1.简介
有效扩展上下文长度对于将大型语言模型(LLM)推向人工通用智能(AGI)至关重要。然而,传统注意力机制中固有的二次计算复杂度显著增加了计算开销,这成为了实现这一目标的一大障碍。
在这项工作中,作者了混合块注意力(MoBA),一种创新的方法,适用于混合专家(MoE)的注意力机制的原则。这种新颖的架构在长上下文任务上表现出了极佳性能,同时提供了一个关键优势:能够在完全注意力和稀疏注意力之间无缝转换,提高效率而不会影响性能。MoBA已经被部署来支持Kimi的长上下文请求,并在LLM的有效注意力计算方面取得了重大进展。
-
-
2.论文详解
简介
对人工通用智能(AGI)的追求推动了大型语言模型(LLM)的发展,使其达到了前所未有的规模,并有望处理模拟人类认知的复杂任务。实现AGI的一个关键能力是处理、理解和生成长序列的能力,这对于从历史数据分析到复杂推理和决策过程的广泛应用至关重要。
然而,由于标准注意力机制相关的计算复杂性呈二次增长,因此在LLM中扩展序列长度并非易事。这一挑战激发了一波旨在提高效率而不牺牲性能的研究。一个突出的方向是利用注意力分数的内在稀疏性。这种稀疏性在数学上来自softmax操作。
Softmax函数的稀疏性是指在计算过程中,对于给定的输入向量,只有少数几个元素(即概率值)会显著大于零,而其他大多数元素则接近于零。这种现象在处理长序列和高维数据时尤为明显,因为Softmax函数会将输入向量转换为一个概率分布,其中大部分概率质量集中在少数几个元素上。
为什么Softmax具有稀疏性?
指数函数的性质:Softmax函数是通过指数函数和归一化操作来计算的。对于输入向量 x,Softmax函数定义为:
其中 xi 是输入向量的第 i 个元素。指数函数 exi 会放大输入值的差异,使得较大的输入值对应的概率值显著大于较小的输入值。
归一化操作:Softmax函数的分母是所有指数值的和,这确保了输出向量是一个概率分布,即所有元素的和为1。这种归一化操作进一步加剧了概率值的集中,因为较小的指数值在归一化后会变得更小。
长尾分布:在许多实际应用中,如自然语言处理和图像识别,数据的分布往往是长尾的。这意味着只有少数几个类别或元素出现的频率很高,而大多数类别或元素出现的频率很低。Softmax函数在这种情况下会将大部分概率质量分配给那些高频的类别或元素,而低频的类别或元素则分配到接近于零的概率值。
现有的方法通常利用预定义的结构约束,如sink-based的或滑动窗口注意,以利用这种稀疏性。虽然这些方法可能是有效的,但它们往往是依赖于特定任务,可能会阻碍模型的整体通用性。或者使用一系列动态稀疏注意机制,例如Quest,Minference和RetrievalAttention,这些方法在推理时选择标记的子集。虽然这样的方法可以减少长序列的计算,但它们并没有实质上减轻长上下文模型的密集训练成本,这使得将LLM有效地扩展到数百万个令牌的上下文具有挑战性。
另一种有前途的替代方法最近以线性注意力模型的形式出现,如Mamba,RWKV和RetNet。这些方法用线性近似代替了基于规范softmax的注意力,从而减少了长序列处理的计算开销。然而,由于线性注意力和传统注意力之间的实质性差异,调整现有的Transformer模型通常会导致高转换成本或需要从头开始训练全新的模型。更重要的是,它们在复杂推理任务中的有效性的证据仍然有限。
因此,一个关键的研究问题出现了:我们如何设计一个强大的和适应性强的注意力架构,保留原来的Transformer框架,同时坚持“少结构”的原则,允许模型来确定在哪里参加,而不依赖于预定义的结果?理想情况下,这种架构将在完全注意力模式和稀疏注意力模式之间无缝转换,从而最大限度地提高与现有预训练模型的兼容性,并在不影响性能的情况下实现高效推理和加速训练。
因此,作者引入了一种新型架构,称为块注意力混合(MoBA),它通过动态选择历史片段(块)进行注意力计算来扩展Transformer模型的功能。MoBA受到混合专家(MoE)和稀疏注意力技术的启发。前一种技术主要应用于Transformer架构中的前馈网络(FFN)层,而后者已被广泛用于缩放Transformer以处理长上下文。
-
方法
初步准备:Transformer中的标准注意力
首先回顾一下Transformer中的注意力标准。为了简单起见,我们重新考虑单个Query令牌涉及N个Key令牌和Value令牌的情况,分别表示
