小博最近学习了一下人脸识别,用opencv,ssd都跑了一遍,感觉都不是很理想。那个ssd配环境配的头疼,以至于小博果断放弃,更换新赛道。发现用这个Arcface做人脸识别还是蛮不错的,没有很多环境的问题。
一、性能对比(关键指标)
|
二、环境配置
1.安装依赖库
首先,确保你已经安装了 Python 和相关的深度学习框架(如 PyTorch 或 TensorFlow)。这里我们以 PyTorch 为例。并且已经创建好了相关的虚拟环境,在pycharm中配置好并激活了。这里小博用的是conda环境。打开配置好的虚拟环境终端:
# 安装必要的库
pip install torch torchvision numpy opencv-python insightface scikit-learn上面安装的insightface如果你使用的是 GPU 环境,建议安装支持 GPU 的版本:
pip install insightface-gpu注意:运行不畅可能是子模块缺失,可以尝试重新安装 insightface:
pip uninstall insightface
pip install insightface或者直接从 GitHub 克隆源码安装:
git clone https://github.com/deepinsight/insightface.git
cd insightface
pip install -e .
三、代码实现
1.代码
import cv2
import numpy as np
from insightface.app import FaceAnalysis
import os
import pickle
import warnings
from sklearn.neighbors import NearestNeighbors
import time
# 忽略 NumPy 的 FutureWarning
warnings.filterwarnings("ignore", category=FutureWarning)
# 初始化 FaceAnalysis 应用
def initialize_face_analysis():
try:
import onnxruntime
providers = onnxruntime.get_available_providers()
if 'CUDAExecutionProvider' in providers:
print("GPU 可用,使用 GPU 加速。")
ctx_id = 0 # 使用 GPU
else:
print("GPU 不可用,回退到 CPU。")
ctx_id = -1 # 使用 CPU
except ImportError:
print("onnxruntime-gpu 未安装,回退到 CPU。")
ctx_id = -1
app = FaceAnalysis(name='buffalo_l')
app.prepare(ctx_id=ctx_id, det_size=(640, 640))
return app
# 计算余弦相似度
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 加载或创建人脸数据库
def load_or_create_database(database_path):
os.makedirs(os.path.dirname(database_path), exist_ok=True) # 确保目录存在
if os.path.exists(database_path):
with open(database_path, "rb") as f:
database = pickle.load(f)
else:
database = {}
return database
# 保存人脸数据库
def save_database(database, database_path):
with open(database_path, "wb") as f:
pickle.dump(database, f)
# 添加新人脸数据
def add_face_to_database(app, database, name, image_path=None, camera_capture=False):
if camera_capture:
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("无法打开摄像头,请检查设备。")
return
