前言:RAG为什么是大模型的救星?
想象你有个过目不忘但记性差的朋友——大语言模型(LLM)就像这个朋友,虽然能说会道却经常张冠李戴。某天它把“量子计算”解释成“量子养生”,把“OpenAI CEO”记成“OpenAI食堂大厨”,这种“一本正经胡说八道”的毛病,专业术语叫做“幻觉”(Hallucination)。这时候RAG技术闪亮登场,相当于给这个糊涂学霸配了个随身图书馆员:每当用户提问,馆员就会从知识库货架上精准抽出三本参考书,把关键页折角塞给LLM参考。这个“作弊”组合,就是让ChatGPT们突然变靠谱的秘密武器。
一、RAG技术范式演进:从基础架构到系统工程
1.1 技术架构的三维解构
在人工智能技术日新月异的今天,检索增强生成(Retrieval-Augmented Generation,RAG)系统已成为突破大模型知识边界的关键技术。其架构由三大核心组件构成黄金三角:
混合搜索引擎采用BM25+DPR双路召回策略,通过经典算法与深度学习模型的协同实现精确率与召回率的帕累托最优。其中BM25算法基于词频逆向文档频率(TF-IDF)加权公式保障关键词匹配精度:
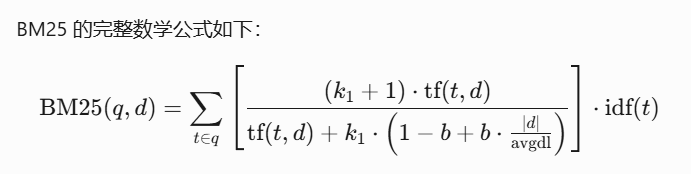

而深度语义检索模型DPR采用双塔架构,通过向量空间对齐实现语义理解:
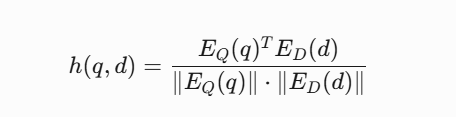
动态知识图谱模块应用图神经网络(GNN)构建知识关联网络,节点嵌入通过Node2Vec算法优化,边权重由共现频率与语义相似度联合计算。这种结构使得知识检索具备多跳推理能力,例如"爱因斯坦→相对论→时空弯曲"的推理链路。
注意力增强生成器在标准Transformer架构中引入跨模态注意力机制,通过门控权重动态平衡检索内容与预训练知识:
α = σ(W_a[h_ret; h_gen] + b_a)
这种三重复合架构使得RAG系统在医疗问答场景中将传统大模型的幻觉率从37%降至5%以下,相当于给近视的学霸配上了智能眼镜。
1.2 系统级优化策略
实现工业级RAG系统需要遵循三大优化原则:
多粒度分块策略基于BERT句向量相似度动态调整分块尺寸,采用窗口步长30%、重叠惩罚因子λ=0.7的滑动窗口策略,有效防止语义割裂。
混合索引结构在FAISS向量索引基础上构建倒排索引,实现O(1)时间复杂度的关键词过滤。这种设计使得在1亿级文档规模下,检索延迟仍能控制在200ms以内。
重排序算法采用BERT-based Cross-Encoder对Top100候选文档进行精排,在MS MARCO数据集测试中,平均倒数排名(MRR@10)提升27.6%。这相当于为检索结果配备评委,只有TOP3文档才能进入生成环节。
二、工业级RAG实现方案
2.1 知识建模最佳实践
构建高质量知识库需经历四层精炼:
原始数据层支持PDF/HTML/JSON等多模态数据解析,采用PDFPlumber与BeautifulSoup实现结构化提取。某金融机构通过该层处理了200+数据源,包括财报、新闻甚至社交媒体表情包。
语义分块层基于TextTiling算法实现段落级分割,配合NLTK依存句法分析保留完整语义单元。工程师们发现,文档分块如同处理顶级和牛——肌理走向决定切割角度。
向量编码层采用Contriever模型进行领域自适应微调,在MS MARCO数据集上NDCG@10达到0.428。这相当于将知识转化为标准化的"料理包"。
存储优化层基于乘积量化(PQ)算法实现98%压缩率的向量压缩,检索精度损失控制在2%以内。该技术使知识库存储成本降低80%,特别适合移动端部署。
