对大模型进行增量微调,则需要选择一个合适的大模型。对中文的文本分类、情感分析等需求,我们一般选择谷歌的 bert-base-chinse大模型,在该模型上进行增量微调。
一、中文自然语言处理模型Bert介绍
Hugging Face平台上的bert-base-chinese模型是由Google开发的BERT(Bidirectional Encoder Representations from Transformers)模型的中文版本,专门针对中文语料库进行了预训练,旨在增强模型对中文文本的理解和处理能力。
模型特点:
- 语言:中文
- 架构:BERT Base(12层Transformer,隐藏层大小为768,注意力头数为12,总参数量约为1.1亿)
- 用途:适用于各种中文自然语言处理任务,如文本分类、情感分析、命名实体识别和问答系统等。
bert-base-chinese模型:https://huggingface.co/google-bert/bert-base-chinese
二、下载到本地
进行微调一般都需要将模型下载到本地。使用代码来下载模型和分词器。
from transformers import BertTokenizer,BertForSequenceClassification
model_name="google-bert/bert-base-chinese"
cache_dir="model/bert-base-chinese"
#下载模型
BertForSequenceClassification.from_pretrained(model_name,cache_dir=cache_dir)
#下载分词工具
BertTokenizer.from_pretrained(model_name,cache_dir=cache_dir)
print(f"模型分词器已下载到:{cache_dir}")我们将模型下载到当前目录的 model/bert-base-chinese目录下,文件结构如下。
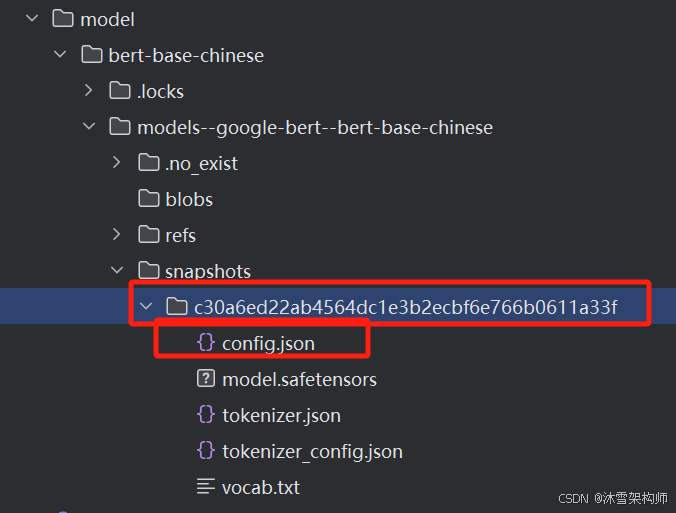
三、使用本地Bert模型
使用transformers的pipeline来使用本地模型,记住模型地址使用绝对路径,路径最终定位到config.json这一层目录。
from transformers import BertTokenizer,BertForSequenceClassification,pipeline
#设置具体包含config.json的目录,只支持绝对路径
model_dir = r"D:\Test\LLMTrain\day03\model\bert-base-chinese\models--google-bert--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
#加载模型和分词器
model = BertForSequenceClassification.from_pretrained(model_dir)
tokenizer = BertTokenizer.from_pretrained(model_dir)
#创建分类pipleine
classifier = pipeline("text-classification",model=model,tokenizer=tokenizer,device="cpu")
#进行文本分类
result = classifier("你好,我是一款语言模型")
print(result)
print(model)device若可以使用cuda,则填写cuda,也可以使用cpu。
四、文本编码
微调过程中,给大模型输入的文本需要先编码,将编码后的值传给大模型,否则大模型无法识别。
扫描二维码关注公众号,回复:
17615609 查看本文章

from transformers import BertTokenizer
mode_path = r"D:\Test\LLMTrain\day03\model\bert-base-chinese\models--google-bert--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f"
#加载字典和分词器
token = BertTokenizer.from_pretrained(mode_path)
print(token)
sents=["百日依山尽,","价格在这个地段属于适中, 附近有早餐店,小饭店, 比较方便,无早也无所"]
# 批量编码句子
out=token.batch_encode_plus(
batch_text_or_text_pairs=[sents[0],sents[1]],
add_special_tokens=True,
#当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=4,
#一律补0到max_length
padding="max_length",
#可取值为tf,pt,np,默认为list
return_tensors=None,
return_attention_mask=True,
return_token_type_ids=True,
return_special_tokens_mask=True,
#返回序列长度
return_length=True
)
#input_ids 就是编码后的词
#token_type_ids第一个句子和特殊符号的位置是0,第二个句子的位置1()只针对于上下文编码
#special_tokens_mask 特殊符号的位置是1,其他位置是0
#length 编码之后的序列长度
for k,v in out.items():
print(k,":",v)
print("解码后的值-------------------")
#解码文本数据
print(token.decode(out["input_ids"][0]),token.decode(out["input_ids"][1]))
返回结果
BertTokenizer(name_or_path='D:\Test\LLMTrain\day03\model\bert-base-chinese\models--google-bert--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f', vocab_size=21128, model_max_length=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True, added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
input_ids : [[101, 4636, 3189, 102], [101, 817, 3419, 102]]
token_type_ids : [[0, 0, 0, 0], [0, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 1], [1, 0, 0, 1]]
length : [4, 4]
attention_mask : [[1, 1, 1, 1], [1, 1, 1, 1]]
解码后的值-------------------
[CLS] 百 日 [SEP] [CLS] 价 格 [SEP]
input_ids 就是编码后的词 token_type_ids第一个句子和特殊符号的位置是0,第二个句子的位置1()只针对于上下文编码 special_tokens_mask 特殊符号的位置是1,其他位置是0 length 编码之后的序列长度。
input_ids里101是特殊字符CLS编码(一句话的开始),4636是“百”在vocab.txt中的序列号(从0开始),其他的文字/符号也是类似的,102是特殊字符SEP编码(一句话的结束)。
max_length是编码后的字符长度,若超过则会被截取。