1.摘要
DeepSeek R1成功复制了o1级的表现,它也是通过数百万个样本和多个训练阶段强化学习达到的。然而,尽管进行了大量的o1复制尝试,但没有一个公开地复制了明确的测试时间缩放行为。因此,我们要问:什么是最简单的方法来实现测试时间的缩放和强大的推理性能?
测试时扩展(Test-time scaling)是一种很有前途的语言建模新方法,它使用额外的测试时计算来提高性能。最近,OpenAI的o1模型展示了这种能力,但没有公开分享其方法。
作者寻求最简单的方法来实现测试时间缩放和强大的推理性能。
- 首先,作者策划了一个包含1,000个问题的小型数据集s1K,并根据三个标准进行推理跟踪:难度,多样性和质量。
- 其次,作者开发了预算强制(budget forcing)来控制测试时间计算(test-time compute),通过强制终止模型的思考过程或通过在模型的生成过程中多次添加“等待”来延长它。这可能会导致模型重复检查其答案,通常会修复不正确的推理步骤。
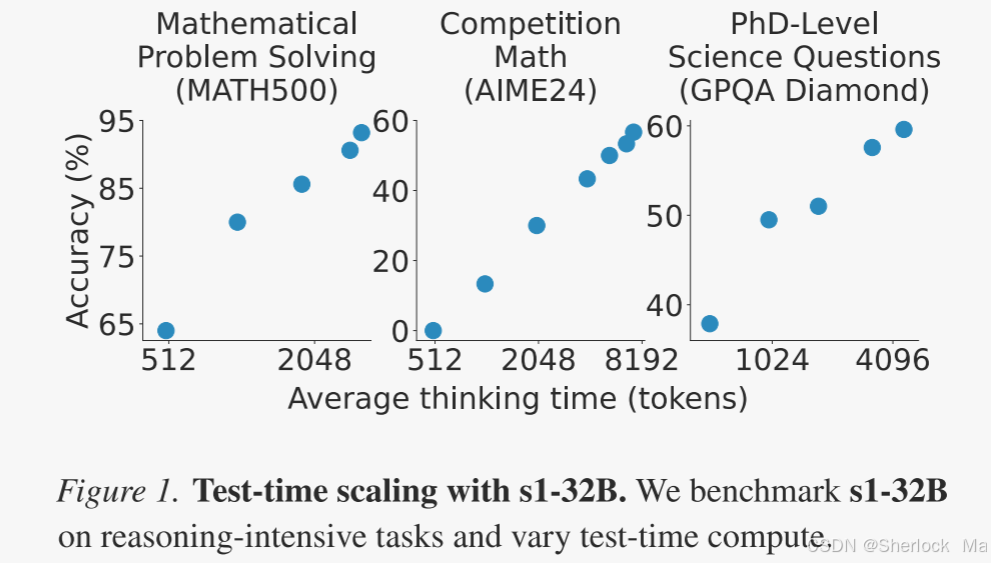
作者表明,仅对1,000个样本进行训练,并通过一种简单的测试时间技术(称之为预算强制(budget forcing))控制思维链持续时间,就可以得到一个强大的推理模型,该模型的性能随着测试时间计算的增加而提高。
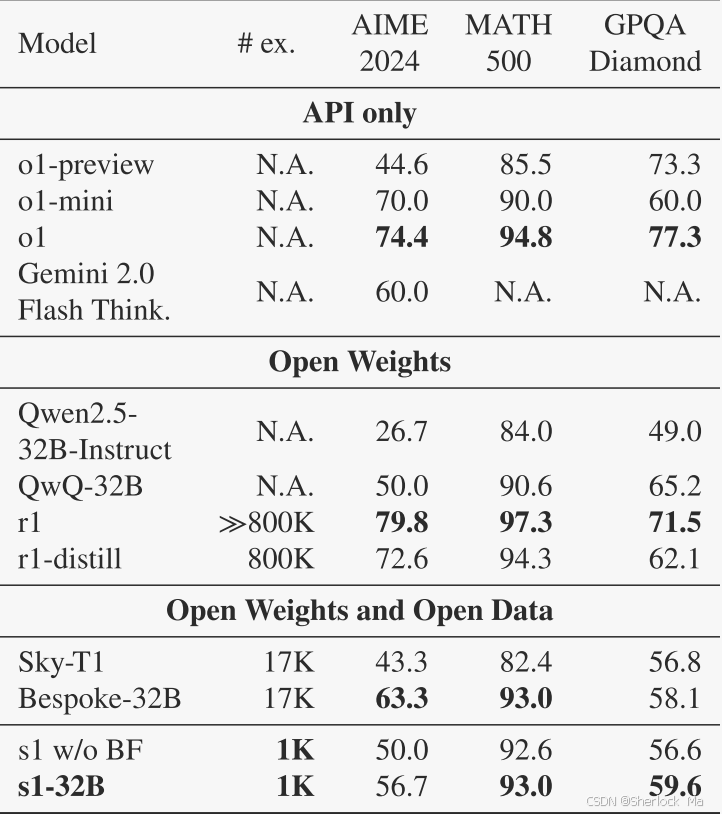
在s1K上对Qwen 2. 5-32 B-Instruct模型进行监督微调,并为其配备预算强制后,作者的模型s1- 32 B在竞争数学问题上超过o1-preview高达27%(MATH和AIME 24)。
代码地址:https://github.com/simplescaling/s1
-
-
2.数据集构建
初始采集59K样本
作者从16个不同的来源收集了59029个问题,遵循三个指导原则。
- 质量:数据集应该是高质量的;我们总是检查样本并忽略数据集,例如,格式不佳;
- 难度:数据集应该具有挑战性,需要大量的推理工作;
