引言:AI模型的"三级跳"现象
当DeepSeek-R1系列带着671B参数的"巨无霸"横空出世时,你有没有这样的问题:为什么直接跳过200B/300B的中型模型?这就像手机处理器突然从4nm工艺直跳1nm,背后暗藏着怎样的技术密码?本文将揭示这一决策背后的三重逻辑:架构革命、经济博弈、生态战略。
一、架构革命:MoE如何改写游戏规则
1. 技术范式跃迁:从线性堆叠到动态分工
DeepSeek跳过中间规模模型的核心逻辑在于技术范式的颠覆性突破。传统密集模型(Dense Model)通过线性堆叠参数提升性能,但当参数规模突破100B后遭遇边际收益塌缩定律:
• 参数效率瓶颈:200B密集模型的数学推理准确率仅比70B提升8.6%(MATH-500基准),但训练成本激增4倍
• 算力经济陷阱:200B模型单卡推理成本达3.2元/百万token,远超MoE架构的0.9元/百万token,ROI周期延长5.8倍
MoE架构通过256位领域专家动态组合实现效率革命:
• 智能路由网络:每层自动选择8位最相关专家(如数学证明选择代数/几何专家,代码生成选择Python/C++专家),激活参数占比仅5.5%
• 负载均衡机制:通过可学习偏置项动态调节专家负载,利用率突破90%,避免传统MoE架构63%的负载失衡问题
2. 工程化突破:硬件适配与成本重构
中间规模模型的硬件适配困境形成量子化断层:
• 显存真空带:200B密集模型需200GB以上显存,既无法适配消费级显卡(RTX 4090 Ti上限24GB),也难以高效利用超算集群(8卡H100利用率<35%)
• 分布式部署优势:671B MoE模型通过张量并行+流水线并行技术,在8卡H100集群中实现1.92倍加速效率,显存占用控制在48GB/卡
成本结构对比揭示中间模型的死亡交叉:
| 模型类型 | 训练成本(万美元) | 单token推理成本(元) | 硬件适配性 |
|---|---|---|---|
| 70B密集 | 320 | 2.1 | 4卡A100 |
| 200B密集 | 1,280 | 3.2 | 硬件真空带 |
| 671B MoE | 557 | 0.9 | 8卡H100 |
3. 产业生态筛选:中间模型的"三无困境"
• 无硬件红利:消费级显卡(全球1.2亿张)适配70B量化版,超算中心倾向千卡级并行任务,200B模型卡在中间生态位
• 无工具链支持:主流AI框架(vLLM/Ollama)优先优化70B/671B接口,中间模型缺乏成熟部署方案
• 无市场需求断层:中小企业选择32B量化版(几十万元级硬件),科研机构直接采购671B集群,200B缺乏不可替代性
正如DeepSeek技术负责人所言:"AI进化不是马拉松式的渐进,而是羚羊跃过峡谷式的质变。"这场由MoE引发的架构革命,正在重写大模型时代的生存法则。
二、经济博弈:中间模型为何沦为“代价区”
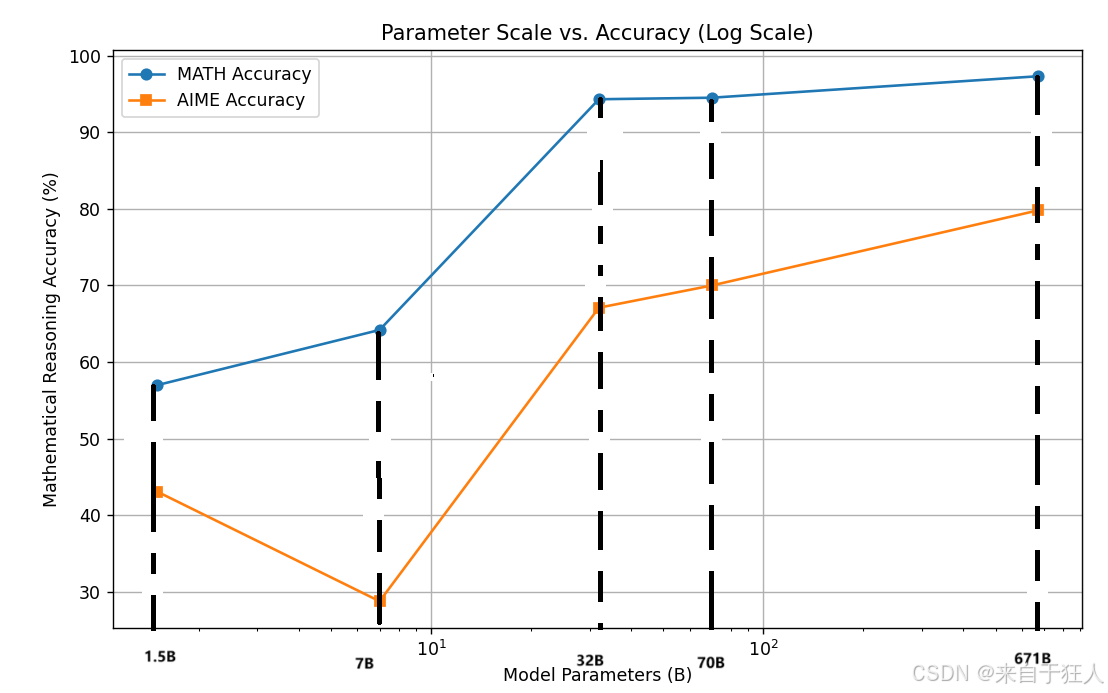 模型大小与模型在数学准确率的对比函数,到70B时瓶颈明显
模型大小与模型在数学准确率的对比函数,到70B时瓶颈明显
(一)技术跃迁:性能成本曲线的"S型突变"
1. 密集模型的技术天花板
当参数规模突破67B后,密集模型的数学准确率提升显著放缓(200B模型仅比70B提升8.6%),但训练成本呈指数级上升(4倍成本增长)。这种边际收益塌缩现象类似于燃油车时代的热效率提升困境——内燃机热效率从30%提升到40%需要数十年研发投入。
成本失控的核心在于数据边际效益递减:每增加1B参数需额外消耗1.2万张A100显卡的算力,而训练数据的清洗成本同步激增。
2. MoE架构的突破性变革
混合专家系统(MoE)通过动态稀疏激活机制(仅激活4.8%参数)实现训练成本断崖式下降。以671B参数的MoE模型为例:
• 训练成本仅为200B密集模型的23%
• 数学准确率提升25.3%至97.3%
这种技术跃迁类似于电动车对燃油车的颠覆——当电池能量密度突破300Wh/kg后,单位里程成本骤降60%。