。标准注意力计算如下:
,其中d表示单个注意力头部的尺寸。
-
MoBA架构
与每个Query令牌关注整个上下文的标准关注不同,MoBA使每个Query令牌仅关注Key和Value的子集:,其中
是所选Key和Value的集合。
MoBA的关键创新是块划分和选择策略。作者将长度为N的完整上下文划分为n个块,其中每个块表示后续令牌的子集。这里假设上下文长度N可被块的数量n整除。可以进一步将表示为块大小,而
是第i个块的范围。
通过应用来自MoE的top-k门控机制,可以使每个Query能够选择性地关注来自不同块的令牌子集,而不是整个上下文:为每个查询标记选择最相关的块。具体步骤是首先计算度量Query q和第i个块之间的相关性的亲和度分数si,并在所有块之间应用Top-k门控。
其中,第i个块gi的门值通过下式计算:
其中Topk(·,k)表示包含针对每个块计算的亲和度分数中的k个最高分数的集合。在这项工作中,得分si是通过q和K [Ii]的平均池化沿着序列维度之间的内积计算的:
-
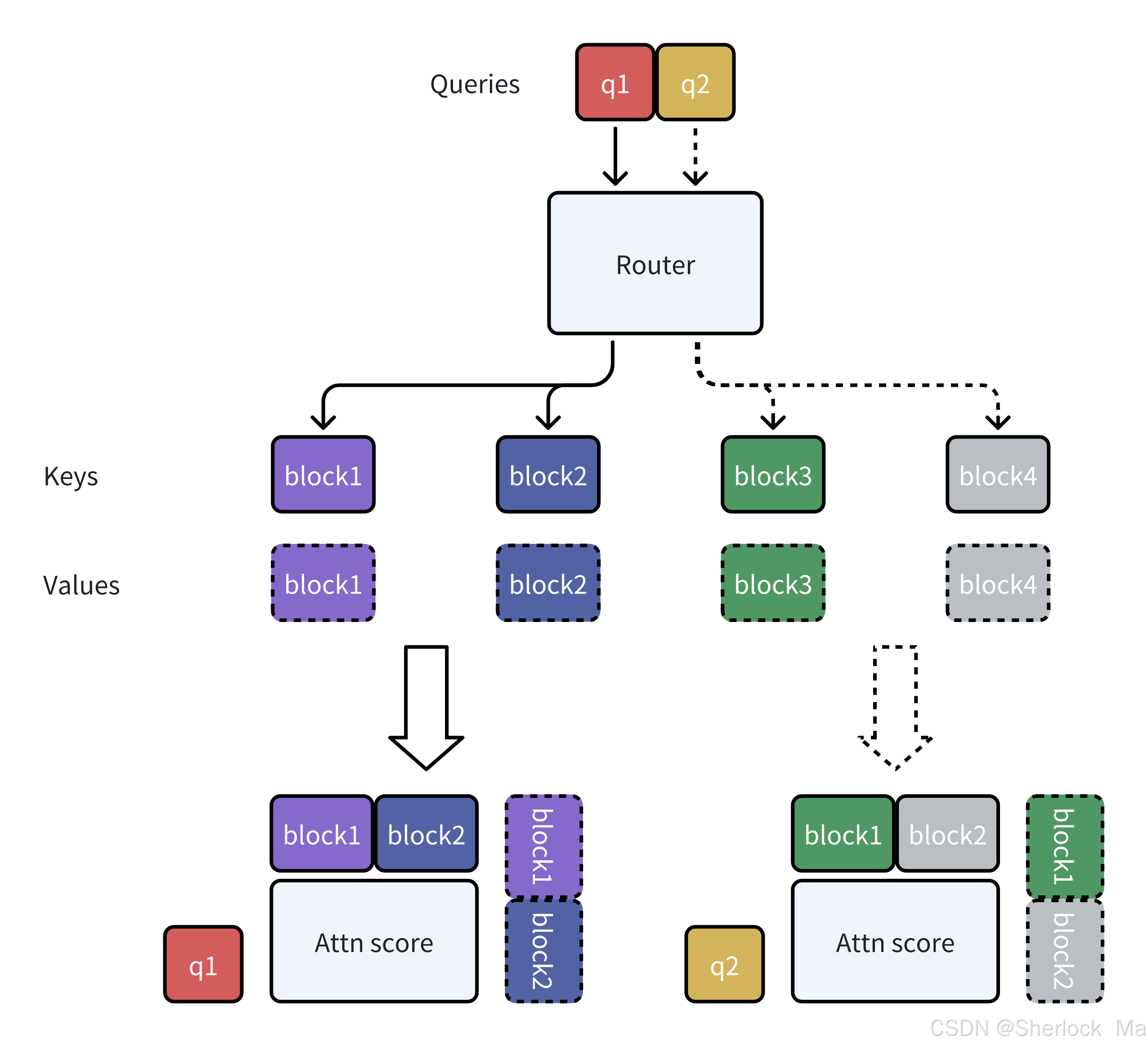
在图1a中提供了一个MoBA的运行示例,其中有两个Query令牌和四个KV块。
运行过程
-
块分割(Block Partitioning)
-
将整个序列的键(Key)和值(Value)分割成多个块(Block)。图1a中展示了4个块,每个块用不同的颜色表示。
-
-
动态选择最相关的块(Dynamic Block Selection)
-
对于每个查询(Query),MoBA通过一个路由网络(Router)计算Query与每个块的相关性分数(Affinity Score)。
-
根据这些分数,路由网络选择与Query最相关的块。图中展示了每个Query选择的块:
-
第一个查询(Query 1)选择了第1块和第2块。
-
第二个查询(Query 2)选择了第3块和第4块。
-
-
-
注意力计算(Attention Computation)
-
每个Query只对它选择的块进行注意力计算,而不是对整个序列进行计算。
-
这种稀疏的注意力模式显著减少了计算量,同时保留了关键信息。
-
-
具体步骤
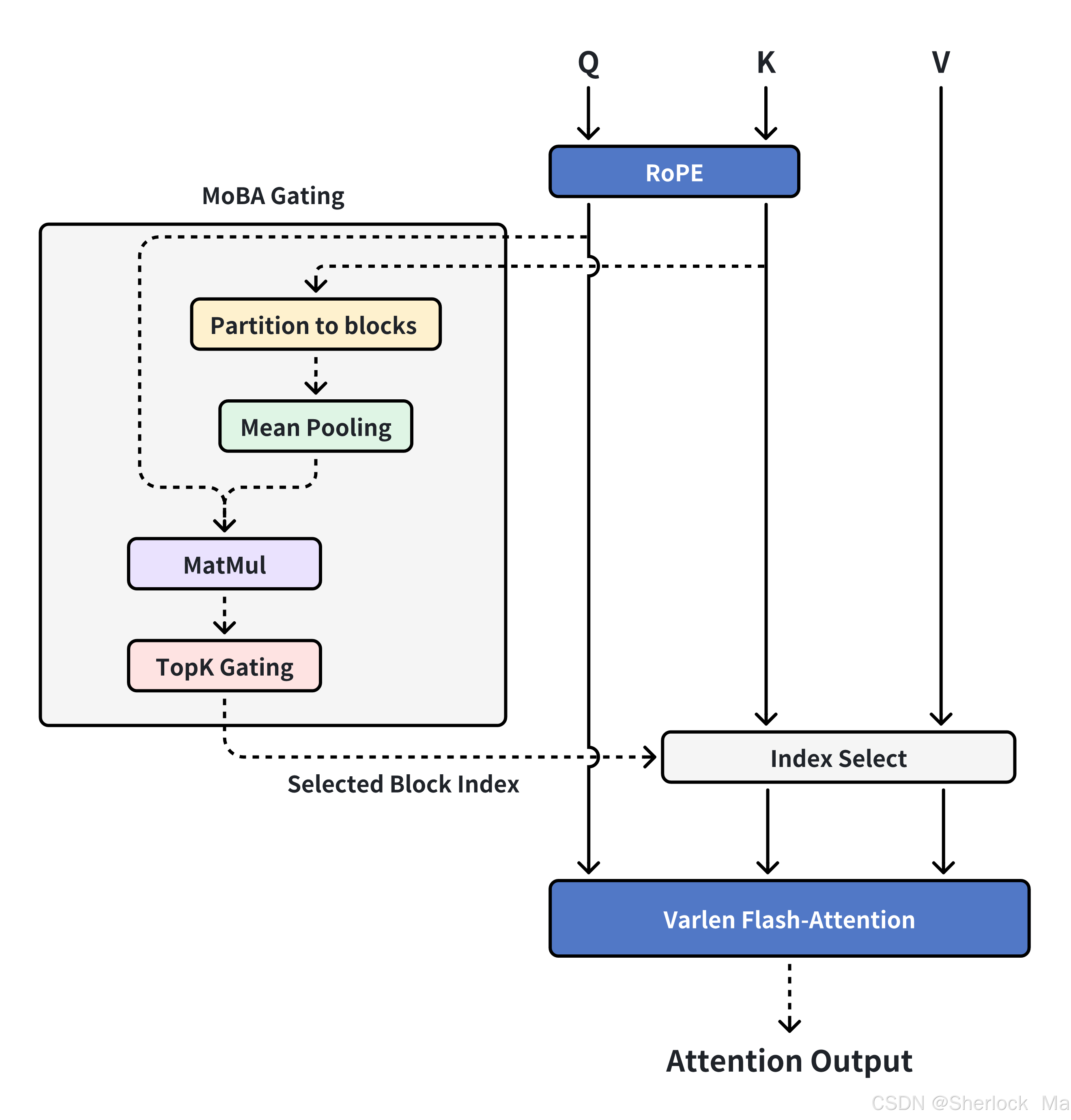
算法工作流程在算法1中形式化,并在图1b中可视化,说明了如何基于MoE和FlashAttention实现MoBA。下面是对算法1的注释:
-
输入
-
Q, K, V:分别是查询(Query)、键(Key)和值(Value)矩阵,维度为 N×h×d,其中 N 是序列长度,h 是注意力头的数量,d 是每个头的维度。
-
块大小 B:将序列分成多个块,每个块包含 B 个连续的键和值。
-
Top-k:每个查询最多可以选择的块数量。
-
总块数 n=BN:序列长度 N 除以块大小 B。
-
- 首先,KV矩阵被划分成块(第2行)。
-
计算块的平均池化表示(第4行):对每个块的键矩阵 K 进行平均池化操作,得到每个块的表示
,其维度为 n×h×d。
- 计算查询与块的亲和力分数:根据(第5行)计算门控分数,该公式用于测量Query查询标记和KV块之间的相关性(第5行)。
-
应用因果掩码并选择Top-k块(第7-8行)
- 因果掩码:确保查询只能关注当前块和过去的块,不能关注未来的块。掩码 M 的维度为 N×n。
-
Top-k选择:对每个查询,从亲和力分数和掩码 S+M 中选择Top-k个块,生成稀疏的查询到块的映射矩阵 G。
- 重新排列查询和块(第10-11行)
- 根据映射矩阵 G,将查询 Q 和对应的块 K,V 重新排列,以便高效计算注意力。
-
分别处理当前块的注意力(
Qs, Ks, Vs)和历史块的注意力(Qm, Km, Vm)。
- 计算逐块注意力输出(第13-14行):值得注意的是,对历史块的关注(行11和14)和当前块的关注(行10和13)是分开计算的,因为需要在当前块的关注中保持额外的因果关系。
-
当前块的关注:表示在当前块内应用因果掩码(Causal Mask),以确保因果关系。这意味着当前块内的查询只能关注其之前的位置,而不能关注未来的位置。
-
对历史块的关注:这些输出是动态选择的块的注意力结果,不涉及因果掩码。
-
-
