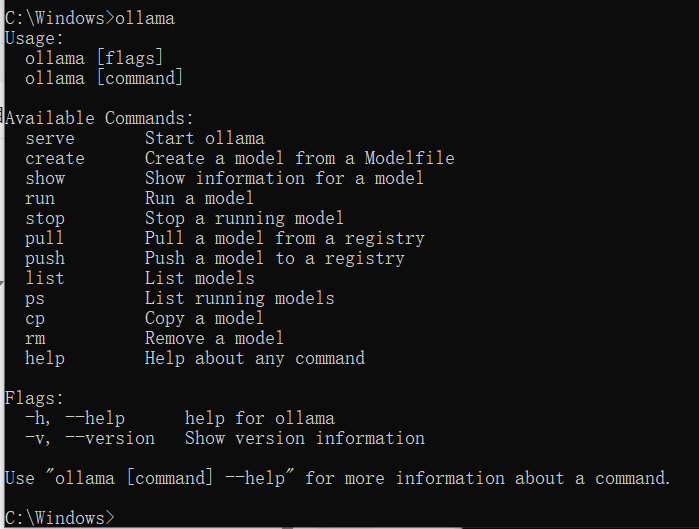
上面几个就是最常用的。
至于模型下载路径,这里懒得演示了,直接扔别人写好的文档
【deepseek-r1】ollama如何更改安装位置以及自定义模型下载位置-CSDN博客
至于Linux用户,应该有自己查找资料的能力,我就不画蛇添足了。
ollama模型运行之后,本地会默认生成一个api,就是127.0.0.1:11434。
你在浏览器访问可以看到
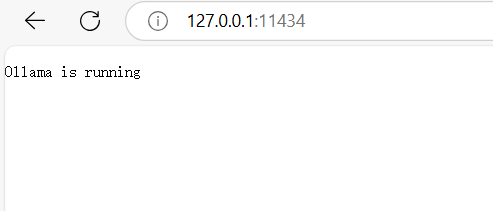
不论你有没有运行AI模型,只要框架跑起来,都可以看到这个。
6. Im studio搭建与运行模型
至于lm studio就更简单了,
LM Studio - Discover, download, and run local LLMs
官方进去之后,选择安装包,然后下一步下一步就行,下载完之后都是图形界面。
进去之后,你会发现模型找不到,不用担心,这是国区特色。
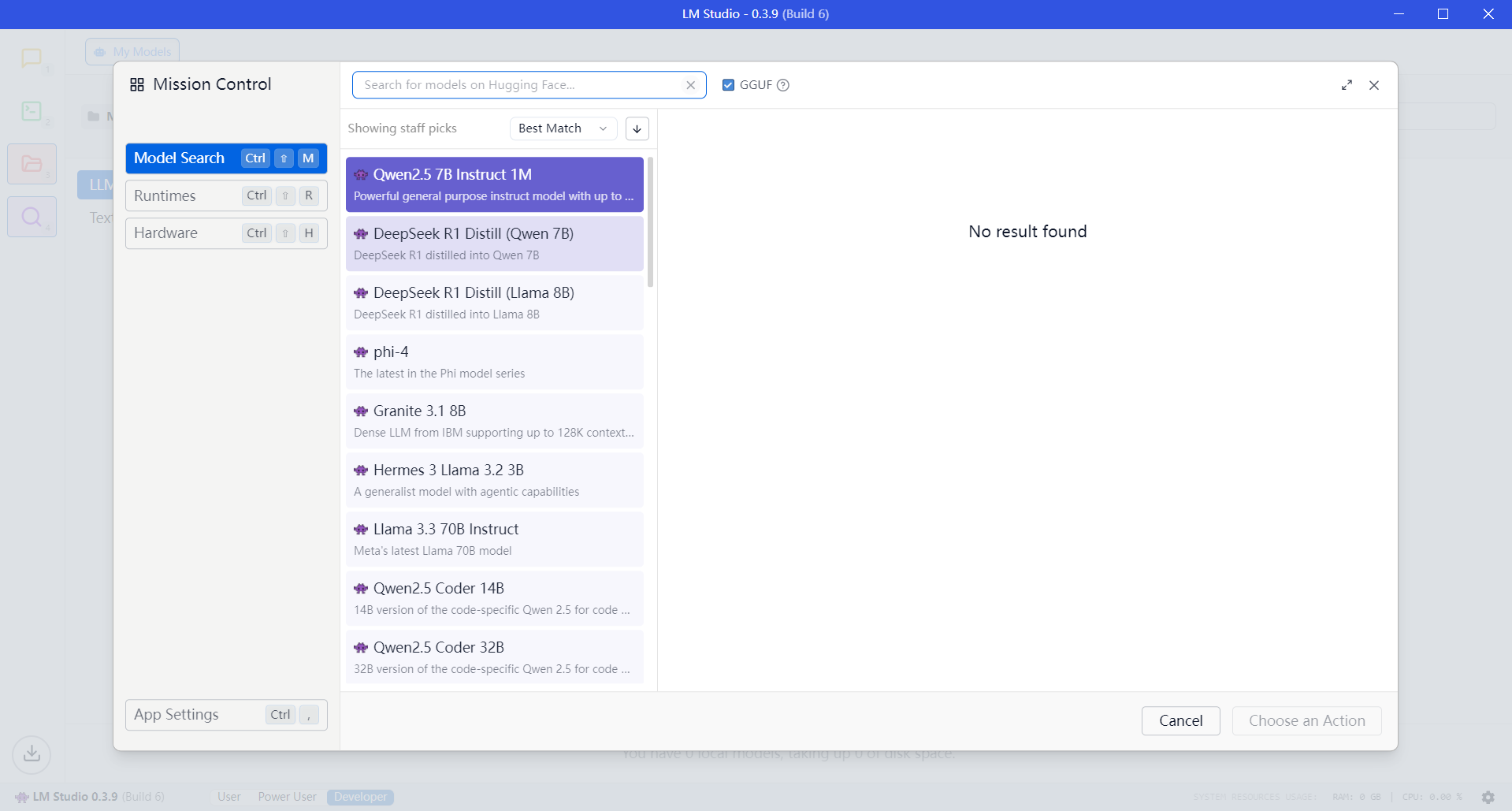
设置起来比较麻烦,我们直接在网页下载之后导入即可。
之前有讲过如何从huggingface即其镜像网站上下载,这里我们就简单演示一下如何导入模型并运行。
确定已经安装完了lm studio之后,我们还是打开控制台。
然后输入lms,这玩意是lm studio自带的命令行工具。
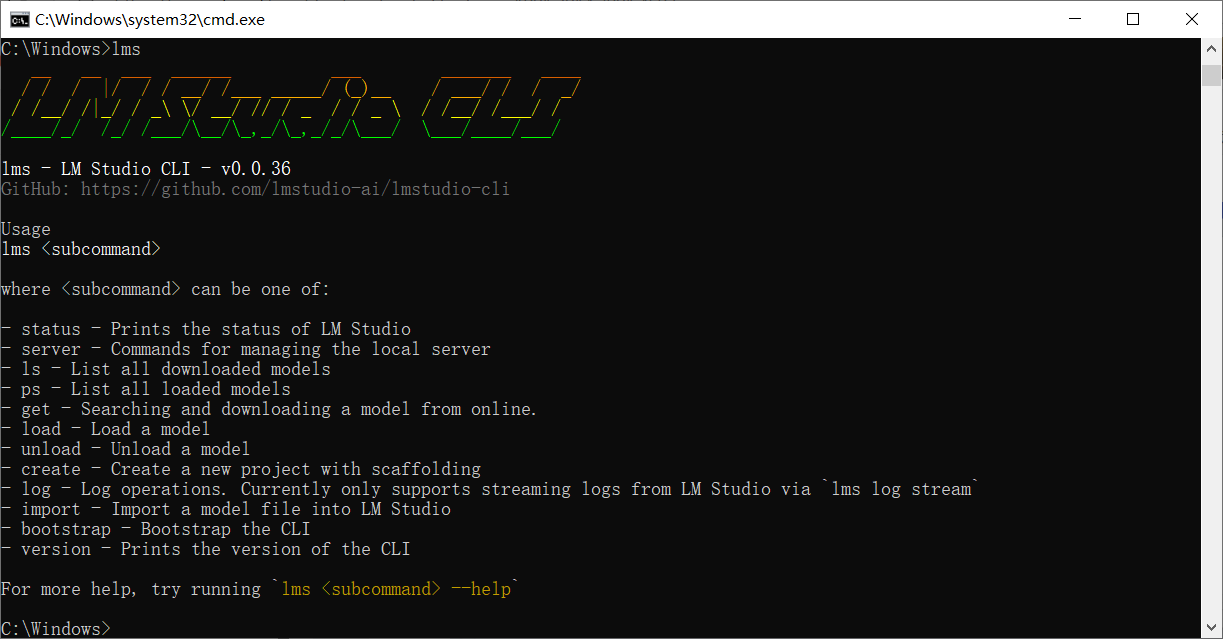
然后,我们输入lms import 模型 就ok。
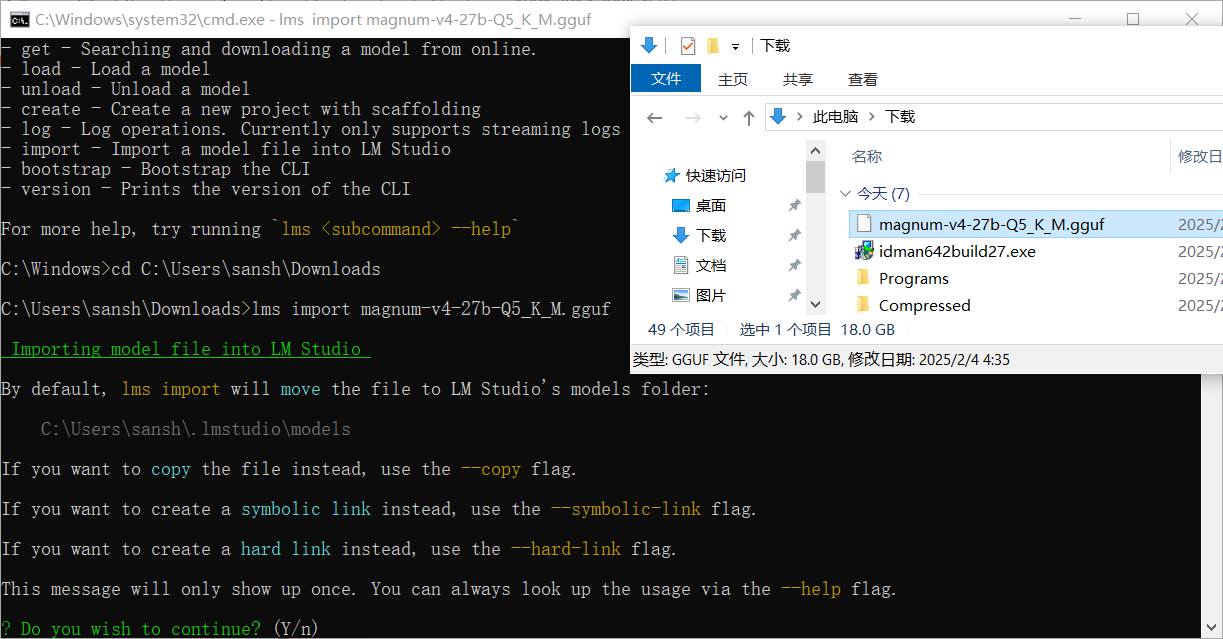
它会问你是否继续,你回答y就行。
然后用上下左右选,选第二个就行。

懒得解释了,直接截图翻译。
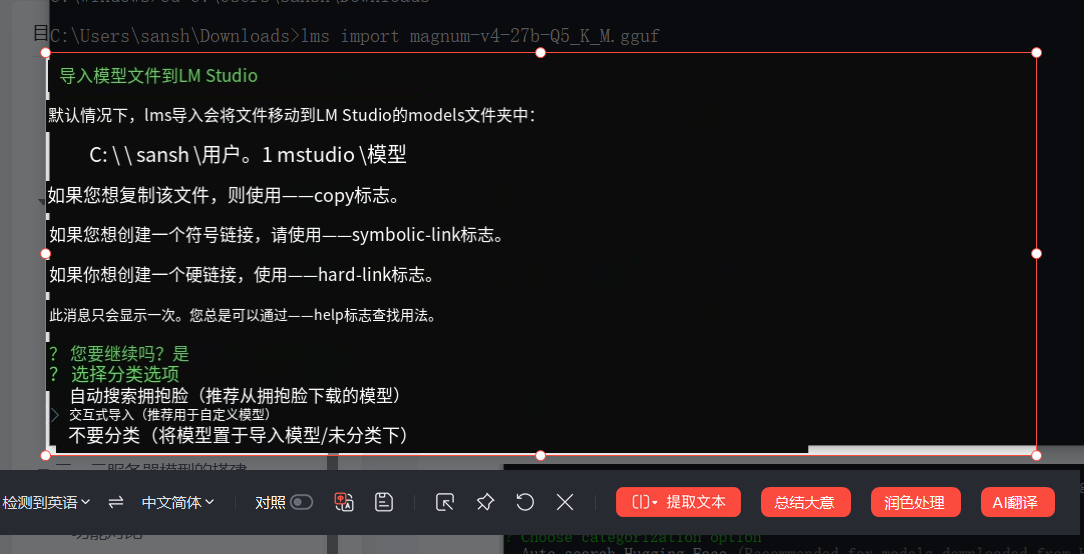
第二个选择好后,剩下的回车就行。

会告诉你已经移动成功了。
然后进去之后,我们就可以在这里看到模型。
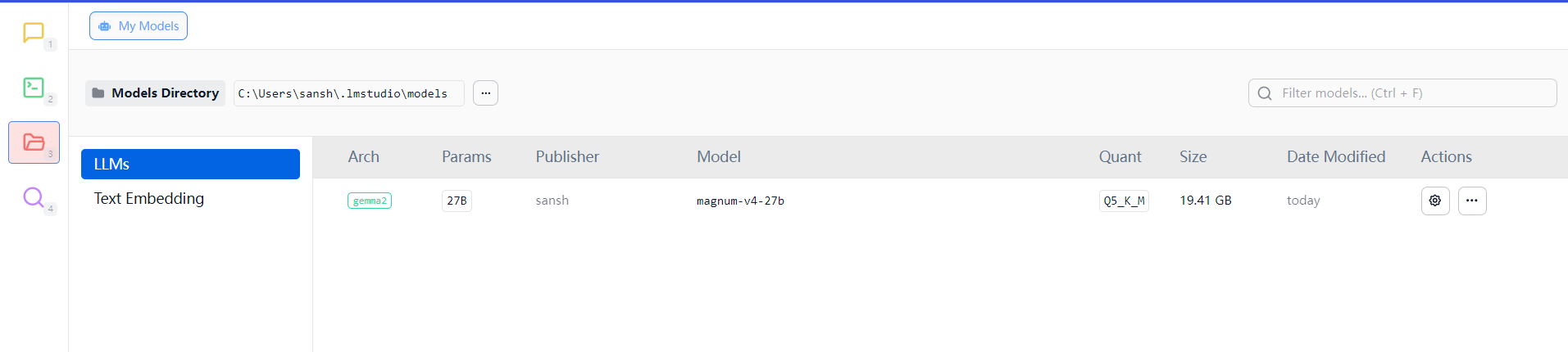
然后我们点坐上角第二个那个绿色的块块,进入这个界面。
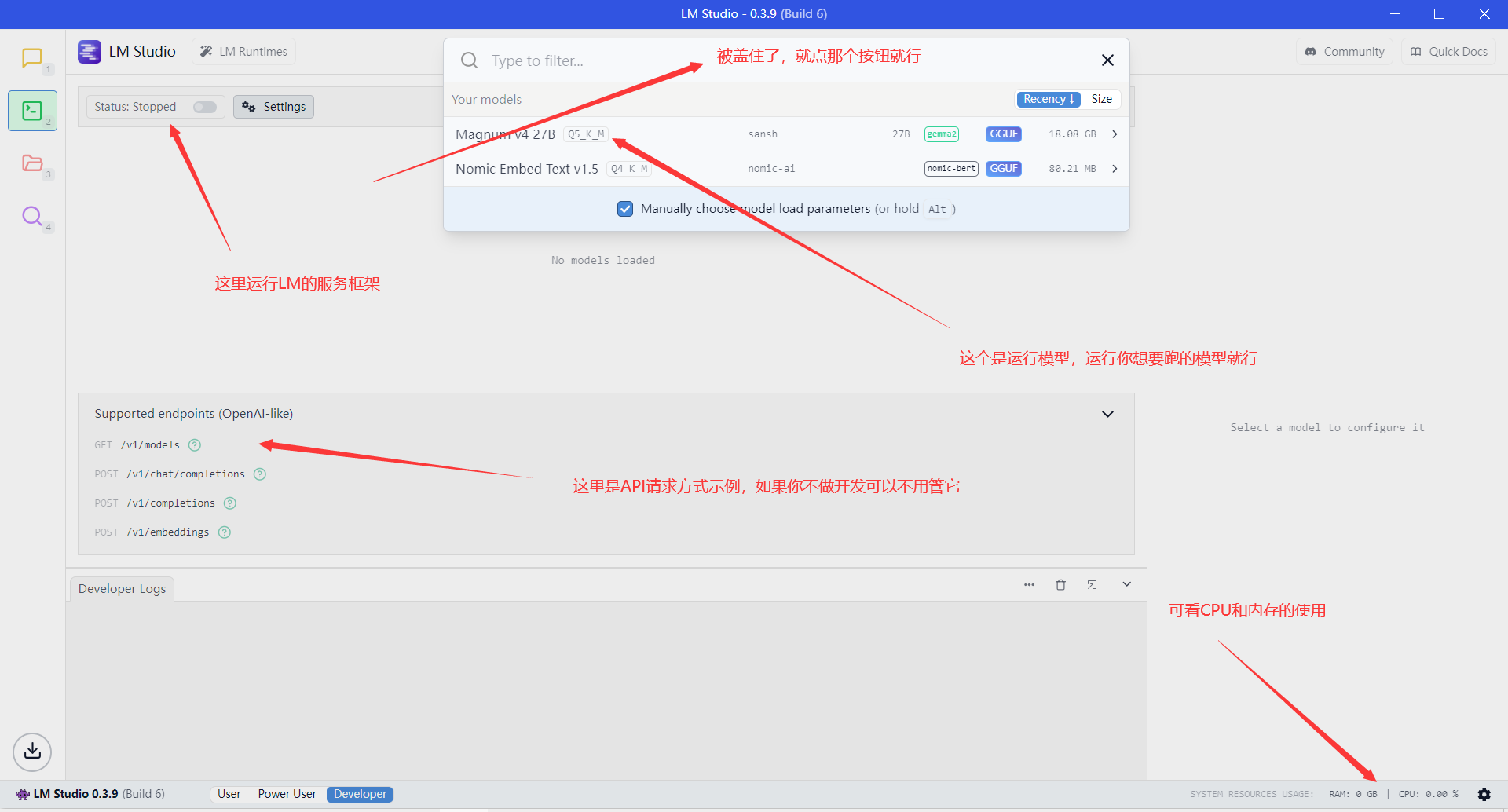
可以按照上图方式运行模型,
考虑到我是用笔记本跑的,性能比较渣,就不用大模型演示了。框架和模型无所谓先后,你也可以先把模型跑起来,再运行LM框架。