print("按 's' 键保存人脸,按 'q' 键退出。")
while True:
ret, frame = cap.read()
if not ret:
print("无法捕获图像,请检查摄像头。")
break
cv2.imshow("Capture Face", frame)
key = cv2.waitKey(1) & 0xFF # 缩短等待时间为 1 毫秒
if key == ord('s'):
faces = app.get(frame)
if len(faces) == 0:
print("未检测到人脸,请调整摄像头角度或光线条件。")
continue
elif len(faces) > 1:
print("检测到多张人脸,请确保画面中只有一张人脸。")
continue
embedding = faces[0].embedding
database[name] = embedding
print(f"人脸 '{name}' 已保存。")
break
elif key == ord('q'):
print("未保存人脸。")
break
cap.release()
cv2.destroyAllWindows()
else:
image_path = image_path.strip().strip('"') # 去除多余空格和引号
print(f"尝试加载图片路径: {image_path}") # 调试信息
if not os.path.exists(image_path):
print(f"图像文件不存在: {image_path}")
return
img = cv2.imread(image_path)
if img is None:
print(f"无法读取图像文件,请检查路径和文件格式: {image_path}")
return
faces = app.get(img)
if len(faces) == 0:
print("未检测到人脸,请检查图像质量。")
elif len(faces) > 1:
print("检测到多张人脸,请确保图像中只有一张人脸。")
else:
embedding = faces[0].embedding
database[name] = embedding
print(f"人脸 '{name}' 已保存。")
# 构建最近邻模型
def build_nn_model(database):
embeddings = np.array(list(database.values()))
names = list(database.keys())
nn_model = NearestNeighbors(n_neighbors=1, metric="cosine")
nn_model.fit(embeddings)
return nn_model, names
# 查找最相似的人脸
def find_best_match(nn_model, names, embedding, threshold=0.6):
distances, indices = nn_model.kneighbors([embedding])
if distances[0][0] < threshold:
return names[indices[0][0]], 1 - distances[0][0]
return None, 0
# 实时人脸识别
def realtime_face_recognition(app, database, threshold=0.6):
nn_model, names = build_nn_model(database)
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("无法打开摄像头,请检查设备。")
return
print("实时人脸识别已启动,按 'q' 键退出。")
while True:
ret, frame = cap.read()
if not ret:
print("无法捕获图像,请检查摄像头。")
break
faces = app.get(frame)
for face in faces:
bbox = face.bbox.astype(int)
embedding = face.embedding
best_match, best_similarity = find_best_match(nn_model, names, embedding, threshold)