- 多样性:数据集应该来自不同的领域,以涵盖不同的推理任务。
作者收集两类数据集:
- 最大的数据源是NuminaMATH,它是一个有30660个数学问题的在线网站。除此还包括历史AIME问题(1983-2021)。为了增强多样性,还增加了OlympicArena,总计4250个问题,涵盖天文学,生物学,化学,计算机科学,地理,数学和物理学。其中OmniMath增加了4238个竞赛级数学问题。以及包括来自AGIEval的2385个问题,其中包括SAT和LSAT等标准化考试的问题,涵盖英语,法律和逻辑。
- 定量推理中的新数据集:为了补充这些现有数据集,作者创建了两个原始数据集。s1-prob由斯坦福大学统计系博士资格考试概率部分的182道题组成(https://statistics.stanford.edu),并附有涵盖困难证明的手写解决方案。概率资格考试每年举行一次,要求专业水平的数学问题解决能力。s1-teasers包括23个具有挑战性的脑筋急转弯,通常用于定量交易头寸的面试问题。每个示例都包含一个问题和来自PuzzledQuant(https://www. puzzledquant. com/)的解决方案。只选取难度最高的例子(“Hard”)。
对于每个问题,作者使用Google Gemini Flash Thinking API生成推理跟踪和解决方案,提取其推理跟踪和响应。这将产生59 K的三元组,包括(问题、生成的推理轨迹和生成的解决方案)。然后对所有样品进行去污,并删除重复数据。
最终选择1K个样本
作者通过三个阶段的过滤,根据三个指导数据原则:质量,难度和多样性,达到1,000个样本的最小集合。
质量:首先删除遇到任何API错误的问题,接下来通过检查它们是否包含任何具有格式问题的字符串模式来过滤掉低质量的示例,例如ASCII艺术图,不存在的图像引用或不一致的问题编号。从这个样本池中,作者从数据集中确定了最终1,000个样本中的384个样本。