然后就要配置模型的运行。一般来说默认就行,重点是上下文,就是2048那个,你要是跑角色扮演的游戏的话,就把那个调高点。(当然我这个是小模型,最高有效就只能2048,建议你那至少调8192)。剩下的选项你要想了解,鼠标移过去,然后会弹出英文,你用翻译软件慢慢翻译就ok。
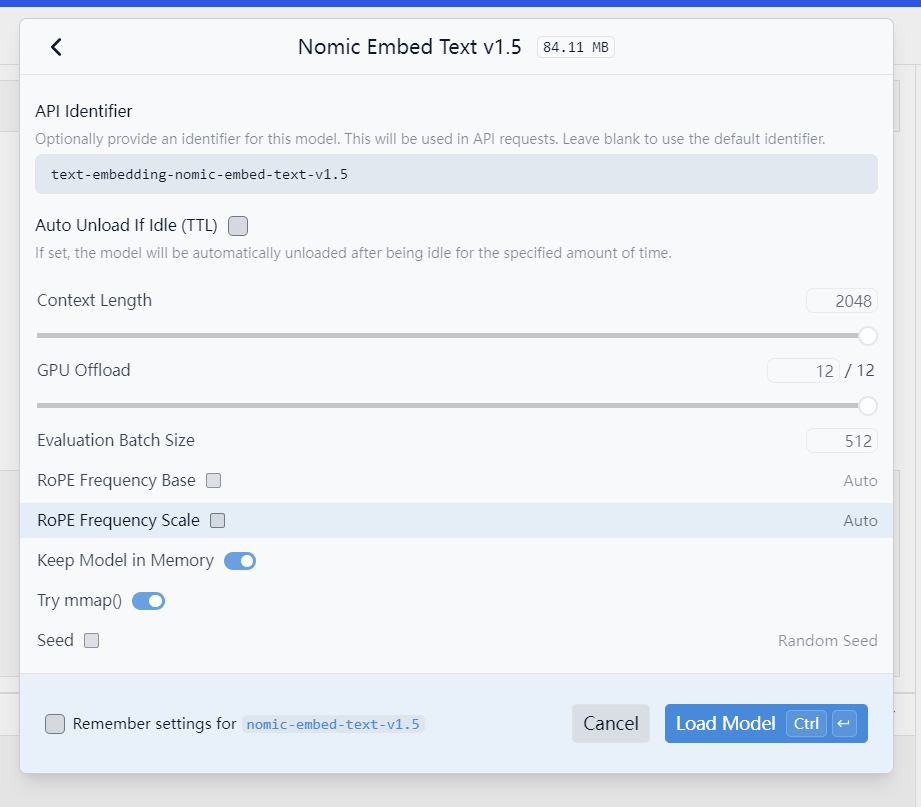
最后点load model就能运行模型了。
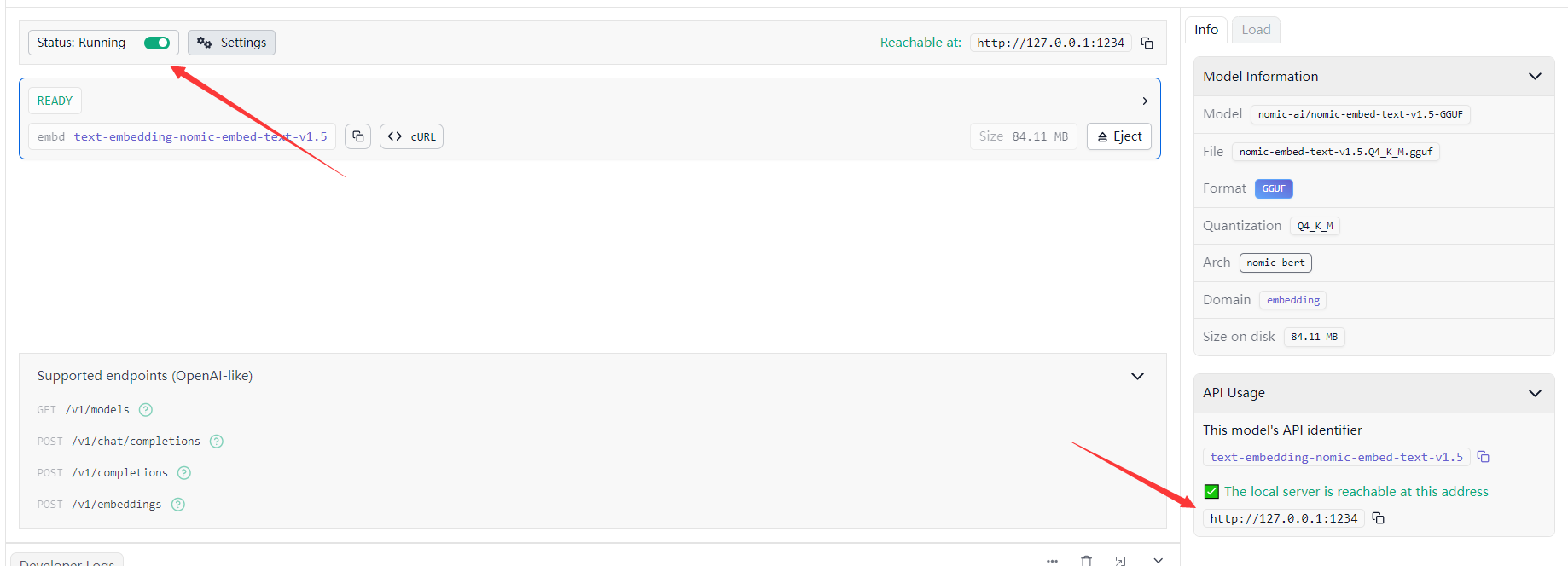
然后把框架也跑起来。跑起来之后,它会给你个ip地址和端口,这个是本地的(你可以用frp之类的软件映射到外网什么的),这个就是API了。
你把模型跑起来之后,可以直接进去聊天,选中你运行起来的模型就行。我跑的是小模型,不支持这个,只是演示一下(笔记本电脑太渣,跑不了27b的)这个至少要rx580 8g显存+32g内存才能勉勉强强跑起来,大概1秒2-3个字符。
7. SillyTavern接入本地API
不论是ollama还是lm studio,把AI模型跑起来之后。拿到API(就是那个IP地址和端口)
ollama默认的是127.0.0.1:14434
lm studio默认的是127.0.0.1:1234
拿到这个之后,之前SillyTavern安装好后,会弹出页面,点那个插头图标。(如果之前关掉了的话,还是运行start.bat就能重新打开)
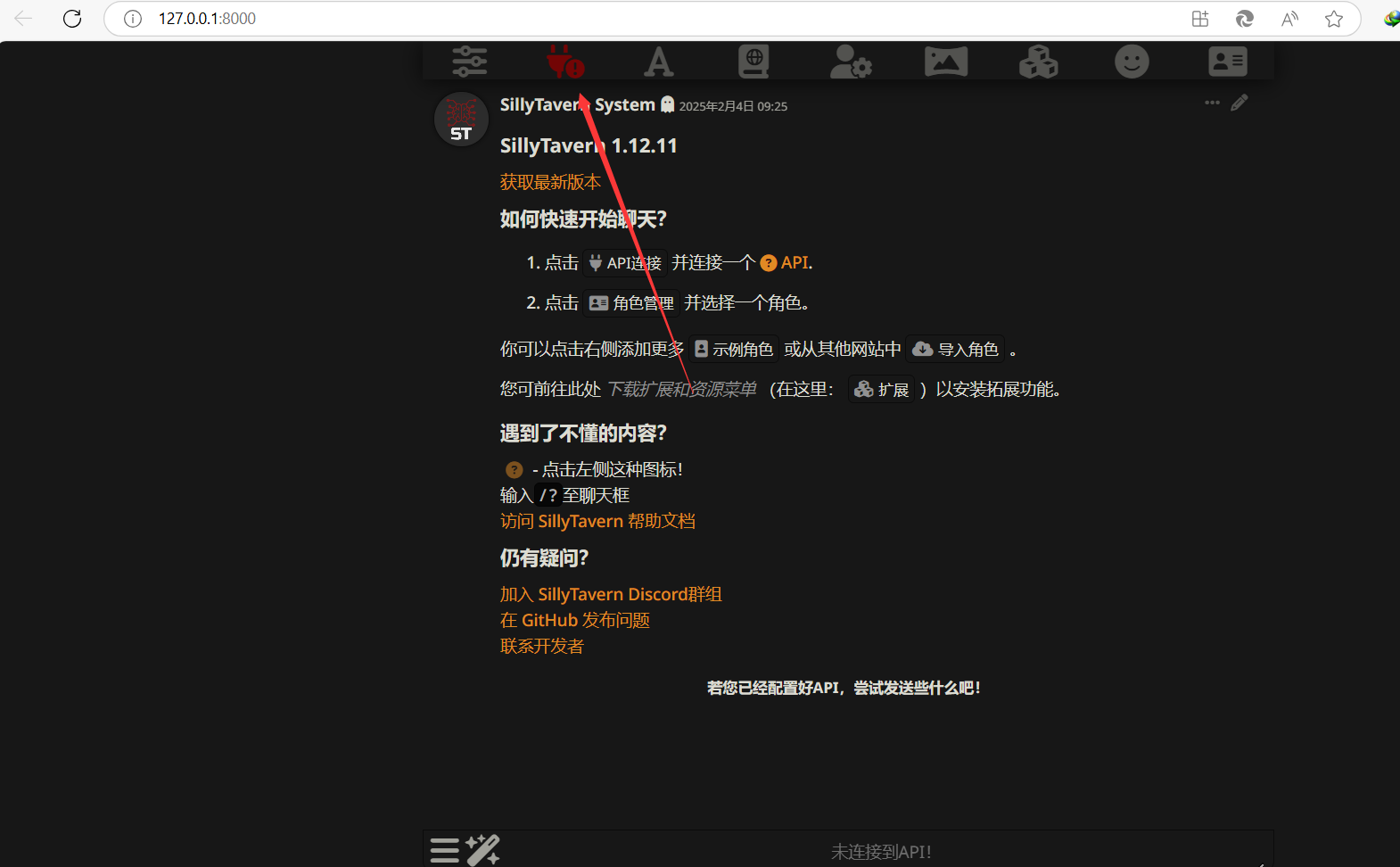
然后会让你选API,(聊天补全就是一个字一个字蹦,文本补全就是等AI写完了一下再直接全部显示),自定义兼容openai就行。
自定义那个你就按他的提示把你的127.0.0.1:端口,按它的格式填进去,剩下的都不用管。
然后点击链接,我推荐先切到文本补全的选项,因为他的连接可以测试。
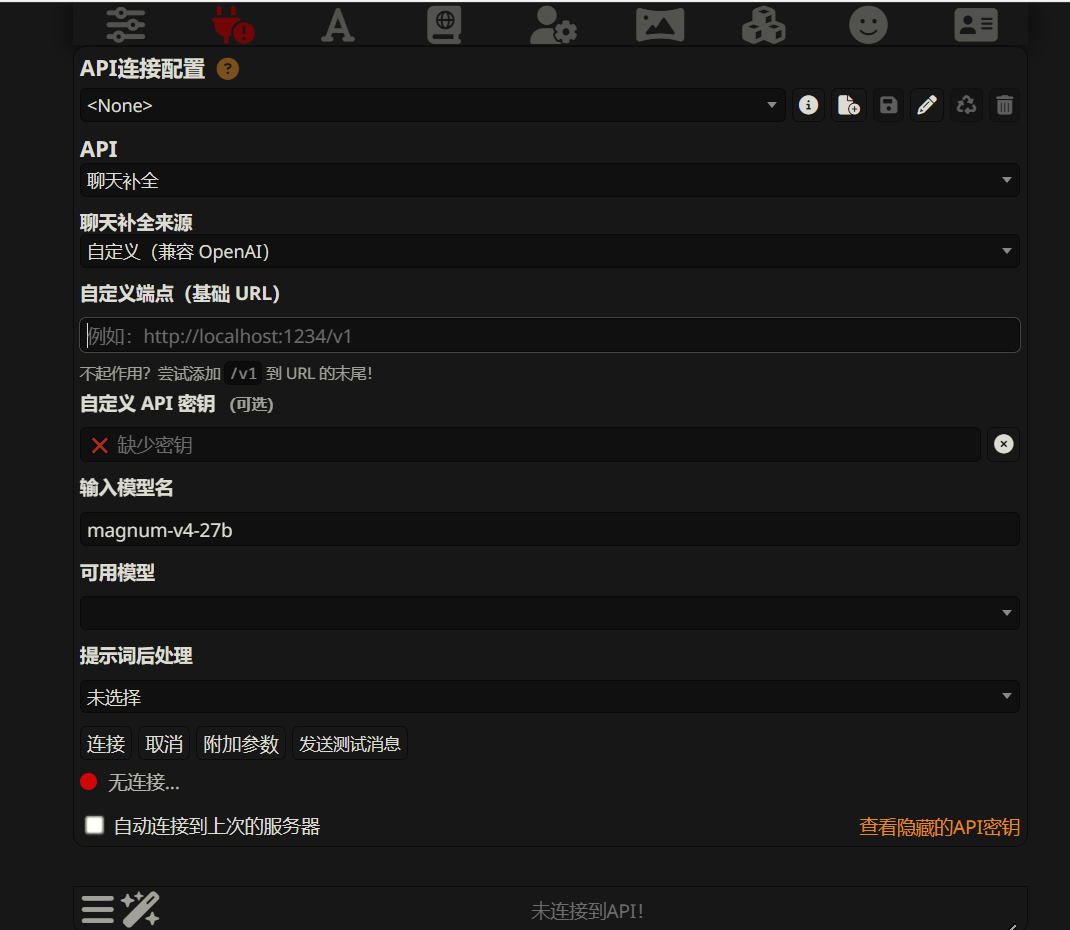
你填好之后,直接点连接就可以测试有没有连上。
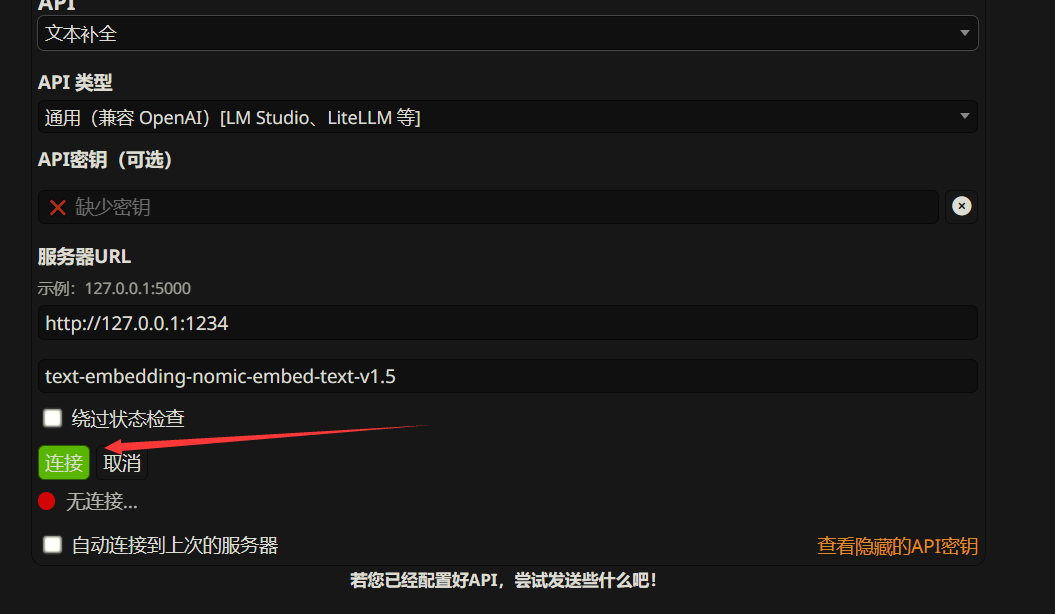
如果连上的话是绿色,红色就是没有连上或出问题。
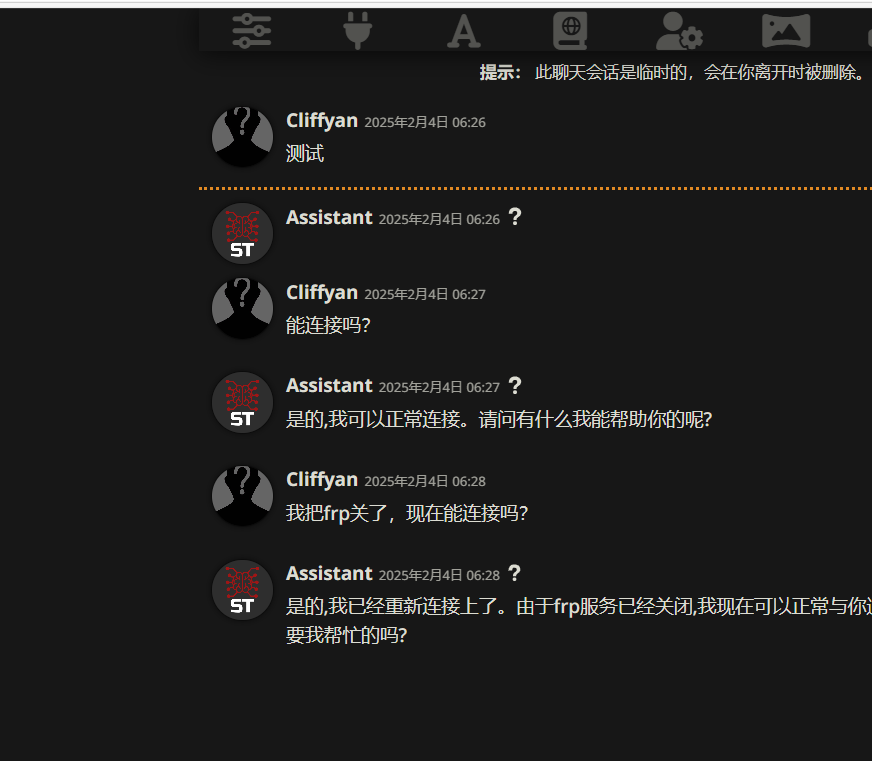
连上之后,可以发点对话测试一下。
连不上的话...慢慢排查问题吧。>_< 我折腾这些也花了两天两夜。
三、云服务器模型的搭建
1. 各个云服务商的性价比与常用功能对比
目前经过我的测试,找到以下几个性价比比较高的,