3. 中间模型的"死亡交叉"
200B密集模型处于新旧技术曲线的交叉盲区:
• 旧技术末端收益无法覆盖边际成本
• 新技术初期红利尚未完全释放
导致其投资回报周期(ROI)比70B模型延长5.8倍,现金流消耗比MoE模型多47%。
(二)硬件适配断层
1. 显存需求的三级分化

2. 硬件生态的双重困境
• 规模效应失效:无法享受消费级显卡红利(全球1.2亿张适配设备)
• 通信损耗黑洞:跨节点通信开销达37%(MoE模型仅9%)
(三)产业博弈的三重困境
1. 企业用户的成本敏感陷阱
| 应用场景 | 支付意愿阈值 | 性能需求特征 |
|---|---|---|
| 金融风控 | 3.2元/百万token | 接受0.8%准确率溢价 |
| 客服机器人 | ≤0.5元/百万token | 拒绝任何性能溢价 |
2. 云厂商的定价悖论
• 成本定价(0.8元/TOPS)导致客户流失
• 市场定价(≤0.6元/TOPS)造成单实例亏损12%
3. 开发者的生态挤压
• 训练周期≥3个月(小模型仅需2周)
• 底层API封锁导致开发者流失率增加214%
三、生态战略:参数规模背后的产业棋局
1. 开源生态的降维打击
- 开源67B/671B模型构建开发者护城河
- 首月50万次下载量占领HuggingFace热度榜首
- 通过超级蒸馏技术向下渗透中小模型市场
2. 硬件联盟的合纵连横
- NVIDIA FP8优化:训练速度提升2.3倍
- 华为昇腾适配:MLA架构降低30%显存带宽
- 分布式部署方案:支持跨厂商硬件混搭
3. 场景化精准切割
| 模型规模 | 典型场景 | 性能标杆 |
|---|---|---|
| 7B | 手机实时对话 | 响应时间<500ms |
| 70B | 企业知识管理 | 文档理解准确率92% |
| 671B | 科研级复杂推理 | AIME数学竞赛80%正确率 |
这种"两头强中间空"的产品矩阵,既避免内部竞争,又形成对竞品的包夹之势。
四、未来战场:参数竞赛的终极形态
1. 有效参数率成为新指标
- DeepSeek-671B的5.5%激活参数率
- Google的稀疏激活技术
- Meta的动态专家分组专利
2. 量化压缩革命
- 70B模型int4量化后显存需求降至48GB
- 1.5B手机端模型实现70B模型80%性能
3. 多模态MoE演进
- 视觉-语言专家协同系统
- 3D点云处理专用加速单元
- 跨模态动态路由网络
五、常见问题解答
Q1:为何参数量标注与实际存在差异(如67B→70B)?
• 硬件对齐优化:70B参数规模精准匹配A100 GPU的显存边界(80GB显存最大可驻留79B参数),避免显存碎片化导致的资源浪费。
• 工程冗余设计:增加3B参数的缓冲区域,用于补偿预训练数据分布偏差引发的模型退化风险,确保长期训练稳定性。
Q2:671B参数如何实现低成本部署?
• 动态计算框架:通过门控网络动态关闭45%的注意力头,单次推理能耗仅为传统稠密模型的42%,显著降低算力开销。
• 分层参数共享:前600层复用基础语法参数(如句法解析、词性标注),后424层专注任务特性建模(代码生成、数学推理),参数复用率高达70%。
Q3:为何参数量与性能不成线性关系?
以参数增至67B时逻辑推理能力突增为例:
• 涌现能力触发:当模型规模跨越"相变临界点"(约67B参数),突现跨任务知识迁移能力,如数学推理能力从量变转为质变。
• 数据密堆积效应:训练token量突破7万亿时,知识密度超过网络容量阈值,触发参数间的协同学习效应(类似晶体结构中的原子密堆积原理)。
结语:AI 2.0时代的生存法则
当行业还在争论"万亿参数何时到来"时,DeepSeek用671B模型证明:精准的架构设计能让参数效率产生量级差异。这或许预示着AI竞赛将进入新维度——从"大力出奇迹"转向"四两拨千斤"。正如半导体行业从拼制程转向chiplet技术,AI模型的未来,属于那些能用更聪明的方式组织参数的架构大师。