一、RT-DETR 模型介绍
在计算机视觉领域,目标检测作为一项基础任务,其性能的提升对于自动驾驶、视频监控、智能安防等应用至关重要。而目标检测任务近年来一直被 YOLO 系列模型主导,截止该文章发布,目前 YOLO 已经更新到了 V11 版本了,这也预示着 YOLO 系列有很大的优化空间。不过随着大模型的进一步发展,另一个分支 Transformer 架构也逐渐在 CV 领域崭露头角,其中基于Transformer 架构的多模态模型层出不穷, VIT 也在视觉分类任务上也取得了不错的成绩。这都进一步表示了 Transformer 在CV领域的大有可为。其中 DETR 便是第一个将 Transformer 架构应用在目标检测领域的模型,其创新性地将目标检测任务转化为一个序列生成问题,移除了之前传统模型依赖的 NMS 过程,核心思想是利用 Transformer的强大特征提取和序列建模能力,直接对图像中的目标进行定位和分类。 整体过程如下图所示:
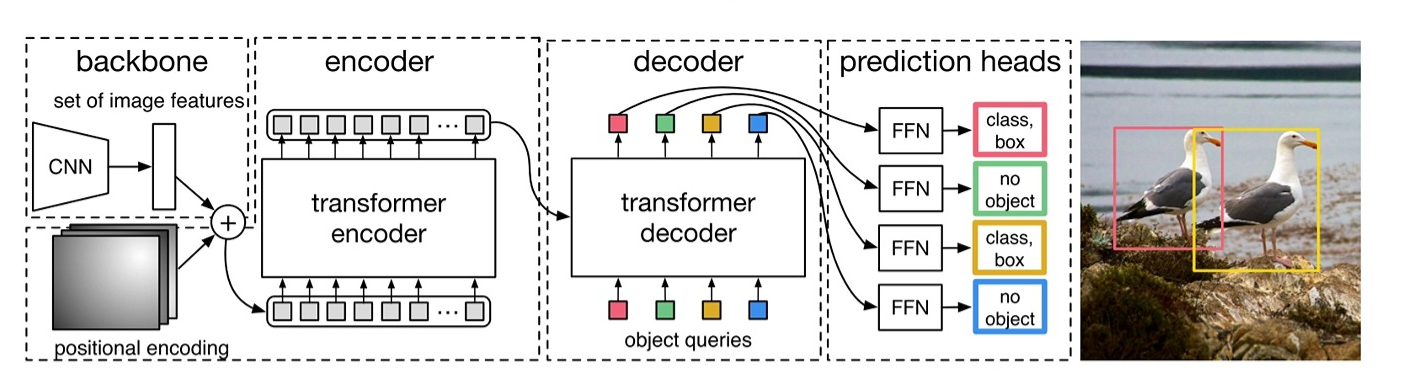
不过 DETR 虽然移除了 NMS 过程,不过相比于 YOLO 系列还是在速度上要慢很多。为此由百度公司提出的新一代的 RT-DETR 模型在DETR的基础上又进行了多项优化。进一步解决了该问题。
RT-DETR 整体结构如下图所示:
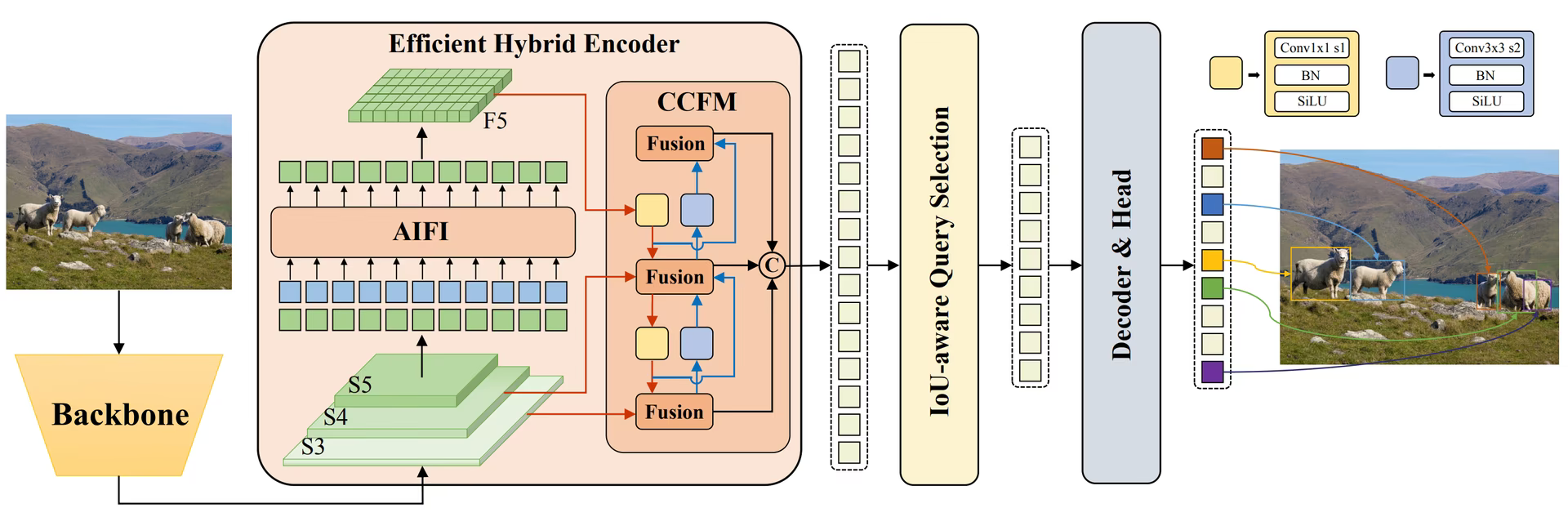
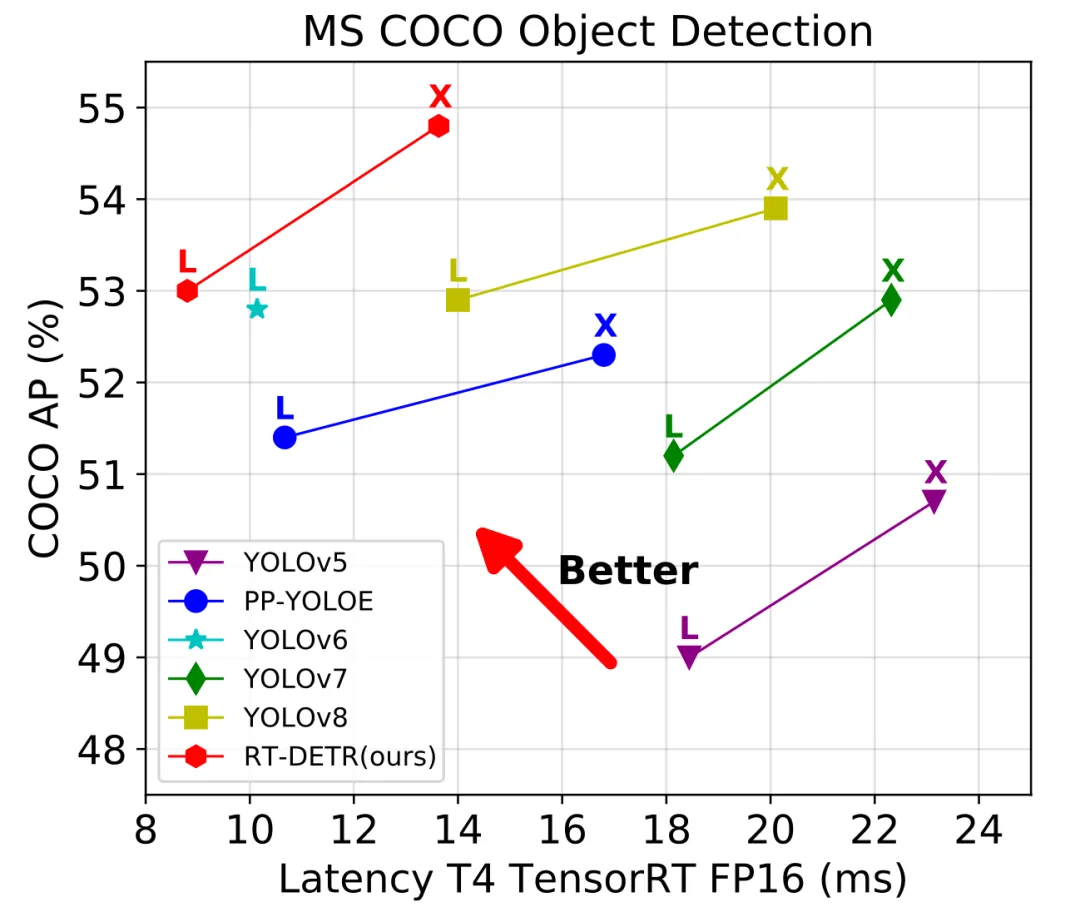
RT-DETR 采用了高效的混合编码器和IoU感知,有效降低了计算成本、提高了检测精度。在速度和精度方面均超过了 YOLOV8 。
主要特点
- 高效混合编码器:采用高效混合编码器,通过解耦尺度内交互和跨尺度融合来处理多尺度特征。这种独特的基于
Vision Transformers的设计降低了计算成本,并允许实时物体检测。 - IoU 感知查询选择:通过
IoU感知查询选择改进了对象查询初始化。这使得模型能够专注于场景中最相关的对象,从而提高检测精度。 - 推理速度可调:支持通过使用不同的解码器层灵活调整推理速度,无需重新训练。这种适应性有助于在各种实时目标检测场景中的实际应用。
RT-DETR 模型使用
本文使用 ultralytics 框架进行测试和后续微调训练,其中 ultralytics 和 pytorch 的版本如下:
torch==1.13.1+cu116
ultralytics==8.3.0
Ultralytics 提供了不同尺度的预训练 RT-DETR 模型:
- RT-DETR-L:
53,0% AP auf COCO val2017, 114 FPS auf T4 GPU - RT-DETR-X:
54,8% AP auf COCO val2017, 74 FPS auf T4 GPU
预训练模型下载地址:
模型使用:
测试图片

预测目标:
from ultralytics import RTDETR
# Load a model
model = RTDETR('rtdetr-l.pt')
model.info()
results = model.predict('../img/1.png')
results[0].show()

可以观察到就连手里拿着的手机都被检测出来了,效果确实非常不错。
二、微调训练自定义的目标检测
数据集使用本专栏前面实验 YOLO-V10 时标注的人脸数据集, 这里你可以收集一些自定义的图片,然后根据下面文章中介绍的方式进行标注:
微调训练,其中 face.yaml 文件内容和上面文章 YOLO-V10 时的一致:
from ultralytics import RTDETR
# 加载模型
model = RTDETR('rtdetr-l.pt')
# 训练
model.train(
data='face.yaml', # 训练配置文件
epochs=50, # 训练的周期
imgsz=640, # 图像的大小
device=[0], # 设备,如果是 cpu 则是 device='cpu'
workers=0,
lr0=0.01, # 学习率
batch=8, # 批次大小
amp=False # 是否启用混合精度训练
)
运行后可以看到打印的网络结构:
from n params module arguments
0 -1 1 25248 ultralytics.nn.modules.block.HGStem [3, 32, 48]
1 -1 6 155072 ultralytics.nn.modules.block.HGBlock [48, 48, 128, 3, 6]
2 -1 1 1408 ultralytics.nn.modules.conv.DWConv [128, 128, 3, 2, 1, False]
3 -1 6 839296 ultralytics.nn.modules.block.HGBlock [128, 96, 512, 3, 6]
4 -1 1 5632 ultralytics.nn.modules.conv.DWConv [512, 512, 3, 2, 1, False]
5 -1 6 1695360 ultralytics.nn.modules.block.HGBlock [512, 192, 1024, 5, 6, True, False]