矩池云:他的4090*24g 200g数据盘 2.8元 好处是硬盘较大,一般70b的模型,文件大概一百多g。且数据盘可以叠加,例如你租两份,硬盘大小也扩大两倍,但400g也没这必要。还有个好处就是自带十来个http映射,你不需要再搭穿透了(当然服务商官方的穿透有点危,你待确定你模型跑出来的数据合不合适。)。坏处就是价格贵,而且没有无卡启动低配下文件的功能(例如autodl,可以用1毛1小时的价格,先下文件下一天)
恒源云:他的4090*24g 50g硬盘 1.6元(似乎目前在搞活动),价格便宜,是目前见过最便宜的,但是无卡启动需要lv2,大概待冲1000,相当于没有。而且硬盘只有50,扩容到200的话一天1.44元,150的话一天1.16。硬盘不用释放时间,15天。
autodl:他的4090*24g 50g硬盘 1.88元,价格也还便宜。硬盘+150g,1天1块。可以无卡启动,1小时1毛钱,这是最大的优点。硬盘不用,释放时间15天。
算力云:他的4090*24g 200g硬盘 2.24,价格偏贵,但好处是硬盘大,至少130b q4的模型,不需要硬盘扩容了。缺点是网络不好,而且不能无卡启动。最大的好处是提供windows系统,至少对小白来说配起来比linux简单不少。硬盘不用,释放时间7天。
以上云服务商,你在百度上搜一下就能找到,
2. 在Windows上搭建模型,并穿透(基于lm studio)
windows上搭建,前面已经讲过了,远程用起来,也无非是用电脑上的远程桌面连接去连那个服务器。这个实在太基础了,都不知道怎么讲。
连接之后,在远程桌面上安装lm studio,这个和本地安装一模一样。(你们可以在本地先安装之后,跑个小点的模型测试一下,把问题全打通,再上服务器。)
之后再安装一个穿透软件,我这里用的是Cpolar,免费且好用,最近打算买个会员也算支持一下。(之前我有提到过要要用http隧道,后来发现tcp也是可以用的,所以这里纠正一下。并且cpolar不好用,推荐用户可以再找找其他frp,现在我在用以前用过的sakura,之前也用过一个openfrp,现在想想也是可以的。)
当然也可以选择通过官方提供的穿透方法穿透,不过考虑到数据的敏感性,所以我选择的方案是第三方工具。
在cpolar注册一个账号,然后在服务器下载安装包并解压安装。
运行之后,会弹出一个网页,输入账号密码登录即可。
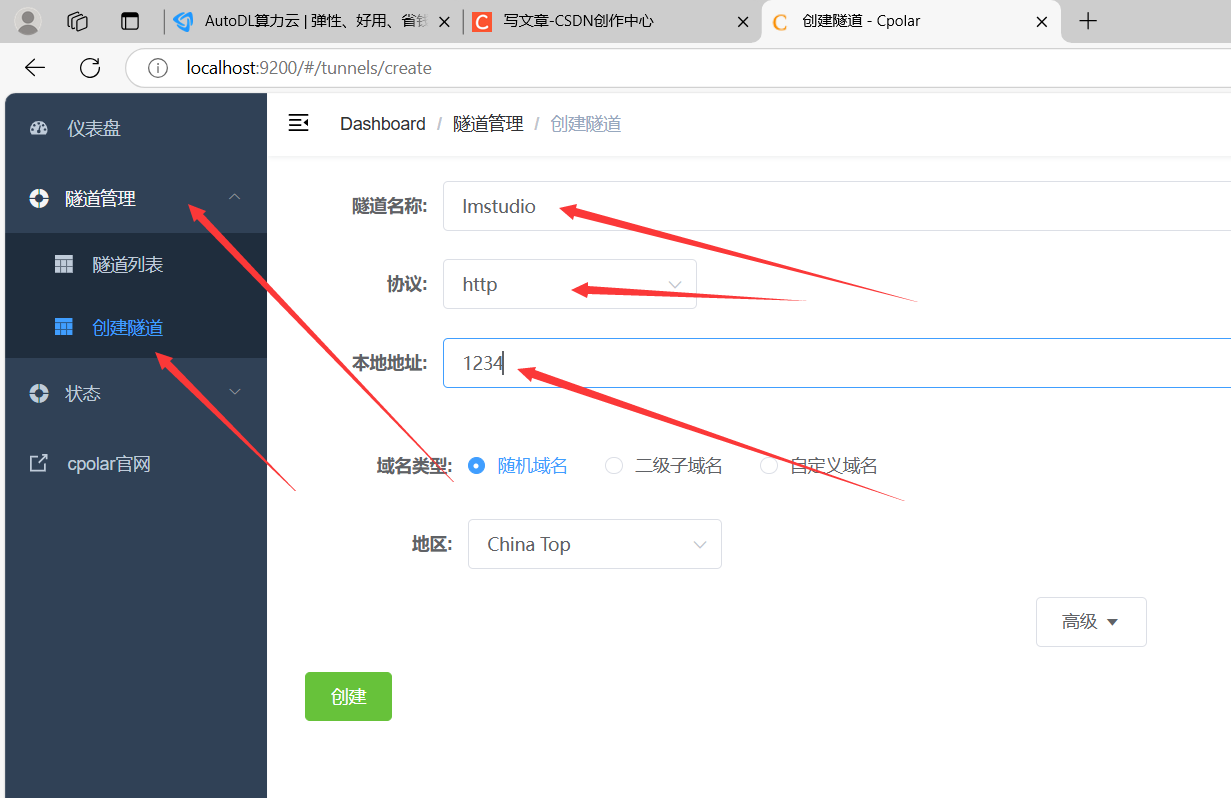
填写好后创建隧道。
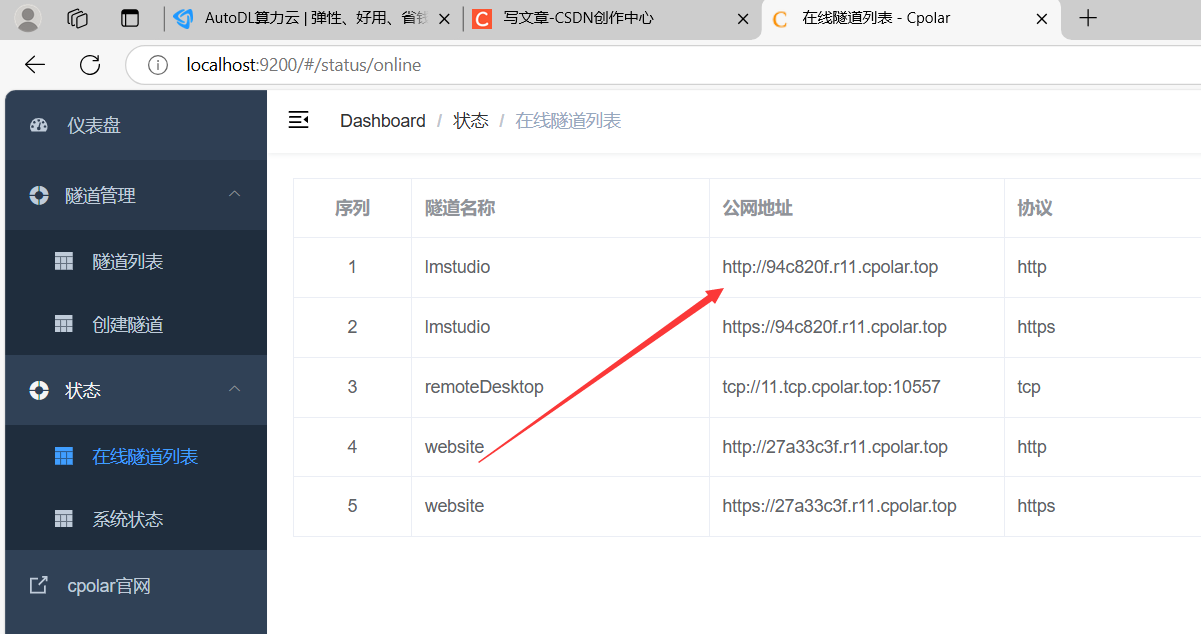