将当前块和历史块的注意力输出合并,并通过在线Softmax操作(动态调整权重)生成最终的注意力输出 O。
-
O:最终的注意力输出,维度为 N×h×d。
-

因果关系
在自回归语言模型中保持因果关系是很重要的,因为它们通过基于先前标记的下一个标记预测来生成文本。这种顺序生成过程确保了一个标记不会影响到它之前的标记,从而保持了因果关系。MoBA通过两种特定的设计保留了因果关系:
因果关系:不注意未来的块。MoBA确保查询令牌不能被路由到任何未来的块。通过将注意力范围限制在当前和过去的块上,MoBA坚持了语言建模的自回归性质。更正式地说,将pos(q)表示为查询q的位置索引,对任何块i设置si = −∞和gi = 0,使得pos(q)< i ×B。
当前块注意力和因果掩蔽。作者将“当前块”定义为包含查询令牌本身的块。到当前块的路由也可能违反因果关系,因为整个块的平均池可能会无意中包含来自未来令牌的信息。当前块注意力 是指模型在处理当前查询时,必须关注其所在的块内的键和值,而不仅仅是动态选择的其他块,并在当前块注意期间应用因果掩码。这种策略不仅避免了后续令牌的任何信息泄漏,而且还鼓励关注本地上下文。
-
关键设计
细粒度块分割。受MoE启发,MoBA沿着上下文长度维度而不是FFN中间隐藏维度操作分割。
MoBA和Full Attention的混合体。MoBA被设计成完全注意力的替代品,保持相同数量的参数,没有任何增减。这一功能启发作者在完全注意力和MoBA之间进行平滑过渡。具体而言,在初始化阶段,每个注意力层都可以选择完全注意力或MoBA,并且如果需要,可以在训练期间动态更改此选择。
滑动窗口注意力(Sliding Window Attention)和注意力下沉(Attention Sink)。滑动窗口注意(SWA)和注意下沉是两种流行的稀疏注意结构。作者证明,两者都可以被视为MoBA的特殊情况。
- 对于滑动窗口注意,每个查询标记只关注其相邻标记。这可以被解释为MoBA的一个变体,它具有一个门控网络,不断选择最近的块。
- 同样,注意力下沉,其中每个查询令牌都涉及初始令牌和最近令牌的组合,可以被视为MoBA的变体,具有始终选择初始和最近区块的门控网络。
- 以上讨论表明,MoBA比滑动窗口注意力和注意力下沉具有更强的表现力。此外,它表明,MoBA可以灵活地近似许多静态稀疏注意力架构,通过结合特定的门控网络。
-
实验
标度律实验与烧蚀研究
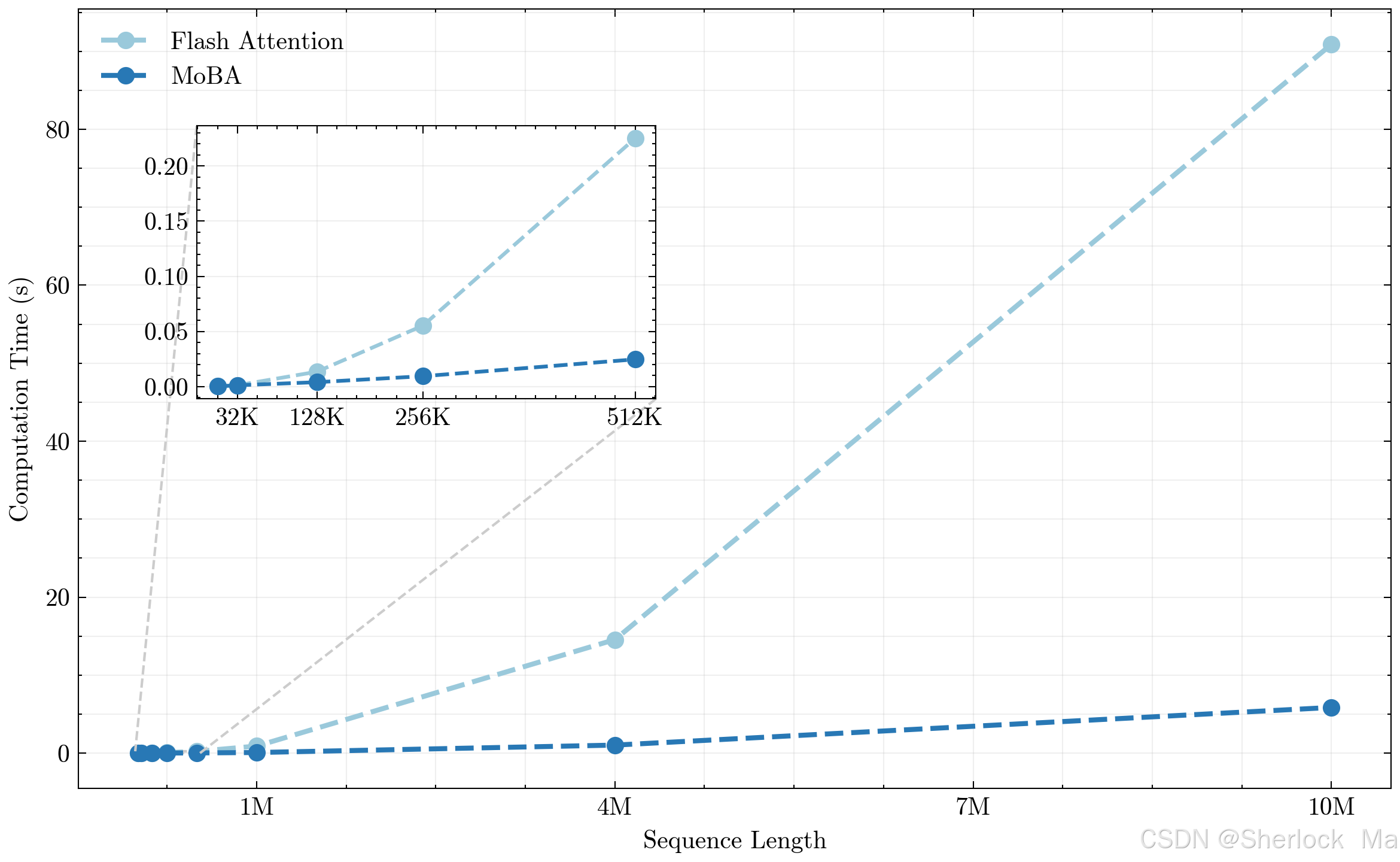
在第3.1节中,作者通过一系列实验验证了Mixture of Block Attention(MoBA)的关键设计选择,并展示了其在长序列任务中的有效性和可扩展性。首先,作者进行了扩展性实验,比较了使用MoBA和全注意力训练的语言模型在验证集上的语言模型(LM)损失。实验遵循Chinchilla扩展性法则,训练了不同大小的模型,并确保每个模型都达到训练最优。结果显示,MoBA在8K序列长度下的验证损失与全注意力非常接近,差异在1e-3以内,表明MoBA在稀疏注意力模式下(最高81.25%的稀疏度)仍能实现与全注意力相当的扩展性能。
为了进一步评估MoBA在长序列上的能力,作者引入了“尾部LM损失”这一指标,专注于序列末尾部分的损失,以避免短序列在数据分布中的偏差。实验中,最大序列长度从8K增加到32K,此时MoBA的稀疏度高达95.31%。结果表明,尽管MoBA在尾部LM损失上略高于全注意力,但差距逐渐缩小,这表明MoBA具有良好的长序列扩展性。
此外,作者还进行了关于MoBA块粒度的消融研究。使用1.5B参数的模型和32K的上下文长度,调整块大小和top-k参数以保持一致的注意力稀疏度(75%)。实验发现,块粒度对MoBA性能有显著影响,细粒度分割(如从128个块中选择32个)比粗粒度分割(如从8个块中选择2个)表现更好,这表明细粒度分割是提升MoBA性能的关键因素。
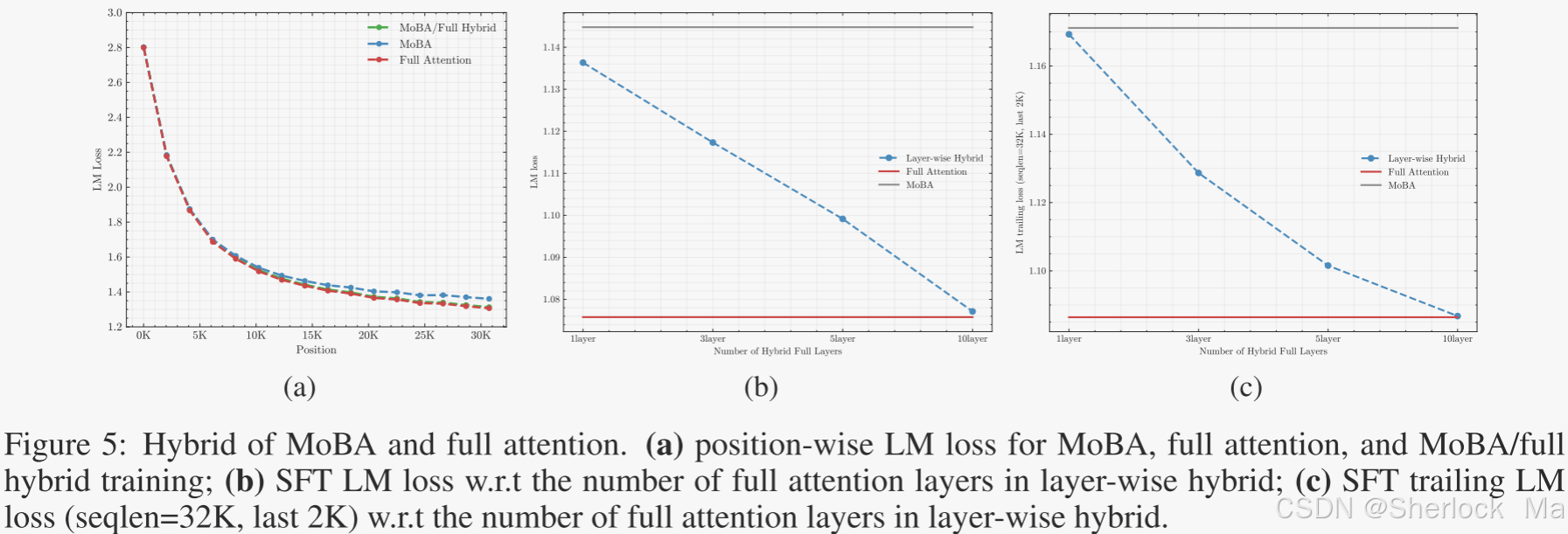
最后,作者探讨了MoBA与全注意力的混合使用策略。在混合训练中,模型先使用MoBA训练90%的token,然后切换到全注意力完成剩余10%的训练。结果显示,这种混合策略在尾部token的LM损失上几乎与全注意力相当,且在MoBA与全注意力之间切换时未观察到显著的损失波动,证明了MoBA的灵活性和鲁棒性。此外,作者还提出了层间混合策略,即在监督微调(SFT)阶段,将部分Transformer层从MoBA切换到全注意力,以解决SFT中稀疏注意力可能面临的梯度稀疏问题。实验表明,这种层间混合策略能显著降低SFT损失,进一步证明了MoBA在实际应用中的有效性。
