一、句子语义等价识别任务
句子语义等价识别任务,说白了,就是让模型来判断两个句子是不是在说同一个意思。就像我们人类有时候会说两句话来表达同一个想法。本文基于开源的 hfl/chinese-roberta-wwm-ext 模型,微调训练句子语义等价识别任务。
实验所使用的主要依赖版本如下:
torch==1.13.1+cu116
transformers==4.37.0
预训练模型下载地址:
二、实验数据集介绍:
数据集采用 modelscope 上公开的大规模中文语义相似度数据,地址如下:
数据量统计:
| 训练集(train.csv) | 验证集(dev.csv) |
|---|---|
| 86193 | 9999 |
数据集格式如下所示:
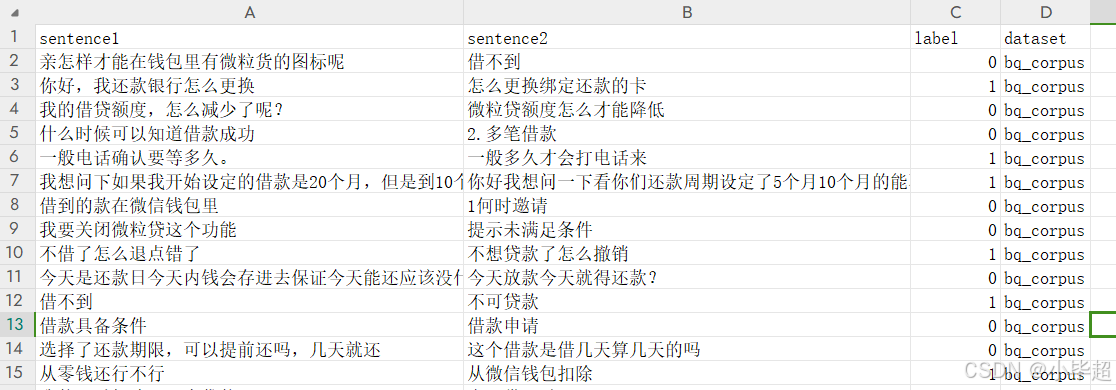
其中 label: 0: 语义不相干,1: 语义等价, train.csv 数据集的标签分布为:
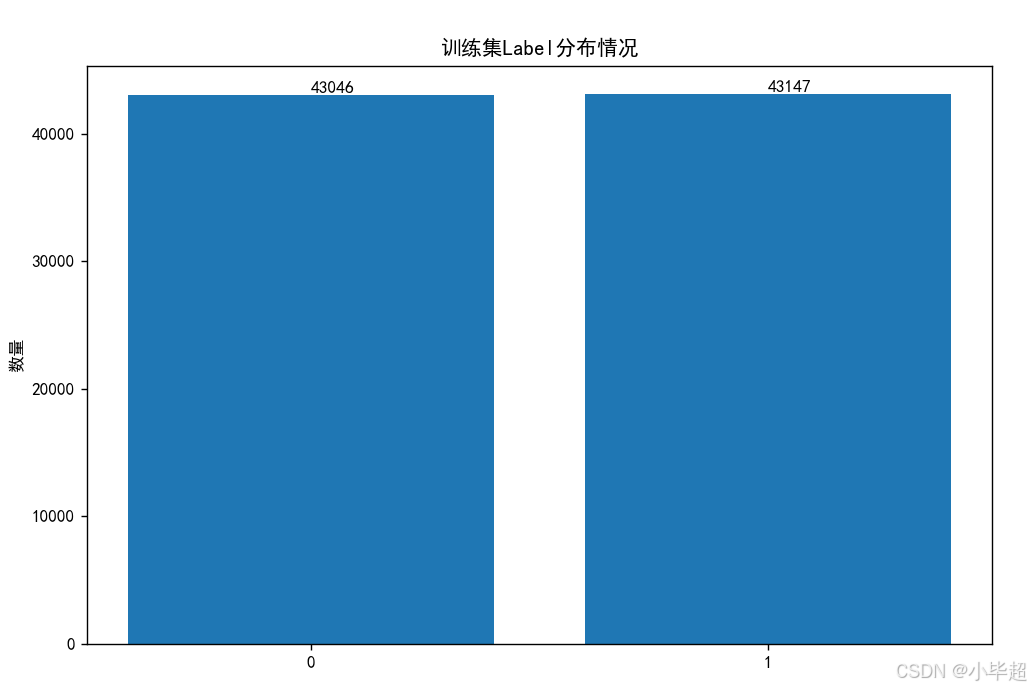
整体标签分布是非常均衡的。
下面统计下 train.csv 的 Token 数分布,以便后面训练时指定一个合理的 max_length:
from transformers import BertTokenizer
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei']
# 获取Token数
def get_num_tokens(file_path, tokenizer):
input_num_tokens = []
df = pd.read_csv(file_path)
for index, row in df.iterrows():
sentence1 = row["sentence1"]
sentence2 = row["sentence2"]
tokens = len(tokenizer(sentence1, sentence2)["input_ids"])
## bert最大512,将超过512的丢弃
if tokens > 512:
continue
input_num_tokens.append(tokens)
return input_num_tokens
# 计算分布
def count_intervals(num_tokens, interval):
max_value = max(num_tokens)
intervals_count = {
}
for lower_bound in range(0, max_value + 1, interval):
upper_bound = lower_bound + interval
count = len([num for num in num_tokens if lower_bound <= num < upper_bound])
intervals_count[f"{
lower_bound}-{
upper_bound}"] = count
return intervals_count
def main():
model_path = "D:/AIGC/model/mengzi-bert-base"
train_data_path = "dataset/train.csv"
tokenizer = BertTokenizer.from_pretrained(model_path)
input_num_tokens = get_num_tokens(train_data_path, tokenizer)
intervals_count = count_intervals(input_num_tokens, 20)
print(intervals_count)
x = [k for k, v in intervals_count.items()]
y = [v for k, v in intervals_count.items()]
plt.figure(figsize=(8, 6))
bars = plt.bar(x, y)