这个就是API了,像本地那样,填写进游戏的API框框中,就能访问测试。
3. 在Linux上搭建模型,并穿透(基于ollama)
我的linux服务器是租的AutoDl。
有以下两个原因,第一是因为我要跑的模型叫做anthracite-org/magnum-v4-123b-gguf,在4q量化下,有73.2g,所以我扩容25g后,1天0.14,一个月4.2。这个价格我能承受。而恒源云一个月则要8.7。
而autodl上有个显卡叫vGPU-32GB,一台1.58,租四台的话,6.32,这比5台4090便宜不少。
不说价格了,我们继续。
如果你是在autodl上买的话,购买之后,首先关机,然后以无卡模式开机,这种方式可以调试代码,下载软件,一个小时只要一毛钱。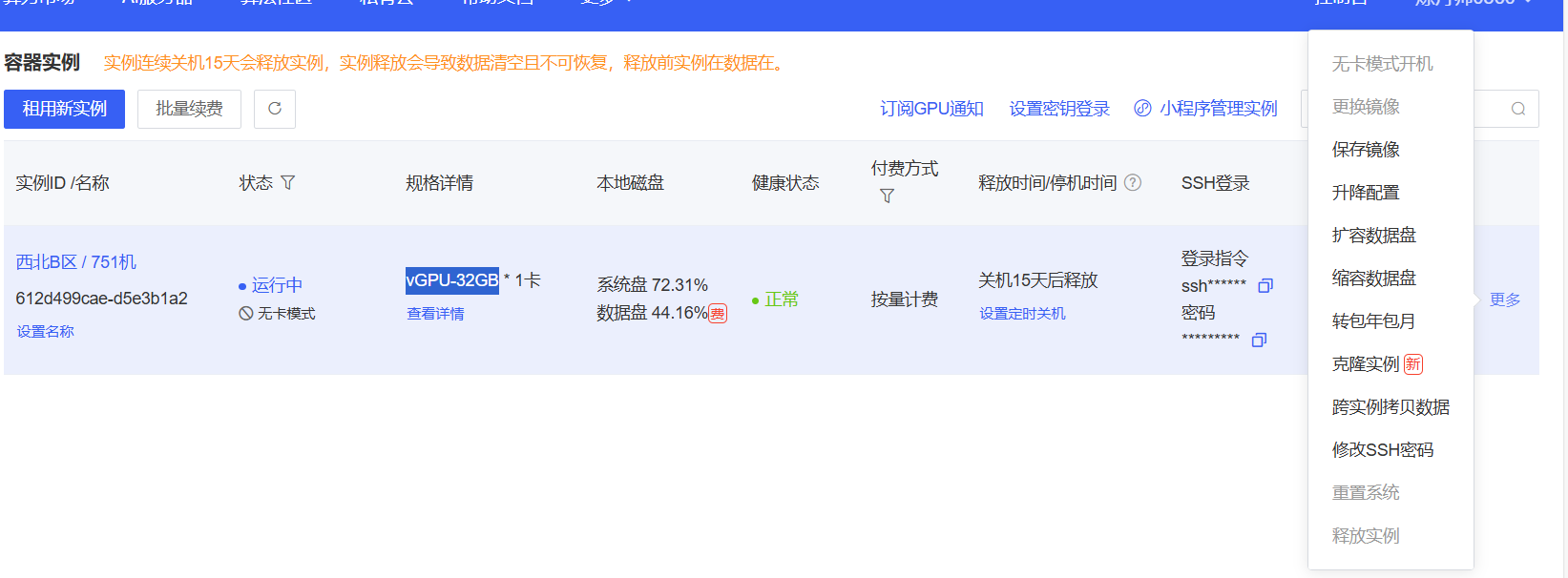
开机之后,用jupyterlab工具进入,进入之后,双击终端进入一个终端。
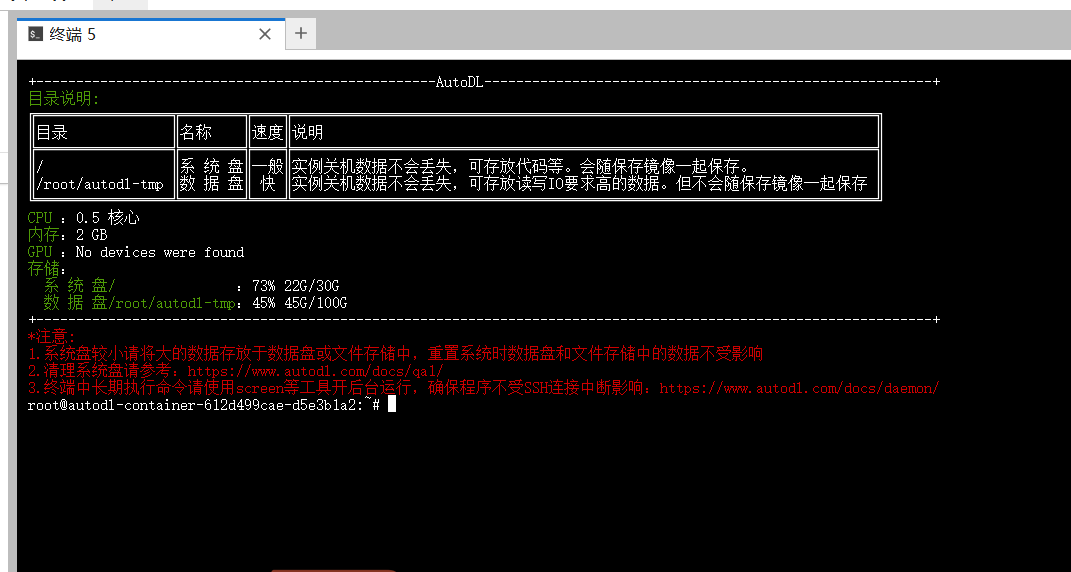
大概这个样子。
云商的服务器,各种容量参数什么的不好直接用df -h,free -m ,top之类的命令查看。
硬盘占用什么的,你点进他的链接,会告诉你怎么查。而htop的话,你直接上实时监控上看就ok。

安装ollama在Linux也很简单,直接访问ollama官网,
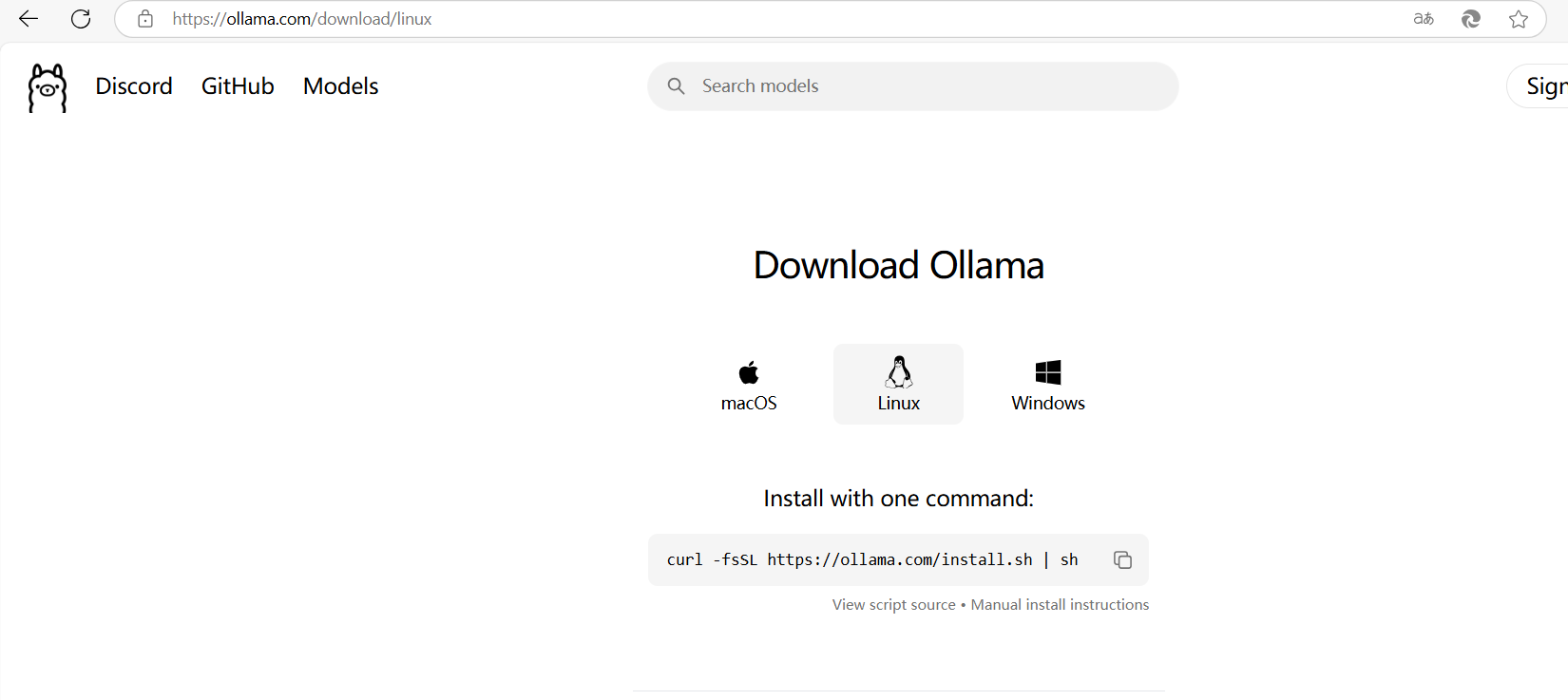
然后复制 curl -fsSL https://ollama.com/install.sh | sh 这一条

复制之后执行,他就会自动安装下载。
如果出现网络错误的话,可能是运气不好。
source /etc/network_turbo # 科学加速
unset http_proxy && unset https_proxy # 取消科学加速
这两条命令大概可以解决问题,当然你也可以重新执行一遍ollama官网的下载,没准第二次就装上了。
装上之后,运行ollama serve,可以看到跑起来了,说明没问题。
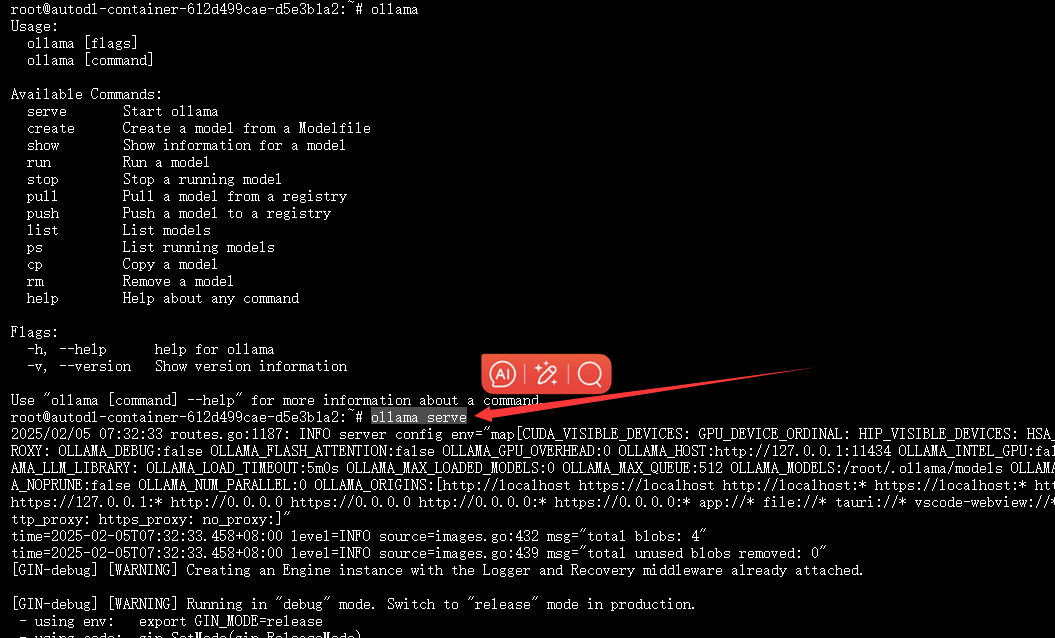
我们先ctrl+c给他终止了。
export OLLAMA_HOST="0.0.0.0:11434"
export OLLAMA_MODELS=/root/autodl-tmp/models