MoBA和Full Attention的混合
在第3.2节中,作者深入探讨了Mixture of Block Attention(MoBA)与全注意力机制结合使用的灵活性和优势,特别是在长序列预训练和监督微调(SFT)阶段的应用。作者首先提出了MoBA与全注意力的混合训练策略,通过在预训练阶段先使用MoBA高效处理大量token,然后在训练的最后阶段切换到全注意力,以确保模型在长序列上的性能。实验结果表明,这种混合策略能够实现与全注意力相当的性能,同时显著提高了训练效率。
进一步地,作者研究了在监督微调阶段采用层间混合策略的可能性。由于MoBA在SFT阶段可能会因稀疏梯度问题导致性能下降,作者提出在模型的最后几层保留全注意力,而其余层使用MoBA。这种层间混合方法不仅有效解决了稀疏梯度问题,还显著降低了SFT阶段的损失,证明了MoBA在实际应用中的适应性和灵活性。
此外,作者还通过实验验证了MoBA在长序列任务中的性能表现。以Llama-8B模型为例,作者展示了MoBA在不同上下文长度(从128K到1M tokens)下的持续预训练效果,并通过位置插值技术平稳过渡到更长的上下文长度。最终,MoBA在多个长序列基准测试中表现出与全注意力相当的性能,尤其是在最长的RULER任务中,MoBA在128K上下文长度下几乎与全注意力模型匹配。
总体而言,第3.2节通过混合训练和层间混合策略的实验,证明了MoBA不仅能够高效处理长序列,还能在保持性能的同时显著降低计算成本,为大规模语言模型的长序列预训练和微调提供了一种实用且高效的解决方案。
大型语言建模评估
在第3.3节中,作者通过一系列实验全面评估了Mixture of Block Attention(MoBA)在真实世界下游任务中的性能表现,并将其与全注意力机制进行了对比。实验以Llama 3.1 8B Base模型为基础,通过持续预训练将模型的上下文长度从128K逐步扩展到1M tokens,期间采用位置插值技术以适应更长的上下文。在完成1M tokens的持续预训练后,模型继续在100B tokens上进行激活,使用MoBA机制并结合层间混合策略——保留最后三层为全注意力,其余层切换为MoBA,以平衡效率与性能。
在监督微调(SFT)阶段,作者同样采用了逐步增加上下文长度的策略,从32K扩展到1M tokens,并在多个长序列基准测试中对MoBA和全注意力模型进行了性能评估。结果显示,Llama-8B-1M-MoBA在多种任务上的表现与全注意力模型Llama-8B-1M-Full高度接近,例如在RULER任务(128K上下文长度)中,MoBA模型的得分仅略低于全注意力模型,表明其在长序列任务中具有出色的性能和效率平衡。
此外,作者还通过Needle in a Haystack基准测试评估了模型在高达1M tokens的上下文长度下的表现,进一步证明了MoBA在处理极长序列时的有效性和实用性。总体而言,第3.3节的实验结果表明,MoBA不仅在长序列任务中实现了与全注意力相当的性能,还在计算效率和可扩展性方面展现出显著优势,为大规模语言模型在长序列任务中的应用提供了一种高效且实用的解决方案。
-
-
3.代码详解
环境安装
配置虚拟环境
conda create -n moba python=3.10
conda activate moba
pip install .当然,也可以手动安装flash-attn,需注意本项目依赖的flash-attn版本为2.6.3
pip install flash_attn-2.6.3+cu118torch2.3cxx11abiFALSE-cp311-cp311-linux_x86_64.whl 如果使用已有环境,需注意本项目的transformers版本为>=4.48.3
然后下载llama-3.1-8B-Instruction:魔搭社区
在examples/llama.py里指定模型地址(也可以每次命令行手动指定),如:
parser.add_argument("--model", type=str, default="/media/good/4TB/mn/model/llm/llama/LLaMA3.2/llama3.2")接着就可以直接使用了:
python3 examples/llama.py当然,也可以手动指定参数
python3 examples/llama.py --model meta-llama/Llama-3.1-8B --attn moba-
简化版本详解
代码位于moba/moba_naive.py下,该函数是简化版本,更详细的版本可参考moba/moba_efficient.py
def moba_attn_varlen_naive(
q: torch.Tensor, # [seqlen, head, head_dim]
k: torch.Tensor,
v: torch.Tensor,
cu_seqlens: torch.Tensor,
max_seqlen: int,
moba_chunk_size: int,
moba_topk: int,
) -> torch.Tensor:
# qkv shape = [ S, H, D ]
batch = cu_seqlens.numel() - 1
softmax_scale = q.shape[-1] ** (-0.5)
o = torch.zeros_like(q)
for batch_idx in range(batch): # 以batch 维度进行循环,计算每个 batch 的注意力输出。
batch_start = cu_seqlens[batch_idx].item()
batch_end = cu_seqlens[batch_idx + 1].item()
# get qkv of this batch
q_ = q[batch_start:batch_end]
k_ = k[batch_start:batch_end]
v_ = v[batch_start:batch_end]
o_ = o[batch_start:batch_end]
# calc key gate weight
key_gate_weight = []
batch_size = batch_end - batch_start
num_block = math.ceil(batch_size / moba_chunk_size) # 计算当前 batch 中键的块数。每个块大小为 moba_chunk_size。
for block_idx in range(0, num_block):
block_start = block_idx * moba_chunk_size
block_end = min(batch_size, block_start + moba_chunk_size)
key_gate_weight.append(k_[block_start:block_end].mean(dim=0, keepdim=True)) # 计算当前块内所有键(k)的平均值,维度保持不变。
key_gate_weight = torch.cat(key_gate_weight, dim=0) # [ N, H, D ] 将所有块的门控权重拼接成一个矩阵。
# calc & mask gate
q_ = q_.type(torch.float32)
key_gate_weight = key_gate_weight.type(torch.float32)
gate = torch.einsum("shd,nhd->hsn", q_, key_gate_weight) # [ H, S, N ] (公式5)该行代码计算查询 q_ 和键门控权重 key_gate_weight 之间的注意力得分
key_gate_weight = key_gate_weight.type_as(k)
q_ = q_.type_as(k)
for i in range(num_block): # 修改 gate 矩阵来控制哪些查询(Q)可以关注到特定的键值对块(KV chunk)。
# select the future Qs that can attend to KV chunk i
gate[:, : (i + 1) * moba_chunk_size, i] = float("-inf") # 修改 gate 矩阵,确保每个块只能被未来的查询关注。