难度:作者使用两个指标:模型性能和推理迹长。作者对每个问题评估两个模型:Qwen2.5- 7 B-Instruct和Qwen 2. 5-32 B-Instruct,通过Claude 3.5 Sonnet进行比较来评估正确性。作者使用Qwen2.5标记器测量每个推理轨迹的标记长度以指示问题的难度。这依赖于这样一个假设,即更困难的问题需要更多的思考令牌。根据评分,作者删除了Qwen2.5- 7 B-Instruct或Qwen2.5- 32 B-Instruct可以正确解决的问题,因此可能太容易了。通过使用两个模型,作者降低了由于其中一个模型的简单问题上出现罕见错误而导致简单样本通过过滤的可能性。这使作者的总样本减少到24496,为下一轮基于多样性的子采样奠定了基础。
多样性:为了量化多样性,作者使用基于数学主题分类(MSC)系统的Claude 3.5 Sonnet将每个问题分类到特定领域(例如,几何学、动力系统、真实的分析等)。为了从24,496个问题中选择最终示例,作者首先均匀随机选择一个域。然后,根据一个有利于更长推理轨迹的分布,从这个领域中抽取一个问题,重复这个过程,直到我们有1,000个样本。
-
-
3.Test-time scaling
方法
作者将测试时间缩放方法分为
- 顺序的,其中后面的计算依赖于前面的计算(例如,长推理轨迹)
- 并行,其中计算独立运行(例如,多数投票)。
作者关注顺序缩放,因为直觉上认为它应该更好地缩放,因为后面的计算可以建立在中间结果的基础上,允许更深层次的推理和迭代改进。
-
预算强制(Budget forcing):作者提出了一种简单的解码时间干预,通过在测试时间强制使用最大或最小数量的思考token。具体来说,budget forcing 包括以下两个主要操作:
1. 强制结束思考过程(Forcing Early Exit)
-
如果模型生成的推理步骤(tokens)超过了预设的上限(budget),则会强制结束其思考过程。这是通过在模型生成的推理步骤达到上限时,直接插入一个“结束思考”的标记(end-of-thinking token delimiter)来实现的。
-