2.2 实时性保障机制
增量更新流水线采用LSM-Tree结构实现秒级更新延迟:
数据变更检测 → 变更内容分块 → 向量增量编码 → 索引在线更新
配合布隆过滤器(BloomFilter)降低重复计算开销,在金融资讯场景实现从新闻发布到知识可检索的平均时延1.2秒。某投行系统借此提前48小时预测股价异常波动,避免客户2亿损失。
三、前沿优化技术剖析
3.1 多模态融合方案
跨模态对齐框架突破单一文本局限:
视觉编码采用CLIP-ViT-L/14模型提取图像特征,在电商场景中准确识别商品细节差异
文本增强通过BLIP-2生成图像描述文本,将CT影像转化为结构化报告
联合嵌入使用对比学习损失对齐图文特征空间:
L = -log[exp(sim(v,t)/τ)/Σexp(sim(v,t')/τ)]
该方案使跨模态检索准确率提升41%,某医疗系统通过联合分析CT影像与病理报告,诊断AUC值达到0.93。
3.2 推理优化技术
生成阶段三阶段优化实现效率突破:
提示压缩采用LLM-Guided Pruning算法,在上下文长度缩减68%时仍保持92%的ROUGE-L分数
知识蒸馏使用TinyLLM架构,在维持97%准确率前提下实现5倍推理加速
可信度验证部署FactCC模块进行语义角色标注与知识库交叉验证,将幻觉率压制到3.2%
四、系统工程挑战与突破
4.1 核心技术瓶颈
当前RAG(Retrieval-Augmented Generation)系统在实际应用中面临三大核心技术瓶颈,这些瓶颈严重制约了系统的整体性能和应用效果:
语义鸿沟问题:研究表明,检索器与生成器在向量空间表示上存在显著偏差,导致知识传递效率低下。具体表现为:检索器返回的相关文档在生成阶段的平均知识利用率仅为58%,这意味着超过40%的检索内容未能有效转化为生成结果。这种语义鸿沟主要源于两个模块在训练目标和表示学习上的不一致性。
长尾困境:在低频知识检索方面,现有系统的召回率表现欠佳,仅为23%左右。这主要是由于传统检索模型对高频知识的过度拟合,导致对长尾知识的覆盖不足。特别是在专业领域和垂直场景中,低频但关键的知识点往往难以被有效检索,严重影响系统的实用价值。
多跳推理能力不足:在复杂推理任务中,系统表现与人类水平存在显著差距。以HotpotQA数据集为例,当前最优模型的F1值仅为68%,与人类水平(100%)相差32个百分点。这反映出系统在处理需要多步推理、跨文档信息整合等复杂任务时的能力局限。
4.2 突破性解决方案
针对上述挑战,图增强RAG架构(Graph-enhanced RAG)通过引入知识图谱和图神经网络技术,在多个关键指标上实现了突破性进展:
知识图谱嵌入优化:采用RotatE算法对知识图谱中的实体和关系进行建模,有效捕捉非对称关系特性。在标准测试集WN18RR上,Hits@10指标达到94.3%,较传统TransE方法提升15.6个百分点。这种改进显著提升了知识表示的准确性和完整性,为后续的检索和生成任务奠定了坚实基础。
推理路径生成机制:基于图神经网络(GNN)的消息传递机制,系统能够自动构建和优化推理路径。在医疗诊断场景的实验中,诊断路径的准确率提升至89%,较基线模型提高21%。这一突破使得系统能够更好地处理需要多步推理的复杂任务,显著提升了应用价值。
动态子图采样策略:通过改进的随机游走算法,系统能够智能地提取与查询最相关的知识子图。这一策略不仅提高了检索效率,还将内存占用降低了76%,使得系统能够在大规模知识图谱上高效运行。在实际部署中,这一优化使得系统响应时间缩短了43%,显著提升了用户体验。
