一、搜索内容相关性判断任务
搜索内容相关性任务是指评估用户查询(Query)与搜索引擎返回的文档或信息(Document)之间的匹配程度。这个任务的核心是确定哪些文档最符合用户的查询意图。特别是大模型 RAG的场景下,在使用向量召回时,TopK的选择成了一个棘手的问题。如果TopK选取得太小,可能会遗漏相关文本;而选取得太大,则会增加计算负担和Token数量。因此,构建一个轻量级的搜索内容相关性判断模型显得尤为重要。
本文实验基于 hfl/chinese-roberta-wwm-ext 使用 lora 微调的方式,训练内容相关性判断任务,数据集采用 Github 上公开的QQ浏览器搜索相关性数据集,下面所使用的主要依赖版本如下:
torch==1.13.1+cu116
transformers==4.37.0
peft==0.12.0
数据集地址如下:
该数据集是QQ浏览器搜索引擎目前针对大搜场景构建的一个融合了相关性、权威性、内容质量、 时效性等维度标注的学习排序(LTR)数据集,广泛应用在搜索引擎业务场景中。相关性的含义:0,相关程度差;1,有一定相关性;2,非常相关。数字越大相关性越高。
数据量统计:
| 训练集(train) | 验证集(dev) | 公开测试集(test_public) | 私有测试集(test) |
|---|---|---|---|
| 180,000 | 20,000 | 5,000 | >=10,0000 |
数据集格式如下所示:
{
"id": 0, "query": "小孩咳嗽感冒", "title": "小孩感冒过后久咳嗽该吃什么药育儿问答宝宝树", "label": "1"}
{
"id": 1, "query": "前列腺癌根治术后能活多久", "title": "前列腺癌转移能活多久前列腺癌治疗方法盘点-家庭医生在线肿瘤频道", "label": "1"}
{
"id": 2, "query": "英雄大作战022", "title": "英雄大作战v0.65无敌版英雄大作战v0.65无敌版小游戏4399小游戏", "label": "1"}
{
"id": 3, "query": "如何将一个文件复制到另一个文件里", "title": "怎么把布局里的图纸复制到另外一个文件中去百度文库", "label": "0"}
{
"id": 4, "query": "gilneasart", "title": "gilneas-pictures&charactersart-worldofwarcraftcataclysmlandscapewow和scenery", "label": "1"}
{
"id": 5, "query": "国产手机", "title": "国产手机排行榜2014前十名-手机中国第1页", "label": "2"}
{
"id": 6, "query": "宋昭公出亡文言文阅读及答案", "title": "宋昭公出亡阅读答案文言文宋昭公出亡翻译赏析", "label": "1"}
{
"id": 7, "query": "ueng", "title": "按ueng搜索结果列表-docincom豆丁网", "label": "1"}
{
"id": 8, "query": "ipod坏了去哪里修", "title": "水货ipodnano4坏了去哪里修百度知道", "label": "1"}
{
"id": 9, "query": "qbt2358", "title": "qbt2358标准测试仪-中国行业信息网", "label": "1"}
{
"id": 10, "query": "36个6分之1加上25的9%和是多少", "title": "一个数的百分之36与它的百分之9的和是315求这个数百度知道", "label": "1"}
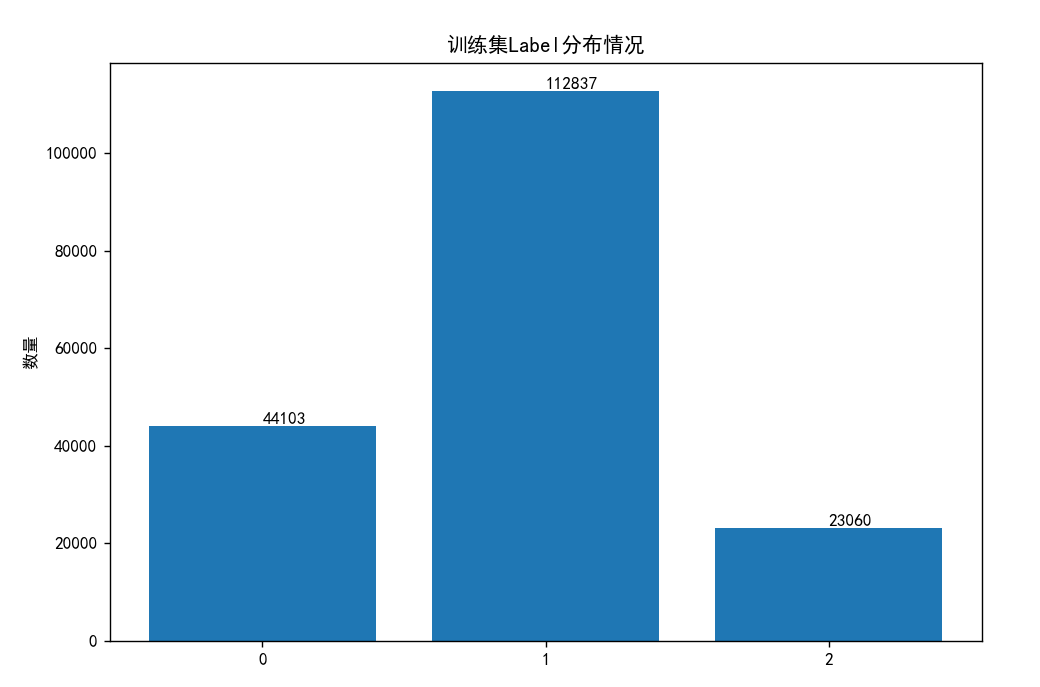