6 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
7 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
8 -1 1 11264 ultralytics.nn.modules.conv.DWConv [1024, 1024, 3, 2, 1, False]
9 -1 6 6708480 ultralytics.nn.modules.block.HGBlock [1024, 384, 2048, 5, 6, True, False]
10 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
11 -1 1 789760 ultralytics.nn.modules.transformer.AIFI [256, 1024, 8]
12 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 7 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
15 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
17 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
18 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
19 3 1 131584 ultralytics.nn.modules.conv.Conv [512, 256, 1, 1, None, 1, 1, False]
20 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
22 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
23 [-1, 17] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
25 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
26 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
27 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
28 [21, 24, 27] 1 7303907 ultralytics.nn.modules.head.RTDETRDecoder [1, [256, 256, 256]]
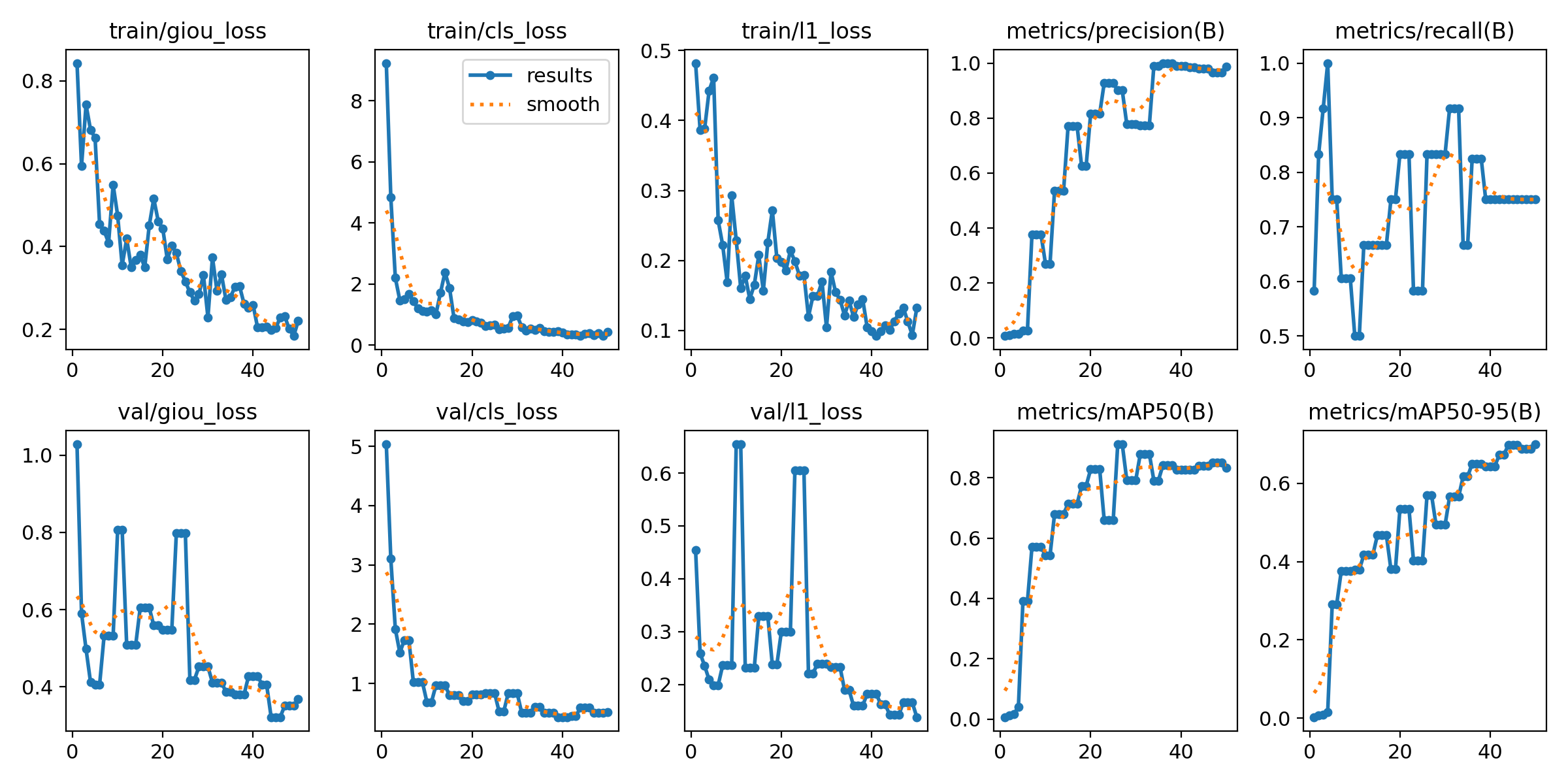
训练结束后可以在 runs 目录下面看到训练的结果,其中 weights 下面的就是训练后保存的模型,这里可以先看下训练时 loss 的变化图:
三、模型测试
在 runs\detect\train\weights 下可以看到 best.pt 和 last.pt 两个模型,表示最佳和最终模型,下面使用 best.pt 模型进行测试
from ultralytics import RTDETR
from matplotlib import pyplot as plt
import os
plt.rcParams['font.sans-serif'] = ['SimHei']
# 测试图片地址
base_path = "../data/images"
# 加载模型
model = RTDETR('runs/detect/train/weights/last.pt')
for img_name in os.listdir(base_path):
img_path = os.path.join(base_path, img_name)
image = plt.imread(img_path)
# 预测
results = model.predict(image, device='cpu')
boxes = results[0].boxes.xyxy
confs = results[0].boxes.conf
ax = plt.gca()
for index, boxe in enumerate(boxes):
x1, y1, x2, y2 = boxe[0], boxe[1], boxe[2], boxe[3]
score = confs[index].item()
ax.add_patch(plt.Rectangle((x1, y1), (x2 - x1), (y2 - y1), linewidth=2, fill=False, color='red'))
plt.text(x=x1, y=y1-10, s="{:.2f}".format(score), fontsize=15, color='white',
bbox=dict(facecolor='black', alpha=0.5))
plt.imshow(image)
plt.show()