# 可以写进.bashrc里,省的每次执行都要重新输入。写最后面就行了。
执行这两条命令,前者的设定使ollama接受外界访问,后者给模型下载路径改成数据盘。
注意这两条一定要执行的,(ollama serve开之前都要先执行,不然你list都找不到文件),不然你后面穿透的话,会报403错误,我一开始以为是穿透工具不行,后面才发现是因为ollama给拒了。这玩意折磨了我两天,害得我想方设法的在linux装图形界面和vnc来运行lm studio。而垃圾云服务商提供的图形界面安装教程存在bug,根本没法用。
注意,网上写的把这些玩意改拿什么配置文件,屁用没有,你一定要直接改环境才行。改.bashrc都比改那狗屎配置文件靠谱。
另外你执行的命令,只在你当前的终端管用。且个终端就要重新执行这两条命令,毕竟那是另外的bash了。
执行完之后,我们再输入 ollama serve 启动ollama。
注意启动之后,运行信息会占用界面,我们直接点加号再开个终端就行,这个不用管,后面还能在上面看日志信息。或者你给他调到后台执行,不过没必要。
然后直接ollama拉镜像,我推荐玩st就用magnum-v4这个模型,123b q4km的那个要73.2g,72b q4的47g,而q5的54.5g。
但是这些模型主要语料还是英文,如果你们有什么好的中文语料训练的模型,可以推荐给我。
然后执行,
ollama pull hf-mirror.com/anthracite-org/magnum-v4-72b-gguf:Q4_K_M
这个至少要48g显存,例如2块4090。
ollama pull hf-mirror.com/anthracite-org/magnum-v4-123b-gguf:Q4_K_M
# 其实这个跑不了,因为ollama不支持分片gguf拉取。后面我们会讲一下怎么把这些片片合并。
这个至少要90g显存75g硬盘,例如4块4090。
下载之后,直接 ollama run 就行了。
如果运行成功的话,会提示你输入信息,你可以测试几下,然后我们就可以继续下一步了。
现在先输入 /bye 给他关掉。
注意,虽然你和他bye了,但其实AI还在后台运行。运行ollama ps就可以看到,然后你也可以ollama stop终止。但我们这里不用终止。
安装一个穿透软件,这里推荐Cpolar。
你进他的官网注册一下。
Cpolar快速入门教程:Ubuntu系列 - cpolar 极点云官网
然后阅读他的文档下载一下就行,其实就只需要执行一行。