train.json 数据集的标签分布如下:
import json
from transformers import AutoTokenizer
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
def labels_distribution(file_path):
labels = {
"0": 0, "1": 0, "2": 0}
with open(file_path, "r", encoding="utf-8") as r:
for line in r:
line = json.loads(line)
label = line['label']
labels[label] = labels[label] + 1
return labels
def main():
train_data_path = "dataset/train.json"
labels = labels_distribution(train_data_path)
print(labels)
plt.figure(figsize=(8, 6))
x, y = [], []
for label, num in labels.items():
x.append(label)
y.append(num)
bars = plt.bar(x, y)
plt.title('训练集Label分布情况')
plt.ylabel('数量')
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom')
plt.show()
if __name__ == '__main__':
main()
Token 数分布如下:
import json
from transformers import BertTokenizer
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
def get_num_tokens(file_path, tokenizer):
input_num_tokens = []
with open(file_path, "r", encoding="utf-8") as r:
for line in r:
line = json.loads(line)
query = line["query"]
title = line["title"]
input_num_tokens.append(len(tokenizer(query, title)["input_ids"]))
return input_num_tokens
def count_intervals(num_tokens, interval):
max_value = max(num_tokens)
intervals_count = {
}
for lower_bound in range(0, max_value + 1, interval):
upper_bound = lower_bound + interval
count = len([num for num in num_tokens if lower_bound <= num < upper_bound])
intervals_count[f"{
lower_bound}-{
upper_bound}"] = count
return intervals_count
def main():
model_path = "hfl/chinese-roberta-wwm-ext"
train_data_path = "dataset/train.json"
tokenizer = BertTokenizer.from_pretrained(model_path)
print(tokenizer)
input_num_tokens = get_num_tokens(train_data_path, tokenizer)