这种方法可以防止模型过度思考,从而节省计算资源,并确保模型在有限的时间内生成答案。
2. 延长思考过程(Forcing Continued Thinking)
-
如果希望模型在某个问题上花费更多的计算资源,可以通过抑制“结束思考”的标记生成,并在模型的推理步骤中插入特定的字符串(如“Wait”)来鼓励模型继续思考。
-
这种方法可以促使模型重新检查其推理过程,修正可能的错误,从而提高答案的准确性。

-
指标
作者衡量三个指标:
- Control(可控性):衡量测试时计算扩展方法对计算资源(以生成的token数量衡量)的控制能力。
-
-
其中,A 是所有评估运行的集合,amin 和 amax 是预设的最小和最大计算预算(token数量)。如果模型在所有评估中生成的token数量都在预设范围内,则Control值为100%,表示完全可控。
-
意义:高Control值表明方法能够精确地将模型的计算量控制在预设的范围内,这对于资源受限的环境尤为重要。
-
-
Scaling(扩展性):衡量随着测试时计算量增加,模型性能提升的速率。
-
-
其中,a(a) 和 a′(a′) 分别是模型在计算量为 a 和 a′ 时的准确率。Scaling值是所有评估点对之间的平均斜率,表示随着计算量增加,准确率提升的平均速率。
-
意义:高Scaling值表明模型在增加计算量时能够显著提升性能,这对于需要更高准确率的任务非常关键。
-
-
Performance(性能):衡量模型在测试时计算扩展方法下的最高准确率。
-
-
即模型在所有评估点中达到的最高准确率。
-
意义:高Performance值表明模型在某种计算预算下能够达到较高的准确率,这对于实际应用中的性能要求至关重要。
-
-
-
4.结果
设置
训练:使用s1 K对Qwen 2. 5-32 B-Instruct进行监督微调,在16个NVIDIA H100 GPU上使用PyTorch FSDP耗时26分钟。
评估:作者选择了三个在该领域广泛使用的具有代表性的推理基准:
- AIME 24由2024年1月31日(星期三)至2月1日(星期四)举行的2024年美国数学邀请考试(AIME)中使用的30道题组成。AIME测试数学问题解决与算术,代数,计数,几何,数论,概率,和其他中学数学主题。在测试中得分高的高中生将被邀请参加美利坚合众国数学奥林匹克竞赛。所有AIME答案都是从000到999(包括000和999)的整数。一些AIME问题依赖于使用矢量图形语言Asagnptote提供给模型的图形,因为它不能接受图像输入。
- MATH 500是难度不等的竞赛数学题的标杆。
- GPQA Diamond由198道来自生物学、化学和物理学的博士级科学题组成。相应领域的博士专家仅达到69.7%。
其他模型:作者将s1- 32 B与以下模型进行比较:
- OpenAI o1系列,这是一种推广测试时间缩放思想的闭源模型;
- DeepSeek r1系列,这是开放式权重推理模型,具有高达o1级的性能;
- Qwen的QwQ-32 B-Preview,一个32 B开放权重推理模型;
- Sky-T1- 32 B-Preview和Bespoke 32 B,这是一个开放的模型,具有从QwQ-32 B预览版和r1中提取的开放推理数据;
- Google Gemini 2.0 Flash Thinking Experimental,我们从中提取的API。
结果
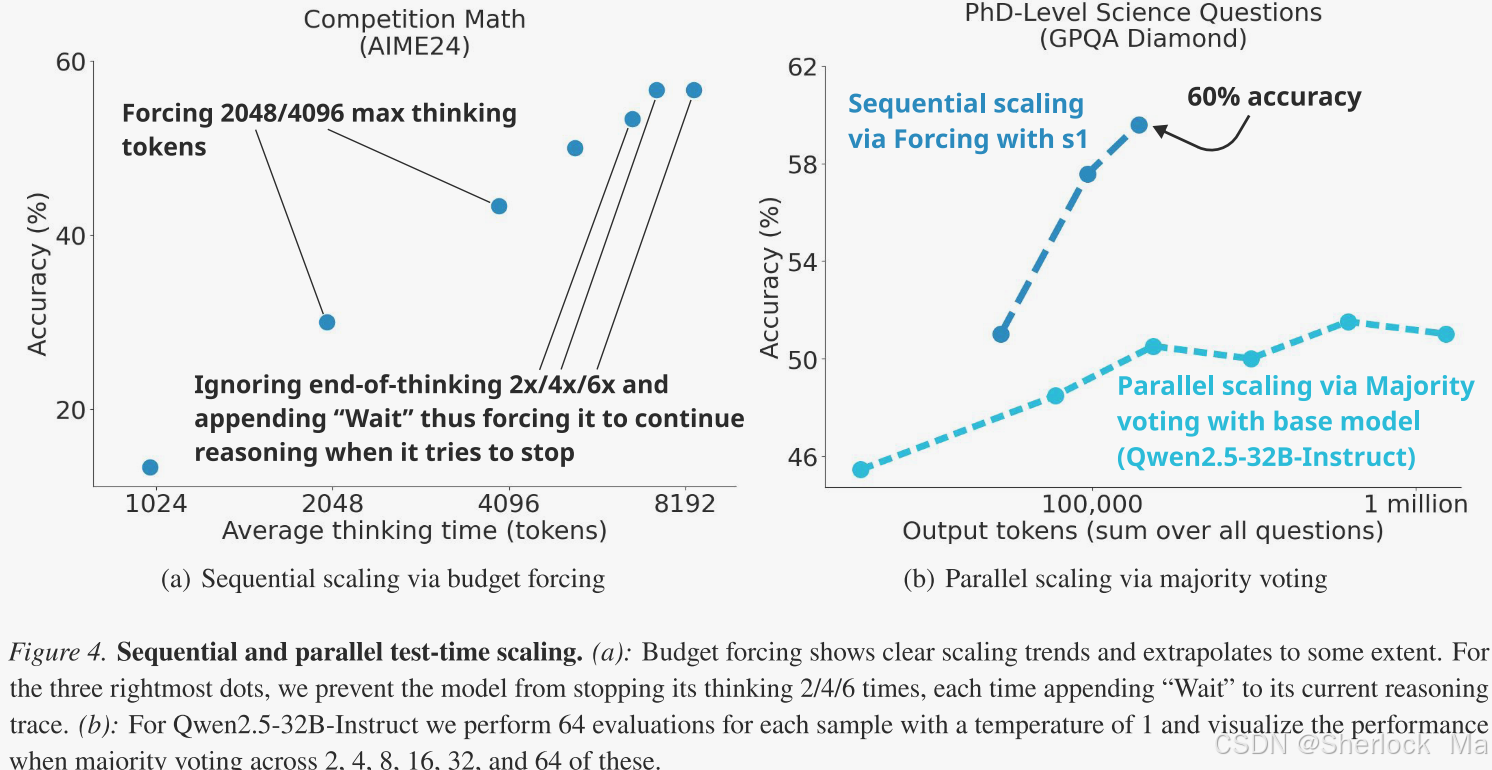
在图4(左)中,尽管可以使用预算强制技术和更多的测试时间计算来提高AIME 24的性能,但最终还是会降低到原来的6倍。太频繁地抑制思维结束标记,可能会导致模型陷入重复循环,而不是继续推理。在图4(右)中,作者展示了在1,000个样本上训练Qwen 2. 532 B-Instruct以产生s1- 32 B并为它配备简单的预算强制技术之后,它在不同的缩放范例中操作。通过多数表决在基本模型上扩展测试时计算无法赶上s1- 32 B的性能,这验证了顺序扩展比并行扩展更有效。
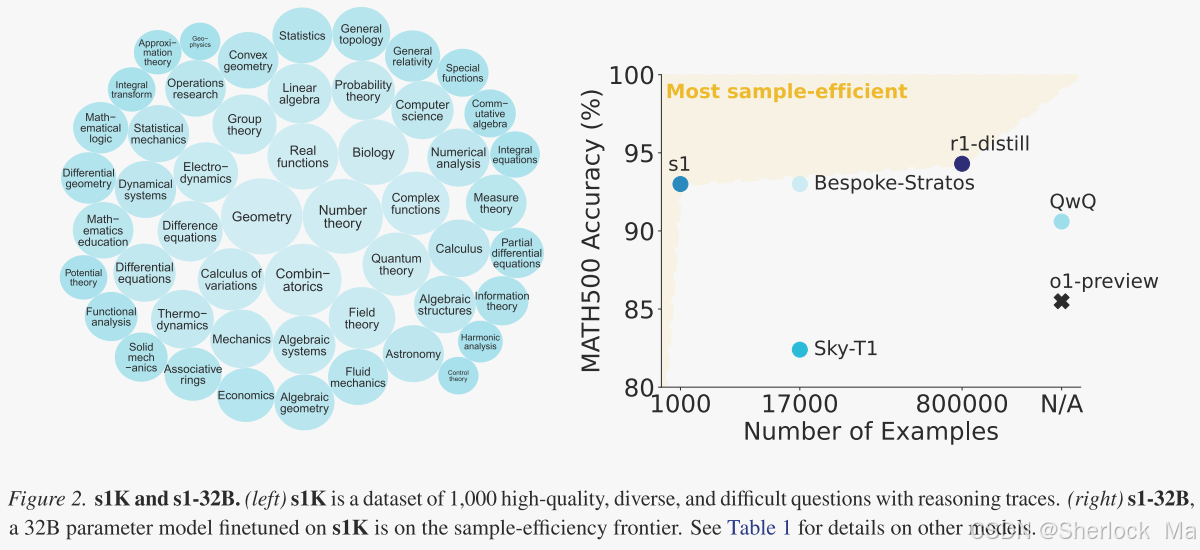