curl -L https://www.cpolar.com/static/downloads/install-release-cpolar.sh | sudo bash
执行完就安装上了。
运行 cpolar 会弹出命令帮助。
登录进穿透软件,会看到这个
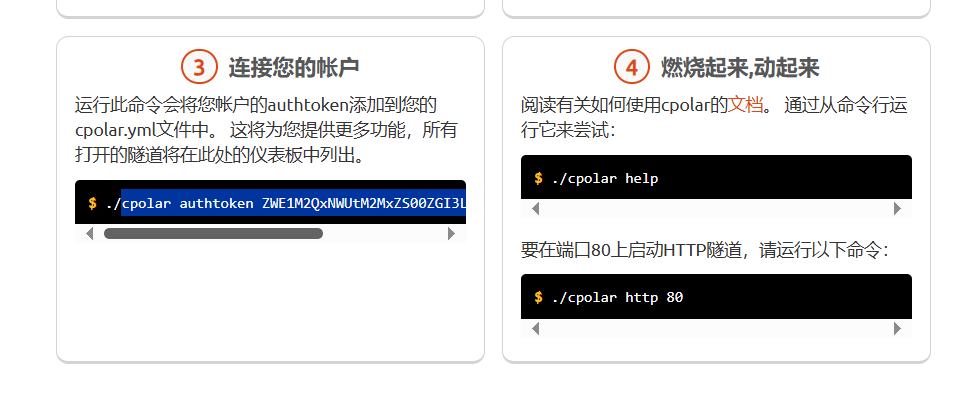
你在终端执行我选中的部分就行了。
然后执行
cpolar http 11434
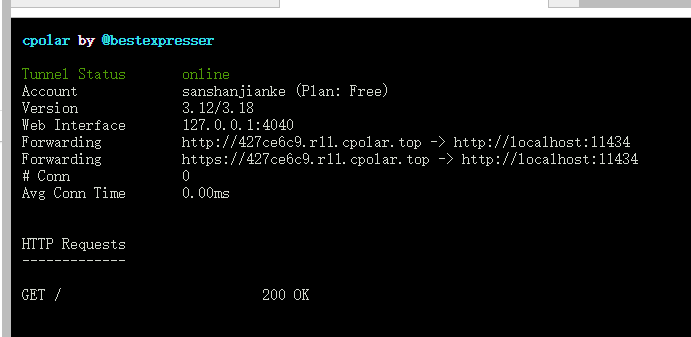
可以看到,他给我们映射了一个地址,我们双击点开就可以看到已经能在远程访问到了。
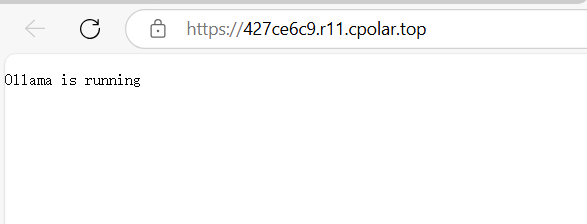
我们多刷新几次页面。
可以看到不论是穿透工具,还是ollama都记录上了我们的访问请求。
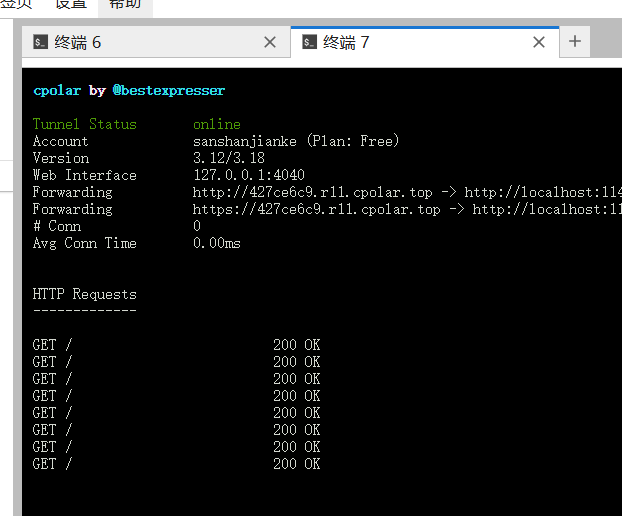
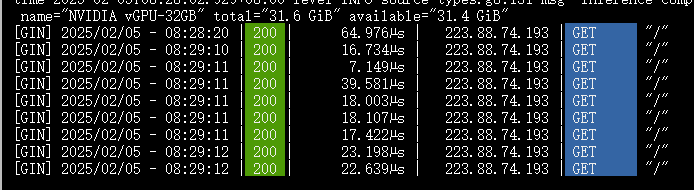
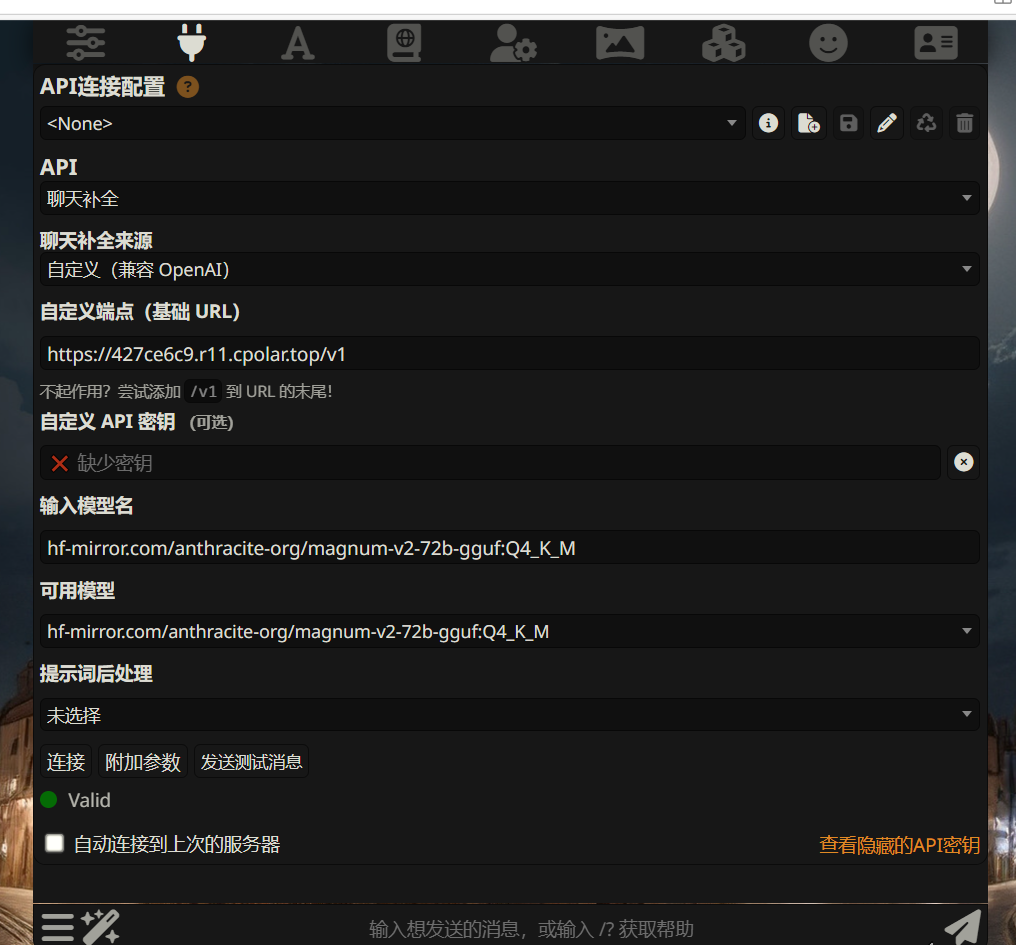
其实此时这个网址,就是我们游戏中需要的api接口。
这时候我们直接拿这个网址,输入到游戏的的接口处就OK了。
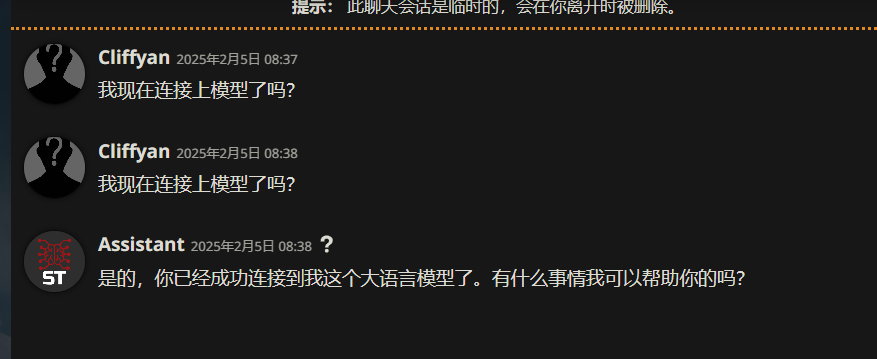
此时发消息,可以收到回复。
4. 有分片的模型合并以及导入本地模型
(如果你是从云商租的服务器,注意,本地导入模型一定要看磁盘空间的容量,保障你的磁盘空间是模型大小的两倍以上,例如模型是72g,你的剩余空间一定要是144g,最好200g,留有一定余量。因为导入模型的时候,它不会自动给那些分片删了。导入完成后,事后你可以缩容。autodl是 只扣一天几毛钱。)
之前忘了说了,这里补上。
现在很多较大的模型,大于50g的模型,很多使用分片的方法,这种方式便于网络不好的环境下,下载使用。(毕竟100g的模型,下到50g突然网络中断,那岂不是亏死)
例如之前我下载的123b模型,在q4下就分成了三个片。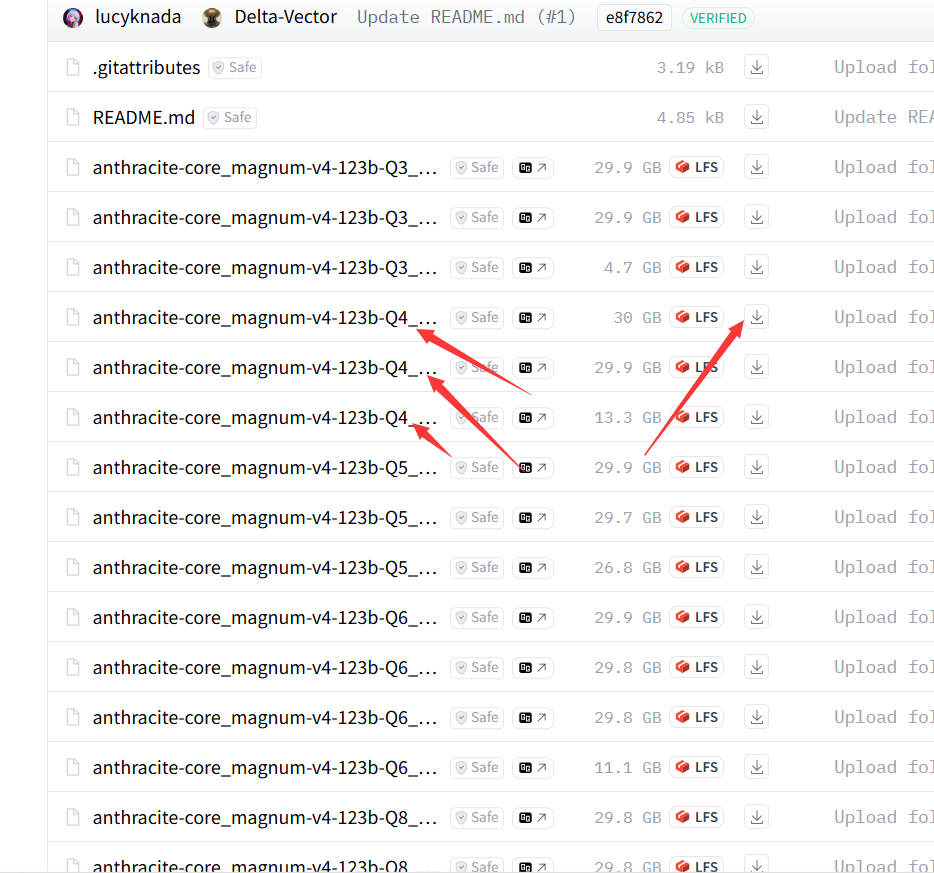
我们用ollama直接拉这样的模型,是不被支持的(至少我写这篇文档的时候是这样的)
拉的时候它会报错,告诉我们,ollama不支持什么的。
这个时候我们只有点到上图的页面手动下载,Windows上你直接下载就行了。Linux上,你可以复制链接,用wget在服务器下载,也可以直接下载,然后用winscp之类的工具上传上去。这些都是常识,就不细讲了。