intervals_count = count_intervals(input_num_tokens, 20)
print(intervals_count)
x = [k for k, v in intervals_count.items()]
y = [v for k, v in intervals_count.items()]
plt.figure(figsize=(8, 6))
bars = plt.bar(x, y)
plt.title('训练集Token分布情况')
plt.ylabel('数量')
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom')
plt.show()
if __name__ == '__main__':
main()
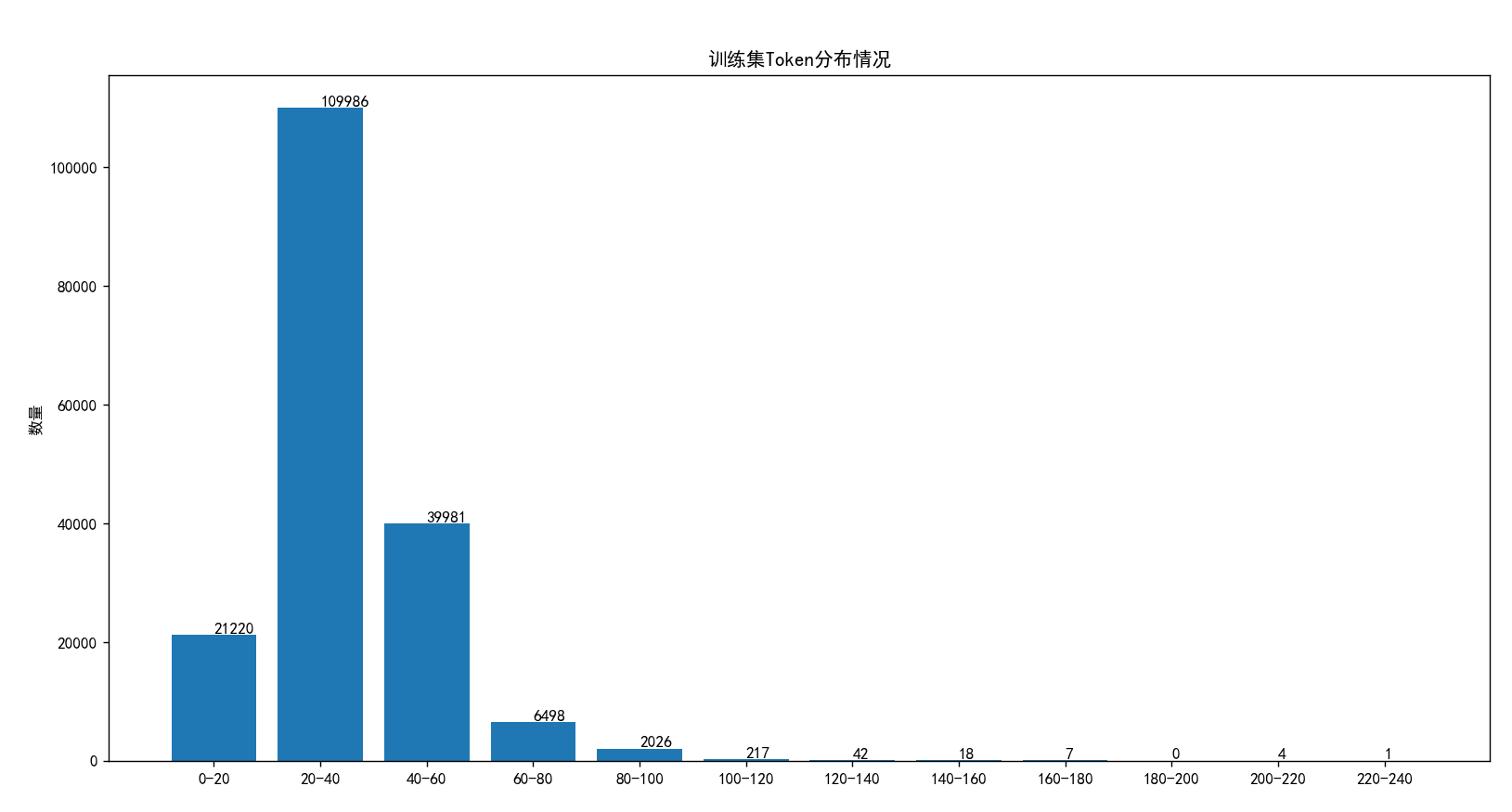
数据集 Token量主要都分布在 20-40 之间。
底座模式采用比较经典的 hfl/chinese-roberta-wwm-ext ,lora 采用 huggleface 中的 peft 框架实现,主要针对自注意力层的 query 、key、value 做降维升维操作,实现过程如下:
from transformers import BertForSequenceClassification
from peft import LoraConfig, get_peft_model, TaskType
model_name = "hfl/chinese-roberta-wwm-ext"
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=3)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["query", "key", "value"],
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
print(model)
整体训练参数仅占 0.43%:
trainable params: 442,368 || all params: 102,712,323 || trainable%: 0.4307
Lora 后的模型结构:
PeftModelForCausalLM(
(base_model): LoraModel(
(model): BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): lora.Linear(
(base_layer): Linear(in_features=768, out_features=768, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.2, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(key): lora.Linear(
(base_layer): Linear(in_features=768, out_features=768, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.2, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(value): lora.Linear(
(base_layer): Linear(in_features=768, out_features=768, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.2, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
.