plt.title('训练集Token分布情况')
plt.ylabel('数量')
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom')
plt.show()
if __name__ == '__main__':
main()
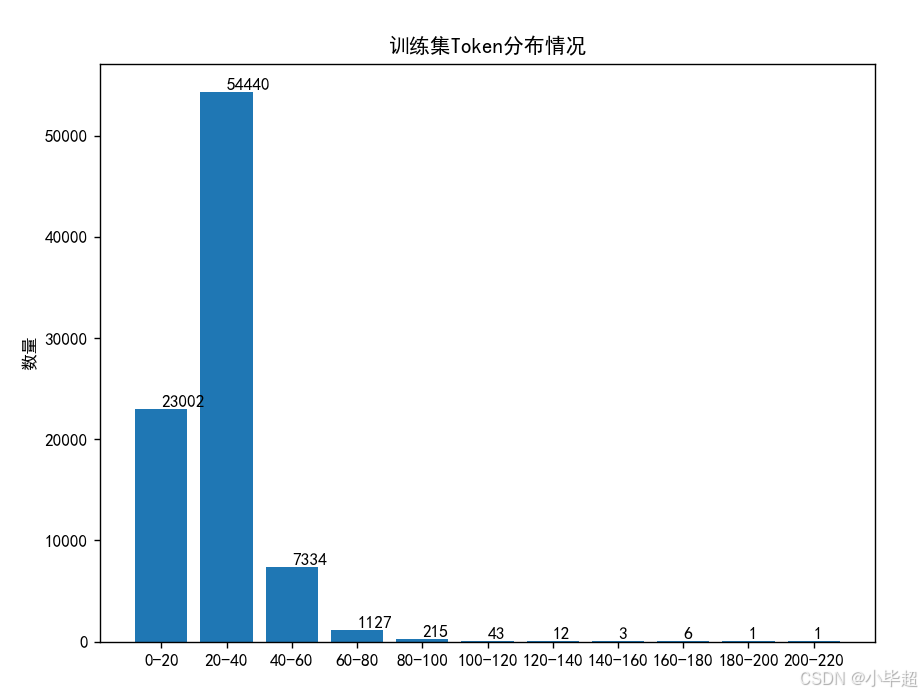
数据集 Token量主要都分布在 20-40 之间,整体来看后面 max_length 可以设置为 64 。
二、微调训练
构建 Dataset ,equate_dataset.py
# -*- coding: utf-8 -*-
from torch.utils.data import Dataset
import torch
import pandas as pd
class EquateDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length) -> None:
super().__init__()
self.tokenizer = tokenizer
self.max_length = max_length
self.data = []
if data_path:
df = pd.read_csv(data_path)
for index, row in df.iterrows():
sentence1 = row["sentence1"]
sentence2 = row["sentence2"]
label = row["label"]
tokens = len(tokenizer(sentence1, sentence2)["input_ids"])
if tokens > 512:
continue
self.data.append({
"sentence1": sentence1,
"sentence2": sentence2,
"label": label
})
print("data load , size:", len(self.data))
def preprocess(self, sentence1, sentence2, label):
encoding = self.tokenizer.encode_plus(
sentence1, sentence2,
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
input_ids = encoding["input_ids"].squeeze()
attention_mask = encoding["attention_mask"].squeeze()
return input_ids, attention_mask, label
def __getitem__(self, index):
item_data = self.data[index]
input_ids, attention_mask, label = self.preprocess(**item_data)
return {
"input_ids": input_ids.to(dtype=torch.long),
"attention_mask": attention_mask.to(dtype=torch.long),
"labels": torch.tensor(label, dtype=torch.long)
}
def __len__(self):
return len(self.data)
微调训练:
# -*- coding: utf-8 -*-
import os.path
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import transformers
from transformers import BertTokenizer, BertForSequenceClassification
from equate_dataset import EquateDataset