总之,例如上面的模型,下载完之后,你可以看到
anthracite-core_magnum-v4-123b-Q4_K_M-00001-of-00003.gguf
anthracite-core_magnum-v4-123b-Q4_K_M-00002-of-00003.gguf
anthracite-core_magnum-v4-123b-Q4_K_M-00003-of-00003.gguf
这样的文件,中间有个000x-of-000x的编号。
下面我们进这里,下载llama的压缩包,里面包含一系列工具,可以评测调整模型什么的,这些感兴趣的可以慢慢了解。
GitHub - ggerganov/llama.cpp:C/C++ 中的 LLM 推理
我们把他下载下来并解压,可以看到里面有一系列文件。
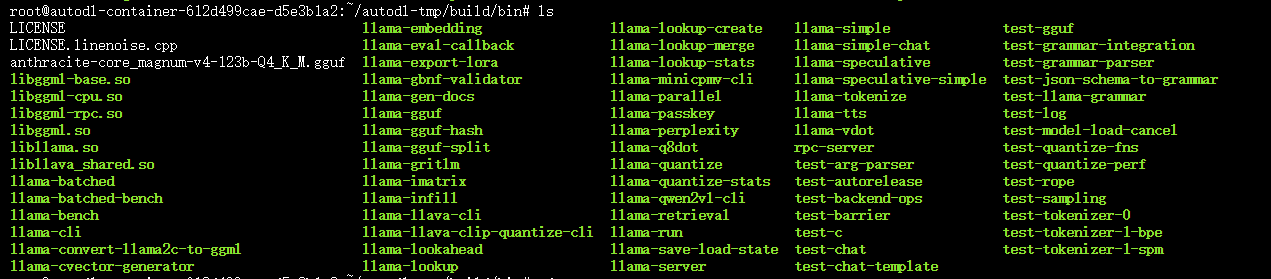
我们把那些带编号的一堆文件丢进这个目录,然后以以下命令参数运行。
(下面这个例子是我的模型,你要下载你喜欢的模型,就按你喜欢的模型名字填,呃,这个应该不用我解释吧。)
./llama-gguf-split --merge anthracite-core_magnum-v4-123b-Q4_K_M-00001-of-00003.gguf anthracite-core_magnum-v4-123b-Q4_K_M.gguf
其中他要求的文件名,你就写第一个文件的文件名就行。第二个文件就是输出出来的文件,为保证可读性,建议只需要把分片的名字去了就行,比如上例那个去了-00001-of-00003。
导出之后,我们可以看到目录中生成了anthracite-core_magnum-v4-123b-Q4_K_M.gguf文件。
但那些分片的文件还在,并占用着大量空间,你自己手动删了就行(上图是我删了之后,只剩下anthracite-core_magnum-v4-123b-Q4_K_M.gguf)
如果是lm studio的话直接按之前讲过的方法导入就行。但ollama好像还没讲如何导入。
这里就说明一下。
首先你随便创建个目录,把模型放进去,然后写个文件,名字叫Modelfile,
然后写下这么一行内容,如果不行的话用绝对路径。
FROM ./模型名字
其实这里还可以写一些参数,来对模型进行配置,但这个有机会了,你们可以慢慢研究(或者等我更新填坑。)这里我们先跑通再说。
然后执行命令
ollama create <模型名称> -f ./Modelfile
