对大模型进行增量微调,样本数据是非常重要的环境,样本数据的来源有几种:
1、网上公开的数据集,比如 hugging face平台的datasets 。https://huggingface.co/datasets
2、在企业中,一般都是需求方(甲方)提供数据集。
一、hugging face的DataSets
1、下载
从hugging face平台的datasets上找相关的数据集,比如中文情感分析二分类数据集 lansinuote/ChnSentiCorp,
写代码下载数据,并且保存。
from datasets import load_dataset
# 从huggingface的datasets库中下载数据集
dataset = load_dataset("lansinuote/ChnSentiCorp",cache_dir="data/",trust_remote_code=True)
dataset_path=r"D:\Test\LLMTrain\day03\data\chn_senti_corp"
# 保存到磁盘
dataset.save_to_disk(dataset_path)
# 将train数据存储到csv
#dataset["train"].to_csv(path_or_buf= r"D:\Test\LLMTrain\day03\data\chn_senti_corp.csv")
print(dataset)保存到D:\Test\LLMTrain\day03\data\chn_senti_corp 目录下。分为3个子目录,test,train,validation。 train为训练的数据,test为测试的数据,validation为验证的数据。
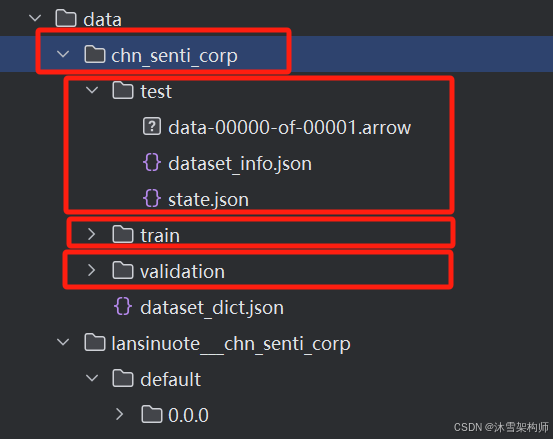
也可以将数据集保存为csv格式文件。
2、读取数据集
from datasets import load_from_disk
# 读取本地的数据集合
dataset_path= r"D:\Test\LLMTrain\day03\data\chn_senti_corp"
dataset=load_from_disk(dataset_path)
print(dataset)返回结果:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 9600
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
})可以看到训练的数据有9600条,测试的数据有1200条,验证的数据有1200条。
我们也可以查看训练的数据集内的详细数据。
from datasets import load_from_disk
# 读取本地的数据集合
dataset_path= r"D:\Test\LLMTrain\day03\data\chn_senti_corp"
dataset=load_from_disk(dataset_path)
#print(dataset)
train_dataset=dataset["train"]
for item in train_dataset:
print(item)结果如下:
 将训练的数据集存储到csv。
将训练的数据集存储到csv。
from datasets import load_from_disk
# 读取本地的数据集合
dataset_path= r"D:\Test\LLMTrain\day03\data\chn_senti_corp"
dataset=load_from_disk(dataset_path)
# 将train数据存储到csv
dataset["train"].to_csv(path_or_buf= r"D:\Test\LLMTrain\day03\data\chn_senti_corp.csv")二、需求方提供的数据集
需求方提供的数据集一般都是csv格式。包含数据和标注。文本分类,每个类别的数据量的最佳比例是1:1:1:1,比如3分类的,每种分类的数据都保持一样多。 样本数据越多越好。数据分为train,test,validation。比如我们那一个微博评论分析的数据,一个8分类的数据集,我们做一个8分类的文本任务。

dataset_info.json是数据集说明。
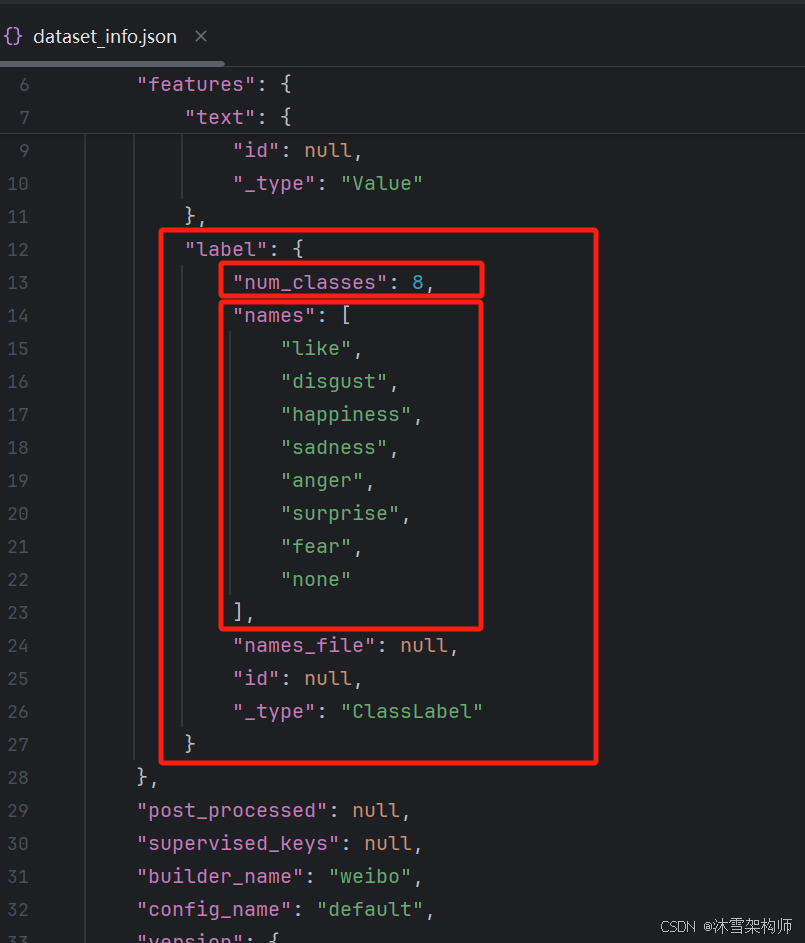
csv中标注的数据label栏就是8分类的标签数值,1=like,2=disgust,3=happiness,4....。
注意:
(1)8分类中若有一类数据样本数据量特别少,则不能参与训练,需要需求方提供更多的数据,或者不让该类数据参与训练。
(2)样本数据要有代表性,重复的数据是没有意义的,label的标注一定要准确,数据质量要高,这样才能训练出正确的模型来。
(3)8分类的数据样本数量要均衡,接近1:1:1... ,若不均衡,则模型训练出来会偏向数据量多的那个结果。
(4)训练集train和test(validation)的数据量比是8:2,test测试集直接当做验证集validation。
1、读取csv文件
from datasets import load_dataset
# 读取 csv数据集
dataset = load_dataset(path="csv",data_files=r"D:\Test\LLMTrain\day03\data\Weibo\train.csv")
print(dataset)
for item in dataset["train"]:
print(item["text"],":",item["label"])