在图2(右)和表1中,作者将s1- 32 B与其他型号进行了比较。可以发现s132 B是样本效率最高的开放数据推理模型。它的性能明显优于基础模型(Qwen2.5- 32 B-Instrut),尽管它只是在额外的1000个样本上进行训练。r1- 32 B显示出比s1- 32 B更强的性能,然而,它是在800 ×以上的推理样本上训练的。仅用1,000个样本是否就能达到其性能,这是一个悬而未决的问题。最后,作者的模型几乎与AIME 24上的Gemini 2.0 Thinking相匹配。由于s1- 32 B是从Gemini 2.0中蒸馏出的,这表明作者的蒸馏程序可能是有效的。

推理效果图



-
-
5.消融实验
数据量、多样性和难度的消融实验
作者在构建s1K数据集时,提出了三个核心原则:质量(Quality)、多样性和难度(Diversity and Difficulty)。为了验证这些原则的有效性,他们进行了多种消融实验,分别考察了仅使用随机选择(Random)、仅考虑多样性(Diverse)和仅考虑难度(Longest)的数据选择策略对模型性能的影响,并与完整的s1K数据集进行了对比。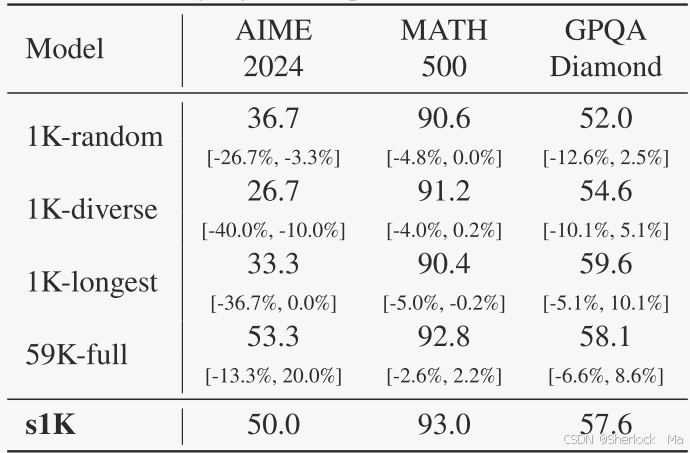
预算强制(Budget Forcing)
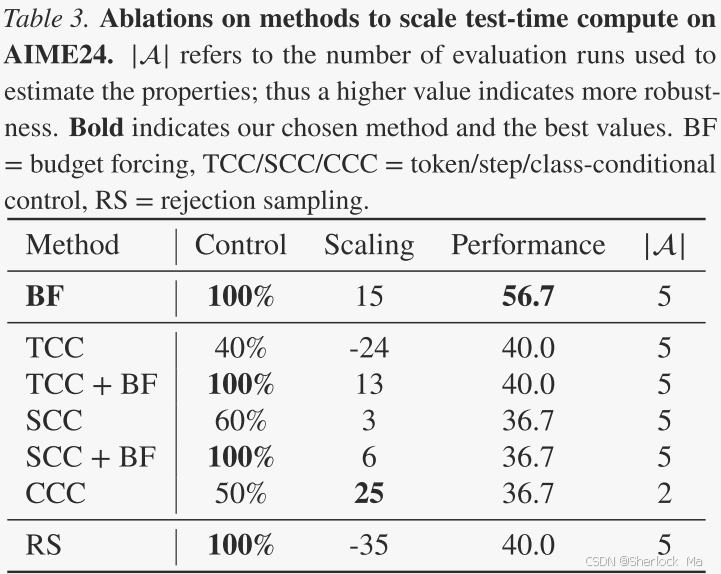
作者对不同的测试时计算扩展方法进行了详细的比较和分析。这些方法的目标是在测试阶段通过增加计算量来提升模型的推理性能。作者提出了一个简单而有效的技术——预算强制(Budget Forcing),并将其与其他方法进行了对比。
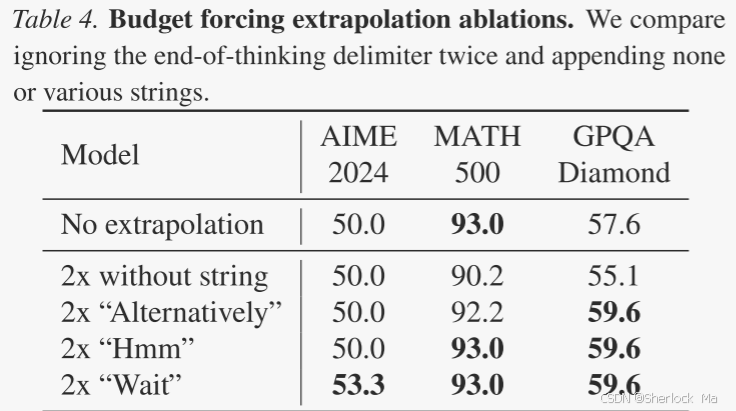
在表4中,作者比较了不同字符串的外推性能。发现“Wait”通常会提供最佳性能。
-
-
总结