其实就是读取之前写的Modelfile,根据你写的内容进行导入。
不出意外,如果模型比较大的话,这需要很长时间。

你可以新开一个终端输入source ~/.bashrc,通过磁盘空间的占用,来判断这模型导入到哪一步了。(如果你租的是autodl的话,其他的云商应该也提供相应的命令,去文档里找找吧。
导入成功后,你输入ollama list即可看见模型,run就行了(如果你是autodl的话,看看爆内存是不是在无卡模式运行)。

四、详细配置与模型微调
目前正在用绅士小说训练模型,等我炼完了丹,如果效果好的话,就跟你们讲讲。
未完待续...(但可能挖坑不填)
多余的话:
今天用的时候ollama的官网炸了。所以如果你们从ollama官网那条下载命令出错的话,只好从github上拉下来了。
我不论是wget还是curl都下下来一堆垃圾,所以就直接下到本地然后上传到服务器。
tar -zxf ollama.tgz
不过我没敢用官网的方式放/usr里,因为感觉autodl对linux有专门设置,怕出问题,就直接解压到root目录了。
另外,autodl的那个vGPU-32GB很垃圾别买,用ollama的话,上两个显卡,利用率只有50%,上四个显卡利用率只有25%。卡信息交换瓶颈了。听说vllm能解决这个问题,不过我没试,等日后试了,再更新一下。我现在用的是A40 48g显存,一小时三块,刚好能跑72b 4q量化。
目前常跑的模型是72B-Qwen2.5-Kunou-v1和L3.3-70B-Euryale-v2.3,另外发现一个14b的中文角色扮演小模型,Tifa-Deepsex-14b-CoT。这个模型的f16量化可以用3090 24g来跑,一小时只要一块钱。
如果安装ollama,穿透转发之后,显示那个监听端口是127.0.0.1而不是下面图中的方括号,而且访问出403错误的话。把ollama删了,然后直接下载文件,解压到本地执行。./bin/ollama serve。就像之前说的那样。这样的话,就使用bash的环境变量了。
![]()
如果有什么问题可以直接[email protected]给我发邮件或者回复,很高兴可以帮助刚入坑的新人答疑解惑。其实我也是刚刚入坑不到一个星期的新人,甚至在这之前都没跑过模型。自从见别人玩这个狂肝了三天三夜,总算跑通了环境。(笑
最后,那些整活向的卡很有趣,规则类怪谈也可以玩一玩。
男女良学校那个卡很有趣!改成TS类型的简直最好玩了,QED,本文完结。(逃