. 省略中间层
.
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): lora.Linear(
(base_layer): Linear(in_features=768, out_features=768, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.2, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(key): lora.Linear(
(base_layer): Linear(in_features=768, out_features=768, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.2, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(value): lora.Linear(
(base_layer): Linear(in_features=768, out_features=768, bias=True)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.2, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=768, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=768, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=3, bias=True)
)
)
)
二、微调训练
构建 Dataset ,qbqtc_dataset.py
# -*- coding: utf-8 -*-
from torch.utils.data import Dataset
import torch
import json
class QbqtcDataset(Dataset):
def __init__(self, data_path, tokenizer, max_length) -> None:
super().__init__()
self.tokenizer = tokenizer
self.max_length = max_length
self.data = []
if data_path:
with open(data_path, "r", encoding='utf-8') as f:
for line in f:
if not line or line == "":
continue
json_line = json.loads(line)
query = json_line["query"]
title = json_line["title"]
label = int(json_line["label"])
self.data.append({
"query": query,
"title": title,
"label": label
})
print("data load , size:", len(self.data))
def preprocess(self, query, title, label):
encoding = self.tokenizer.encode_plus(
query, title,
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
input_ids = encoding["input_ids"].squeeze()
attention_mask = encoding["attention_mask"].squeeze()
return input_ids, attention_mask, label
def __getitem__(self, index):
item_data = self.data[index]
input_ids, attention_mask, label = self.preprocess(**item_data)
return {
"input_ids": input_ids.to(dtype=torch.long),
"attention_mask": attention_mask.to(dtype=torch.long),
"labels": torch.tensor(label, dtype=torch.long)
}
def __len__(self):
return len(self.data)
微调训练:
# -*- coding: utf-8 -*-
import os.path
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import transformers
from transformers import BertTokenizer, BertForSequenceClassification
from qbqtc_dataset import QbqtcDataset
from tqdm import tqdm
import time, sys
from sklearn.metrics import f1_score
from peft import LoraConfig, get_peft_model, TaskType