from tqdm import tqdm
import time, sys
from sklearn.metrics import f1_score
transformers.logging.set_verbosity_error()
def train_model(model, train_loader, val_loader, optimizer,
device, num_epochs, model_output_dir, scheduler, writer):
batch_step = 0
best_accuracy = 0.0
for epoch in range(num_epochs):
time1 = time.time()
model.train()
for index, data in enumerate(tqdm(train_loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))):
input_ids = data['input_ids'].to(device)
attention_mask = data['attention_mask'].to(device)
labels = data['labels'].to(device)
# 清空过往梯度
optimizer.zero_grad()
# 前向传播
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
# 反向传播,计算当前梯度
loss.backward()
# 更新网络参数
optimizer.step()
writer.add_scalar('Loss/train', loss, batch_step)
batch_step += 1
# 100轮打印一次 loss
if index % 100 == 0 or index == len(train_loader) - 1:
time2 = time.time()
tqdm.write(
f"{
index}, epoch: {
epoch} -loss: {
str(loss)} ; lr: {
optimizer.param_groups[0]['lr']} ;each step's time spent: {
(str(float(time2 - time1) / float(index + 0.0001)))}")
# 验证
model.eval()
accuracy, val_loss, f1 = validate_model(model, device, val_loader)
writer.add_scalar('Loss/val', val_loss, epoch)
writer.add_scalar('Accuracy/val', accuracy, epoch)
writer.add_scalar('F1/val', f1, epoch)
print(f"val loss: {
val_loss} , val accuracy: {
accuracy}, f1: {
f1}, epoch: {
epoch}")
# 学习率调整
scheduler.step(accuracy)
# 保存最优模型
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model_path = os.path.join(model_output_dir, "best")
print("Save Best Model To ", best_model_path, ", epoch: ", epoch)
model.save_pretrained(best_model_path)
# 保存当前模型
last_model_path = os.path.join(model_output_dir, "last")
print("Save Last Model To ", last_model_path, ", epoch: ", epoch)