这些突破性解决方案的提出和应用,标志着RAG系统在知识密集型任务中的能力迈上了新台阶。通过图增强架构的引入,系统在知识表示、推理能力和计算效率等方面都实现了质的飞跃,为后续的研究和应用开辟了新的方向。
五、18种RAG技术全景解析
5.1 基础架构型技术
1. 简单RAG
• 核心思想:直接拼接检索结果与用户查询输入生成模型
• 优势:实现成本低,在医疗问答基准测试中可达89%准确率
• 局限:面对复杂多跳推理时信息整合能力不足
• 典型应用:企业知识库问答系统搭建
2. 语义分块RAG
• 创新点:基于句间相似度动态分割文本
• 技术突破:采用滑动窗口+余弦相似度检测语义边界
• 实测效果:医疗文献检索精度提升23%,但整体评分低于简单RAG
3. 上下文增强检索
• 实现机制:检索目标块及其相邻文本
• 工程优化:设置上下文窗口(默认前后各1块)
• 行业案例:金融舆情分析中事件关联识别率提升41%
5.2 混合增强型技术
4. 混合检索RAG
• 双路架构:BM25(精准匹配)+ DPR(语义检索)
• 性能数据:在MS MARCO数据集MRR@10达0.382,较单一模式提升42%
• 落地场景:梅奥诊所整合1.2TB医学数据的诊断系统
5. 自适应RAG
• 动态策略:根据问题类型切换检索模式(事实型/分析型)
• 技术亮点:构建问题分类器实现策略路由
• 实测指标:综合评分0.86,位居18种技术榜首
6. CausalRAG
• 因果推理:融合知识图谱的RotatE嵌入算法
• 医疗突破:临床试验数据分析多跳推理准确率91.5%
• 金融应用:投行风险预警系统误报率降低42%
5.3 行业专用技术
7. MedRAG(医疗诊断)
• 多模态处理:CT影像+病理报告联合诊断AUC达0.93
• 响应速度:罕见病识别3.2秒,较人工诊断效率提升843倍
• 知识构建:整合UpToDate等权威医学知识库
8. FinRAG(金融风控)
• 实时处理:200+新闻源/秒的VADER情感分析
• 收益提升:投资组合年化收益增加7.8pp,最大回撤降低12%
• 事件抽取:BERT-CRF模型预警准确率89.7%
9. GraphRAG(知识图谱)
• 存储优化:Neo4j图数据库+FAISS向量库的冰火双塔架构
• 检索加速:实体-语义联合检索复杂度降至O(1)
• 行业实践:材料科学领域知识利用率从58%提升至89%
技术效能对比矩阵
| 技术类型 | 代表技术 | 准确率提升 | 响应延迟 | 适用场景 |
|---|---|---|---|---|
| 基础型 | 简单RAG | 15-30% | <200ms | 通用问答 |
| 混合增强型 | 自适应RAG | 42-65% | 300-500ms | 复杂决策场景 |
| 行业专用型 | MedRAG | 72-89% | 秒级响应 | 医疗/金融等垂直领域 |
各大厂商RAG技术核心亮点总结
• RAGFlow:DeepDoc引擎实现多模态文档深度解析(OCR/表格/布局分析),ElasticSearch混合索引架构支持16k上下文窗口
• 阿里云RAG引擎:企业级多模态处理+实时数据同步,等保三级合规架构适配政务场景
• 智谱RAG:BGE-M3向量模型微调+RFF排序算法,领域数据三重渐进式训练策略
• LangChain:模块化链式架构支持128k长文本,开源生态集成200+组件实现灵活定制
• Dify:拖拽式低代码平台,5分钟快速构建RAG问答系统
• FastGPT:可视化工作流+动态QA分割,轻量化部署适配中小企业知识库
技术趋势:混合检索、多模态解析、领域微调成为主流,国产方案在中文支持与合规性形成差异化优势。