transformers.logging.set_verbosity_error()
def train_model(model, train_loader, val_loader, optimizer,
device, num_epochs, model_output_dir, scheduler, writer):
batch_step = 0
best_accuracy = 0.0
for epoch in range(num_epochs):
time1 = time.time()
model.train()
for index, data in enumerate(tqdm(train_loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))):
input_ids = data['input_ids'].to(device)
attention_mask = data['attention_mask'].to(device)
labels = data['labels'].to(device)
# 清空过往梯度
optimizer.zero_grad()
# 前向传播
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
# 反向传播,计算当前梯度
loss.backward()
# 更新网络参数
optimizer.step()
writer.add_scalar('Loss/train', loss, batch_step)
batch_step += 1
# 100轮打印一次 loss
if index % 100 == 0 or index == len(train_loader) - 1:
time2 = time.time()
tqdm.write(
f"{
index}, epoch: {
epoch} -loss: {
str(loss)} ; lr: {
optimizer.param_groups[0]['lr']} ;each step's time spent: {
(str(float(time2 - time1) / float(index + 0.0001)))}")
# 验证
model.eval()
accuracy, val_loss, f1 = validate_model(model, device, val_loader)
writer.add_scalar('Loss/val', val_loss, epoch)
writer.add_scalar('Accuracy/val', accuracy, epoch)
writer.add_scalar('F1/val', f1, epoch)
print(f"val loss: {
val_loss} , val accuracy: {
accuracy}, f1: {
f1}, epoch: {
epoch}")
# 学习率调整
scheduler.step(accuracy)
# 保存最优模型
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model_path = os.path.join(model_output_dir, "best")
print("Save Best Model To ", best_model_path, ", epoch: ", epoch)
model.save_pretrained(best_model_path)
# 保存当前模型
last_model_path = os.path.join(model_output_dir, "last")
print("Save Last Model To ", last_model_path, ", epoch: ", epoch)
model.save_pretrained(last_model_path)
def validate_model(model, device, val_loader):
running_loss = 0.0
correct = 0
total = 0
y_true = []
y_pred = []
with torch.no_grad():
for _, data in enumerate(tqdm(val_loader, file=sys.stdout, desc="Validation Data")):
input_ids = data['input_ids'].to(device)
attention_mask = data['attention_mask'].to(device)
labels = data['labels'].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
logits = outputs['logits']
total += labels.size(0)
predicted = logits.max(-1, keepdim=True)[1]
correct += predicted.eq(labels.view_as(predicted)).sum().item()
running_loss += loss.item()
y_true.extend(labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