label = f"{best_match} ({best_similarity:.2f})" if best_match else "Unknown"
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
cv2.putText(frame, label, (bbox[0], bbox[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow("Real-time Face Recognition", frame)
key = cv2.waitKey(1) & 0xFF # 缩短等待时间为 1 毫秒
if key == ord('q'):
print("退出实时人脸识别模式。")
break
cap.release()
cv2.destroyAllWindows()
# 主函数
def main():
app = initialize_face_analysis()
database_path = "D:/Arcface/dd/face_database.pkl"
database = load_or_create_database(database_path)
train_mode = input("是否进入训练模式?(y/n): ").lower()
if train_mode == 'y':
name = input("请输入人名: ")
source = input("通过图片 (i) 还是摄像头 (c) 添加人脸?(i/c): ").lower()
if source == 'i':
image_path = input("请输入图片路径: ")
add_face_to_database(app, database, name, image_path=image_path)
elif source == 'c':
add_face_to_database(app, database, name, camera_capture=True)
else:
print("无效的选择。")
save_database(database, database_path)
realtime_face_recognition(app, database)
if __name__ == "__main__":
main()2.运行效果
小博运行了两个人,每个人训练了两张图片,效果如下:
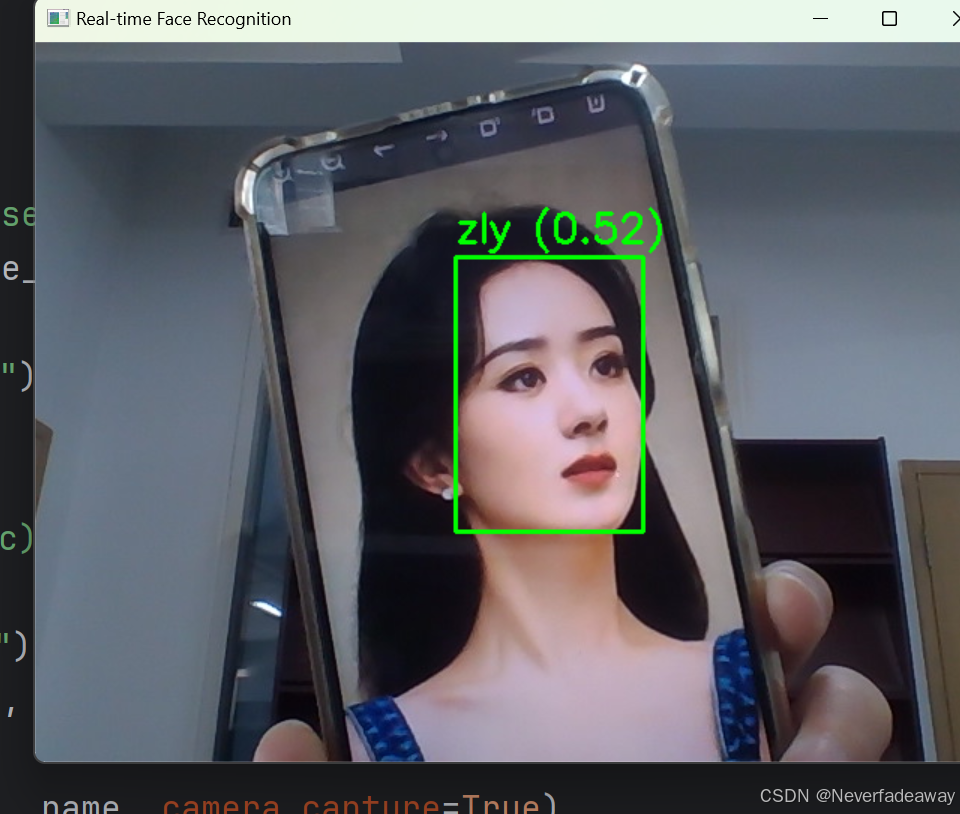
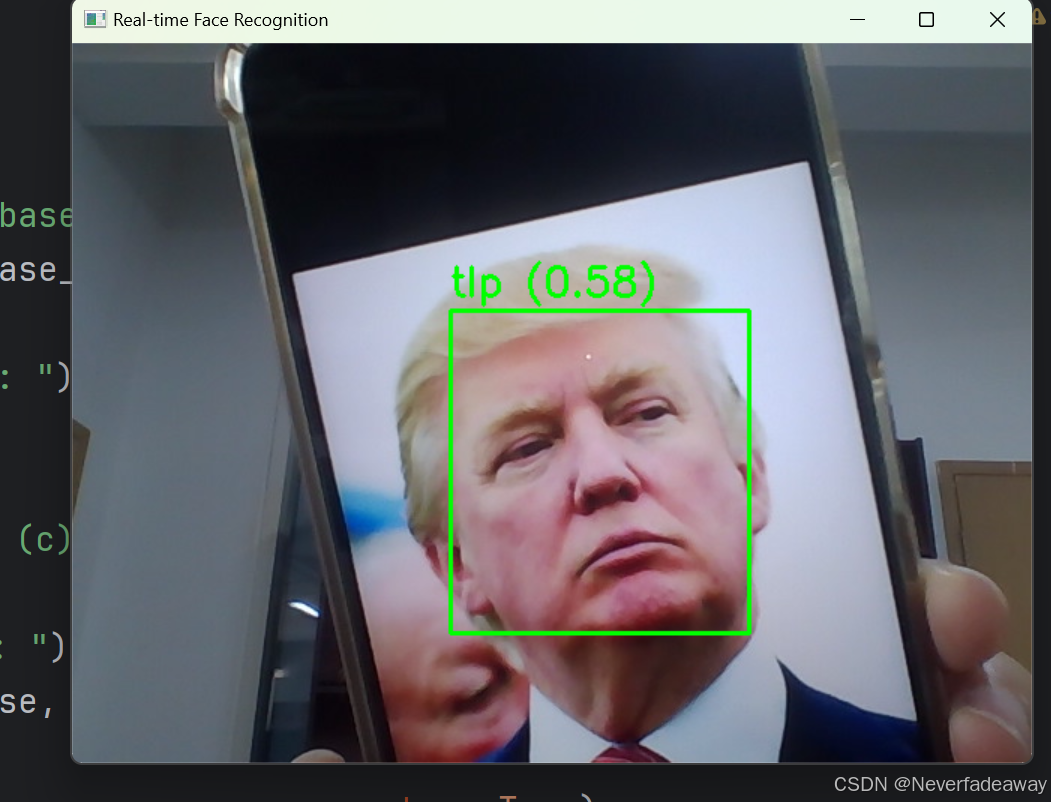
3.关于database_path的说明
database_path 是存储人脸数据库的文件路径。它是一个 .pkl 文件,用于保存所有已录入的人脸特征向量及其对应的人名。每次运行程序时,程序会从该文件加载现有的数据库(如果文件存在),并在训练模式下将新录入的人脸数据添加到数据库中。
4.database_path的作用
database_path 是一个文件路径,指向存储人脸数据库的 .pkl 文件。这个文件的内容是一个 Python 字典,结构如下:
{
"bill": [embedding_vector_for_bill], #人脸特征向量(512维)
"alice": [embedding_vector_for_alice],
"bob": [embedding_vector_for_bob]
}- 键(Key) :人名(如
"bill"、"alice")。 - 值(Value) :对应的人脸特征向量(一个长度固定的 NumPy 数组)。
每次录入新人脸时,程序会将新人脸的特征向量添加到字典中,并覆盖原有的 .pkl 文件。
5.示例:录入多个人脸
(1)保持database_pathb
假设你已经录入了第一个人(bill),现在想录入第二个人(alice),要保持 database_path 不变,在代码中,database_path 被定义为:
database_path = "D:/Arcface/dd/face_database.pkl"
改成你自己的路径:默认与你的 Python 脚本在同一目录下。
如果你想将数据保存到其他目录(例如 data/ 文件夹),可以修改 database_path 变量:
# 修改主函数中的路径
def main():
database_path = "data/face_database.pkl" # 新路径
database = load_or_create_database(database_path)
...