gate[:, i * moba_chunk_size : (i + 1) * moba_chunk_size, i] = float("inf")
# gate_top_k_idx = gate_top_k_val = [ H S K ]
gate_top_k_val, gate_top_k_idx = torch.topk( # 从 gate 矩阵中选择每个查询(Q)对应的前 moba_topk 个最大值及其索引(公式8,选择Top-k个块)
gate, k=min(moba_topk, num_block), dim=-1, largest=True, sorted=False
)
gate_top_k_val, _ = gate_top_k_val.min(dim=-1) # [ H, S ] topk中最小的数值
need_attend = gate >= gate_top_k_val.unsqueeze(-1) # 通过topk中最小的数值,选择 top-k 的块,并生成 need_attend 矩阵。
# add gate_idx_mask in case of there is cornercases of same topk val been selected
gate_idx_mask = torch.zeros(
need_attend.shape, dtype=torch.bool, device=q.device
)
gate_idx_mask = gate_idx_mask.scatter_(dim=-1, index=gate_top_k_idx, value=True) # 根据 gate_top_k_idx 的索引将值设为 True
need_attend = torch.logical_and(need_attend, gate_idx_mask) # 进行逻辑与操作,确保只有在 need_attend 和 gate_idx_mask 同时为 True 的位置才保留为 True。
gate[need_attend] = 0 # 更新 gate 矩阵,使其只保留需要关注的部分。
gate[~need_attend] = -float("inf") # 其余的为-inf
gate = gate.repeat_interleave(moba_chunk_size, dim=-1)[ # 扩展 gate 矩阵, 使用 repeat_interleave 方法将 gate 矩阵在最后一个维度上重复 moba_chunk_size 次。
:, :, :batch_size
] # [ H, S, S ]
gate.masked_fill_( # 应用下三角掩码。通过将上三角部分的值设为负无穷大,防止模型在计算注意力时看到未来的信息(这样会把之前需关注的部分中包含未来块的覆盖掉)。
torch.ones_like(gate, dtype=torch.bool).tril().logical_not(), -float("inf") # 下三角部分(包括对角线)变为 False,其余部分变为 True。这样就得到了一个上三角掩码。
)
# calc qk = qk^t
q_ = q_.type(torch.float32)
k_ = k_.type(torch.float32)
v_ = v_.type(torch.float32)
qk = torch.einsum("xhd,yhd->hxy", q_, k_)
# mask
qk += gate
qk *= softmax_scale
# calc o
p = qk.softmax(dim=-1)
o_ += torch.einsum("hxy,yhd->xhd", p, v_)
o = o.type_as(q)
return o-
以下是对其的详细解释:
首先获取原始QKV
# get qkv of this batch
q_ = q[batch_start:batch_end]
k_ = k[batch_start:batch_end]
v_ = v[batch_start:batch_end]
o_ = o[batch_start:batch_end]计算Query和KV块的亲和力分数,即gate权重
-
计算当前 batch 中键的块数num_block。每个块大小为 moba_chunk_size。