f1 = f1_score(y_true, y_pred, average='macro')
return correct / total * 100, running_loss / len(val_loader), f1 * 100
def main():
# 基础模型位置
model_name = "hfl/chinese-roberta-wwm-ext"
# 训练集 & 验证集
train_json_path = "dataset/train.json"
val_json_path = "dataset/dev.json"
max_length = 64
num_classes = 3
epochs = 15
batch_size = 128
lr = 1e-4
model_output_dir = "output"
logs_dir = "logs"
# 设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载分词器和模型
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=num_classes)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["query", "key", "value"],
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
print("Start Load Train Data...")
train_params = {
"batch_size": batch_size,
"shuffle": True,
"num_workers": 4,
}
training_set = QbqtcDataset(train_json_path, tokenizer, max_length)
training_loader = DataLoader(training_set, **train_params)
print("Start Load Validation Data...")
val_params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 4,
}
val_set = QbqtcDataset(val_json_path, tokenizer, max_length)
val_loader = DataLoader(val_set, **val_params)
# 日志记录
writer = SummaryWriter(logs_dir)
# 优化器
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
# 学习率调度器,连续两个周期没有改进,学习率调整为当前的0.8
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=2, factor=0.8)
model = model.to(device)
# 开始训练
print("Start Training...")
train_model(
model=model,
train_loader=training_loader,
val_loader=val_loader,
optimizer=optimizer,
device=device,
num_epochs=epochs,
model_output_dir=model_output_dir,
scheduler=scheduler,
writer=writer
)
writer.close()
if __name__ == '__main__':
main()
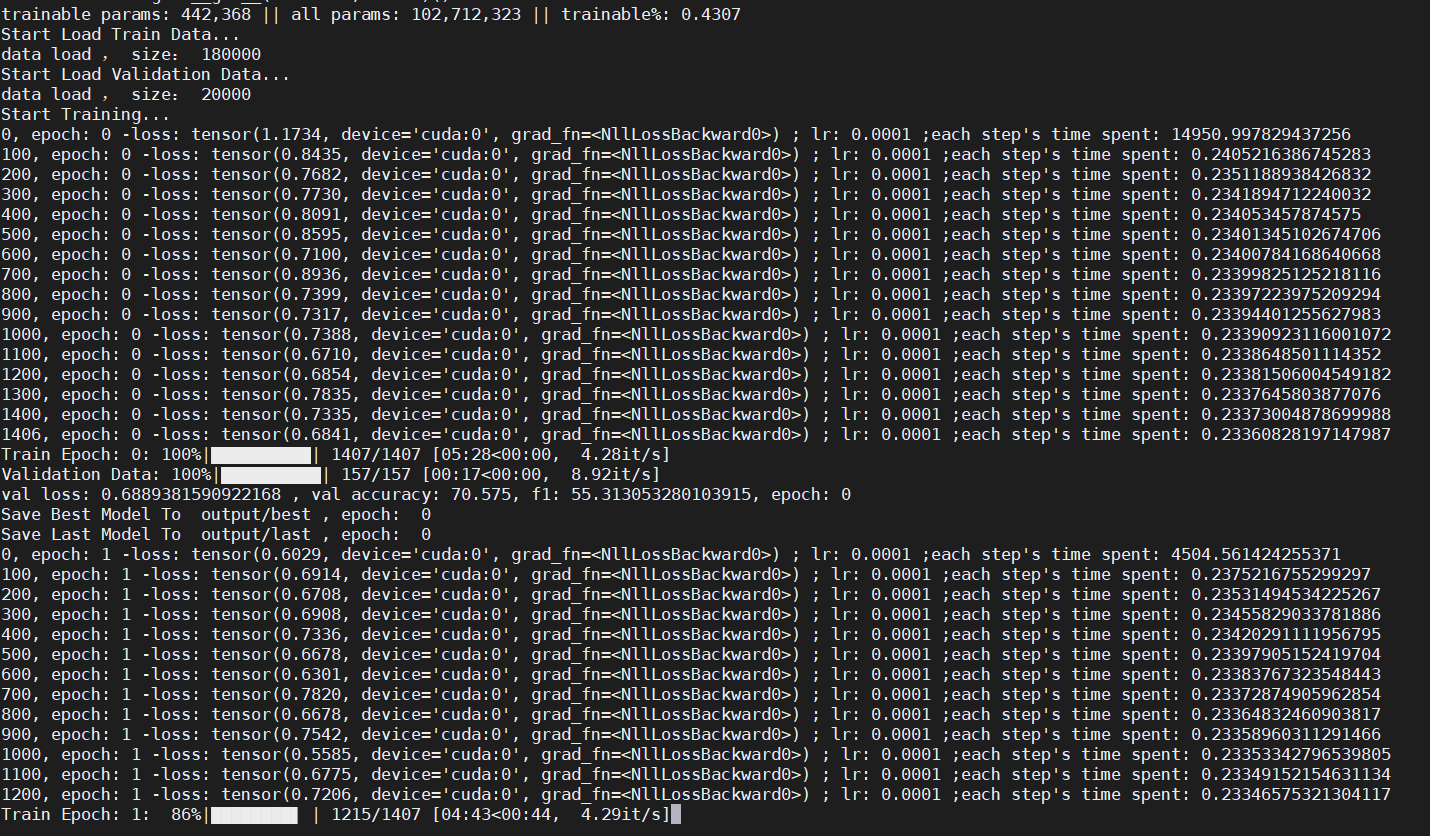
训练过程如下:
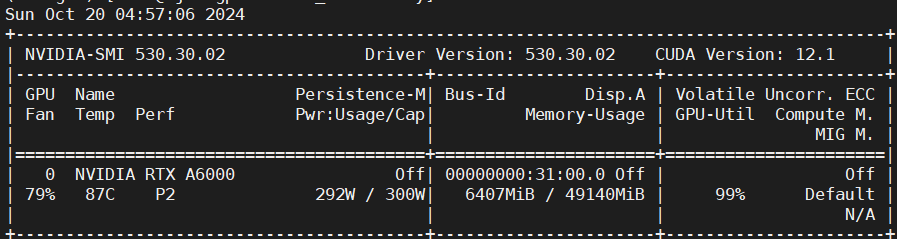
在 batch_size 在 128 的情况下,显存仅占用约 6.2G:
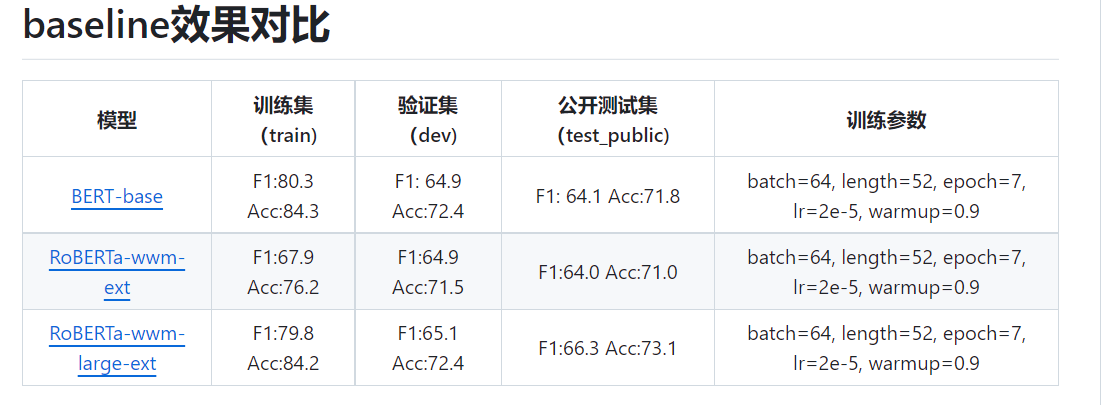
训练结束,最终在 dev 验证集上准确率为 72.5 ,F1:63.3 :

整体和 GitHub 上原作者的效果差不多:
查看 tensorboard 训练过程趋势:
tensorboard --logdir=logs --bind_all
在 浏览器访问 http:ip:6006/



三、模型测试
# -*- coding: utf-8 -*-
import json
from transformers import BertTokenizer, BertForSequenceClassification
from peft import PeftModel
import torch
def main():
model_path = "hfl/chinese-roberta-wwm-ext"
lora_model_path = "output/best"
val_data_path = "dataset/test.json"
max_length = 64
num_classes = 3
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载分词器
tokenizer = BertTokenizer.from_pretrained(model_path)