确保目标目录存在(如data/),否则会报错。
(2)加载现有数据库
程序启动时,会调用 load_or_create_database 函数加载现有的数据库文件:
def load_or_create_database(database_path):
os.makedirs(os.path.dirname(database_path), exist_ok=True) # 确保目录存在
if os.path.exists(database_path):
with open(database_path, "rb") as f:
database = pickle.load(f)
else:
database = {}
return database 如果 face_database.pkl 文件存在,程序会加载其中的内容。
如果文件不存在,程序会创建一个空字典。
(3)添加新人脸
当你录入第二个人(alice)时,程序会将 alice 的人脸特征向量添加到字典中:
database["alice"] = embedding
(4)保存更新后的数据库
程序会在退出训练模式时调用 save_database 函数,将更新后的字典保存回 face_database.pkl 文件:
def save_database(database, database_path):
with open(database_path, "wb") as f:
pickle.dump(database, f)(5)如何验证数据库内容
如果你想查看数据库文件的内容,可以使用以下代码:
import pickle
# 加载数据库文件
database_path = "D:/Arcface/dd/face_database.pkl"
with open(database_path, "rb") as f:
database = pickle.load(f)
# 打印数据库内容
print("当前数据库内容:")
for name, embedding in database.items():
print(f"人名: {name}, 特征向量长度: {len(embedding)}")输出示例:
当前数据库内容:
人名: bill, 特征向量长度: 512
人名: alice, 特征向量长度: 512
人名: bob, 特征向量长度: 512四、注意事项
运行实例:
是否进入训练模式?(y/n): y
请输入人名: zly
通过图片 (i) 还是摄像头 (c) 添加人脸?(i/c): i
请输入图片路径: D:/face photo/zly/OIP-C (3).jpg
人脸 'zly' 已保存。
实时人脸识别已启动,按 'q' 键退出。1.路径输入
如果选择 'i' ,要注意输如路径,不要额外添加双引号。列如,直接输入:
D:/face photo/zly/OIP-C (3).jpg或者使用原始字符串(在路径前加 r)以避免转义字符问题:
r"D:\face photo\zly\OIP-C (3).jpg"2.图片注意
(1)质量要求
清晰度
- 高分辨率 :图片应具有较高的分辨率(建议至少 640x480 或更高),以确保人脸细节清晰可见。
- 避免模糊 :图片不应有运动模糊或失焦现象。
光照条件
- 均匀光照 :避免过亮或过暗的区域,确保人脸部分光线均匀。
- 避免阴影 :人脸不应被帽子、头发或其他物体遮挡产生阴影。
角度
- 正面视角 :尽量选择正脸图片,避免大角度的侧脸或俯仰角。
- 头部姿态 :头部应保持自然直立,避免过度倾斜或旋转。
(2)图片内容要求
单一主体
- 单人图片 :每张图片中应只包含一个人脸。如果图片中有多张人脸,程序默认仅提取第一张人脸特征,可能导致错误。
- 无干扰物 :避免背景中有其他人脸或其他干扰物。
面部特征完整
- 无遮挡 :人脸不应被口罩、墨镜、帽子等遮挡。
- 五官可见 :眼睛、鼻子、嘴巴等关键部位应清晰可见。
表情
- 自然表情 :尽量选择中性表情的图片,避免夸张的表情(如大笑、皱眉)影响特征提取。
(3)图片格式要求
支持的格式
- 确保图片格式为常见的图像格式,例如
.jpg,.jpeg,.png。 - 不支持的格式(如
.bmp,.gif)需要提前转换。
文件命名
- 文件名可以随意命名,但应避免特殊字符(如
*,?,:等),以免读取时出错。
文件大小
- 图片文件大小不宜过大(建议单张图片不超过 5MB),否则可能影响加载速度。
3.键的输入
输入's'保存或'q'退出键时,确保键盘输入焦点在 OpenCV 窗口(弹出的镜头窗口),不要像小博一样,傻傻的一直在运行的命令行窗口输入哦。
欢迎大家留言评论,小博会及时回复!!