本文提出了一种名为“简单测试时扩展”(Simple Test-time Scaling)的方法,旨在通过在测试阶段增加计算资源来提升语言模型的推理性能。该方法的核心是通过少量数据的监督微调(Supervised Fine-Tuning, SFT)和一种称为“预算强制”(Budget Forcing)的技术来控制模型在推理过程中的思考时间,从而实现性能的显著提升。研究团队通过精心策划的数据集s1K,仅包含1000个经过严格筛选的问题及其推理路径,来训练他们的模型s1-32B。s1K的构建遵循了质量、难度和多样性的原则,通过多阶段的筛选过程,从59,029个初始样本中挑选出最具挑战性和多样性的1000个问题。这些样本涵盖了从数学竞赛到科学领域的广泛问题,确保了模型在多种推理任务上的泛化能力。
在测试时,预算强制技术通过强制模型在特定的思考阶段生成一定数量的推理步骤(tokens),从而实现对模型推理过程的精确控制。具体来说,如果模型生成的推理步骤超过了预设的上限,就会强制结束其思考过程;相反,如果希望模型在某个问题上花费更多的计算资源,可以通过插入特定的字符串(如“Wait”)来鼓励模型继续思考。这种技术不仅提高了模型的推理效率,还显著提升了其在复杂问题上的准确性。
实验结果表明,s1-32B模型在多个推理基准测试中表现出色,尤其是在数学竞赛问题上,其性能超过了OpenAI的o1-preview模型,甚至在某些情况下能够接近或达到人类专家的水平。此外,s1-32B模型在样本效率方面也表现出色,仅使用1000个样本就达到了与使用数万个样本训练的模型相当的性能。这表明,通过精心设计的数据集和简单的测试时技术,可以在不增加大量训练数据的情况下,显著提升语言模型的推理能力。
总体而言,本文提出了一种简单而有效的测试时扩展方法,通过少量数据的微调和预算强制技术,显著提升了语言模型在复杂推理任务中的表现。这一成果不仅为语言模型的推理能力研究提供了新的视角,也为未来开发更高效、更强大的推理模型奠定了基础。
如果你觉得这篇文章的内容对你有帮助,或者让你眼前一亮,不妨点个赞吧!你的支持是我继续创作的动力,也希望能看到更多人从中受益。如果想不错过后续的精彩内容,记得关注我哦!还有,收藏一下这篇文章,方便你以后随时回顾,也方便分享给需要的朋友们。感谢你的支持,我们下次见!