# 加载基础模型
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=num_classes)
# 加载Lora模型
model = PeftModel.from_pretrained(model, lora_model_path)
model.to(device)
classify = {
0: "相关程度差", 1: "有一定相关性", 2: "非常相关"
}
with open(val_data_path, 'r', encoding="utf-8") as r:
for line in r:
line = json.loads(line)
query = line["query"]
title = line["title"]
encoding = tokenizer.encode_plus(
query, title,
max_length=max_length,
return_tensors="pt"
)
input_ids = encoding["input_ids"].to(device)
attention_mask = encoding["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
logits = outputs['logits']
predicted = logits.max(-1, keepdim=True)[1].item()
print(f"{
query} 。 {
title} 。 {
classify[predicted]}")
if __name__ == '__main__':
main()

三、模型合并
上面训练后存储的是 Lora 结构模型,所以在使用时需要分别加载基础模型和Lora模型,可以将两个模型合并成一个完整的模型使用:
# -*- coding: utf-8 -*-
from transformers import BertTokenizer, BertForSequenceClassification
import torch
from peft import PeftModel
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_path = "hfl/chinese-roberta-wwm-ext"
lora_model_path = "output/best"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForSequenceClassification.from_pretrained(model_path)
model = PeftModel.from_pretrained(model, lora_model_path).to(device)
# 合并model, 同时保存 token
model = model.merge_and_unload()
model.save_pretrained("lora_output")
tokenizer.save_pretrained("lora_output")
然后就可以只读区一次模型了:
# -*- coding: utf-8 -*-
import json
from transformers import BertTokenizer, BertForSequenceClassification
import torch
def main():
model_path = "lora_output"
val_data_path = "dataset/test.json"
max_length = 64
num_classes = 3
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载分词器
tokenizer = BertTokenizer.from_pretrained(model_path)
# 加载基础模型
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=num_classes)
print(model)
model.to(device)
classify = {
0: "相关程度差", 1: "有一定相关性", 2: "非常相关"
}
with open(val_data_path, 'r', encoding="utf-8") as r:
for line in r:
line = json.loads(line)
query = line["query"]
title = line["title"]
encoding = tokenizer.encode_plus(
query, title,
max_length=max_length,
return_tensors="pt"
)
input_ids = encoding["input_ids"].to(device)
attention_mask = encoding["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
logits = outputs['logits']
predicted = logits.max(-1, keepdim=True)[1].item()
print(f"{
query} 。 {
title} 。 {
classify[predicted]}")
if __name__ == '__main__':
main()