model.save_pretrained(last_model_path)
def validate_model(model, device, val_loader):
running_loss = 0.0
correct = 0
total = 0
y_true = []
y_pred = []
with torch.no_grad():
for _, data in enumerate(tqdm(val_loader, file=sys.stdout, desc="Validation Data")):
input_ids = data['input_ids'].to(device)
attention_mask = data['attention_mask'].to(device)
labels = data['labels'].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
logits = outputs['logits']
total += labels.size(0)
predicted = logits.max(-1, keepdim=True)[1]
correct += predicted.eq(labels.view_as(predicted)).sum().item()
running_loss += loss.item()
y_true.extend(labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
f1 = f1_score(y_true, y_pred, average='macro')
return correct / total * 100, running_loss / len(val_loader), f1 * 100
def main():
# 基础模型位置
model_name = "hfl/chinese-roberta-wwm-ext"
# 训练集 & 验证集
train_json_path = "dataset/train.csv"
val_json_path = "dataset/dev.csv"
max_length = 64
num_classes = 2
epochs = 15
batch_size = 128
lr = 1e-4
model_output_dir = "output"
logs_dir = "logs"
# 设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=num_classes)
print("Start Load Train Data...")
train_params = {
"batch_size": batch_size,
"shuffle": True,
"num_workers": 4,
}
training_set = EquateDataset(train_json_path, tokenizer, max_length)
training_loader = DataLoader(training_set, **train_params)
print("Start Load Validation Data...")
val_params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 4,
}
val_set = EquateDataset(val_json_path, tokenizer, max_length)
val_loader = DataLoader(val_set, **val_params)
# 日志记录
writer = SummaryWriter(logs_dir)
# 优化器
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
# 学习率调度器,连续两个周期没有改进,学习率调整为当前的0.8
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=2, factor=0.8)