- 循环每个块
- 计算当前块的起始和终止序号
- 遍历每个块,计算块内所有键的平均值。
- 将所有块的平均值拼接成一个矩阵,即key_gate_weight。
# calc key gate weight
key_gate_weight = []
batch_size = batch_end - batch_start
num_block = math.ceil(batch_size / moba_chunk_size) # 计算当前 batch 中键的块数。每个块大小为 moba_chunk_size。
for block_idx in range(0, num_block):
block_start = block_idx * moba_chunk_size
block_end = min(batch_size, block_start + moba_chunk_size)
key_gate_weight.append(k_[block_start:block_end].mean(dim=0, keepdim=True)) # 计算当前块内所有键(k)的平均值,维度保持不变。
key_gate_weight = torch.cat(key_gate_weight, dim=0) # [ N, H, D ] 将所有块的门控权重拼接成一个矩阵。计算并修改注意力门控矩阵 gate
- 将查询 q_ 和键门控权重 key_gate_weight 转换为浮点类型,并计算它们之间的注意力得分。
- (见算法1第5行)该行代码计算查询 q_ 和键门控权重 key_gate_weight 之间的注意力得分
- 修改 gate 矩阵,确保每个块只能被未来的块关注。(需要被关注的是inf,不需要被关注的是-inf)
# calc & mask gate
q_ = q_.type(torch.float32)
key_gate_weight = key_gate_weight.type(torch.float32)
gate = torch.einsum("shd,nhd->hsn", q_, key_gate_weight) # [ H, S, N ] (公式5)该行代码计算查询 q_ 和键门控权重 key_gate_weight 之间的注意力得分
key_gate_weight = key_gate_weight.type_as(k)
q_ = q_.type_as(k)
for i in range(num_block): # 修改 gate 矩阵来控制哪些查询(Q)可以关注到特定的键值对块(KV chunk)。
# select the future Qs that can attend to KV chunk i
gate[:, : (i + 1) * moba_chunk_size, i] = float("-inf") # 修改 gate 矩阵,确保每个块只能被未来的查询关注。
gate[:, i * moba_chunk_size : (i + 1) * moba_chunk_size, i] = float("inf")经过这些代码后,gate[0]中的数据是以下样式的:
# 其中第一个块强制关注第一个块的内容(inf),其余(即未来块)不关注(-inf)
inf,-inf,-inf,...
inf,-inf,-inf,...
inf,-inf,-inf,...
inf,-inf,-inf,...
inf,-inf,-inf,...
...
# 其中第二个块强制关注第二个块的内容(inf),也关注历史块内容(小数),其余(即未来块)不关注(-inf)
30.203968048095703,inf,-inf,...
32.04781723022461,inf,-inf,...
37.20567321777344,inf,-inf,...
36.87221908569336,inf,-inf,...
30.654502868652344,inf,-inf,...
...
# 其中第三个块强制关注第三个块的内容(inf),也关注历史块内容(小数),其余(即未来块)不关注(-inf)
-11.862884521484375,28.660888671875,inf,...
-5.640305995941162,30.571495056152344,inf,...
...