model = model.to(device)
# 开始训练
print("Start Training...")
train_model(
model=model,
train_loader=training_loader,
val_loader=val_loader,
optimizer=optimizer,
device=device,
num_epochs=epochs,
model_output_dir=model_output_dir,
scheduler=scheduler,
writer=writer
)
writer.close()
if __name__ == '__main__':
main()
训练过程如下:
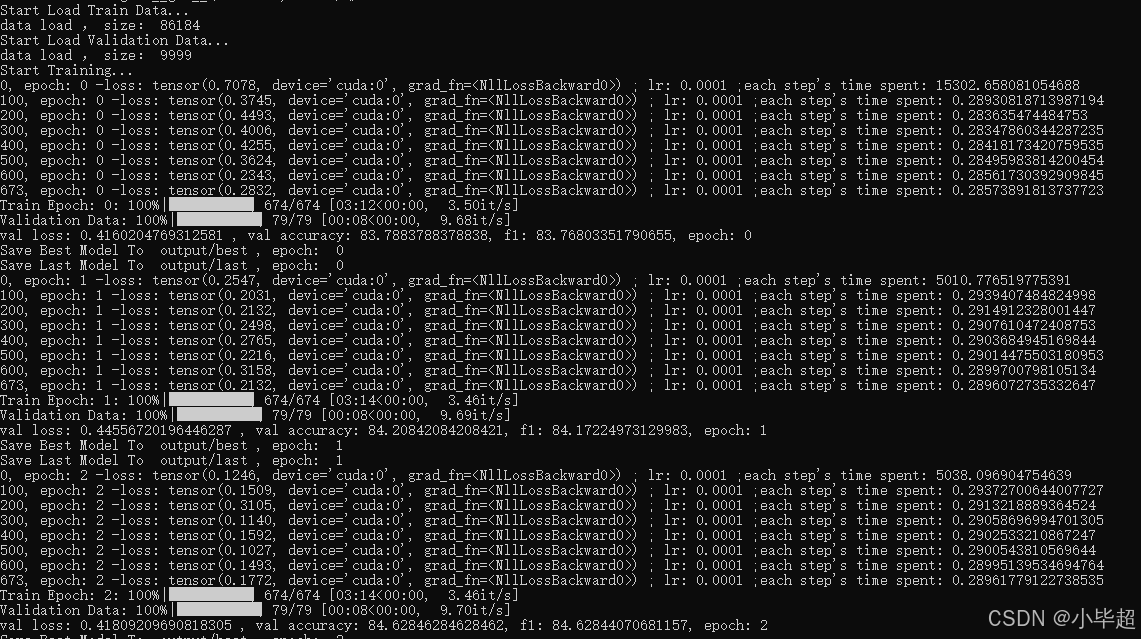
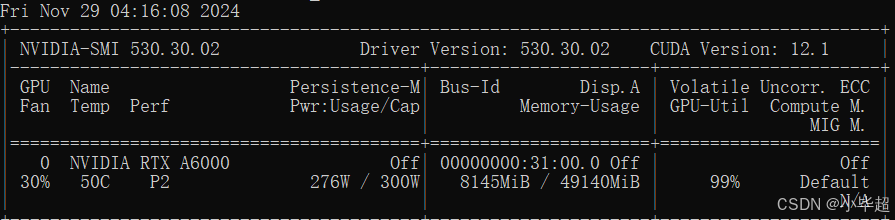
在 batch_size 在 128 的情况下,显存仅占用约 8G:
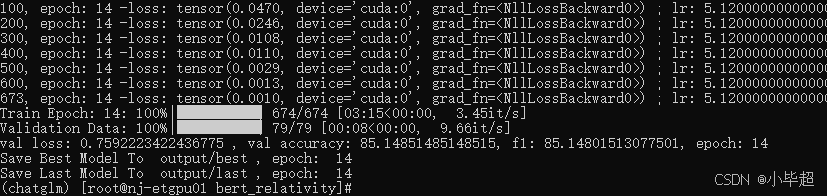
训练结束,最终在 dev 验证集上的 loss 为 0.759,准确率为 85.1485 ,F1:85.1480 :
下面可以通过 tensorboard 查看你训练过程趋势:
tensorboard --logdir=logs --bind_all
在 浏览器访问 http:ip:6006/
三、模型使用测试
# -*- coding: utf-8 -*-
import json
from transformers import BertTokenizer, BertForSequenceClassification
import torch
def main():
base_path = "hfl/chinese-roberta-wwm-ext"
model_path = "output/best"
max_length = 64
num_classes = 2
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载分词器
tokenizer = BertTokenizer.from_pretrained(base_path)
# 加载基础模型
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=num_classes)
model.to(device)
classify = {
0: "语义不相关", 1: "语义等价"
}
tests = [
["一直都没有电话打来", "我很久没有接到电话"],
["换卡要多久", "请问换卡成功没"],
["安全性可靠吗?", "这东西安全吗"],
["不需要帮忙", "别帮我,谢谢"],
["手机停机了怎么办", "我停机了该咋办"],
["为什么不能登录系统总忙。", "解绑后不能登录"],
["年龄没有要求。", "不限制年龄"],
["为什么会审核未通过。", "怎么一直失败?"],
]
for line in tests:
print()
encoding = tokenizer.encode_plus(
line[0], line[1],
max_length=max_length,
return_tensors="pt"
)
input_ids = encoding["input_ids"].to(device)
attention_mask = encoding["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
logits = outputs['logits']
predicted = logits.max(-1, keepdim=True)[1].item()
print(f"{
line} >>> {
classify[predicted]}")
if __name__ == '__main__':
main()