...后面的以此类推这段代码的功能是从 gate 矩阵中选择每个查询(Q)对应的前 moba_topk 个最大值及其索引,并生成一个布尔矩阵 need_attend,用于后续的注意力计算。
- 从 gate 矩阵中选择每个查询(Q)对应的前 moba_topk 个最大值及其索引(算法1第8行,选择Top-k个块)
- 通过topk中最小的数值,选择 所有位于top-k 的块,并生成 need_attend 矩阵。
- 创建 gate_idx_mask 矩阵,确保只有在 gate_top_k_idx 中的索引位置为 True。
# gate_top_k_idx = gate_top_k_val = [ H S K ]
gate_top_k_val, gate_top_k_idx = torch.topk( # 从 gate 矩阵中选择每个查询(Q)对应的前 moba_topk 个最大值及其索引(公式8,选择Top-k个块)
gate, k=min(moba_topk, num_block), dim=-1, largest=True, sorted=False
)
gate_top_k_val, _ = gate_top_k_val.min(dim=-1) # [ H, S ] topk中最小的数值
need_attend = gate >= gate_top_k_val.unsqueeze(-1) # 通过topk中最小的数值,选择 top-k 的块,并生成 need_attend 矩阵。
# add gate_idx_mask in case of there is cornercases of same topk val been selected
gate_idx_mask = torch.zeros(
need_attend.shape, dtype=torch.bool, device=q.device
)
gate_idx_mask = gate_idx_mask.scatter_(dim=-1, index=gate_top_k_idx, value=True) # 根据 gate_top_k_idx 的索引将值设为 True
其中gate_idx_mask的数据如下:
- 刚开始时基本都是-inf,所以True全在前面(即按顺序排列)
- 后面True和False完全以gate_top_k_idx为准
True,True,True,True,True,True,True,True,True,True,True,True,False,False,False,False,False,False,False,False,False
True,True,True,True,True,True,True,True,True,True,True,True,False,False,False,False,False,False,False,False,False
...
True,False,False,False,False,False,True,False,True,False,True,True,True,True,True,True,True,True,True,False,False
True,True,False,False,False,False,False,False,False,True,False,True,True,True,True,True,True,True,True,True,False
True,False,False,False,False,False,False,True,False,True,False,True,True,True,True,True,True,True,True,True,False
True,False,False,False,False,False,False,True,False,True,False,True,True,True,True,True,True,True,True,True,False
True,False,False,False,False,False,False,True,False,True,True,False,True,True,True,True,True,True,True,True,False
True,False,False,False,False,False,False,False,True,False,True,False,True,True,True,True,True,True,True,True,True
False,False,False,False,False,False,False,False,True,False,True,True,True,True,True,True,True,True,True,True,True这段代码的主要功能是更新 gate 矩阵,使其只保留需要关注的部分,并应用下三角掩码防止模型看到未来的信息。具体步骤如下:
- 进行逻辑与操作,确保只有在 need_attend 和 gate_idx_mask 同时为 True 的位置才保留为 True。
- 注意,这一步中,模型没考虑未来信息泄露,只考虑哪些块的内容该被当前Query关注
- 更新 gate 矩阵,使其只保留需要关注的部分,其余部分设为负无穷大。
- 扩展 gate 矩阵,在最后一个维度上重复 moba_chunk_size 次。
- 应用下三角掩码,防止模型在计算注意力时看到未来的信息。
- 注意:这样做实际上是将上一步逻辑与操作中没考虑未来信息泄露的True给覆盖掉,确保模型只考虑历史和当前信息
need_attend = torch.logical_and(need_attend, gate_idx_mask) # 进行逻辑与操作,确保只有在 need_attend 和 gate_idx_mask 同时为 True 的位置才保留为 True。
gate[need_attend] = 0 # 更新 gate 矩阵,使其只保留需要关注的部分。
gate[~need_attend] = -float("inf") # 其余的为-inf
gate = gate.repeat_interleave(moba_chunk_size, dim=-1)[ # 扩展 gate 矩阵, 使用 repeat_interleave 方法将 gate 矩阵在最后一个维度上重复 moba_chunk_size 次。
:, :, :batch_size
] # [ H, S, S ]
gate.masked_fill_( # 应用下三角掩码。通过将上三角部分的值设为负无穷大,防止模型在计算注意力时看到未来的信息(这样会把之前需关注的部分中包含未来块的覆盖掉)。
torch.ones_like(gate, dtype=torch.bool).tril().logical_not(), -float("inf") # 下三角部分(包括对角线)变为 False,其余部分变为 True。这样就得到了一个上三角掩码。
)之后gate的值如下:

计算注意力并应用gate,不多赘述。
# calc qk = qk^t
q_ = q_.type(torch.float32)
k_ = k_.type(torch.float32)
v_ = v_.type(torch.float32)
qk = torch.einsum("xhd,yhd->hxy", q_, k_)
# mask
qk += gate
qk *= softmax_scale
# calc o
p = qk.softmax(dim=-1)
o_ += torch.einsum("hxy,yhd->xhd", p, v_)
o = o.type_as(q)-
-
4.总结
本文介绍了一种名为 Mixture of Block Attention (MoBA) 的新型注意力机制,旨在解决大规模语言模型(LLMs)在处理长序列时面临的计算复杂度问题。MoBA通过将传统的全注意力机制与稀疏注意力相结合,实现了在保持模型性能的同时显著降低计算成本的目标。该机制的核心在于将序列分割成多个块,并通过动态选择与查询最相关的块来计算注意力,从而避免了对整个序列的全注意力计算。MoBA的设计灵感来源于Mixture of Experts(MoE)架构,它通过引入一个门控机制来选择性地路由查询到最相关的块,同时保留了因果关系,确保了自回归语言模型的顺序性。
总体而言,MoBA作为一种创新的注意力机制,为解决大规模语言模型在处理长序列时的计算瓶颈提供了一种新的思路。它通过动态稀疏注意力和块选择机制,在保持模型性能的同时显著降低了计算成本,展示了在长序列任务中的巨大潜力。未来的工作可以进一步探索MoBA在多模态任务中的应用,以及如何通过优化块选择策略来提升模型的泛化能力。
如果你觉得这篇文章对你有帮助,或者内容让你眼前一亮,不妨点个赞、关注一下,或者收藏起来慢慢看!你的每一个点赞和关注都是对我最大的支持,也让我更有动力继续创作更多优质内容。感谢你的支持! ❤️